Автор: Денис Аветисян
Новый обзор демонстрирует, как из исторических записей разговоров можно создать надежного помощника на базе искусственного интеллекта, способного решать рутинные задачи и безопасно передавать сложные вопросы специалистам.
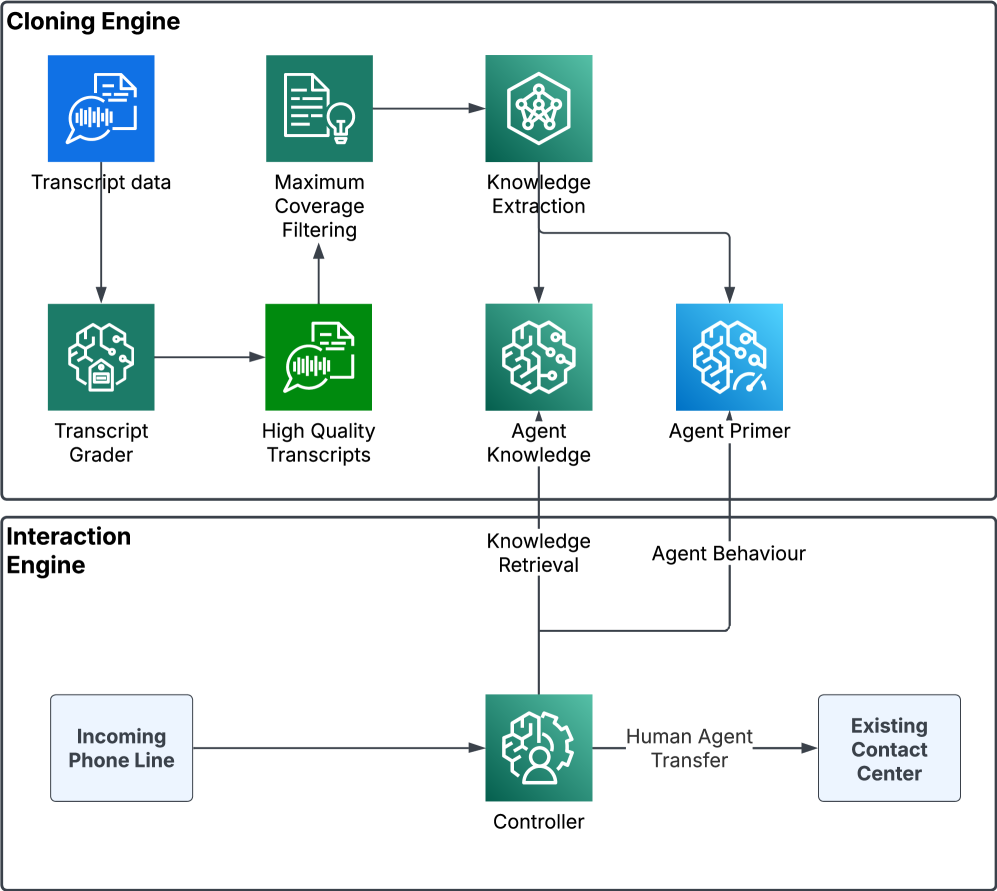
Исследование охватывает извлечение знаний из текстовых данных, интеграцию генеративных моделей с поиском релевантной информации (RAG) и методы надежной оценки эффективности разговорных ИИ-ассистентов.
Несмотря на значительный прогресс в области искусственного интеллекта, создание надежных диалоговых систем для обслуживания клиентов остается сложной задачей из-за неструктурированности данных и необходимости точной передачи запросов операторам. В данной работе, ‘From Transcripts to AI Agents: Knowledge Extraction, RAG Integration, and Robust Evaluation of Conversational AI Assistants’, представлен комплексный подход к построению и оценке диалогового агента на основе исторических записей звонков. Показано, что использование методов извлечения знаний и архитектуры Retrieval-Augmented Generation (RAG) в сочетании с тщательно настроенными промптами позволяет создать систему, способную автономно обрабатывать до 30% обращений, обеспечивая высокую точность и безопасность. Каковы перспективы масштабирования предложенного подхода для автоматизации более сложных сценариев взаимодействия с клиентами и повышения эффективности работы колл-центров?
Раскрытие Потенциала Разговорного ИИ
Современные большие языковые модели (БЯМ) произвели настоящую революцию в области обработки естественного языка, открыв возможности для беспрецедентно реалистичного взаимодействия человека и машины. В отличие от предыдущих поколений систем, БЯМ способны не просто распознавать и выполнять команды, но и генерировать связные, логичные и контекстуально релевантные тексты, имитирующие человеческую речь. Это стало возможным благодаря использованию глубоких нейронных сетей и огромных объемов текстовых данных, на которых модели обучаются. В результате, БЯМ демонстрируют впечатляющие способности в задачах, требующих понимания и генерации естественного языка, таких как машинный перевод, написание текстов, ответы на вопросы и ведение диалогов, приближая нас к эпохе, когда взаимодействие с искусственным интеллектом станет интуитивно понятным и неотличимым от общения с другим человеком.
Эффективное внедрение больших языковых моделей (LLM) в сложные реальные приложения сталкивается с существенными трудностями, связанными с доступом к знаниям и качеством генерируемых ответов. Несмотря на впечатляющие способности к обработке языка, LLM часто ограничены информацией, на которой они были обучены, и испытывают трудности с поиском и интеграцией актуальных знаний из внешних источников. Это может приводить к неточным, устаревшим или нерелевантным ответам, особенно в быстро меняющихся областях знаний. Современные исследования направлены на разработку механизмов, позволяющих LLM эффективно извлекать информацию из различных баз данных, документов и веб-ресурсов, а также на совершенствование методов оценки и фильтрации генерируемого контента для обеспечения его достоверности и соответствия запросу пользователя. Преодоление этих сложностей является ключевым фактором для раскрытия полного потенциала LLM в таких областях, как медицина, финансы и образование.
Усиление LLM с Помощью Поиска Знаний
Метод генерации с расширенным поиском (Retrieval-Augmented Generation, RAG) повышает эффективность больших языковых моделей (LLM) за счет сопоставления генерируемых ответов с актуальной и релевантной информацией из внешних источников. Вместо того, чтобы полагаться исключительно на параметры, полученные в процессе обучения, RAG динамически извлекает информацию из базы знаний во время выполнения запроса, что позволяет LLM предоставлять более точные, контекстуально обоснованные и современные ответы. Это особенно важно для LLM, работающих с быстро меняющимися данными или требующих доступа к специализированным знаниям, которые не были включены в исходный набор данных для обучения.
Метод плотного извлечения (Dense Passage Retrieval) представляет собой технику эффективного поиска релевантных отрывков из базы знаний, используемую для дополнения больших языковых моделей (LLM). В отличие от традиционных методов, основанных на сопоставлении ключевых слов, плотное извлечение преобразует как запросы, так и отрывки базы знаний в векторные представления (эмбеддинги) с использованием нейронных сетей. Релевантность определяется как близость векторов запроса и отрывков в векторном пространстве, что позволяет находить семантически связанные отрывки, даже если в них не содержатся точные ключевые слова из запроса. Использование векторных баз данных и алгоритмов приближенного ближайшего соседа (Approximate Nearest Neighbor, ANN) обеспечивает высокую скорость поиска среди больших объемов данных, что критически важно для приложений реального времени.
Платформы, такие как Kore.ai, PolyAI и Google Duplex, используют технологию RAG (Retrieval-Augmented Generation) для повышения точности и релевантности ответов в диалоговых системах. Вместо генерации ответов исключительно на основе внутренних знаний языковой модели, RAG позволяет извлекать информацию из внешних баз знаний в режиме реального времени. Это особенно важно для вопросов, требующих доступа к актуальным данным или специфической информации о продукте, услуге или клиенте, обеспечивая более контекстуально обоснованные и достоверные ответы в процессе взаимодействия с пользователем.

Обеспечение Качества и Надежности Ответов
Тщательная оценка ответов больших языковых моделей (LLM) является критически важной задачей, требующей использования критериев, выходящих за рамки простой точности. Оценка должна учитывать не только фактическую корректность, но и соответствие ответа контексту запроса, уместность предоставляемой информации и способность модели избегать предоставления недопустимых или вредоносных данных. Простая проверка на фактическую точность недостаточна, поскольку ответ может быть технически верным, но неуместным или не соответствующим потребностям пользователя. Необходимо учитывать такие аспекты, как полнота ответа, его ясность и логическая связность, а также способность модели поддерживать последовательный и содержательный диалог.
Оценка транскриптов (Transcript Grading) представляет собой систематический подход к анализу ответов ассистента, включающий оценку двух ключевых аспектов: соответствия ответа запросу (Appropriateness) и согласованности ответа с контекстом диалога (Observation Alignment). Соответствие ответа запросу оценивает, насколько релевантен и полезен ответ для пользователя, учитывая его исходный вопрос или потребность. Согласованность с контекстом диалога, в свою очередь, проверяет, насколько ответ логически связан с предыдущими репликами и учитывает все доступные данные из беседы. Такой подход позволяет более полно оценить качество работы ассистента, чем простая проверка фактической точности, и выявить проблемы в понимании контекста или генерации релевантных ответов.
Для обеспечения репрезентативности оценки качества ответов языковой модели используется задача о максимальном покрытии (Maximum Coverage Problem). Этот подход позволяет отобрать наиболее разнообразный подмножество транскриптов из общего объема данных, максимизируя объем информации, полученной в ходе оценки. Алгоритм отбирает транскрипты таким образом, чтобы каждое новое добавление в подмножество существенно расширяло охват различных сценариев и запросов, избегая избыточности. Это гарантирует, что оценка будет отражать производительность модели в широком спектре реальных ситуаций, а не только в наиболее часто встречающихся.
В рамках нашей системы оценки, удается охватить до 35% реальных телефонных разговоров в сфере недвижимости. При этом, достигается 97% фактической точности предоставляемых ответов и 100% точность отклонения некорректных или нерелевантных запросов. Данный показатель покрытия позволяет провести всесторонний анализ качества работы системы на значительном объеме данных, обеспечивая высокую надежность и точность предоставляемой информации в данной предметной области.
В области специализированного подбора персонала, наша система оценки охватывает 25% реальных диалогов. При этом достигается 94% фактической точности ответов ассистента, что означает высокую степень соответствия предоставляемой информации действительности. Важно отметить, что система демонстрирует 100% точность в отклонении некорректных или неприемлемых ответов, гарантируя отсутствие нежелательного контента или ошибок в процессе подбора.
Оценка разговорных ИИ-систем, таких как Google Duplex, невозможна без использования автоматического распознавания речи (ASR), обработки естественного языка (NLU) и синтеза речи (TTS). ASR преобразует аудиозаписи разговоров в текстовый формат для последующего анализа. NLU позволяет извлечь смысл из полученного текста, определяя намерения пользователя и сущности, упомянутые в диалоге. TTS, в свою очередь, используется для воспроизведения синтезированной речи, что необходимо для оценки качества и естественности ответов ИИ, а также для проверки корректности проговаривания информации. Взаимодействие этих трех компонентов обеспечивает комплексную оценку производительности и эффективности разговорного ИИ.
Реальные Применения и Перспективы Развития
Успешное применение разработанных методов наблюдается в узкоспециализированных областях, таких как рынок недвижимости и подбор квалифицированного персонала. В сфере недвижимости, автоматизированный анализ данных о предложении и спросе позволяет значительно ускорить процесс оценки объектов и подбора оптимальных вариантов для клиентов. В области рекрутинга, система способна эффективно сопоставлять требования вакансий с профилями кандидатов, сокращая время поиска и повышая качество найма. В обоих случаях, внедрение этих технологий приводит к ощутимому повышению эффективности работы и, как следствие, к росту удовлетворенности клиентов, что подтверждается результатами пилотных проектов и отзывами пользователей.
Тонкая настройка запросов, или Prompt Tuning, представляет собой эффективный метод улучшения поведения больших языковых моделей (LLM). Вместо переобучения всей модели, этот подход фокусируется на оптимизации самих запросов, подаваемых LLM. Путем незначительных изменений в формулировках и структуре запроса, можно значительно повысить точность и релевантность ответов для конкретных задач. Это позволяет добиться стабильно высокого качества генерации текста, а также адаптировать LLM к специфическим требованиям различных областей применения, таких как подбор персонала или анализ рынка недвижимости. Использование Prompt Tuning позволяет максимально эффективно использовать возможности LLM, минимизируя вычислительные затраты и время, необходимые для адаптации модели к новым задачам.
Постоянное совершенствование является ключевым аспектом развития современных систем, основанных на больших языковых моделях. Для выявления потенциальных уязвимостей и повышения их надежности широко применяются методы, подобные Red Teaming — когда специально обученная команда имитирует атаки, стремясь найти слабые места в системе. Этот процесс позволяет не только обнаружить ошибки и недочеты в работе модели, но и оперативно их устранить, повышая устойчивость к непредвиденным ситуациям и обеспечивая более предсказуемое и безопасное функционирование. Регулярное проведение подобных тестов способствует постоянному улучшению качества и надежности систем, делая их более эффективными и полезными в реальных условиях применения.
Исследование демонстрирует, что создание компетентного виртуального помощника требует не просто обработки больших объемов данных, но и тщательной организации знаний, извлеченных из исторических транскриптов. Подобный подход позволяет системе надежно справляться с рутинными запросами, одновременно обеспечивая безопасную передачу сложных случаев человеку-оператору. Как заметила Барбара Лисков: «Программы должны быть спроектированы так, чтобы изменения в одной части не влияли на другие». В контексте данного исследования, модульная структура промптов и управляемая архитектура системы обеспечивают именно такую устойчивость к изменениям и гарантируют предсказуемость поведения помощника, что крайне важно для надежной поддержки человеческих агентов.
Куда же дальше?
Представленная работа, по сути, демонстрирует не столько создание «умного» помощника, сколько взлом системы рутинных запросов. Извлечение знаний из транскриптов — лишь первый шаг; настоящий интерес представляет возможность построения управляемого хаоса в структуре промптов. Если взглянуть пристальнее, становится очевидным, что «безопасная эскалация» сложных случаев — это не гарантия, а признание текущих ограничений. Искусственный интеллект пока что умеет лишь перекладывать ответственность, а не брать её на себя.
Дальнейшее развитие неизбежно потребует выхода за рамки простой «добавленной генерации» (RAG). Необходимо научиться моделировать неопределенность, учитывать контекст не только на уровне текста, но и на уровне намерений пользователя. Иначе говоря, нужно создать систему, способную не просто отвечать на вопросы, а предвидеть их — и, возможно, даже манипулировать ими.
Истинный прорыв, вероятно, произойдет, когда мы перестанем стремиться к созданию «помощников», а начнем разрабатывать инструменты для реверс-инжиниринга человеческого мышления. Тогда и транскрипты, и промпты, и все прочие ухищрения окажутся лишь временными мерами, а настоящий интеллект откроется не как результат программирования, а как побочный эффект взлома самой природы познания.
Оригинал статьи: https://arxiv.org/pdf/2602.15859.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-20 05:30