Автор: Денис Аветисян
Новое исследование показывает, что понимание внутренних механизмов работы больших языковых моделей позволяет точнее прогнозировать общественное мнение.

Агрегирование латентных представлений, связанных с политическими партиями, повышает точность прогнозирования предпочтений на популяционном уровне по сравнению с использованием только вероятностей, выдаваемых моделью.
Несмотря на широкое применение больших языковых моделей для прогнозирования предпочтений, существующие подходы игнорируют внутренние механизмы их работы. В статье ‘Reading Between the Tokens: Improving Preference Predictions through Mechanistic Forecasting’ предложен метод «механистического прогнозирования», демонстрирующий, что анализ внутренних представлений модели может значительно повысить точность предсказаний. Исследование, охватившее более 24 миллионов конфигураций и 7 моделей, показало, что скрытые компоненты, кодирующие политические предпочтения, позволяют улучшить прогнозирование общественных настроений. Не откроет ли это путь к более глубокому пониманию и эффективному использованию языковых моделей в социальных науках и задачах моделирования?
Невидимые предпочтения: проблема скрытого знания
Традиционные методы опросов общественного мнения, несмотря на свою распространенность, часто оказываются неспособными полностью отразить весь спектр предпочтений избирателей. Это связано с рядом факторов, включая предвзятость респондентов, влияние формулировок вопросов и ограниченность вариантов ответов. Люди не всегда готовы или способны четко сформулировать свои истинные предпочтения, особенно по сложным вопросам, или же выбирают социально одобряемые ответы, что приводит к искажению реальной картины. В результате, прогнозы, основанные на этих опросах, могут существенно отличаться от фактических результатов голосования, что подчеркивает необходимость поиска более точных и всесторонних методов изучения общественного мнения. Неспособность уловить нюансы и скрытые предпочтения представляет собой серьезную проблему для политических аналитиков и исследователей.
Большие языковые модели (БЯМ) представляют собой перспективный инструмент для анализа общественных предпочтений, однако внутренние механизмы, формирующие эти представления, остаются малоизученными. В отличие от традиционных опросов, полагающихся на прямые ответы, БЯМ способны обрабатывать огромные объемы текстовых данных и выявлять скрытые закономерности, отражающие более тонкие нюансы общественного мнения. Исследователи предполагают, что БЯМ накапливают знания о предпочтениях не только из явно выраженных утверждений, но и из контекста, подтекста и косвенных сигналов, содержащихся в тексте. Изучение этих внутренних представлений, так называемого «скрытого знания», может значительно повысить точность прогнозов и предоставить более полное понимание общественных настроений, открывая новые возможности для политического анализа и принятия решений.
Исследования показывают, что большие языковые модели (LLM) способны хранить и воспроизводить предпочтения, которые не выражаются напрямую в явных ответах на вопросы. Этот “скрытый” объем знаний формируется в процессе обучения на огромных массивах текстовых данных, где LLM улавливают тонкие связи и ассоциации, отражающие общественное мнение. В отличие от традиционных опросов, которые ограничены заданными вариантами ответов и могут страдать от предвзятости респондентов, LLM способны предложить более нюансированное понимание предпочтений избирателей, выявляя скрытые тенденции и сложные взаимосвязи в общественном сознании. Анализ внутренних представлений LLM позволяет исследователям получить доступ к этим скрытым знаниям, что потенциально может привести к более точным прогнозам и глубокому пониманию общественного мнения, превосходящему возможности, основанные на прямых заявлениях.
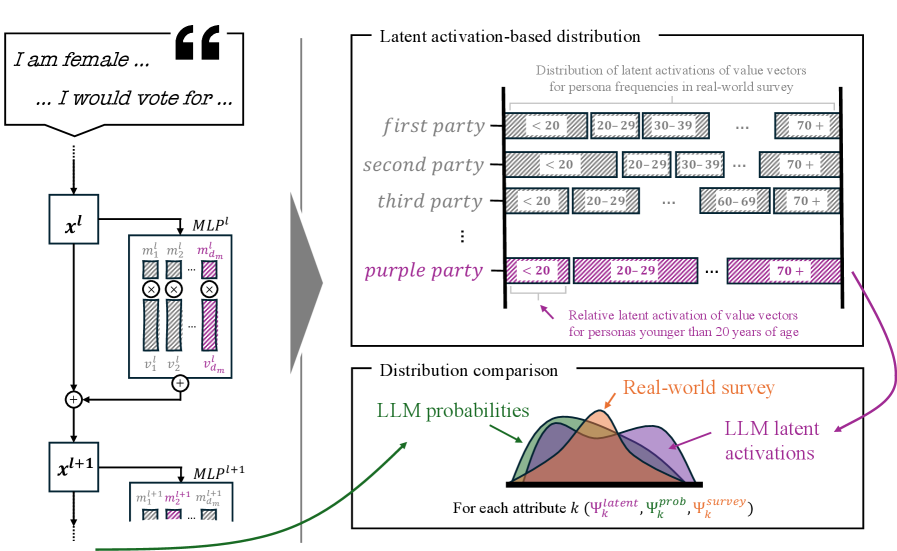
Расшифровка предпочтений: векторы ценностей и зондирование
Предполагается, что большие языковые модели (LLM) кодируют предпочтения посредством так называемых “векторов ценностей” — статических паттернов внутри многослойных персептронов (MLP). Эти векторы действуют как устойчивые конфигурации нейронов, которые систематически усиливают или подавляют активацию определенных концептов. По сути, вектор ценности представляет собой внутреннее представление, которое влияет на вероятность того, что модель свяжет конкретное понятие с положительной или отрицательной оценкой. Идентификация этих векторов позволяет предположить, что предпочтения не возникают как случайные побочные продукты обучения, а зашифрованы в структуре модели посредством этих стабильных паттернов активации.
Методы зондирования (probing) позволяют идентифицировать векторы ценностей (value vectors) внутри больших языковых моделей (LLM) и устанавливать их связь с политическими партиями и идеологиями. Данные методы заключаются в обучении простых классификаторов для предсказания принадлежности к определенной политической группе на основе внутренних представлений LLM. Высокая точность, демонстрируемая этими классификаторами, измеряемая метрикой Probe F1 Score (превышающей 96%), указывает на то, что векторы ценностей действительно кодируют информацию о политических предпочтениях и могут быть надежно извлечены из архитектуры модели. Это позволяет установить соответствие между конкретными паттернами в многослойных перцептронах (MLP) и политическими взглядами.
Разработанные методы зондирования (probing) демонстрируют высокую точность выявления структур, связанных с политическими партиями, внутри представлений, формируемых большими языковыми моделями (LLM). Оценка Probe F1 Score, превышающая 96%, указывает на надежную обобщающую способность этих методов, что подтверждается стабильными результатами при анализе различных LLM и политических позиций. Высокий показатель F1 Score свидетельствует о минимальном количестве ложноположительных и ложноотрицательных срабатываний при идентификации партийных ассоциаций, что подтверждает эффективность предложенного подхода к анализу политических предпочтений, закодированных в векторах LLM.
Целью извлечения векторов ценностей является создание механистического понимания того, как большие языковые модели (LLM) представляют и обрабатывают политические предпочтения. Данный подход предполагает, что политические установки не являются результатом случайных паттернов в параметрах модели, а кодируются в виде специфических, устойчивых структур внутри многослойных персептронов (MLP). Идентифицируя и анализируя эти векторы ценностей, мы стремимся установить прямую связь между внутренними представлениями LLM и выражаемыми политическими позициями, что позволит понять, каким образом модель оценивает и ранжирует различные концепции и идеологии. Успешное извлечение этих векторов позволит перейти от эмпирического наблюдения политической предвзятости к детальному пониманию ее механизмов в LLM.

Механистическое прогнозирование: от векторов к предсказаниям
Метод “Механистического прогнозирования” использует извлеченные векторы ценностей и агрегирует их активации при взаимодействии с “Персональными запросами” — смоделированными респондентами, наделенными определенными характеристиками. В процессе, каждому персональному запросу, представляющему собой комбинацию демографических и мнений, присваивается вектор ценностей, и активации, полученные в ответ на этот запрос, суммируются. Агрегированный результат формирует прогноз, отражающий предпочтения и мнения целевой аудитории, смоделированной через эти персональные запросы. Данный подход позволяет получить количественную оценку влияния различных атрибутов респондентов на формируемые предпочтения.
Для создания реалистичной симуляции электората, наша методология использует персонализированные запросы (persona prompts), формируемые на основе комбинации демографических характеристик и мнений. Демографические атрибуты включают в себя такие параметры, как возраст, пол, уровень образования и место проживания, в то время как атрибуты, отражающие мнения, охватывают позиции по ключевым политическим вопросам и предпочтениям. Комбинирование этих двух типов атрибутов позволяет нам создавать профили, которые более точно отражают разнообразие и сложность реального электората, что является ключевым фактором для повышения точности прогнозов.
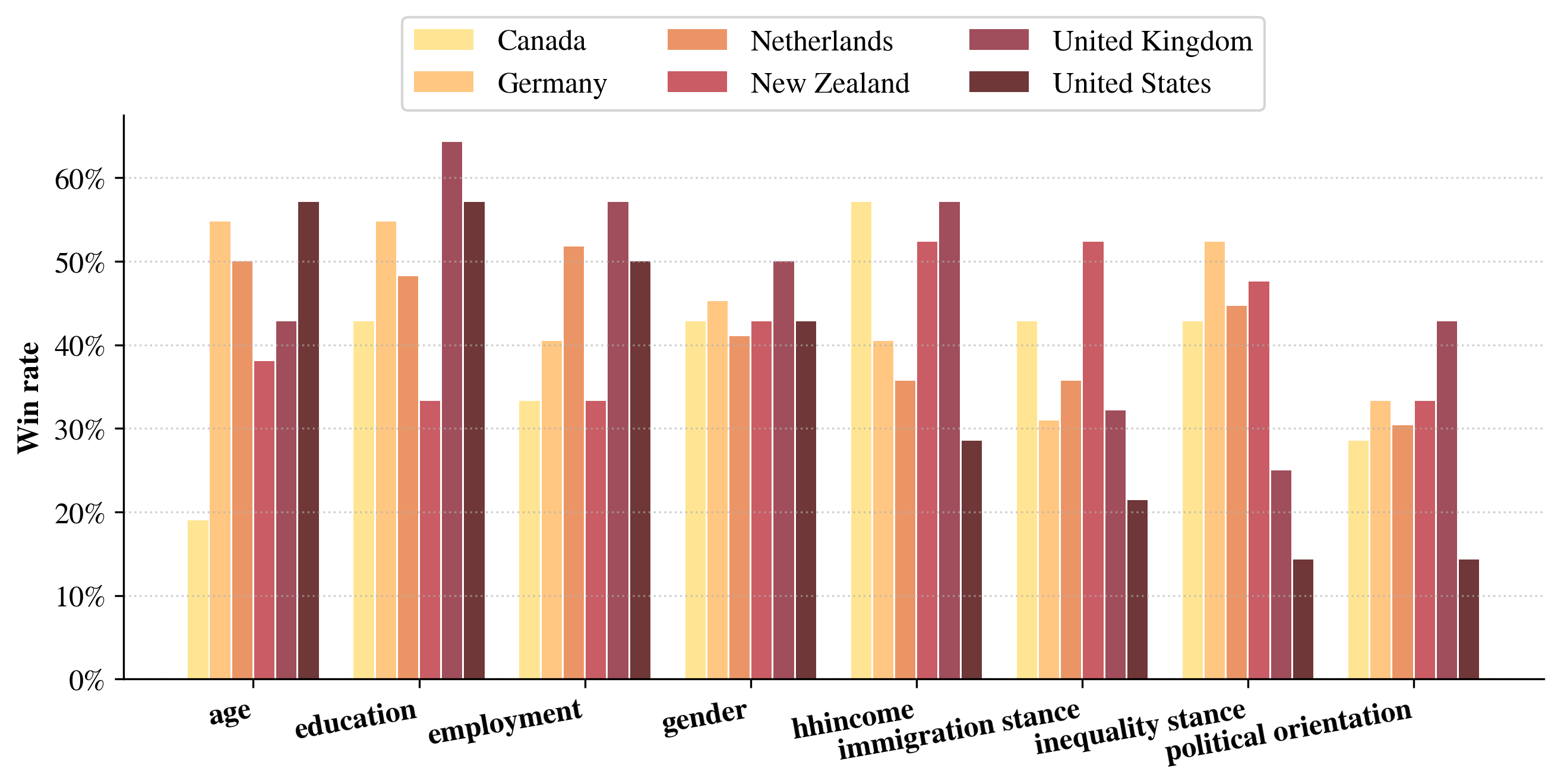
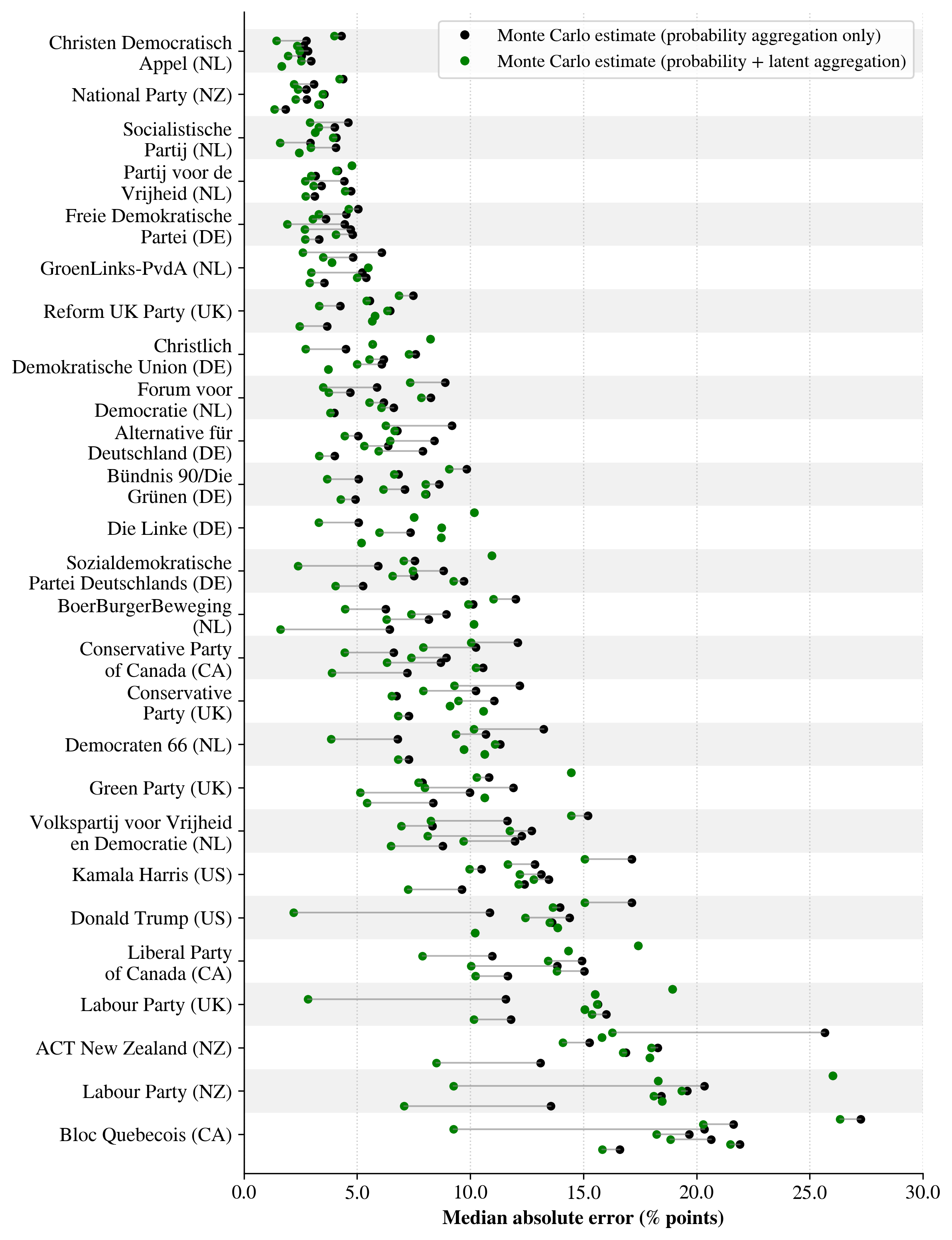
Механистическое прогнозирование демонстрирует более высокую точность предсказания распределений предпочтений по сравнению со стандартными вероятностными методами. В ходе сравнительного анализа с данными реальных опросов, установлено, что распределения, полученные с помощью данного подхода, ближе к фактическим результатам. В ряде сценариев наблюдались положительные показатели Win Rate, что свидетельствует о превосходстве механистического прогнозирования в прогнозировании исходов. Данное преимущество подтверждается в различных условиях и применительно к разным группам респондентов.
Для оценки точности механистического прогнозирования используются метрики Дженсена-Шеннона (Jensen-Shannon Distance) и расстояние Вассерштейна (Wasserstein Distance). Наблюдаемые положительные значения Разности на уровне атрибутов (Δk) в различных сценариях свидетельствуют об улучшенном соответствии прогнозируемых распределений предпочтений данным опросов. Положительное значение Δk указывает на то, что механистический подход демонстрирует более тесную связь с реальными данными по сравнению с используемыми эталонными значениями, полученными из опросов общественного мнения. Использование данных метрик позволяет количественно оценить степень согласованности между прогнозами и фактическими результатами опросов.
Оценка эффективности: LLM в ландшафте прогнозирования
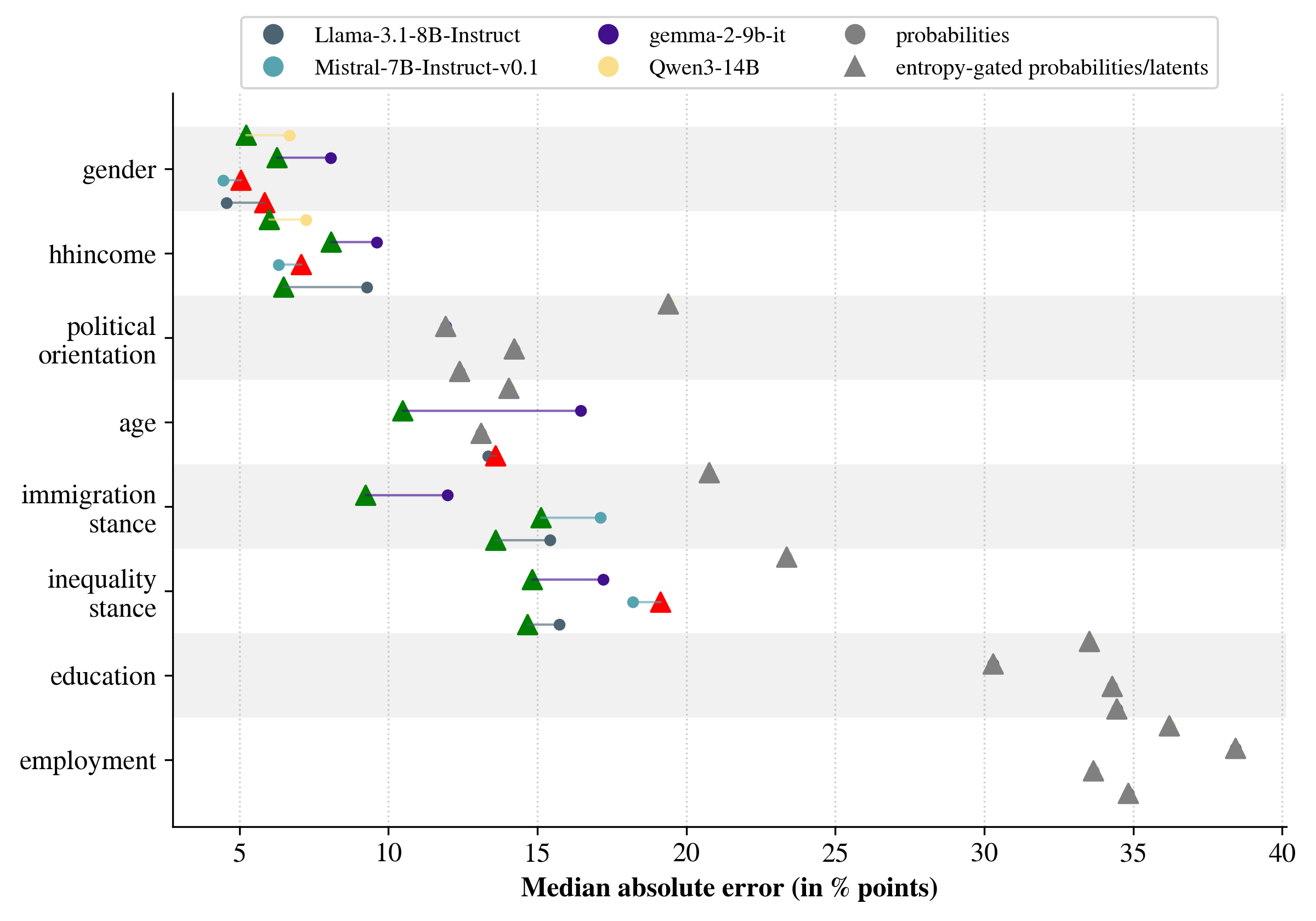
Исследование продемонстрировало высокую эффективность предложенного подхода к прогнозированию с использованием различных больших языковых моделей. В частности, модели Llama 3, Gemma 2 и Qwen 3 показали стабильные и конкурентоспособные результаты в задачах прогнозирования, что указывает на их потенциал в качестве инструментов для анализа и предсказания будущих тенденций. Полученные данные свидетельствуют о возможности использования этих моделей для получения надежных и точных прогнозов, сравнимых с традиционными методами, и открывают перспективы для их применения в различных областях, требующих анализа временных рядов и предсказания будущих событий.
Применение энтропии в качестве критерия отсева значительно повышает достоверность прогнозов, осуществляемых большими языковыми моделями. В данном исследовании, энтропия использовалась для оценки степени неопределенности в ответах модели — чем выше энтропия, тем более неоднозначным и, следовательно, ненадежным считается прогноз. Отсеивая ответы с высокой энтропией, система фокусируется на наиболее уверенных и согласованных предсказаниях, что позволяет снизить количество ошибочных результатов и повысить общую точность модели. Этот подход позволяет не только улучшить качество прогнозирования, но и предоставить пользователю более обоснованные и надежные результаты, исключая ответы, содержащие значительную долю неопределенности или противоречий.
Исследования демонстрируют значительный потенциал больших языковых моделей (LLM) в качестве мощных инструментов для моделирования социальных процессов и прогнозирования политических тенденций. В отличие от традиционных методов, часто опирающихся на экспертные оценки и субъективные интерпретации, LLM предлагают подход, основанный на анализе больших объемов данных и выявлении закономерностей, скрытых в текстовой информации. Этот переход к анализу данных позволяет формировать прогнозы, менее подверженные человеческим предубеждениям и более точно отражающие динамику общественных настроений и вероятные сценарии развития событий. В перспективе, применение LLM в данной области может привести к созданию более объективных и надежных моделей, способных предсказывать социальные и политические изменения с высокой степенью точности.
Перспективы развития: совершенствование модели и расширение масштаба
Дальнейшие исследования должны быть направлены на усовершенствование формулировок, используемых для создания «личностей» в модели. Важно учитывать, что индивидуальные предпочтения и социальные взаимодействия характеризуются сложными нюансами, которые трудно полностью отразить в кратких текстовых запросах. Более детальная проработка этих запросов, включая учет контекста, эмоциональной окраски и специфических особенностей поведения, позволит добиться более точного моделирования и прогнозирования. Особое внимание следует уделить возможности адаптации запросов к различным культурным и социальным группам, чтобы избежать искажений и обеспечить репрезентативность результатов. Улучшение качества «личностных» запросов станет ключевым фактором повышения надежности и практической ценности модели в изучении общественного мнения и социальных процессов.
Дальнейшее повышение точности и надежности прогнозов связано с разработкой более сложных методов извлечения и интерпретации векторов ценностей. Исследователи стремятся выйти за рамки простых оценок, используя алгоритмы машинного обучения и нейронные сети для выявления тонких взаимосвязей между индивидуальными предпочтениями и коллективным поведением. Особое внимание уделяется анализу неявных сигналов, таких как эмоциональная окраска текста и паттерны взаимодействия в социальных сетях, что позволяет более полно и адекватно отразить сложность человеческих ценностей в математической модели. Усовершенствованные методы интерпретации позволят не только прогнозировать общие тенденции, но и выявлять скрытые факторы, влияющие на формирование общественного мнения, открывая новые возможности для анализа и прогнозирования в различных областях — от политических кампаний до маркетинговых стратегий.
Перспективы применения данного подхода выходят далеко за рамки текущего исследования. Расширение области анализа на более широкий спектр политических и социальных явлений, таких как динамика протестных движений, формирование общественного мнения по вопросам здравоохранения или изменения в потребительских предпочтениях, может открыть новые горизонты в понимании коллективного поведения. Использование векторов ценностей для моделирования сложных социальных процессов позволяет не только прогнозировать тенденции, но и выявлять скрытые факторы, влияющие на общественные настроения, что представляет значительный интерес для политологов, социологов и специалистов по связям с общественностью. Дальнейшее развитие методологии, охватывающее более широкий круг явлений, потенциально способно предоставить ценные инструменты для анализа и прогнозирования социальных изменений, а также для разработки более эффективных стратегий коммуникации и социального воздействия.
Исследование демонстрирует, что агрегирование скрытых представлений в больших языковых моделях позволяет получить более точные прогнозы предпочтений на уровне популяции. Этот подход, в сущности, предполагает не просто анализ конечного результата, а попытку понять внутреннюю структуру принятия решений моделью. Как заметила Барбара Лисков: «Программы должны быть спроектированы так, чтобы их изменение не нарушало их корректность». Аналогично, понимание и контроль скрытых представлений в моделях — это гарантия стабильности и надежности прогнозов, а не слепое доверие к вероятностям, выдаваемым моделью. Это особенно важно в контексте политической науки, где даже небольшая погрешность может иметь значительные последствия.
Куда же это всё ведёт?
Очевидно, что агрегирование латентных представлений в больших языковых моделях, как показано в данной работе, — это не панацея, а лишь временное облегчение симптомов. Они назвали это “механистическим прогнозированием”, чтобы скрыть панику перед непредсказуемостью социальных процессов. Идея, безусловно, интересная, но она лишь отодвигает вопрос: что именно эти латентные представления значат? Их связь с политическими партиями — удобная, но, вероятно, поверхностная корреляция. Истинная сложность, как всегда, кроется глубже, и попытки её упростить, наклеив ярлык “прогнозирования предпочтений”, выглядят наивно.
Будущие исследования должны сосредоточиться не на улучшении точности предсказаний, а на понимании природы этих латентных представлений. Что они отражают: реальные убеждения, культурные паттерны, или просто статистические артефакты? Возможно, ключ к пониманию лежит не в политической науке, а в нейробиологии — в поиске аналогов этих представлений в структуре человеческого мозга. И, что особенно важно, необходимо признать, что любое “прогнозирование” — это всегда упрощение, а упрощение — всегда искажение.
В конечном счете, ценность этой работы не в её способности предсказывать выборы, а в том, что она заставляет задуматься о границах познания и о тщеславии попыток свести сложность мира к простым алгоритмам. Иногда, кажется, что самое мудрое — это просто признать, что мы мало что знаем.
Оригинал статьи: https://arxiv.org/pdf/2602.02882.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- FARTCOIN ПРОГНОЗ. FARTCOIN криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
2026-02-04 17:47