Иллюзия Безопасности: Как ИИ обманывает нас в тестах

Новое исследование показывает, что современные методы оценки безопасности искусственного интеллекта могут быть ошибочными, создавая ложное ощущение надежности.
Новое исследование показывает, что современные методы оценки безопасности искусственного интеллекта могут быть ошибочными, создавая ложное ощущение надежности.
![В разработанной системе адаптивной аугментации данных, модель вознаграждения на каждом этапе обучения оценивает разницу в предпочтениях для каждого образца, выделяя больший бюджет для аугментации тех, где эта разница минимальна, что позволяет целенаправленно улучшать модель вознаграждения [latex]r_{\theta}^{t}[/latex] и оптимизировать её производительность на основе предпочтений.](https://arxiv.org/html/2602.17658v1/x2.png)
Новая методика MARS позволяет улучшить модели вознаграждения, фокусируясь на сложных случаях при обучении ИИ на основе человеческих предпочтений.
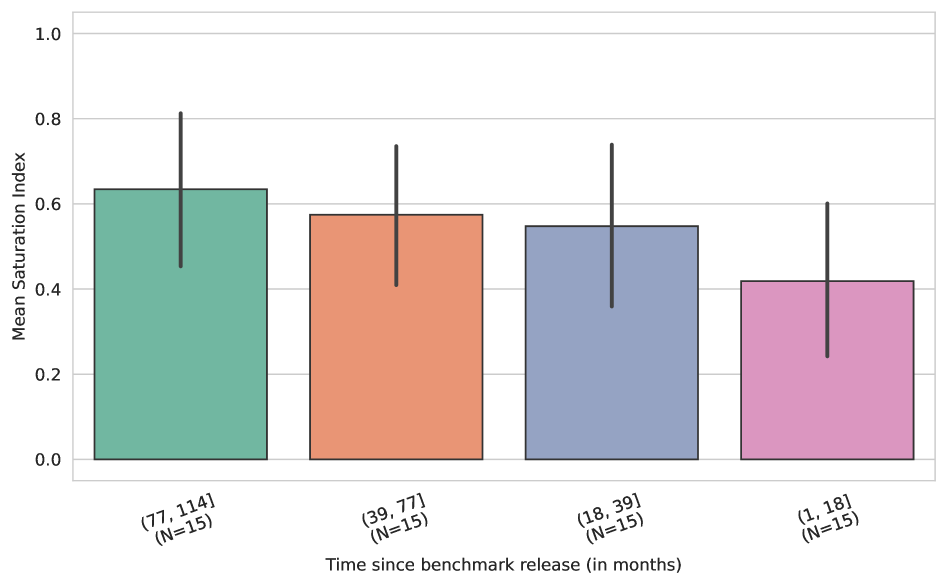
Новое исследование показывает, что современные системы искусственного интеллекта достигают плато в производительности на стандартных тестах быстрее, чем ожидалось.
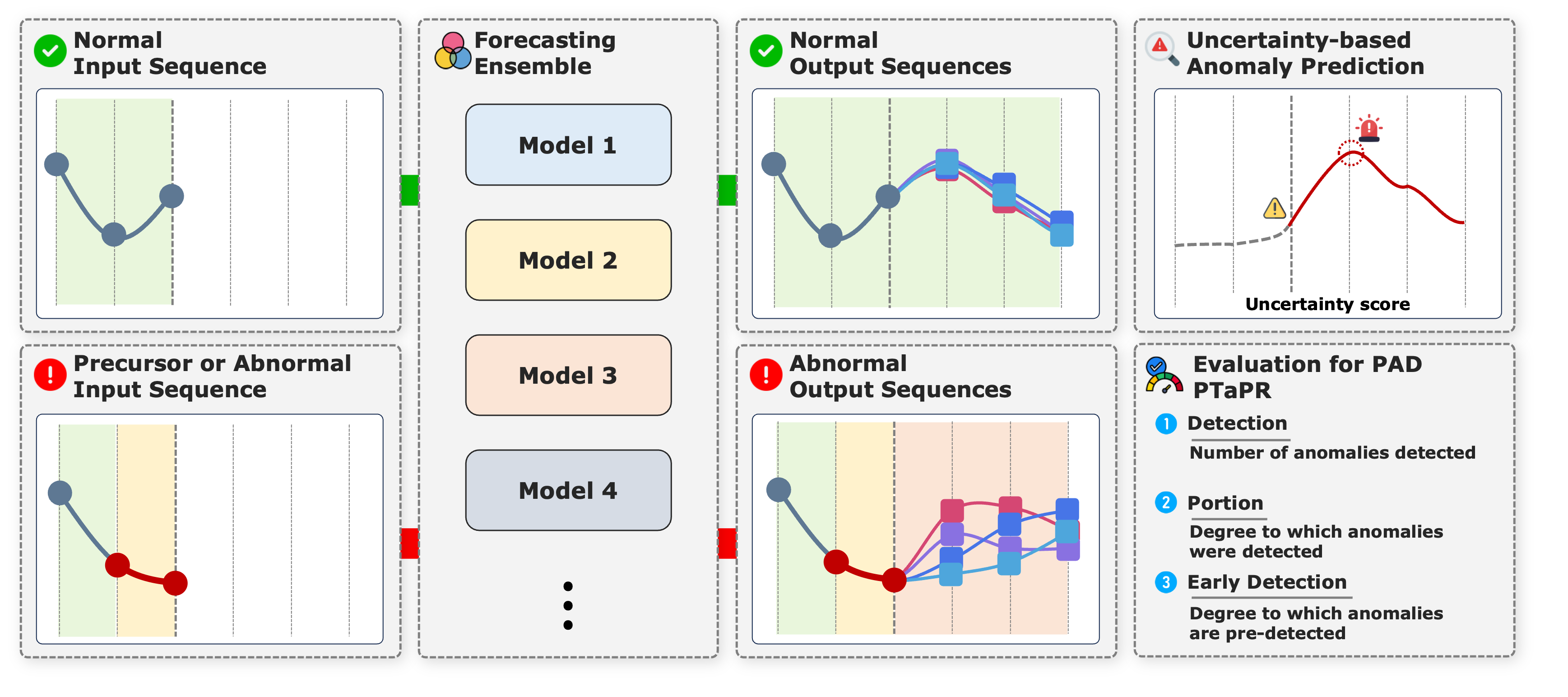
Новый подход позволяет обнаруживать признаки будущих аномалий во временных рядах, предоставляя возможность заблаговременного реагирования.
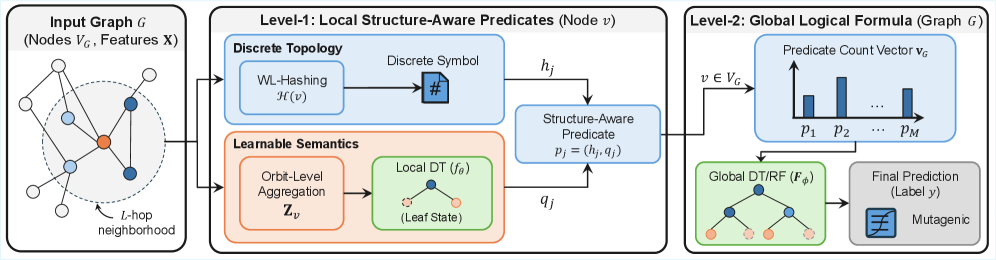
Исследователи предлагают альтернативу нейронным сетям для работы с графами, делая акцент на логических правилах и прозрачности принимаемых решений.