Автор: Денис Аветисян
Исследование выявляет разрыв между академическими подходами и практической реализацией защиты от атак на системы машинного обучения, предлагая новые методы обучения специалистов.
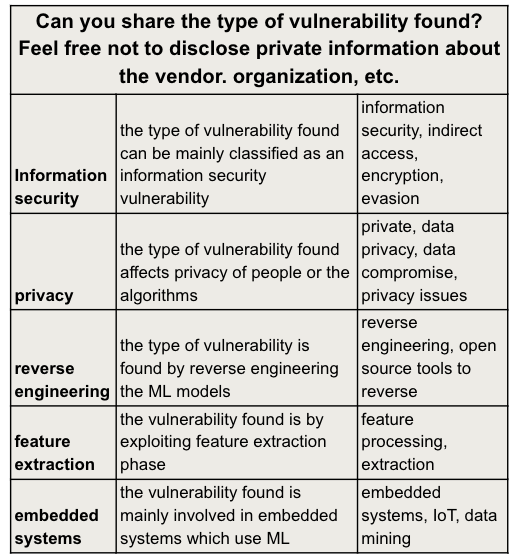
Сравнительный анализ подходов к защите от adversarial machine learning и оценка эффективности образовательных CTF-форматов.
Несмотря на экспоненциальный рост машинного обучения и генеративного искусственного интеллекта, вопросы безопасности, связанные с уязвимостями к атакам типа «состязательное машинное обучение» (AML), остаются недостаточно изученными. В работе ‘Comparative Insights on Adversarial Machine Learning from Industry and Academia: A User-Study Approach’ представлено сравнительное исследование взглядов профессионалов индустрии и студентов на различные угрозы AML и эффективные стратегии обучения. Полученные данные свидетельствуют о прямой корреляции между уровнем кибербезопасности и осознанием рисков, связанных с AML, а также подтверждают эффективность CTF-формата (Capture The Flag) для повышения интереса к данной проблематике. Какие инновационные подходы к образованию в области безопасности машинного обучения позволят эффективно сократить разрыв между теоретическими знаниями и практическими навыками?
Растущая Угроза: Уязвимости в Современных Чат-Ботах
Современные чат-боты, такие как LollyAI, стремительно внедряются в различные сферы жизни — от клиентской поддержки до образования и развлечений. Этот повсеместный рост использования, однако, одновременно расширяет и потенциальную поверхность атаки для злоумышленников. Чем больше систем, основанных на искусственном интеллекте, становятся частью критической инфраструктуры и повседневных взаимодействий, тем важнее становится оценка и усиление их безопасности. Увеличение количества развернутых чат-ботов создает больше возможностей для кибератак, направленных на компрометацию данных, манипулирование информацией или нарушение нормальной работы сервисов. Таким образом, широкое распространение этих технологий требует пристального внимания к вопросам кибербезопасности и разработки эффективных мер защиты.
Современные чат-боты, несмотря на свою полезность, оказываются уязвимыми к атакам, известным как «отравление данных». Суть этих атак заключается в намеренном внесении в обучающую выборку ложной или вредоносной информации. В результате, чат-бот начинает выдавать неверные, предвзятые или даже опасные ответы, что подрывает доверие к системе и ее надежность. Особенно опасны такие атаки в контексте чат-ботов, используемых для предоставления критически важной информации, например, в сфере здравоохранения или финансов, где неточность может привести к серьезным последствиям. Успешное внедрение вредоносных данных в обучающую выборку может быть незаметным для разработчиков, что делает защиту от подобных атак особенно сложной задачей.
Современные чат-боты обучаются на колоссальных объемах данных, полученных из разнообразных источников, что создает существенные трудности в выявлении злонамеренных входных данных. Огромный масштаб и гетерогенность этих данных означают, что даже небольшое количество отравленных примеров может остаться незамеченным, особенно учитывая, что отличить намеренно искаженные данные от обычного шума или ошибок в данных крайне сложно. Автоматические методы обнаружения аномалий часто оказываются неэффективными из-за сложности моделирования нормального поведения чат-бота и необходимости учета контекста и нюансов языка. Таким образом, поддержание целостности и надежности этих систем требует не только совершенствования алгоритмов, но и разработки более сложных и адаптивных стратегий анализа данных, способных эффективно обнаруживать и нейтрализовывать скрытые угрозы.

Расширение Поверхности Атаки: От LollyAI до Bake-time
Первоначальный вектор атаки, продемонстрированный на примере LollyAI, успешно воспроизводится и в последующих чат-ботах, таких как Bake-time Lolly Chatbot. Это подтверждается тем, что один и тот же набор входных данных, приводящих к нежелательному поведению в LollyAI, вызывает аналогичные результаты и в Bake-time, что указывает на общую уязвимость в базовой архитектуре или процессе обработки данных. Успешная эксплуатация в одном приложении напрямую переносится на другое, подтверждая возможность распространения атак между связанными системами.
Успешная эксплуатация уязвимостей в одной платформе, как продемонстрировано с LollyAI, предоставляет злоумышленникам информацию и методы, которые могут быть непосредственно применены к атакам на другие, схожие системы. Этот системный характер угрозы означает, что анализ успешной атаки позволяет выявить общие уязвимости и закономерности, что облегчает разработку и применение эксплойтов против других чат-ботов и платформ, использующих аналогичные архитектуры и данные. По сути, полученные знания о векторе атаки и способах обхода защитных механизмов могут быть повторно использованы, значительно расширяя область поражения и повышая эффективность атак.
Взаимосвязь между платформами, такими как LollyAI и Bake-time, подтверждает возможность перекрестного загрязнения данных в результате атак, основанных на отравлении данных (data poisoning). Успешная эксплуатация одной платформы, приводящая к внедрению вредоносных данных в обучающую выборку, может привести к распространению этих данных на другие системы, использующие схожие или общие источники данных. Это означает, что атака, первоначально направленная на одну платформу, может незаметно повлиять на производительность и надежность нескольких связанных систем, что значительно расширяет радиус поражения и усложняет обнаружение и устранение последствий.
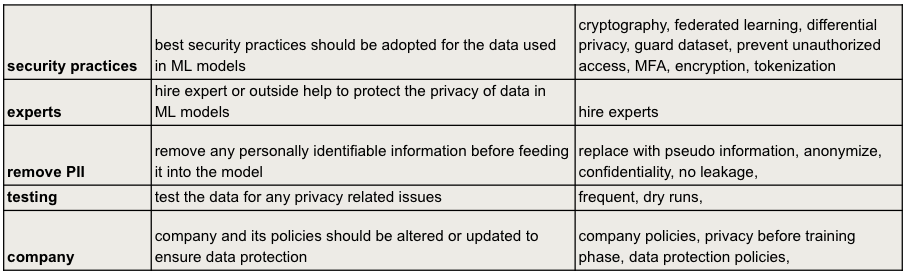
Соединяя Разрозненное: Взгляд Индустрии и Науки
В рамках исследования было проведено пользовательское исследование с целью выявления взглядов представителей индустрии и академической среды на уязвимости к отравлению данных в чат-ботах. Исследование включало сбор данных от специалистов, работающих в коммерческих организациях и научных учреждениях, для оценки их понимания рисков, связанных с атаками на целостность данных, используемых для обучения и функционирования чат-ботов. Полученные данные позволили сопоставить различные подходы к обеспечению безопасности и выявить пробелы в знаниях и практиках в обеих сферах.
Исследование выявило слабую корреляцию между уровнем образования в области кибербезопасности и осознанием важности безопасности в машинном обучении. Коэффициент корреляции Пирсона варьировался от 0.017 до 0.101, что указывает на практически отсутствие связи между формальным образованием в сфере кибербезопасности и пониманием уязвимостей, связанных с безопасностью моделей машинного обучения. Данный результат предполагает, что существующие образовательные программы по кибербезопасности недостаточно охватывают специфические угрозы, связанные с отравлением данных и другими атаками на системы машинного обучения.
Исследование показало умеренную корреляцию (0.6) между предыдущим опытом участия в соревнованиях Capture the Flag (CTF) и предпочтением CTF как инструмента обучения, однако текущие участники CTF не всегда используют их для получения знаний в области защиты от отравления данных (Adversarial Machine Learning — AML). При этом, для определенной группы участников исследования, корреляция между опытом в сфере кибербезопасности и осознанием важности безопасности в машинном обучении оказалась крайне низкой — всего 0.001. Это указывает на разрыв между практическим опытом в кибербезопасности и пониманием специфических угроз, связанных с безопасностью моделей машинного обучения.
Исследование демонстрирует, что разрыв между академическими знаниями и практическими навыками в области Adversarial Machine Learning (AML) достаточно велик. Участники из индустрии, как правило, сталкиваются с более реалистичными угрозами, в то время как академические исследования часто сосредоточены на теоретических атаках. Данная работа подчеркивает необходимость создания образовательных инструментов, таких как CTF-соревнования, для повышения осведомленности и улучшения практических навыков в борьбе с данными угрозами. Как однажды заметил Линус Торвальдс: «Плохой дизайн — это когда что-то сложное кажется простым». Иными словами, кажущаяся простота системы может скрывать уязвимости, особенно в контексте постоянно развивающихся атак, направленных на машинное обучение. Эффективная архитектура безопасности требует четкого понимания всей системы и осознанного выбора приоритетов, а не попыток «залатать» отдельные дыры.
Что дальше?
Исследование выявило закономерную, но печальную истину: граница ответственности между академической теорией и практической безопасностью в области машинного обучения размыта и часто игнорируется. Системы защиты, разработанные в стерильных лабораторных условиях, оказываются хрупкими перед лицом реальных угроз, а специалисты, обученные лишь распознаванию паттернов, оказываются беспомощными перед творческим подходом атакующих. Всё ломается по границам ответственности — если их не видно, скоро будет больно. Очевидно, что необходимо сместить акцент с пассивной защиты на активное обучение и моделирование угроз.
Следующим шагом представляется разработка не просто образовательных курсов, но целых экосистем, имитирующих реальные сценарии атак и защиты. Формат CTF, как показано в данной работе, является перспективным инструментом, однако его необходимо масштабировать и адаптировать к быстро меняющемуся ландшафту угроз, включая новые вызовы, связанные с генеративным искусственным интеллектом и отравлением данных. Структура определяет поведение, и структура образовательного процесса должна отражать структуру реальных атак.
В конечном счете, успех в борьбе с adversarial machine learning зависит не от создания идеальных алгоритмов, а от формирования культуры безопасности, в которой каждый специалист понимает свои обязанности и способен предвидеть слабые места системы. Необходимо признать, что абсолютной защиты не существует, и сосредоточиться на повышении устойчивости и способности к быстрому восстановлению после атак. Простота и ясность — вот ключ к элегантному и надежному дизайну.
Оригинал статьи: https://arxiv.org/pdf/2602.04753.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-05 06:52