Автор: Денис Аветисян
Исследователи предлагают инновационную систему SONAR, способную выявлять дипфейки в аудиозаписях, опираясь на анализ частотных характеристик и контрастное обучение.
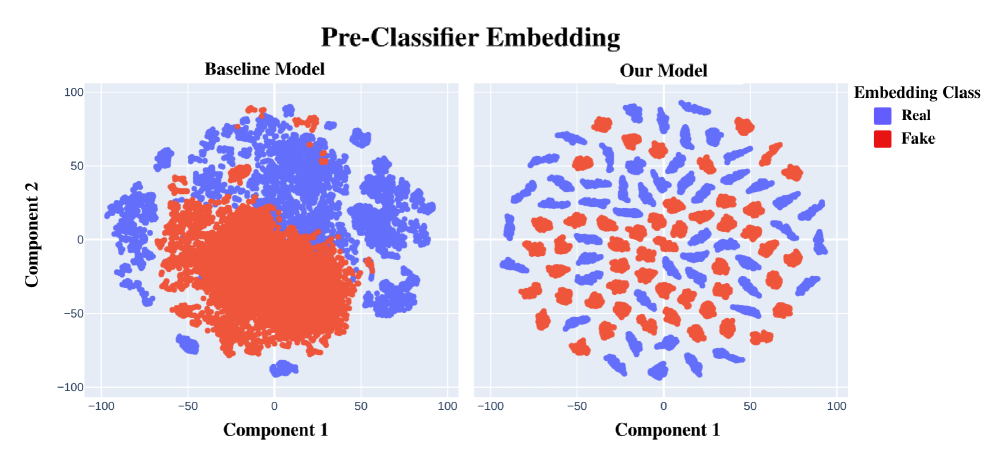
Метод SONAR использует двухпутевую архитектуру и анализ остаточных сигналов в частотной области для эффективного обнаружения аудио-дипфейков, преодолевая ограничения, связанные со спектральным смещением.
Несмотря на значительный прогресс в области обнаружения дипфейковых аудиозаписей, существующие системы часто демонстрируют низкую обобщающую способность при работе с данными, отличными от тренировочных. В данной работе, представленной под названием ‘SONAR: Spectral-Contrastive Audio Residuals for Generalizable Deepfake Detection’, предлагается новый подход, основанный на частотно-ориентированном представлении аудиосигнала и контрастивном обучении. Ключевая идея заключается в разделении сигнала на низко- и высокочастотные компоненты, что позволяет более эффективно выявлять артефакты, создаваемые генераторами дипфейков. Способен ли предложенный метод SONAR открыть новые горизонты в разработке надежных и универсальных систем обнаружения дипфейков в различных аудиоприложениях?
Разоблачение Иллюзий: Введение в Эпоху Синтетических Медиа
Современные достижения в области генеративного искусственного интеллекта открывают возможности для создания аудио-дипфейков, поразительно реалистичных и трудноотличимых от подлинных записей. Данное явление представляет собой серьезную угрозу для безопасности и доверия в цифровом пространстве, поскольку позволяет злоумышленникам имитировать голоса отдельных лиц с целью манипулирования, обмана или дискредитации. Успехи в алгоритмах машинного обучения, особенно в области генеративно-состязательных сетей (GAN) и нейронных сетей, позволяют создавать дипфейки с высокой степенью правдоподобия, преодолевая ограничения, существовавшие ранее. Это создает риски для различных сфер, включая политику, финансы, правоохранительные органы и личную жизнь граждан, требуя разработки эффективных методов обнаружения и защиты от подобных манипуляций.
Традиционные методы обнаружения дипфейков сталкиваются с существенными трудностями при анализе всё более сложных и разнообразных синтетических созданий. Изначально разработанные для выявления артефактов в контролируемых лабораторных условиях, эти алгоритмы часто оказываются неэффективными при работе с реальными данными. Современные генеративные модели искусственного интеллекта способны создавать дипфейки с высокой степенью реалистичности, имитируя мельчайшие детали голоса и внешности, что затрудняет их распознавание. Неоднородность данных, полученных из различных источников и подверженных различным видам обработки, еще больше усложняет задачу, поскольку алгоритмы, обученные на одном типе данных, могут давать сбои при анализе других. В результате, существующие системы обнаружения дипфейков часто демонстрируют низкую точность и высокую частоту ложных срабатываний при применении в реальных сценариях, что подрывает доверие к цифровой информации и требует разработки принципиально новых подходов к обнаружению подделок.
Проблема обнаружения дипфейков значительно усугубляется распространением так называемых «диких данных» — аудио- и видеоматериалов, полученных не в лабораторных условиях, а из реального мира. В отличие от тщательно контролируемых образцов, используемых для обучения алгоритмов, дипфейки, циркулирующие в сети, часто характеризуются низким качеством, шумами, различной степенью сжатия и другими артефактами, присущими реальным условиям записи. Это приводит к тому, что существующие методы обнаружения, разработанные для «чистых» дипфейков, демонстрируют существенно более низкую эффективность при анализе реальных данных. Сложность заключается в том, что алгоритмам необходимо различать манипуляции, внесенные в аудио- или видеоматериал, от естественных изменений, вызванных условиями записи и передачи данных, что требует разработки новых, более устойчивых и адаптивных методов анализа.
Сохранение целостности цифровой коммуникации становится критически важным в эпоху стремительного развития технологий создания дипфейков. Эффективное обнаружение поддельных аудио- и видеоматериалов необходимо для предотвращения злонамеренного использования, которое может варьироваться от распространения дезинформации и манипулирования общественным мнением до нанесения ущерба репутации отдельных лиц и организаций. Отсутствие надежных методов выявления дипфейков подрывает доверие к цифровым источникам информации, создавая угрозу для демократических процессов и стабильности общества. Разработка и внедрение передовых технологий обнаружения, способных адаптироваться к постоянно меняющимся методам создания подделок, является ключевой задачей для обеспечения информационной безопасности и защиты от потенциальных злоупотреблений.

SONAR: Гармония Частот и Разоблачение Подделок
Предлагаемый подход SONAR реализует анализ аудиосигналов посредством двухканальной (Dual-Path) архитектуры. В отличие от традиционных методов, рассматривающих только содержимое аудио, SONAR одновременно обрабатывает как сам аудиоконтент, так и характеристики фонового шума. Такой подход позволяет более эффективно выявлять несоответствия, возникающие при синтезе или модификации аудиозаписей, поскольку манипуляции часто проявляются в различиях между содержательной частью сигнала и его шумовыми компонентами. Двухканальная структура обеспечивает параллельную обработку этих компонентов, что повышает скорость и точность анализа.
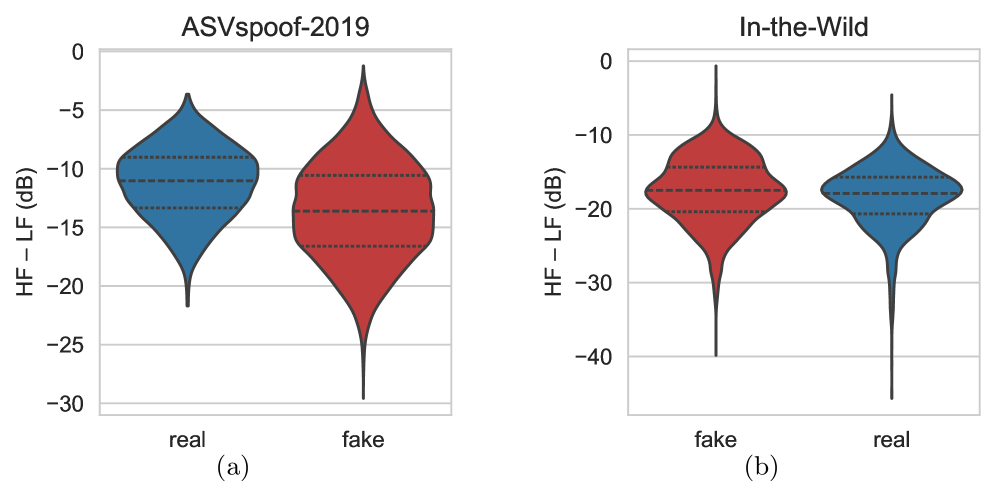
В основе SONAR лежит использование фильтров Spectral Residual Modulation (SRM) для выделения высокочастотных остатков ($Spectral\,Residuals$). Эти остатки формируются после удаления основных спектральных компонентов аудиосигнала и содержат артефакты, возникающие при манипулировании звуком. В частности, синтетические или отредактированные аудиозаписи часто демонстрируют аномалии в высокочастотном диапазоне, проявляющиеся в виде неестественных шумов или искажений, которые SRM-фильтры эффективно выделяют для дальнейшего анализа и обнаружения подделок.
В основе работы SONAR лежит обучение с использованием контрастивного анализа частотных характеристик (Frequency-Contrastive Learning). Этот метод предполагает обучение модели отличать признаки, характерные для реальных аудиосигналов, от тех, которые возникают при синтезе или манипулировании звуком. В процессе обучения модель получает пары данных: аутентичные фрагменты и их искусственно измененные аналоги. Цель обучения — минимизировать расстояние между представлениями аутентичных фрагментов и максимизировать расстояние между представлениями аутентичных и синтезированных данных в пространстве частотных признаков. Такой подход позволяет SONAR более эффективно выявлять различия между подлинными и сгенерированными аудиозаписями, повышая точность обнаружения дипфейков.
Принцип выравнивания контента и шума является основополагающим в работе SONAR, позволяя выявлять несоответствия между этими компонентами в дипфейках. В поддельных аудиозаписях часто наблюдается рассогласование между исходным речевым сигналом и добавленным шумом, обусловленное особенностями алгоритмов синтеза. SONAR анализирует спектральные характеристики как речевого контента, так и фонового шума, выявляя аномалии в их взаимосвязи. Несоответствия могут проявляться в виде нереалистичных изменений спектральной плотности, асинхронности между компонентами или неестественных переходов. Выравнивание контента и шума позволяет SONAR эффективно обнаруживать эти артефакты, повышая точность идентификации дипфейков.
Усиление SONAR: Расширенные Представления и Функции Потерь
Система SONAR использует модель XLSR (Cross-Lingual Speech Representation) для извлечения детализированных акустических признаков из речевых сигналов. XLSR представляет собой предварительно обученную нейронную сеть, способную создавать векторные представления речи, устойчивые к различным акцентам и языкам. В основе XLSR лежит архитектура Transformer, позволяющая эффективно моделировать временные зависимости в аудиоданных. Эти представления служат входными данными для последующих этапов системы, обеспечивая высокую точность распознавания и верификации голоса, а также устойчивость к шумам и искажениям. Модель XLSR обучена на большом объеме многоязычных данных, что позволяет ей обобщать и эффективно работать с различными языковыми вариациями.
В системе SONAR интегрирована проверенная временем система защиты от подделок аудио AASIST, которая обеспечивает надежную базовую производительность. AASIST зарекомендовала себя как эффективное решение для обнаружения поддельных аудиозаписей, используя комплексный анализ акустических характеристик. Интеграция AASIST в архитектуру SONAR позволяет использовать ее существующие возможности и оптимизированные алгоритмы, сокращая время разработки и обеспечивая высокую степень точности обнаружения подделок. Использование устоявшегося и проверенного решения, такого как AASIST, также способствует повышению надежности и стабильности системы SONAR в различных условиях эксплуатации.
В системе SONAR для обучения используется функция потерь, основанная на расхождении Йенсена-Шеннона ($JSD$). Эта функция потерь эффективно минимизирует расстояние между представлениями реальных пар «контент-шум» в латентном пространстве, одновременно максимизируя расстояние между представлениями фальсифицированных пар. $JSD$ измеряет сходство между двумя вероятностными распределениями и, в контексте SONAR, позволяет системе различать аутентичные и поддельные аудиозаписи, основываясь на их представлении в латентном пространстве, полученном с помощью модели XLSR. Минимизация $JSD$ способствует формированию кластеров для реальных данных и их разделению от фальсификатов.
В SONAR анализ проводится в частотной области для преодоления ограничений методов, подверженных эффекту маскировки низкими частотами и спектральному смещению. Традиционные методы, оперирующие непосредственно с временными сигналами, могут быть неэффективны при наличии доминирующих низкочастотных шумов, которые маскируют важные признаки речи. Анализ в частотной области позволяет выделить и акцентировать ключевые частотные компоненты, повышая устойчивость системы к шумам и искажениям, а также снижая предвзятость, возникающую из-за неравномерного распределения энергии в спектре аудиосигнала. Такой подход позволяет более точно извлекать характеристики, необходимые для обнаружения подделок и повышения надежности системы.

Влияние и Перспективы: Эволюция Обнаружения Дипфейков
Экспериментальные результаты демонстрируют, что разработанная система SONAR достигает конкурентоспособной производительности в обнаружении дипфейков. В ходе тестирования на датасете DF система показала уровень ошибки первого рода и ложного пропуска (Equal Error Rate, EER) в 1.45%, что свидетельствует о высокой точности идентификации поддельных материалов. При оценке на более сложном и реалистичном датасете In-the-Wild, включающем данные, полученные из открытых источников и подверженные различным искажениям, SONAR сохранила высокую эффективность, достигнув EER в 5.43%. Эти показатели подтверждают способность системы надежно выявлять дипфейки даже в условиях, приближенных к реальным сценариям использования, и делают её перспективным инструментом для борьбы с распространением дезинформации.
Предложенная система SONAR демонстрирует высокую устойчивость к разнообразным атакам и сохраняет точность даже при анализе данных, полученных в реальных условиях, так называемых «In-The-Wild» данных. Это означает, что разработанный подход способен эффективно выявлять дипфейки не только в контролируемых лабораторных условиях, но и в сложных сценариях, где изображения и видео подвергаются различным искажениям, шумам и манипуляциям, характерным для реального мира. Такая надежность достигается за счет комплексного анализа частотных характеристик и выравнивания контента с шумом, что позволяет системе эффективно различать подлинные и сфабрикованные изображения даже при наличии сложных артефактов и помех, обеспечивая тем самым более надежную защиту от все более изощренных дипфейков.
Исследования показали, что разработанная система SONAR демонстрирует значительно более высокую скорость обучения по сравнению с существующими методами обнаружения дипфейков. В то время как традиционным алгоритмам требуется около 100 эпох для достижения сопоставимых результатов, SONAR способен обеспечить аналогичный уровень точности всего за 4-6 эпох обучения. Такая ускоренная сходимость обусловлена эффективной архитектурой и оптимизированными алгоритмами, что позволяет существенно сократить время и вычислительные ресурсы, необходимые для развертывания и обновления системы в условиях постоянно развивающихся угроз. Это делает SONAR особенно привлекательным для практического применения в сценариях реального времени, где важна оперативность и адаптивность.
Несмотря на значительное повышение эффективности в обнаружении дипфейков, разработанная система SONAR демонстрирует лишь незначительное увеличение времени обработки — всего 15-25% по сравнению с базовой моделью XLSR, использующей один поток данных. Это означает, что, сохраняя высокую точность и устойчивость к различным атакам, система не требует существенного увеличения вычислительных ресурсов или задержки в реальном времени. Такой баланс между производительностью и скоростью обработки делает SONAR перспективным решением для практического применения в системах безопасности и верификации, где важна как надежность, так и оперативность.
Исследование демонстрирует, что анализ в частотной области и выравнивание контента с шумом играют ключевую роль в эффективном обнаружении все более изощренных дипфейков. Традиционные методы, фокусирующиеся исключительно на пространственной области, часто оказываются уязвимыми перед манипуляциями, сохраняющими визуальное качество, но изменяющими частотные характеристики. Предложенный подход позволяет выявлять несоответствия в частотном спектре, возникающие при создании дипфейков, а также учитывать взаимосвязь между содержанием и шумом, что повышает устойчивость к различным атакам и улучшает точность обнаружения даже при анализе данных, полученных в реальных условиях. Таким образом, данная работа подчеркивает необходимость перехода к более глубокому анализу частотных характеристик и структуры шума для создания надежных систем защиты от дипфейков.
Дальнейшие исследования в области системы SONAR сосредоточены на расширении её возможностей для анализа мультимодальных данных, объединяя обработку как аудио-, так и видеоинформации. Такой подход позволит значительно повысить надежность выявления дипфейков, поскольку позволит учитывать несоответствия не только в визуальном, но и в звуковом контенте. Кроме того, планируется разработка адаптивных стратегий обучения, способных реагировать на постоянно меняющиеся методы создания дипфейков. Эти стратегии будут направлены на непрерывное совершенствование модели и поддержание её эффективности перед лицом новых, более изощренных угроз, обеспечивая устойчивую защиту от манипуляций с контентом.
Исследование, представленное в статье, демонстрирует стремление к глубокому пониманию внутренних механизмов аудиосигналов, подобно попытке взлома сложной системы. Авторы, фокусируясь на частотном анализе и контрастивном обучении, не просто обнаруживают подделки, но и раскрывают структуру, по которой создаются манипуляции. Как заметил Роберт Тарьян: «Любая достаточно сложная система, рано или поздно, будет взломана.» Эта фраза особенно точно отражает подход, реализованный в SONAR — систему, которая, моделируя взаимосвязь между низко- и высокочастотным контентом, стремится не только к обнаружению аномалий, но и к пониманию принципов их создания, что является ключом к будущей защите от всё более изощрённых подделок.
Куда же дальше?
Предложенная система SONAR, безусловно, демонстрирует изрядную изобретательность в обходе спектральных предубеждений, что является хронической проблемой в области обнаружения аудио-подделок. Однако, следует признать: разоблачение артефактов, связанных с частотным содержанием — это лишь один винтик в сложной машине обмана. Успешное моделирование взаимосвязи между низкими и высокими частотами — это, конечно, прогресс, но он не гарантирует неуязвимости перед новыми, более изощренными методами генерации. По сути, это постоянная гонка вооружений.
Наиболее интересным направлением представляется отказ от фокусировки исключительно на спектральных характеристиках. Вместо этого, необходимо обратить внимание на более тонкие, нелинейные искажения, которые могут возникать в процессе синтеза речи или манипулирования звуком. Разработка методов, способных выявлять эти «шероховатости» в аудиопотоке, может оказаться более перспективной, чем дальнейшая оптимизация спектрального анализа. Иными словами, пора копать глубже — искать следы несовершенства в самой ткани звука.
В конечном итоге, SONAR — это лишь очередной шаг на пути к созданию универсального детектора подделок. И этот путь, похоже, бесконечен. Ведь, как известно, любой замок можно взломать — вопрос лишь времени и изобретательности взломщика. И данная работа, скорее, подталкивает к поиску новых, более изощренных методов обмана, чем предлагает окончательное решение проблемы.
Оригинал статьи: https://arxiv.org/pdf/2511.21325.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ЗЛОТОМУ
2025-11-29 00:58