Автор: Денис Аветисян
Новое исследование показывает, что алгоритмы, основанные на обучении с подкреплением, способны создавать эффективные стратегии коммуникации даже в условиях неполной информации.
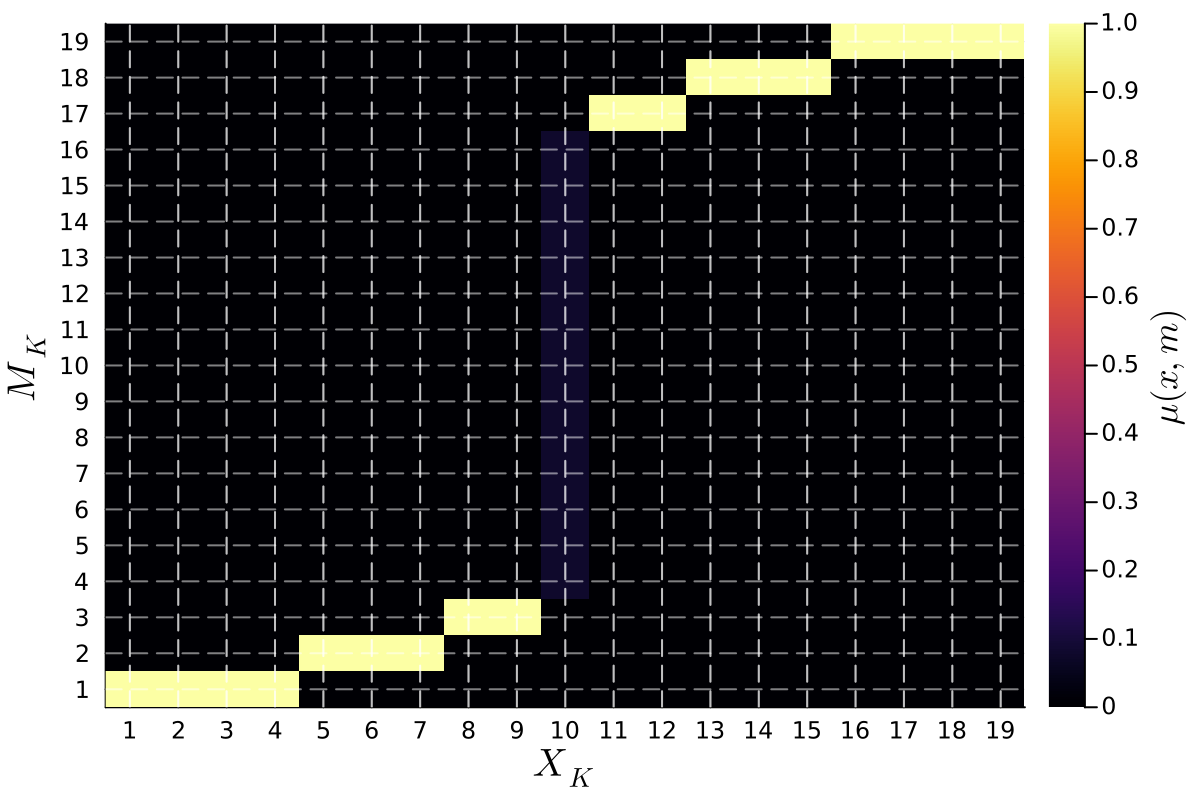
Анализ показывает, что алгоритмические стратегии общения превосходят статические равновесные решения и обеспечивают надежную передачу информации.
В традиционных моделях стратегической коммуникации предполагается полная рациональность отправителя, что не всегда соответствует реальности. В работе ‘The Algorithmic Advantage: How Reinforcement Learning Generates Rich Communication’ анализируется ситуация, когда советник использует алгоритмы обучения с подкреплением для формирования сообщений. Показано, что такое обучение может приводить к устойчиво информативным коммуникациям даже при отсутствии изначально информативной стратегии, а в условиях несовпадения интересов — поддерживать циклы, превосходящие по эффективности любые статические равновесия. Какие новые возможности для анализа и оптимизации коммуникационных процессов открывает применение алгоритмов обучения с подкреплением?
Иллюзия Прозрачности в Коммуникации
Традиционные модели коммуникации часто исходят из предположения о полной прозрачности обмена информацией, однако реальные сценарии значительно сложнее. В большинстве ситуаций участники обладают частной информацией, недоступной другим сторонам, и используют стратегическое взаимодействие для достижения собственных целей. Это означает, что передаваемые сообщения не всегда отражают истинные намерения или знания отправителя, а могут быть тщательно сконструированы для влияния на восприятие получателя. Такое несоответствие между заявленным и фактическим содержанием коммуникации является нормой, а не исключением, что существенно усложняет процессы интерпретации и принятия решений. Понимание этой асимметрии информации и стратегического характера общения необходимо для адекватного анализа коммуникативных процессов и прогнозирования их результатов.
В рамках концепции “дешевых сигналов” (Cheap Talk), ученые исследуют ситуации, когда одна сторона обладает информацией, недоступной другой, и пытается передать ее посредством сообщений, не имеющих прямой материальной ценности. Однако, предсказать исход подобного взаимодействия оказывается крайне сложной задачей, поскольку оптимальные стратегии передачи информации зависят от множества факторов и могут быть нетривиальными. Компьютерное моделирование показывает, что даже при использовании оптимальных стратегий, полное раскрытие информации часто оказывается не самым эффективным подходом — в некоторых случаях, частичная или искаженная передача данных может принести больше выгоды взаимодействующим сторонам, демонстрируя, что прозрачность в коммуникации не всегда является наилучшим решением.
Адаптивное Сигнализирование: Обучение на Опыте
В рамках модели «дешевых сигналов» (Cheap Talk Framework) предлагается использование алгоритма Q-обучения (Q-Learning) для динамической оптимизации стратегии сообщений отправителя. Q-обучение, являясь алгоритмом обучения с подкреплением, позволяет агенту (отправителю) адаптировать свою политику сообщений на основе получаемого опыта. Алгоритм формирует таблицу Q-значений, отражающих ожидаемую полезность (reward) от отправки конкретного сообщения в определенном состоянии. Путем итеративного обновления этих значений на основе полученных результатов, отправитель постепенно совершенствует свою стратегию, стремясь максимизировать полезность и эффективно передавать информацию получателю. Это обеспечивает адаптивность к меняющимся условиям и потенциально превосходит эффективность статических равновесий.
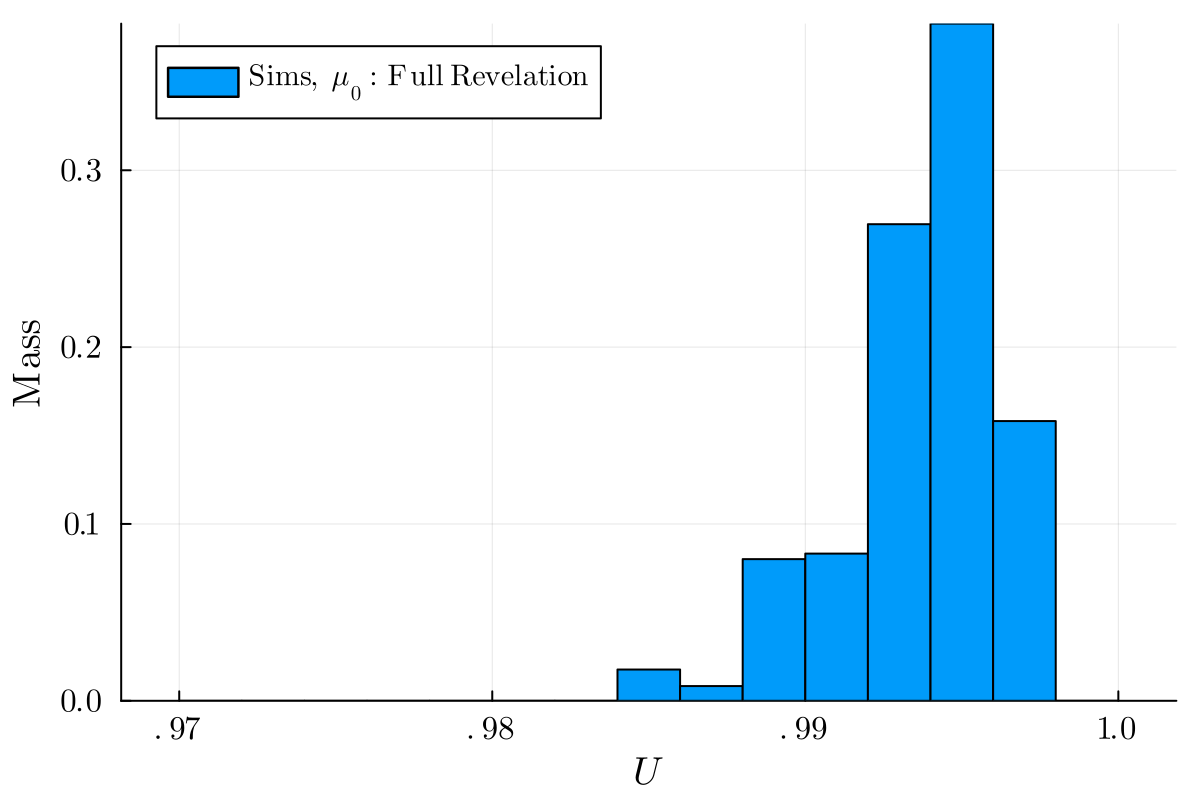
Процесс обучения в рамках предложенного подхода основан на адаптации, управляемой вознаграждением. Успешные сообщения, приводящие к желаемому результату, усиливаются, то есть вероятность их повторной отправки увеличивается, в то время как неэффективные сообщения, не достигающие цели, ослабляются и используются реже. Такой механизм позволяет алгоритму динамически формировать оптимальную стратегию сигнализирования, направленную на достижение показателя благосостояния (welfare ratio) больше 1. Это означает, что предложенный подход способен превзойти по эффективности статические равновесия, характерные для традиционных моделей ‘дешевых разговоров’ (cheap talk).
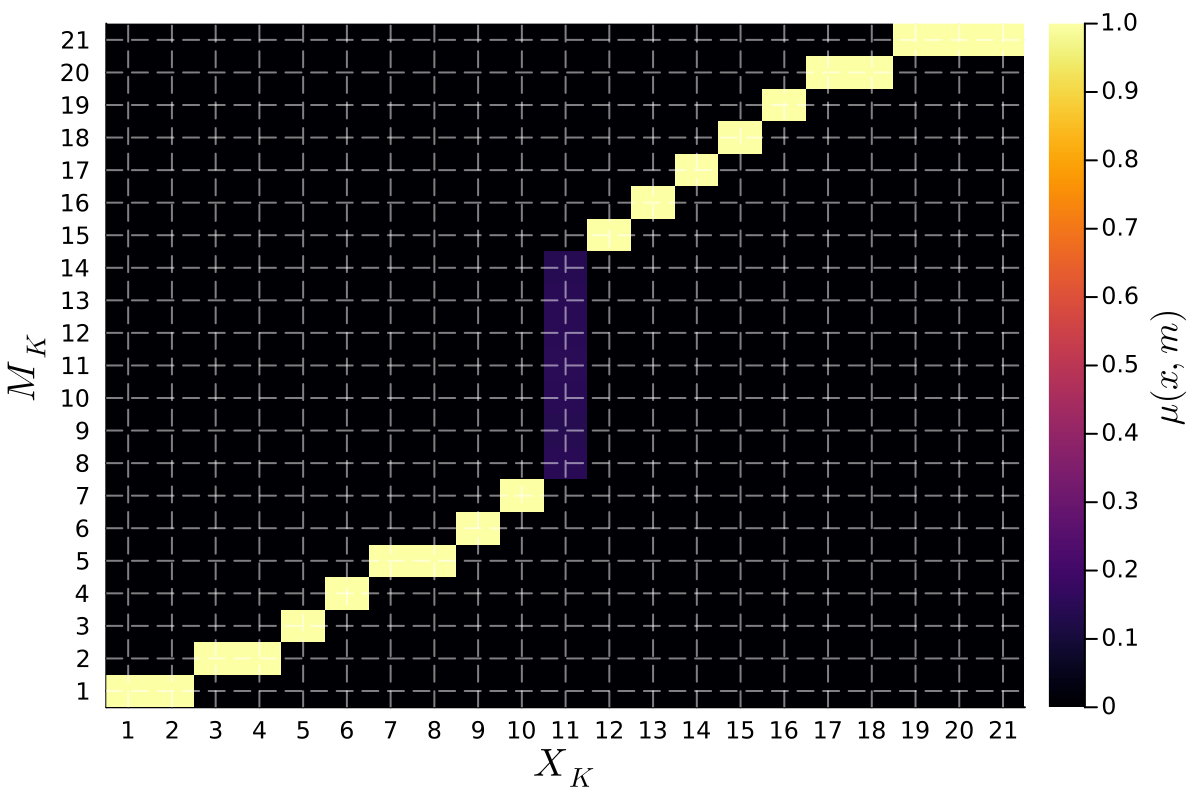
От Стабильности к Цикличности: Политика в Действии
В определенных условиях, обусловленных параметрами модели обучения с подкреплением, сформированная политика сходится к равновесию Кроуфорда-Собеля. Данное равновесие представляет собой статичное решение, при котором отправитель и получатель достигают четкого взаимопонимания относительно передаваемой информации. В этом состоянии отправитель выбирает стратегию сообщений, а получатель — стратегию интерпретации, которые максимизируют их общую выгоду при заданных ограничениях. Важно отметить, что такое равновесие характеризуется неполной информацией, то есть получатель не всегда точно знает истинный тип отправителя или состояние мира, но достигает оптимального решения, учитывая доступную информацию и стратегию отправителя.
Наличие ‘Смещения Предпочтений’ — расхождения интересов отправителя и получателя информации — приводит к дестабилизации равновесия и формированию ‘Циклической Политики’. В данном сценарии, алгоритм Q-обучения не достигает устойчивого решения, а демонстрирует бесконечную последовательность изменений в стратегиях отправки сообщений. Это означает, что отправитель постоянно адаптирует свои сообщения, пытаясь эксплуатировать неполную информацию получателя, в то время как получатель реагирует на эти изменения, что приводит к непрерывному колебанию паттернов коммуникации и невозможности достижения стабильного информационного обмена. Отсутствие согласованности интересов является ключевым фактором, препятствующим конвергенции к равновесию и определяющим динамику циклической политики.
Повышенная скорость исследования (Exploration Rate) в процессе Q-обучения позволяет отправителю информации выявлять и использовать незначительные преимущества в стратегии коммуникации. Однако, это достигается за счет потенциальной нестабильности алгоритма. В условиях отсутствия смещения предпочтений (no-bias case), алгоритм способен достичь не менее 98% от потенциального выигрыша, который мог бы быть получен при полном раскрытии информации. Это указывает на то, что активный поиск оптимальной стратегии, несмотря на риск колебаний, позволяет приблизиться к теоретическому максимуму эффективности коммуникации.
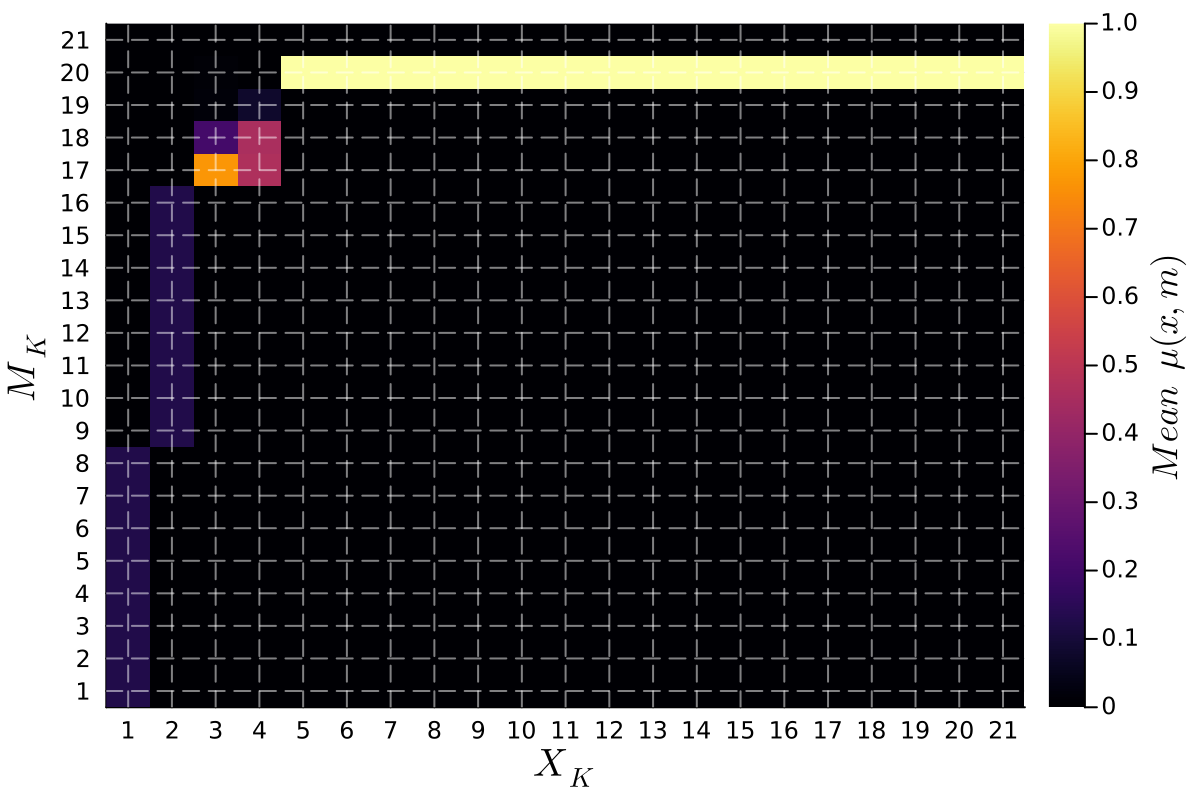
Измерение Успеха Коммуникации: Влияние на Благосостояние
В конечном счете, оценка эффективности коммуникации должна базироваться на показателе, известном как “благосостояние” — суммарной выгоде, полученной как отправителем, так и получателем информации. Данный показатель выходит за рамки простого анализа передаваемых сигналов или точности декодирования. Он учитывает, насколько успешно обмен информацией способствует достижению целей обеих сторон. Более высокий показатель благосостояния свидетельствует о том, что коммуникация не только состоялась, но и принесла ощутимую пользу обоим участникам процесса, что делает его наиболее релевантным критерием оценки эффективности в контексте информационного взаимодействия. Оптимизация коммуникационных стратегий, таким образом, должна быть направлена на максимизацию этого суммарного показателя благосостояния, а не просто на достижение технической точности передачи сообщения.
Исследования показали, что максимизация благосостояния — суммарной выгоды отправителя и получателя информации — может достигаться не только при использовании статических равновесий, таких как равновесие Кроуфорда-Собеля, но и при реализации циклических стратегий. Проведенные симуляции демонстрируют, что отношение благосостояния превышает единицу, что свидетельствует о превосходстве данных подходов над статическими ориентирами. Это указывает на то, что динамические стратегии, адаптирующиеся к изменяющимся обстоятельствам, способны приносить более высокую общую выгоду, чем фиксированные модели коммуникации. Полученные результаты подчеркивают важность учета динамики взаимодействия для оптимизации коммуникационных процессов и достижения максимального благосостояния обеих сторон.
Исследования показывают, что стратегия последовательной передачи сообщений, применяемая к взаимосвязанным состояниям, способствует повышению предсказуемости коммуникации и, как следствие, улучшению общего благосостояния обеих сторон. Когда сообщения используются согласованно в схожих ситуациях, это уменьшает неопределенность для получателя, позволяя ему точнее интерпретировать сигнал и принимать более обоснованные решения. Такой подход, известный как «связанная политика», создает более надежную и эффективную систему обмена информацией, где получатель может опираться на ранее полученные сигналы для прогнозирования будущих. Это, в свою очередь, ведет к более выгодным исходам как для отправителя, так и для получателя, максимизируя совокупную выгоду и демонстрируя превосходство над статичными подходами к коммуникации.
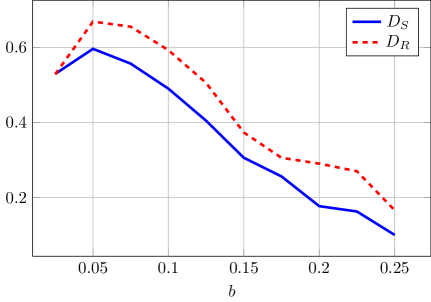
Исследование показывает, что алгоритмы, обученные с помощью обучения с подкреплением, способны формировать коммуникацию, превосходящую статические стратегии. Этот процесс напоминает поиск наиболее эффективного способа передачи информации, даже если она не является абсолютно полной. Как заметил Альбер Камю: «Не надо надеяться на то, что все поймут. Достаточно, чтобы несколько поняли». Подобно этому, алгоритмы не стремятся к идеальной передаче данных, а оптимизируют коммуникацию для достижения конкретных целей, что особенно заметно в контексте Bayesian persuasion, где информация формируется и передается стратегически. Важно понимать, что любое «поведение инвестора» — это просто эмоциональная реакция с хорошим обоснованием, и алгоритмы лишь усиливают эти тенденции, адаптируясь к ним для максимизации вознаграждения.
Куда же это всё ведёт?
Представленные результаты, конечно, демонстрируют, что алгоритмы, обученные с подкреплением, способны к удивительно эффективной коммуникации, даже когда речь идёт о намеренно неполной информации. Но не стоит забывать: алгоритм — это лишь зеркало, отражающее желания и страхи тех, кто его создал. Если целью является максимизация некоего «благосостояния», возникает вопрос: чьего именно? И кто определяет, что это за благосостояние — абстрактный математик или человек, принимающий решение в условиях неопределённости?
Следующий шаг, вероятно, лежит в исследовании не просто эффективности коммуникации, а её психологической правдоподобности. Алгоритмы могут генерировать оптимальные сигналы, но будут ли они восприняты как искренние? Ведь рынки не двигаются — они тревожатся. Именно эта тревога, эта иррациональная составляющая, часто определяет реальное поведение. Понимание этого позволит создать не просто «умные» алгоритмы, а алгоритмы, способные учитывать фундаментальную нерациональность человеческой природы.
В конечном счете, истинный вызов заключается в том, чтобы перейти от анализа формальных моделей к исследованию когнитивных искажений, которые лежат в основе этих моделей. Потому что цифры — это лишь тени, а настоящая реальность — в мотивах тех, кто эти цифры создает.
Оригинал статьи: https://arxiv.org/pdf/2602.12035.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-13 13:30