Автор: Денис Аветисян
Новое исследование показывает, что правильно разработанные метки на теле животных значительно повышают точность автоматической идентификации с использованием алгоритмов машинного обучения.

Оптимизация дизайна отметок на спине свиней для повышения эффективности систем автоматической идентификации на основе компьютерного зрения и методов увеличения данных.
Несмотря на растущий интерес к автоматизированному мониторингу животных, разработка эффективных меток для индивидуальной идентификации, особенно у видов с однородной внешностью, остается сложной задачей. В настоящей работе, ‘Insights on back marking for the automated identification of animals’, исследуется влияние дизайна меток на точность их распознавания алгоритмами машинного обучения. Полученные результаты показывают, что оптимизация дизайна меток с учетом особенностей поведения животных и стратегий аугментации данных, используемых при обучении моделей, таких как ResNet-50, существенно повышает надежность идентификации. Каким образом полученные знания могут быть применены для разработки универсальных принципов создания меток, пригодных для различных видов и условий наблюдения?
Индивидуальная идентификация в животноводстве: вызов точности
Эффективное управление животноводством всё больше зависит от возможности индивидуальной идентификации каждого животного, что необходимо для мониторинга его здоровья и продуктивности. Современные методы позволяют собирать данные о состоянии здоровья, потреблении корма, активности и других важных показателях каждого отдельного животного, а не только о поголовье в целом. Это, в свою очередь, позволяет фермерам принимать более обоснованные решения, направленные на оптимизацию производственных процессов, улучшение благополучия животных и повышение экономической эффективности. Например, своевременное выявление больных животных или отслеживание индивидуальных потребностей в питании может значительно снизить затраты и повысить качество производимой продукции. Таким образом, точная идентификация является ключевым элементом современной системы управления животноводством, обеспечивая переход от реактивного подхода к проактивному и превентивному.
Традиционные методы индивидуальной идентификации сельскохозяйственных животных, основанные на визуальном наблюдении и ручном учете, требуют значительных трудозатрат и характеризуются высокой вероятностью ошибок. Необходимость постоянного мониторинга большого поголовья в условиях динамичной фермы делает эти методы неэффективными и экономически затратными. В связи с этим, в рамках концепции точного животноводства (Precision Livestock Farming) возникла острая потребность в автоматизированных системах, способных точно и непрерывно идентифицировать каждое животное. Такие системы, использующие компьютерное зрение, машинное обучение и другие передовые технологии, позволяют не только снизить трудозатраты и повысить точность учета, но и собирать ценные данные о состоянии здоровья, продуктивности и поведении каждого животного в отдельности, открывая новые возможности для оптимизации управления фермой и повышения ее эффективности.
Точная идентификация сельскохозяйственных животных по визуальным признакам, таким как отметины на спине, играет ключевую роль в современных системах точного животноводства. Однако, надежное распознавание представляет собой сложную задачу, обусловленную динамичностью поведения животных и изменчивостью условий окружающей среды. Непрерывное движение, изменения в освещении, углы обзора камеры и даже естественные деформации шерсти могут существенно искажать визуальные образы, приводя к ошибкам в идентификации. Разработка алгоритмов компьютерного зрения, способных эффективно справляться с этими факторами и обеспечивать высокую точность распознавания даже в сложных условиях, является приоритетной задачей для повышения эффективности управления стадом и оптимизации производственных процессов.

Автоматизация идентификации: компьютерное зрение и машинное обучение
Компьютерное зрение предоставляет возможность автоматизировать идентификацию маркировок на обратной стороне изделий посредством анализа изображений с использованием методов машинного обучения. Этот подход позволяет заменить ручную проверку автоматизированной системой, способной обрабатывать большие объемы данных и повышать точность и скорость идентификации. В основе системы лежит анализ визуальной информации, извлечение признаков из изображений и классификация этих признаков с помощью обученных моделей машинного обучения. Автоматизация процесса позволяет снизить трудозатраты, минимизировать человеческий фактор и обеспечить более надежный контроль качества продукции.
В качестве основной модели для системы была выбрана ResNet-50, глубокая сверточная нейронная сеть, получившая широкое признание за высокую эффективность в задачах классификации изображений. Архитектура ResNet-50, состоящая из 50 слоев, использует «остаточные связи» (residual connections) для решения проблемы затухания градиента при обучении очень глубоких сетей, что позволяет эффективно извлекать и обрабатывать сложные признаки из изображений. Выбор данной модели обусловлен ее способностью к обобщению и высокой точностью, подтвержденной на различных стандартных наборах данных для классификации, что делает ее подходящей основой для автоматической идентификации меток.
Реализация модели базируется на фреймворке глубокого обучения PyTorch, обеспечивающем полный набор инструментов для обучения и развертывания. PyTorch предоставляет динамический граф вычислений, упрощающий отладку и эксперименты с различными архитектурами нейронных сетей. Он также поддерживает автоматическое дифференцирование, необходимое для алгоритмов оптимизации, используемых в процессе обучения. Кроме того, PyTorch предлагает широкую поддержку GPU-ускорения, что критически важно для обработки больших объемов данных изображений и сокращения времени обучения модели. Возможности фреймворка включают в себя инструменты для загрузки и предобработки данных, определения архитектуры модели, выбора функций потерь и оптимизаторов, а также мониторинга и оценки производительности модели.
Первоначальное тестирование системы автоматической идентификации на валидационном наборе данных показало точность классификации 91%, что свидетельствует о перспективности подхода. Однако, при оценке производительности на тестовом наборе, представляющем реальные условия эксплуатации, точность снизилась до 69%. Данное расхождение указывает на потенциальную переобученность модели на валидационных данных и необходимость дальнейшей оптимизации, включая расширение обучающей выборки и применение методов регуляризации для повышения обобщающей способности системы в условиях реальной эксплуатации.
Расширение обучающей выборки: аугментация данных
Для преодоления ограничений, связанных с недостаточным объемом данных, были применены методы аугментации данных, направленные на искусственное увеличение размера и разнообразия обучающей выборки. Данный подход позволил создать дополнительные обучающие примеры путем внесения небольших изменений в существующие изображения, что эффективно расширило набор данных без необходимости сбора новых. Аугментация данных является стандартной практикой в задачах машинного обучения, особенно при работе с ограниченными ресурсами, и способствует повышению обобщающей способности модели и ее устойчивости к вариациям в реальных условиях.
Для увеличения разнообразия обучающей выборки применялись методы увеличения данных, включающие горизонтальное отражение (Flip Augmentation), кадрирование (Crop Augmentation) и изменение цветовых характеристик (Colour Augmentation). Горизонтальное отражение создает зеркальные копии изображений, расширяя вариативность представленных объектов. Кадрирование позволяет модели научиться распознавать объекты в различных масштабах и позициях внутри кадра. Изменение цветовых характеристик, такое как регулировка яркости, контрастности и насыщенности, повышает устойчивость модели к изменениям освещения и цветовой гаммы, встречающимся в реальных условиях эксплуатации.
Применение методов аугментации данных способствует улучшению обобщающей способности модели при работе с ранее не встречавшимися изображениями. Искусственное расширение обучающей выборки за счет модификаций существующих данных, таких как отражения, обрезка и изменение цветовой гаммы, позволяет модели стать менее чувствительной к вариациям в перспективе, композиции и внешнем виде объектов. Это, в свою очередь, повышает устойчивость модели к условиям реального мира, где изображения могут отличаться по освещенности, углу обзора и другим параметрам, не представленным в исходном обучающем наборе.
Исходные данные для обучения модели были получены с камеры видеонаблюдения HIKVISION DS 2CD5046G0-AP. Данная камера использовалась для записи видеоматериала, который затем послужил основой для создания расширенного набора данных посредством методов аугментации. Разрешение и характеристики данной камеры определили исходное качество и детализацию изображений, используемых в процессе обучения. Все последующие преобразования и вариации данных были выполнены на основе этого первичного видеопотока, обеспечивая консистентность и реалистичность расширенного набора данных.
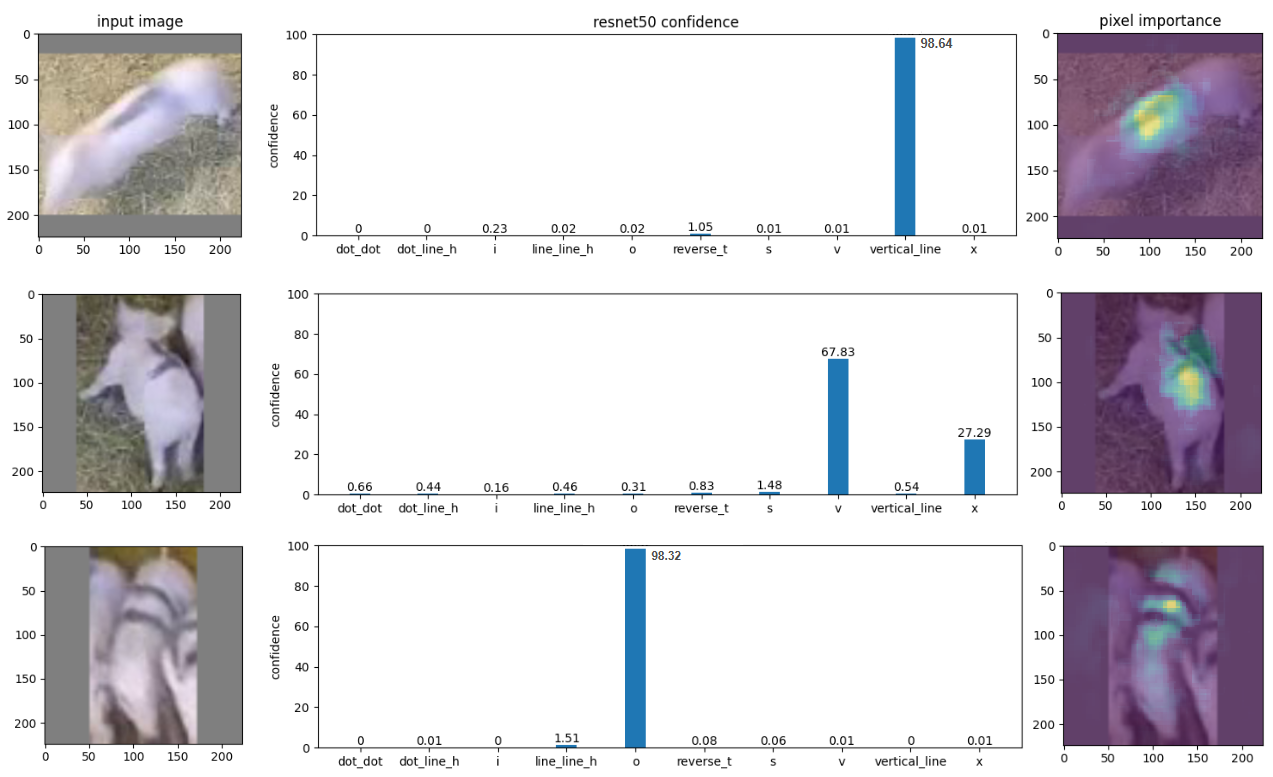
Преодоление сложностей: движение, окклюзия и вариативность поз
Исследование выявило значительные трудности в идентификации отметок на спинах животных в условиях, имитирующих реальные сельскохозяйственные условия. Модель демонстрировала неустойчивую работу при наличии размытия, вызванного движением (motion blur), частичной видимости из-за перекрытия объектов (окклюзии), а также при разнообразных позах животных. Эти факторы существенно снижали точность распознавания, указывая на необходимость разработки алгоритмов, способных эффективно обрабатывать искаженные изображения и учитывать динамику поведения животных в сложных условиях. Неспособность модели стабильно функционировать в условиях, близких к реальным, подчеркивает существующие ограничения современных компьютерных систем зрения в применении к сельскохозяйственным задачам.
Исследования показали значительную разницу в эффективности распознавания различных визуальных маркеров. В частности, паттерн, имеющий форму перевернутой буквы «Т», продемонстрировал низкую точность классификации, составив всего 38% на тестовом наборе данных. В то же время, паттерн, представляющий собой вертикальную линию, показал существенно лучшие результаты, достигнув 88% точности. Данное различие указывает на то, что сложные формы оказываются более чувствительными к помехам и вариациям в изображении, в то время как более простые геометрические фигуры демонстрируют повышенную устойчивость и надежность в условиях реальных сельскохозяйственных сценариев.
Возникающие трудности, связанные с размытием в движении, перекрытиями объектов и разнообразием поз животных, подчеркивают острую необходимость в разработке алгоритмов, устойчивых к реальным искажениям изображений и вариациям поведения животных. Игнорирование этих факторов приводит к существенному снижению точности идентификации, что особенно критично в динамичных сельскохозяйственных условиях. Повышение робастности алгоритмов требует учета не только статических характеристик изображений, но и динамических изменений, вызванных естественным движением и поведением животных, а также способности эффективно обрабатывать частичные перекрытия объектов на изображении. Разработка таких алгоритмов является ключевым шагом к созданию надежных и эффективных систем автоматизированного мониторинга и управления в сельском хозяйстве.
Несмотря на применение методов аугментации данных, результаты работы модели выявили существенные ограничения современных алгоритмов компьютерного зрения в сложных сельскохозяйственных условиях. Проблема заключается не просто в распознавании объектов, но и в их надежной идентификации при наличии помех, таких как размытость движения, перекрытия и вариативность поз животных. Данный факт указывает на необходимость разработки более устойчивых и адаптивных систем, способных эффективно функционировать в реальных полевых условиях, где факторы, влияющие на качество изображения и поведение животных, постоянно меняются. Очевидно, что существующие подходы требуют значительной доработки для обеспечения высокой точности и надежности в практических применениях, связанных с автоматизацией процессов в сельском хозяйстве.
Исследование демонстрирует, что продуманное проектирование меток на спинах животных — ключевой фактор для точной индивидуальной идентификации с использованием машинного обучения. Этот подход особенно важен, учитывая поведение животных и распространенные методы увеличения данных. Как однажды заметил Джеффри Хинтон: «Наши модели — это всего лишь приближения к истине». Эта фраза подчеркивает необходимость тщательной разработки и тестирования систем идентификации, поскольку даже самые передовые алгоритмы могут давать сбои, если данные не подготовлены должным образом или если методология не учитывает реальные условия применения, такие как естественные движения животных и вариации в освещении. Гармоничное сочетание продуманного дизайна меток и надежных алгоритмов машинного обучения создает целостную систему, обеспечивающую высокую точность идентификации.
Куда Ведет Этот Путь?
Представленная работа демонстрирует, что кажущаяся простота маркировки животных — это лишь верхушка айсберга. Элегантность решения, в данном случае, не просто эстетическая категория, а прямое следствие глубокого понимания взаимодействия между дизайном метки, поведением животного и алгоритмами машинного обучения. Небрежно нанесенный знак — крик в цифровом пространстве, шум, который заглушает истинный сигнал. Аккуратность — это не прихоть исследователя, а необходимое условие для достижения гармонии между формой и функцией.
Очевидно, что проблема не ограничивается лишь оптимизацией дизайна самих меток. Необходимо учитывать влияние различных техник аугментации данных, которые, будучи полезными, могут искажать информацию, содержащуюся в изображении. Следующим шагом видится разработка алгоритмов, устойчивых к этим искажениям, или, возможно, создание новых методов аугментации, учитывающих специфику маркировки животных. Простое увеличение количества данных не решит проблему, если сами данные содержат артефакты.
Истинный прогресс потребует междисциплинарного подхода, объединяющего знания в области этологии, компьютерного зрения и машинного обучения. Необходимо не просто научиться идентифицировать животных, но и понимать, как дизайн маркировки влияет на их поведение и благополучие. В конечном итоге, задача состоит не в том, чтобы создать идеальный алгоритм, а в том, чтобы создать систему, которая работает в гармонии с природой.
Оригинал статьи: https://arxiv.org/pdf/2603.25535.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-03-28 00:00