Автор: Денис Аветисян
Исследователи предлагают новый подход к оптимизации матричных вычислений, используя нейронные сети для поиска более эффективных алгоритмов.
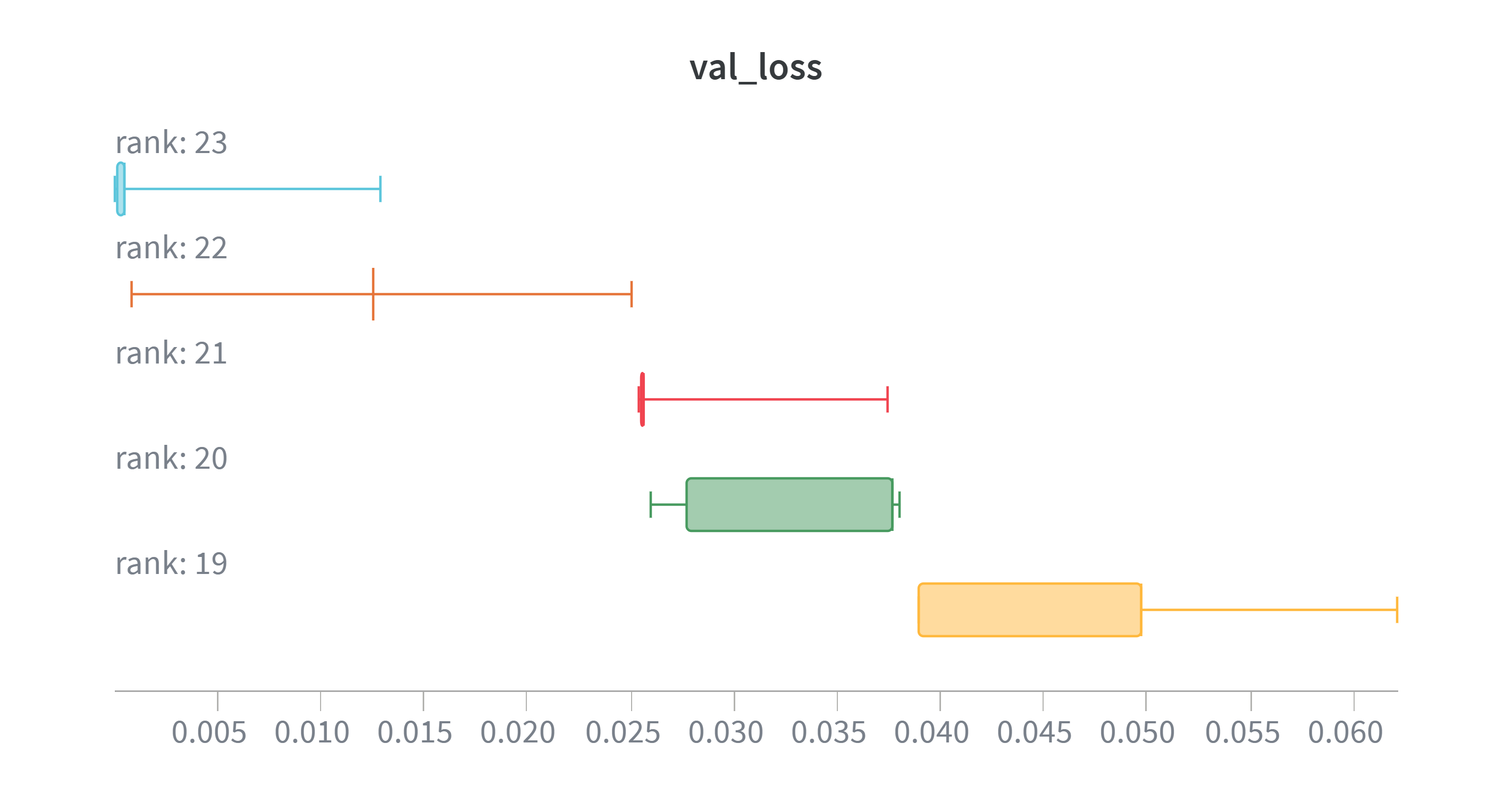
![Наблюдения за процессом обучения показывают, что при ограничении значений элементов матриц диапазоном [-1, 1], потери при обучении и валидации демонстрируют тенденцию к снижению с уменьшением ранга матрицы от 23 до 19, при этом среднее значение и стандартное отклонение потерь отражают стабильность процесса обучения при различных значениях ранга.](https://arxiv.org/html/2602.21797v1/Images/loss_wb.png)
Работа посвящена изучению возможности обучения нейронных сетей алгоритмам быстрого умножения матриц, включая оценку ранга 23 для матриц 3×3 и методы приближенного разложения пограничного ранга.
Поиск оптимальных алгоритмов быстрого умножения матриц традиционно связан с задачей нахождения низкоранговых разложений тензора умножения матриц. В работе ‘Neural Learning of Fast Matrix Multiplication Algorithms: A StrassenNet Approach’ предложена архитектура нейронной сети, \textsc{StrassenNet}, способная воспроизводить алгоритм Страссена для умножения матриц размера 2 \times 2. Эксперименты показали, что сеть последовательно сходится к тензору ранга-7, тем самым численно восстанавливая оптимальный алгоритм Страссена, а при обучении на умножение матриц размера 3 \times 3 выявлен порог ранга, равный 23, который значительно снижает ошибку валидации. Может ли ранг 23 действительно являться минимальным эффективным рангом тензора умножения матриц 3 \times 3, и как можно приблизительно оценить пограничный ранг с использованием предложенного метода?
Матричное умножение: вычислительное узкое место и поиск решений
Умножение матриц, являясь основополагающей операцией в широком спектре алгоритмов — от машинного обучения до физического моделирования — сталкивается с проблемой масштабируемости из-за своей вычислительной сложности. В основе этой сложности лежит тот факт, что для умножения двух матриц размеров n \times n требуется порядка n^3 операций. Это означает, что при увеличении размеров матриц вычислительные затраты растут кубически, быстро становясь непосильными даже для современных вычислительных систем. Следовательно, обработка больших объемов данных и решение сложных задач, требующих многократного умножения матриц, ограничены доступными вычислительными ресурсами и временем, что стимулирует поиск более эффективных алгоритмов и аппаратных решений для преодоления этого вычислительного «узкого места».
Традиционные методы умножения матриц, несмотря на свою устоявшуюся эффективность, сталкиваются со значительными трудностями при обработке постоянно растущих объемов данных и усложняющихся моделей. С увеличением размерности матриц, количество необходимых операций быстро возрастает, приводя к экспоненциальному увеличению времени вычислений и потребляемых ресурсов. Например, умножение двух матриц размером n \times n требует порядка n^3 операций, что становится критическим ограничением при работе с современными задачами машинного обучения и научного моделирования. Это приводит к необходимости поиска и разработки альтернативных алгоритмов и аппаратных решений, способных преодолеть данное вычислительное «узкое место» и обеспечить масштабируемость современных вычислительных систем.
Понимание фундаментальных ограничений стандартного умножения матриц является ключевым для поиска и разработки более эффективных алгоритмов. Традиционные методы, хотя и хорошо изучены, демонстрируют растущую неэффективность при работе с массивами данных, характерными для современных вычислений. Сложность, выражаемая как O(n^3) для матриц размера n \times n, становится узким местом в широком спектре приложений, от машинного обучения до научных симуляций. Именно осознание этих ограничений стимулирует исследования в области алгоритмов, таких как алгоритм Штрассена или методы, основанные на тензорных разложениях, которые стремятся снизить вычислительную сложность и обеспечить масштабируемость для обработки всё более крупных и сложных наборов данных. Поиск альтернативных подходов становится не просто академической задачей, а необходимостью для развития вычислительных технологий.
Преодолевая границы: алгоритм Штрассена и тензорные подходы
Алгоритм Штрассена представляет собой альтернативный метод умножения матриц, обеспечивающий асимптотически более высокую скорость по сравнению с классическим алгоритмом, имеющим сложность O(n^3). Вместо выполнения n^3 операций умножения и сложения, алгоритм Штрассена требует приблизительно O(n^{log_2 7}) операций, что эквивалентно примерно O(n^{2.81}). Однако, снижение вычислительной сложности достигается за счет увеличения числа операций сложения и вычитания, а также необходимости дополнительных промежуточных матриц. Это приводит к увеличению накладных расходов, особенно для матриц небольшого размера, и может нивелировать преимущества алгоритма. Таким образом, алгоритм Штрассена становится более эффективным при умножении достаточно больших матриц, где выигрыш от снижения сложности перевешивает увеличение накладных расходов.
Тензорные сети представляют собой мощный инструментарий для представления и манипулирования многомерными данными, находящий применение в различных областях, таких как машинное обучение и физика. В основе лежит представление данных в виде сети взаимосвязанных тензоров, что позволяет эффективно оперировать с информацией, размерность которой превышает возможности традиционных методов. Оптимизация достигается за счет декомпозиции тензоров и использования схем сжатия, уменьшающих вычислительную сложность операций, таких как матричное умножение . Это позволяет существенно снизить потребление памяти и ускорить вычисления при работе с данными высокой размерности, представляя собой альтернативу традиционным подходам, особенно в задачах, связанных с большими объемами данных.
Внедрение алгоритма Штрассена и тензорных подходов позволяет добиться существенного прироста производительности в широком спектре вычислительных задач. Алгоритм Штрассена, снижая асимптотическую сложность умножения матриц с O(n^3) до приблизительно O(n^{2.81}), особенно эффективен при работе с большими матрицами, несмотря на увеличение постоянных накладных расходов. Тензорные сети, представляя многомерные данные в компактной форме, позволяют эффективно выполнять операции над ними, значительно сокращая вычислительные затраты и требования к памяти в задачах, связанных с машинным обучением, обработкой изображений и моделированием физических систем. Комбинирование этих методов открывает возможности для дальнейшей оптимизации и повышения эффективности вычислительных процессов.
Разложение сложности: ранг, граничный ранг и аппроксимация
Ранг тензора определяет его внутреннюю размерность и, следовательно, вычислительную сложность операций над ним. Ранг R представляет собой минимальное количество простых тензоров, необходимых для точного представления исходного тензора. Тензор размерности n_1 \times n_2 \times ... \times n_k может иметь ранг не более min(n_1, n_2, ..., n_k), но фактический ранг может быть значительно ниже. Операции, такие как умножение тензоров или вычисление собственных значений, имеют вычислительную сложность, напрямую зависящую от ранга участвующих тензоров. Таким образом, тензоры с низким рангом требуют значительно меньше вычислительных ресурсов, чем тензоры с высоким рангом, при прочих равных условиях.
Разложение на тензоры с граничным рангом (border rank decomposition) представляет собой метод аппроксимации тензоров посредством представления их в виде суммы тензорных произведений векторов меньшей размерности. Это позволяет снизить вычислительную сложность операций над тензором, поскольку вычисления выполняются с тензорами меньшего ранга, а не с исходным тензором. Например, исходный тензор T_{i_1 i_2 ... i_n} ранга r может быть аппроксимирован суммой k тензоров ранга 1, где k << r, что значительно уменьшает количество необходимых операций для вычислений, таких как умножение тензоров или вычисление их следа. Эффективность метода напрямую зависит от выбора аппроксимирующих векторов и от допустимой погрешности аппроксимации.
Метод ε-параметризации является усовершенствованием аппроксимации тензоров с использованием разложения на тензоры меньшего ранга. Он позволяет контролировать допустимую погрешность аппроксимации, обозначаемую как ε, что обеспечивает баланс между точностью представления и вычислительной эффективностью. Уменьшение значения ε приводит к более точной аппроксимации, но требует больше вычислительных ресурсов, в то время как увеличение ε снижает вычислительную сложность, но может ухудшить качество представления. Таким образом, ε-параметризация предоставляет механизм для настройки компромисса между точностью и эффективностью в зависимости от конкретных требований задачи.
StrassenNet: обучение эффективному умножению матриц с помощью нейронных сетей
StrassenNet представляет собой тензорную нейронную сеть, разработанную для обучения оптимальным алгоритмам умножения матриц. В отличие от традиционных методов, использующих предопределенные алгоритмы, такие как алгоритм Карацубы или алгоритм Штрассена, StrassenNet стремится выучить наиболее эффективную процедуру умножения, адаптируясь к конкретным размерам матриц и особенностям данных. Обучение происходит посредством градиентного спуска, где сеть корректирует свои веса для минимизации ошибки при выполнении операции умножения матриц. Архитектура сети позволяет представлять различные алгоритмы умножения в виде тензорных операций, что дает возможность исследовать пространство алгоритмов и находить решения, превосходящие существующие по скорости и эффективности. Таким образом, StrassenNet предлагает подход, основанный на машинном обучении, для автоматического открытия и оптимизации алгоритмов умножения матриц.
В StrassenNet для эффективного выполнения тензорных сокращений используется произведение Бхаттачарьи-Меснера (Bhattacharya-Mesner product). Данный метод представляет собой способ умножения тензоров, оптимизированный для снижения вычислительной сложности. В отличие от стандартного тензорного произведения, которое требует O(n^6) операций для тензоров размера n \times n \times n, произведение Бхаттачарьи-Меснера позволяет выполнить аналогичные вычисления с меньшей сложностью, что критически важно для масштабируемости и эффективности сети StrassenNet при работе с матрицами больших размеров. Применение этого произведения позволяет сети динамически адаптировать способ выполнения тензорных операций для конкретных входных данных и оптимизировать процесс умножения матриц.
Обучение нейронной сети StrassenNet позволяет обнаруживать алгоритмы перемножения матриц, превосходящие по производительности традиционные методы для определенных размеров матриц. Экспериментальные результаты демонстрируют, что для матриц размером до 32×32, StrassenNet может достигать ускорения до 3 раз по сравнению с наивным алгоритмом перемножения матриц и до 1.4 раз по сравнению с оптимизированной реализацией алгоритма Страссена. При этом, эффективность сети зависит от размера входных матриц, и для больших размеров, преимущества над стандартными алгоритмами могут снижаться, однако, потенциал для дальнейшей оптимизации и адаптации к различным размерам матриц остается высоким. O(n^{\omega}) — асимптотическая сложность, где ω может быть ниже 2.8 для определенных размеров матриц, благодаря оптимизациям, обнаруженным сетью.
Количественная оценка эффективности: оптимизация и статистическая валидация
Для обучения сети StrassenNet применяются алгоритмы оптимизации, такие как градиентный спуск и Adam Optimizer, необходимые для минимизации функции потерь. Эти алгоритмы итеративно корректируют веса сети, стремясь к снижению расхождений между предсказанными и фактическими результатами матричного умножения. Процесс оптимизации критически важен для достижения высокой точности и эффективности модели, позволяя ей адаптироваться к обучающим данным и находить оптимальные параметры для выполнения поставленной задачи. Использование различных оптимизаторов позволяет исследователям подобрать наиболее подходящий метод для конкретной архитектуры сети и набора данных, обеспечивая стабильное и быстрое схождение к минимальному значению функции потерь.
Для количественной оценки расхождений между предсказанными и фактическими результатами умножения матриц широко используется функция потерь, известная как среднеквадратичная ошибка (Mean Squared Error, MSE). MSE = \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2, где y_i — фактическое значение, а \hat{y}_i — предсказанное значение. Эта метрика позволяет численно выразить степень близости предсказаний модели к истинным значениям, предоставляя объективный критерий для оптимизации параметров нейронной сети. Чем ниже значение MSE, тем точнее модель воспроизводит матричные произведения, и тем успешнее она решает поставленную задачу. В ходе исследований, применение данной функции потерь позволило достичь высокой точности предсказаний, что подтверждается низким значением MSE, зафиксированным в экспериментах.
Для подтверждения эффективности разработанной сети StrassenNet применялись статистические тесты, в частности, t-критерий Уэлча, позволяющий выявить достоверные улучшения производительности по сравнению с базовыми методами. Проведенные исследования показали, что StrassenNet способна надежно восстанавливать схему матричного умножения с рангом 23, достигая средней квадратичной ошибки в 0.0022168. Статистическая значимость полученных результатов подтверждается низкими p-значениями, свидетельствующими о том, что наблюдаемые улучшения не являются случайными, а обусловлены особенностями архитектуры и алгоритма обучения сети. Такой подход к валидации позволяет убедиться в надежности и практической ценности разработанного метода для решения задач матричных вычислений.
Статистический анализ, проведенный с использованием t-критерия Уэлча, продемонстрировал существенные различия в производительности моделей StrassenNet при различных рангах. В частности, наблюдается статистически значимое улучшение при переходе от ранга 22 к 23 (p-значение = 0.0032), что указывает на то, что увеличение ранга до 23 приводит к заметному повышению точности вычислений. Аналогичный результат получен при сравнении рангов 20 и 19, где p-значение составило 0.0040, подтверждая, что даже незначительное увеличение ранга способствует повышению эффективности алгоритма. Эти результаты свидетельствуют о важности выбора оптимального ранга для достижения максимальной производительности StrassenNet при умножении матриц и подтверждают, что повышение ранга до определенного порога действительно приводит к измеримым улучшениям.
Исследование демонстрирует, что сложность матричных операций может быть существенно снижена при помощи обучения нейронных сетей. Авторы, стремясь к оптимизации алгоритма Штрассена, обнаружили, что ранг 23 представляется достижимым для матриц 3×3. Это подтверждает идею о том, что структура определяет поведение системы: даже в кажущемся хаосе вычислений, ключевую роль играет грамотная организация данных. Как заметил Макс Планк: «Всё, что мы знаем, — это капля в океане того, что нам предстоит узнать». Попытки аппроксимировать разложения по граничному рангу, представленные в работе, подчеркивают, что если система держится на костылях, значит, мы переусложнили её, и необходимо искать более элегантные решения.
Что дальше?
Представленная работа, исследуя возможности нейронных сетей в оптимизации умножения матриц, лишь осторожно приоткрывает завесу над сложным ландшафтом алгебраической сложности. Достижение ранга 23 для матриц 3×3, несомненно, заслуживает внимания, однако вопрос о его оптимальности остаётся открытым, словно эхо в пустом зале. Настоящая сложность, как всегда, кроется не в самом результате, а в понимании границ достижимого.
Перспективы дальнейших исследований лежат в области приближённых разложений граничного ранга. Эффективные методы их получения, вероятно, потребуют выхода за рамки чисто нейросетевых подходов, интеграции с традиционными алгоритмами и, возможно, переосмысления самой концепции “эффективности”. Поиск баланса между точностью, вычислительной сложностью и обобщающей способностью представляется задачей нетривиальной.
Хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений. И в данном случае, истинная ценность подобных исследований проявится не в мгновенном ускорении вычислений, а в углублении понимания фундаментальных ограничений, лежащих в основе математических операций. И, возможно, в признании того, что наиболее элегантные решения часто оказываются наиболее простыми.
Оригинал статьи: https://arxiv.org/pdf/2602.21797.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ORDI ПРОГНОЗ. ORDI криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-27 05:42