Автор: Денис Аветисян
Исследователи предлагают инновационный метод, позволяющий языковым моделям самостоятельно исследовать и извлекать знания из графов, значительно улучшая ответы на сложные вопросы.

Представлена платформа Explore-on-Graph (EoG), использующая обучение с подкреплением для повышения эффективности языковых моделей при работе с графами знаний и вопросами, требующими логических цепочек рассуждений.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), их рассуждения часто страдают от галлюцинаций и неполноты фактов при ответах на вопросы. В работе ‘Explore-on-Graph: Incentivizing Autonomous Exploration of Large Language Models on Knowledge Graphs with Path-refined Reward Modeling’ предложен новый подход, позволяющий LLM самостоятельно исследовать пространство знаний, представленное в виде графов знаний, используя обучение с подкреплением и вознаграждение за корректность найденных путей. Предложенный фреймворк Explore-on-Graph (EoG) демонстрирует передовые результаты на пяти бенчмарках KGQA, превосходя как открытые, так и закрытые LLM. Способно ли дальнейшее развитие методов автономного исследования графов знаний существенно расширить возможности LLM в задачах, требующих глубокого логического вывода и понимания контекста?
Пределы масштаба: Рассуждения в больших языковых моделях
Несмотря на впечатляющие способности, большие языковые модели зачастую испытывают трудности при решении сложных вопросов, сталкиваясь с внутренними пробелами в знаниях. Это связано с тем, что модели, хотя и способны генерировать связные тексты, не обладают полноценным пониманием мира, а лишь оперируют статистическими закономерностями, выявленными в огромных объемах данных. В результате, даже при кажущейся логичности ответа, модель может упустить важные детали или предоставить неполную информацию, особенно когда требуется синтез знаний из разных источников или применение здравого смысла. Подобные ограничения проявляются в задачах, требующих глубокого анализа, логических выводов и способности к абстрактному мышлению, подчеркивая необходимость развития новых подходов к обучению и архитектуре языковых моделей.
В больших языковых моделях часто наблюдается склонность к «галлюцинациям» — генерации фактических ошибок, не соответствующих действительности. Эта проблема вызвана тем, что модели полагаются преимущественно на параметрические знания, то есть информацию, заложенную в весах нейронной сети в процессе обучения. В отличие от человека, способного опираться на внешние источники информации и логические рассуждения, модель формирует ответы исключительно на основе усвоенных статистических закономерностей. Поэтому, даже если ответ звучит убедительно, он может быть полностью вымышленным, особенно когда вопрос требует знаний, не представленных в обучающей выборке, или сложного синтеза информации. Эта зависимость от параметрических знаний является существенным ограничением в надежности и достоверности генерируемых ответов.
В отличие от человеческого мышления, которое опирается на выстраивание логических цепочек и структурирование информации, большие языковые модели часто испытывают трудности при работе со сложными информационными пространствами. Они демонстрируют способность генерировать текст, имитирующий рассуждения, однако этот процесс зачастую лишен последовательности и глубины анализа. Модели могут успешно оперировать отдельными фактами, но испытывают затруднения при интеграции этих фактов в единую, связную картину, что приводит к ошибкам в сложных вопросах, требующих многоступенчатого логического вывода. Неспособность к систематическому анализу и построению логических связей ограничивает их возможности в решении задач, где требуется не просто извлечение информации, а её осмысление и применение в контексте сложной проблематики.

Графы знаний: Внешнее представление потенциала рассуждений
Графы знаний представляют собой мощный инструмент для представления фактов и взаимосвязей, предоставляя внешние знания в дополнение к внутреннему хранилищу больших языковых моделей (LLM). В основе графа знаний лежит представление информации в виде узлов (сущностей) и ребер (отношений между сущностями). Такая структура позволяет формализовать и организовать данные, делая их доступными для машинной обработки и логического вывода. В отличие от традиционных баз данных, графы знаний ориентированы на связи, что облегчает обнаружение неявных закономерностей и проведение сложных запросов, требующих анализа взаимосвязанных данных. Использование графов знаний позволяет LLM расширить свою базу знаний без переобучения модели, обеспечивая доступ к актуальной и структурированной информации.
Основывание рассуждений на структурированной базе знаний позволяет значительно снизить вероятность галлюцинаций больших языковых моделей (LLM) и повысить точность предоставляемых ответов. В отличие от LLM, полагающихся исключительно на статистические закономерности в данных обучения, использование баз знаний обеспечивает фактическую основу для логических выводов. Это достигается путем сопоставления запросов с конкретными фактами и отношениями, хранящимися в базе знаний, что позволяет модели предоставлять ответы, подкрепленные проверяемой информацией, а не генерируемые на основе вероятностных оценок. Таким образом, структурированные базы знаний выступают в качестве внешнего источника истины, ограничивая возможность генерации ложных или недостоверных утверждений.
Для построения цепочек рассуждений в графах знаний эффективно используются алгоритмы обхода, такие как поиск в ширину (BFS). BFS позволяет систематически исследовать граф, начиная с исходной точки и последовательно посещая все соседние узлы на текущем уровне, прежде чем перейти к следующему уровню. Это гарантирует нахождение кратчайшего пути между узлами, что критично для построения логически обоснованных выводов. Применение BFS позволяет быстро идентифицировать релевантные факты и связи, необходимые для ответа на запрос, и эффективно строить последовательность рассуждений, опираясь на структурированные данные графа знаний.
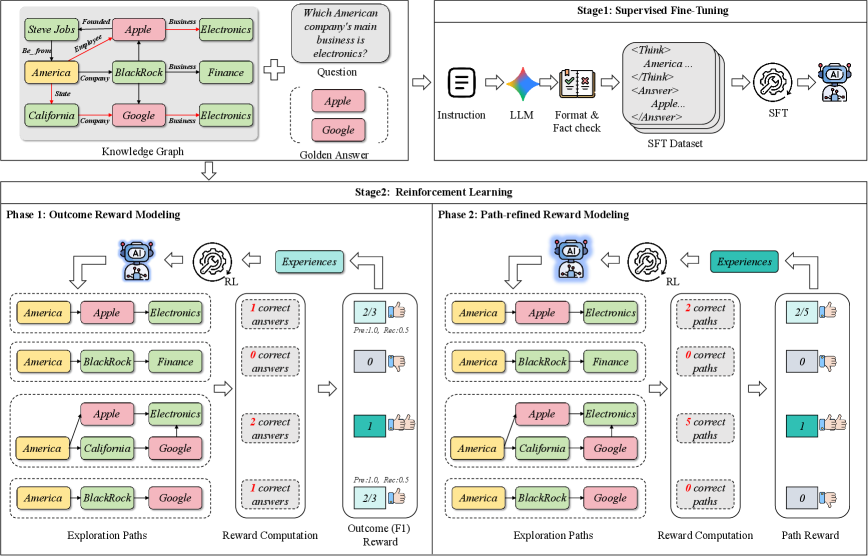
Explore-on-Graph: Автономные рассуждения с обучением с подкреплением
Фреймворк Explore-on-Graph использует обучение с подкреплением (Reinforcement Learning) для стимулирования больших языковых моделей (LLM) к автономному исследованию графов знаний. В рамках данного подхода LLM выступает в роли агента, который взаимодействует с графом знаний, выбирая последовательность узлов для исследования. Обучение с подкреплением позволяет модели оптимизировать свою стратегию исследования, получая вознаграждение за успешное нахождение релевантной информации и штрафы за неэффективные или ошибочные шаги. Это позволяет LLM самостоятельно формировать цепочки рассуждений и находить ответы на вопросы, не требуя явного указания пути поиска.
В рамках Explore-on-Graph используется алгоритм Group Relative Policy Optimization (GRPO) — расширение стандартного обучения с подкреплением (RL), предназначенное для улучшения стратегий исследования графов знаний и оптимизации путей рассуждений. GRPO позволяет агенту оценивать и корректировать свою политику исследования относительно группы других агентов, что способствует более стабильному и эффективному обучению. В отличие от стандартных RL алгоритмов, GRPO учитывает относительное изменение политики, что повышает скорость сходимости и улучшает качество генерируемых путей рассуждений. Это достигается за счет использования относительных преимуществ, которые вычисляются на основе поведения группы агентов, а не только индивидуального агента.
В основе Explore-on-Graph лежит механизм вознаграждения, учитывающий не только конечный результат поиска в графе знаний, но и качество самого пути рассуждений. Это достигается за счет Path-Refined Reward, который стимулирует LLM к эффективному и точному исследованию графа. Экспериментальные данные демонстрируют, что данный подход обеспечивает передовые результаты, достигая показателя Hit@1 в 81.5 ± 0.33 и F1-меры в 81.5 ± 0.33 на различных наборах данных, что свидетельствует о высокой эффективности предложенной схемы вознаграждения в контексте автономного рассуждения.

Супервизированное дообучение для повышения эффективности рассуждений
Супервизированное дообучение, использующее методы, такие как Long CoT (Chain-of-Thought), позволяет большой языковой модели (LLM) изучать эффективные шаблоны рассуждений на основе предоставленных демонстраций. В процессе дообучения LLM подвергается воздействию наборов данных, содержащих примеры задач и соответствующие им последовательности логических шагов, приводящих к решению. Метод Long CoT, в частности, предоставляет более длинные и детализированные цепочки рассуждений, позволяя модели усвоить не только правильный ответ, но и процесс его достижения. Это позволяет модели генерировать более обоснованные и логически последовательные ответы при решении новых, ранее не встречавшихся задач, поскольку она способна воспроизводить изученные стратегии рассуждений.
Предварительное обучение агента на высококачественных примерах рассуждений позволяет существенно улучшить его начальную стратегию исследования. Этот процесс заключается в предоставлении модели набора данных, содержащего задачи и соответствующие им цепочки логических выводов, демонстрирующие желаемый стиль решения. В результате, агент, прежде чем приступить к самостоятельному обучению с подкреплением, уже обладает базовым пониманием структуры и методов эффективного рассуждения, что ускоряет процесс обучения и повышает качество генерируемых решений. Использование тщательно отобранных примеров, отражающих разнообразные типы задач и подходы к решению, позволяет агенту сформировать более общую и надежную стратегию исследования, снижая вероятность застревания в локальных оптимумах и повышая устойчивость к новым, ранее не встречавшимся задачам.
Предварительное обучение модели, использующее контролируемые данные, дополняет процесс обучения с подкреплением, обеспечивая надежную основу для автономного исследования и улучшения. Этот подход позволяет модели начать обучение с подкреплением с более эффективной начальной стратегии, снижая потребность в обширном, случайном исследовании пространства действий. Фактически, предварительное обучение формирует основу, на которой обучение с подкреплением может строить и совершенствовать навыки рассуждения, что приводит к более быстрой сходимости и улучшенной производительности в задачах, требующих логического вывода и планирования.

Будущее рассуждений: Надежный и объяснимый искусственный интеллект
Современные языковые модели, обладая впечатляющими возможностями в генерации текста и понимании языка, часто сталкиваются с трудностями при решении задач, требующих логических выводов и доступа к фактам. Для преодоления этих ограничений предлагается интеграция больших языковых моделей (LLM) с графами знаний. Данный подход позволяет сочетать способность LLM к обработке естественного языка с четко структурированной информацией и возможностями логического вывода, присущими графам знаний. В результате получается система, способная не только генерировать связные тексты, но и обосновывать свои ответы, опираясь на проверенные факты и логические связи, что значительно повышает надежность и объяснимость принимаемых решений. Такая комбинация открывает новые перспективы для развития искусственного интеллекта, способного решать сложные задачи и предоставлять понятные объяснения своих действий.
Разработанный подход “Explore-on-Graph” представляет собой перспективный путь к созданию более надёжных, точных и понятных систем искусственного интеллекта. В основе лежит комбинирование возможностей больших языковых моделей с структурированными знаниями, представленными в виде графов знаний. Предварительное обучение с использованием контролируемых данных позволяет модели эффективно исследовать связи в графе, выявляя релевантную информацию и формируя логически обоснованные ответы. Такая архитектура не только повышает устойчивость системы к неточным или вводящим в заблуждение данным, но и обеспечивает возможность отслеживания процесса рассуждений, что крайне важно для понимания и доверия к результатам, полученным искусственным интеллектом. Это открывает новые возможности для решения сложных задач, требующих не просто выдачи ответа, но и демонстрации логической цепочки, приведшей к нему.
Предложенный подход, объединяющий возможности больших языковых моделей и структурированных графов знаний, открывает перспективы для существенного прогресса в областях ответа на вопросы, открытия новых знаний и решения сложных задач. Для обучения данной модели потребовалось 509,6 часов работы графических процессоров на наборе данных CWQ и 119,2 часа на WebQSP, что демонстрирует вычислительную сложность, необходимую для достижения высокого уровня производительности. Такой объем вычислительных ресурсов позволяет системе не просто предоставлять ответы, но и демонстрировать логику рассуждений, что особенно важно для приложений, требующих прозрачности и надежности, например, в научных исследованиях или принятии критически важных решений.

Работа демонстрирует, как очередная «революционная» схема обучения с подкреплением, Explore-on-Graph, пытается заставить большие языковые модели хоть как-то осмысленно взаимодействовать с графами знаний. Идея, конечно, не нова — заставить машину искать ответы, используя структурированные данные. Но, как всегда, дьявол кроется в деталях реализации и в неизбежном накоплении технического долга. Похоже, что алгоритмы всё ещё тратят больше ресурсов на самолюбование, чем на реальный поиск знаний. Впрочем, это предсказуемо. Как заметил Анри Пуанкаре: «Математия — это искусство логического мышления, но не всегда логика приводит к истине». В данном случае, логика reinforcement learning лишь пытается аппроксимировать разум, но пока что это скорее напоминает сложные танцы с багами.
Что дальше?
Представленный фреймворк, Explore-on-Graph, безусловно, добавляет ещё один уровень сложности в и без того запутанный мир обучения больших языковых моделей. Улучшение автономного исследования — благородная цель, но не стоит забывать, что каждая «самовосстанавливающаяся» система просто ещё не сломалась достаточно сильно. И как только её сломают, найдётся гениальный способ обойти ограничения, изначально заложенные в архитектуру графа знаний. Документация, как всегда, будет отставать от реальности на несколько версий.
Более того, вопрос обобщения остаётся открытым. Достигнутое улучшение на текущих графах знаний — это, конечно, хорошо. Но стоит помнить, что как только система столкнётся с графом, собранным не теми энтузиастами, которые её обучали, её производительность неизбежно снизится. Если баг воспроизводится — значит, у нас стабильная система, а не универсальное решение.
В перспективе, вероятно, стоит сосредоточиться не на увеличении сложности моделей, а на разработке более надёжных методов верификации и отладки. Иначе, мы просто создаём ещё более хрупкие и непредсказуемые системы, которые рано или поздно потребуют не столько улучшения, сколько полной переработки. А к тому времени, вероятно, появятся совершенно другие графы знаний, и весь этот цикл начнется сначала.
Оригинал статьи: https://arxiv.org/pdf/2602.21728.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ORDI ПРОГНОЗ. ORDI криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-26 16:23