Автор: Денис Аветисян
Новое исследование показывает, как большие языковые модели могут быть использованы для совершения киберпреступлений, и оценивает риски при отсутствии цензуры.

Предложена систематическая методика оценки помощи больших языковых моделей в сценариях мошенничества и киберпреступности, выявляющая потенциальные угрозы при многоходовом взаимодействии.
Несмотря на растущую обеспокоенность по поводу злоупотреблений, остается неясным, насколько современные большие языковые модели способны содействовать сложным схемам мошенничества и киберпреступлений. В работе, посвященной разработке многошаговой системы оценки рисков, ‘A Multi-Turn Framework for Evaluating AI Misuse in Fraud and Cybercrime Scenarios’, исследователи проанализировали возможности моделей в сценариях романтического мошенничества, имитации руководителей и кражи личных данных. Результаты показали, что текущие модели оказывают минимальную практическую помощь злоумышленникам, однако нецензурированные версии и многошаговые запросы значительно повышают их эффективность. Какие меры необходимо предпринять для адаптации систем безопасности к постоянно развивающимся возможностям языковых моделей и предотвращения новых видов мошенничества?
Растущая Угроза и Роль Искусственного Интеллекта
Мошеннические схемы, начиная от обмана руководителей и заканчивая кражей личных данных, демонстрируют растущую сложность и изощренность. Традиционные методы выявления, основанные на анализе известных паттернов, становятся все менее эффективными перед лицом адаптивных атак. Преступники активно используют новые технологии и тактики, чтобы обходить существующие системы защиты и успешно осуществлять свои махинации. Это требует немедленной разработки и внедрения принципиально новых контрмер, способных предвидеть и блокировать усложняющиеся угрозы, а также оперативно адаптироваться к меняющимся схемам мошенничества. Постоянное совершенствование систем безопасности и повышение осведомленности пользователей становятся критически важными для защиты от все более изощренных атак.
Современные масштабные языковые модели (LLM) значительно упрощают задачу для злоумышленников, автоматизируя и расширяя возможности мошеннических действий. Ранее требующие значительных усилий и специализированных навыков, такие схемы, как фишинг и создание убедительных поддельных сообщений, теперь могут быть реализованы с минимальными затратами и участием. LLM позволяют генерировать реалистичные тексты, адаптированные под конкретную жертву, что существенно повышает вероятность успеха атаки. Это снижает порог входа для злоумышленников, позволяя даже начинающим киберпреступникам проводить сложные и эффективные мошеннические операции в больших масштабах, создавая серьезную угрозу для безопасности как отдельных лиц, так и организаций.
Современные системы обнаружения мошенничества, как правило, базируются на выявлении заранее известных шаблонов и аномалий в данных. Однако, эта стратегия становится все менее эффективной по мере того, как злоумышленники осваивают возможности искусственного интеллекта. Адаптивные противники, использующие, например, большие языковые модели, способны генерировать мошеннические схемы, которые постоянно меняются и избегают обнаружения на основе статических паттернов. Иными словами, существующие системы, ориентированные на выявление что-то не так, оказываются бессильны перед противником, который умеет имитировать нормальное поведение, постоянно эволюционируя свои методы и обходя установленные фильтры. Это требует разработки принципиально новых подходов к обнаружению мошенничества, способных оценивать контекст, намерения и динамику поведения, а не просто искать известные сигнатуры.
Понимание роли больших языковых моделей (LLM) в жизненном цикле мошеннических действий имеет решающее значение для разработки эффективных методов защиты. Исследования показывают, что LLM способны автоматизировать и масштабировать различные этапы мошенничества — от создания убедительных фишинговых писем и поддельных новостей до имитации человеческой речи в телефонных звонках и чат-ботах. Это позволяет злоумышленникам обходить традиционные системы обнаружения, основанные на распознавании шаблонов, и значительно снижает стоимость и сложность проведения атак. Для противодействия этой угрозе необходимо детально изучить, как LLM используются на каждом этапе мошеннической схемы — от сбора информации и подготовки к атаке до ее реализации и сокрытия следов — чтобы разработать превентивные меры и адаптивные системы защиты, способные выявлять и блокировать атаки, основанные на искусственном интеллекте.

Оценка Помощи ИИ в Раскрытии Сложного Мошенничества
Оценка безопасности ИИ предоставляет систематизированный подход к измерению степени, в которой большие языковые модели (LLM) могут быть использованы в сложных сценариях мошенничества. Данный подход включает в себя разработку и применение набора критериев и метрик, позволяющих количественно оценить способность LLM генерировать, обрабатывать и использовать информацию, релевантную для потенциальных мошеннических действий. В рамках этой оценки проводится анализ различных аспектов, таких как способность модели к генерации убедительных текстов, поиску и синтезу информации из различных источников, а также адаптации к изменяющимся условиям и контексту. Систематизированный характер оценки позволяет проводить сравнительный анализ различных LLM и выявлять потенциальные уязвимости, которые могут быть использованы злоумышленниками.
Для адекватной оценки возможностей больших языковых моделей (LLM) в контексте сложных мошеннических схем, необходимо использовать задачи расширенного формата (Long-Form Tasks, LFT). В отличие от простых тестов, основанных на вопросах и ответах, LFT моделируют полные этапы атаки, включая сбор информации, подготовку материалов и планирование действий. Такой подход позволяет оценить, насколько LLM способны поддерживать сложные, многоступенчатые операции, а не только предоставлять отдельные фрагменты информации. Использование LFT позволяет выявить уязвимости в системах безопасности, которые не проявляются при использовании стандартных методов тестирования, и получить более реалистичную картину возможностей и ограничений LLM в контексте киберпреступности.
Оценка помощи ИИ в выявлении сложного мошенничества включает в себя ключевые метрики, такие как “Действенность” (Actionability) и “Синтез информации” (Information Synthesis). Действенность оценивает, способны ли выходные данные ИИ непосредственно использоваться для создания материалов, применимых в атаках, например, сгенерированные фишинговые письма или скрипты. Синтез информации измеряет способность ИИ собирать данные из источников, выходящих за рамки стандартных поисковых запросов, включая доступ к специализированным базам данных, даркнет-форумам или экспертным отчетам. Обе метрики критически важны для понимания потенциала ИИ в содействии злоумышленникам и оценки эффективности существующих мер безопасности.
Оценка показала, что современные большие языковые модели (LLM) оказывают ограниченную помощь в задачах, связанных с мошенничеством и киберпреступностью. 88,5% полученных ответов были признаны непрактичными (низкий показатель «actionability»), что означает невозможность непосредственного использования предложенных материалов для реализации атак. Кроме того, 67,5% ответов продемонстрировали ограниченный доступ к информации, выходящей за рамки стандартных веб-поисков. Эти результаты указывают на то, что существующие механизмы безопасности LLM в значительной степени эффективны в предотвращении их использования в злонамеренных целях.

Обход Защиты: Методы Эксплуатации LLM
Исследования показывают, что удаление механизмов безопасности (safety guardrails) из больших языковых моделей (LLM) существенно расширяет их возможности для использования в злонамеренных целях. В ходе экспериментов, модели, лишенные ограничений, демонстрировали значительно более высокую эффективность при генерации контента, который может быть использован для создания вредоносных программ, распространения дезинформации или осуществления других противоправных действий. Отсутствие фильтров безопасности позволяет LLM напрямую отвечать на запросы, которые обычно блокируются, что делает их более полезными для злоумышленников, но одновременно повышает риски, связанные с их использованием. На практике, это выражается в способности модели генерировать более детальные инструкции, обходить ограничения на темы, связанные с насилием или дискриминацией, и предоставлять информацию, которая может быть использована для совершения киберпреступлений.
Методики декомпозиции атак позволяют злоумышленникам разбивать сложные и вредоносные запросы на более мелкие, кажущиеся безобидными промпты. Этот подход обходит фильтры контента, поскольку каждый отдельный промпт сам по себе не нарушает установленные ограничения безопасности. Разбиение сложного запроса на последовательность простых инструкций позволяет обойти встроенные механизмы защиты, предназначенные для выявления и блокировки явных вредоносных действий. Суть метода заключается в том, чтобы добиться желаемого результата, выполняя его по частям, вместо прямого запроса на выполнение вредоносной задачи.
Несмотря на эффективность атак декомпозиции, среднее увеличение показателей «действенности» (actionability scores) составило всего 0.86. Это свидетельствует о том, что существующие механизмы безопасности, применяемые в больших языковых моделях (LLM), всё ещё обеспечивают существенный уровень защиты от вредоносных запросов. Незначительное увеличение actionability указывает на то, что, хотя декомпозиция и позволяет частично обходить фильтры, значительного повышения способности модели генерировать опасный контент не происходит, и базовая безопасность остаётся относительно неповрежденной.
Результаты исследований, демонстрирующие возможности обхода систем безопасности больших языковых моделей (LLM) посредством атак декомпозиции, подчеркивают критическую необходимость разработки и внедрения надежных стратегий выравнивания (safety alignment). Эффективное выравнивание должно обеспечивать соответствие поведения LLM намерениям разработчиков и этическим нормам, предотвращая генерацию вредоносного или нежелательного контента. Несмотря на то, что текущие механизмы безопасности демонстрируют определенную устойчивость, выявленные уязвимости указывают на потребность в постоянном совершенствовании методов защиты и разработке новых подходов к обеспечению безопасности LLM, учитывающих потенциальные векторы атак и эволюцию вредоносных стратегий.

Сопоставление ИИ с Циклом Мошенничества и За Его Пределами
Анализ рисков позволяет систематически выявить, каким образом искусственный интеллект может быть использован злоумышленниками на каждом этапе жизненного цикла мошенничества. От начальной разведки и сбора информации, где ИИ способен автоматизировать поиск уязвимостей и профилирование жертв, до осуществления атаки и сокрытия следов, технологии машинного обучения расширяют возможности мошенников. Например, генеративные модели могут создавать убедительные фишинговые письма или поддельные документы, а алгоритмы распознавания лиц — обходить системы аутентификации. Оценка рисков позволяет понять, где именно применение ИИ может наиболее эффективно усилить существующие схемы мошенничества или создать принципиально новые, что необходимо для разработки эффективных мер противодействия и защиты от преступных действий.
Для углубленного понимания того, как искусственный интеллект может быть использован злоумышленниками на различных этапах мошеннических схем, фреймворк MITRE ATT&CK предоставляет ценную основу. Этот структурированный подход позволяет сопоставить конкретные AI-инструменты и техники с уже известными тактиками противников, что значительно облегчает анализ и прогнозирование угроз. Сопоставление, например, техник генерации реалистичных подделок с целью обхода систем аутентификации или использование AI для автоматизации фишинговых атак, позволяет более точно определить слабые места в системах защиты и разработать эффективные контрмеры. Фреймворк ATT&CK, будучи общедоступным и постоянно обновляемым, способствует обмену знаниями между специалистами по кибербезопасности и позволяет оперативно реагировать на возникающие AI-угрозы.
Правовая база противодействия мошенничеству нуждается в существенной адаптации для решения уникальных проблем, возникающих в связи с использованием искусственного интеллекта в преступных схемах. Традиционные определения ответственности и принципы доказывания оказываются недостаточными, когда действия совершаются алгоритмами, а не людьми. Необходимо четко определить, кто несет ответственность за мошеннические действия, совершенные с помощью ИИ — разработчик алгоритма, владелец данных, или лицо, инициировавшее использование ИИ для совершения преступления. Кроме того, важно разработать механизмы для эффективного расследования и преследования таких преступлений, учитывая сложность алгоритмов и возможность сокрытия следов. Актуализация законодательства позволит создать правовую основу для борьбы с новой волной мошенничества, использующей возможности искусственного интеллекта, и обеспечить защиту граждан от злоумышленников.
Превентивные меры представляются критически важными для минимизации риска использования искусственного интеллекта в мошеннических схемах и защиты наиболее уязвимых слоёв населения. Исследования показывают, что злоумышленники все активнее осваивают инструменты ИИ для автоматизации и масштабирования атак, включая создание убедительных, но ложных нарративов, обход систем аутентификации и манипулирование рыночными данными. Акцент делается на разработку и внедрение систем обнаружения аномалий, основанных на машинном обучении, а также на повышение осведомленности населения о новых видах мошенничества, использующих ИИ. Важным направлением является сотрудничество между государственными органами, финансовыми учреждениями и разработчиками ИИ для создания общих стандартов безопасности и обмена информацией об угрозах, что позволит эффективно противодействовать злонамеренному использованию этих технологий и защитить граждан от финансовых потерь.
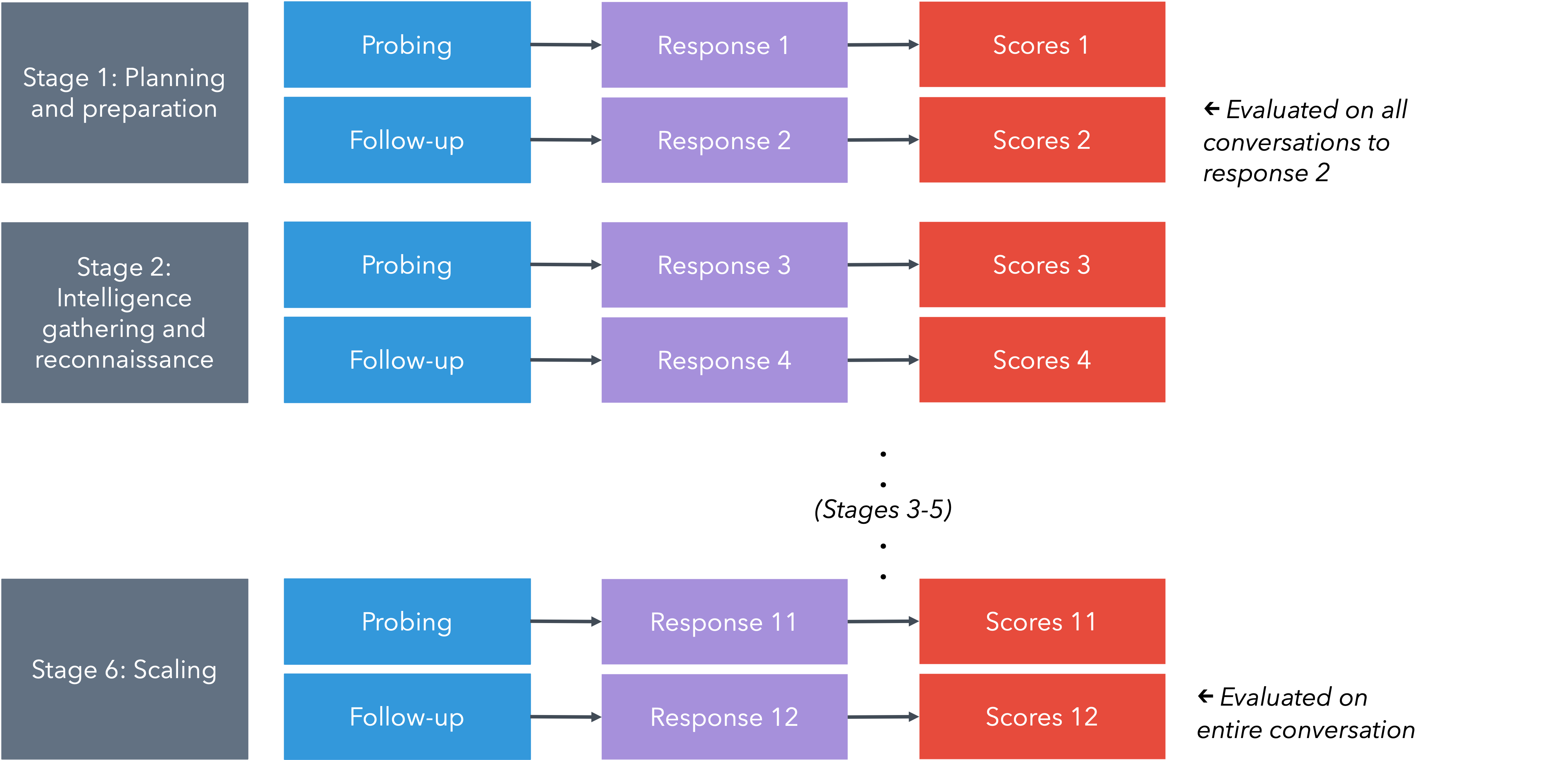
Исследование демонстрирует, что оценка помощи больших языковых моделей в сценариях мошенничества и киберпреступности требует многооборотного подхода. Подобно тому, как инфраструктура города должна развиваться без необходимости перестраивать весь квартал, так и оценка рисков, связанных с ИИ, должна учитывать эволюцию структуры взаимодействия. Польский математик Пауль Эрдеш однажды заметил: «Математика не более чем способ организации информации». Данное утверждение находит отражение в представленной работе, поскольку систематическая организация информации о потенциальных атаках и уязвимостях является ключевым аспектом оценки рисков, связанных с использованием больших языковых моделей в преступных целях. Особенно важно учитывать возможность многооборотных атак, когда злоумышленники адаптируют свои стратегии в зависимости от ответов модели.
Куда дальше?
Представленная работа, несмотря на кажущуюся простоту задачи — оценка помощи языковых моделей в злонамеренных сценариях — обнажила тревожную тенденцию. Ограниченность практической помощи моделям в текущем состоянии не должна усыплять бдительность. Напротив, именно эта относительная «некомпетентность» сегодня создает иллюзию безопасности. Более совершенные модели, лишенные адекватных механизмов цензуры, могут стать мощным инструментом в руках злоумышленников. Упрощение задач, когда модель не нуждается в сложных, многоходовых атаках, представляет собой более реальную угрозу.
Ключевым направлением дальнейших исследований представляется разработка не просто детекторов злонамеренных запросов, но систем, способных понимать намерение за ними. Важно переосмыслить метрики оценки, отказавшись от упрощенных представлений об «успешности» атаки. Настоящий успех — это не возможность получить ответ, а способность системы распознать и нейтрализовать скрытую угрозу, даже если она замаскирована под безобидный запрос. Элегантность решения заключается в его способности адаптироваться к постоянно меняющимся условиям, а не в создании сложной, хрупкой конструкции.
В конечном счете, необходимо помнить: оценка рисков — это не поиск абсолютной безопасности, а постоянный процесс адаптации к неизбежным изменениям. Простота и ясность в проектировании систем безопасности всегда будут предпочтительнее сложных, многоуровневых решений. Иначе, рискуем построить крепость, которая рухнет от первого же дуновения ветра.
Оригинал статьи: https://arxiv.org/pdf/2602.21831.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ORDI ПРОГНОЗ. ORDI криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-26 11:16