Автор: Денис Аветисян
Новое исследование предлагает способ выявлять ложные утверждения в больших языковых моделях, анализируя колебания в механизмах внимания.
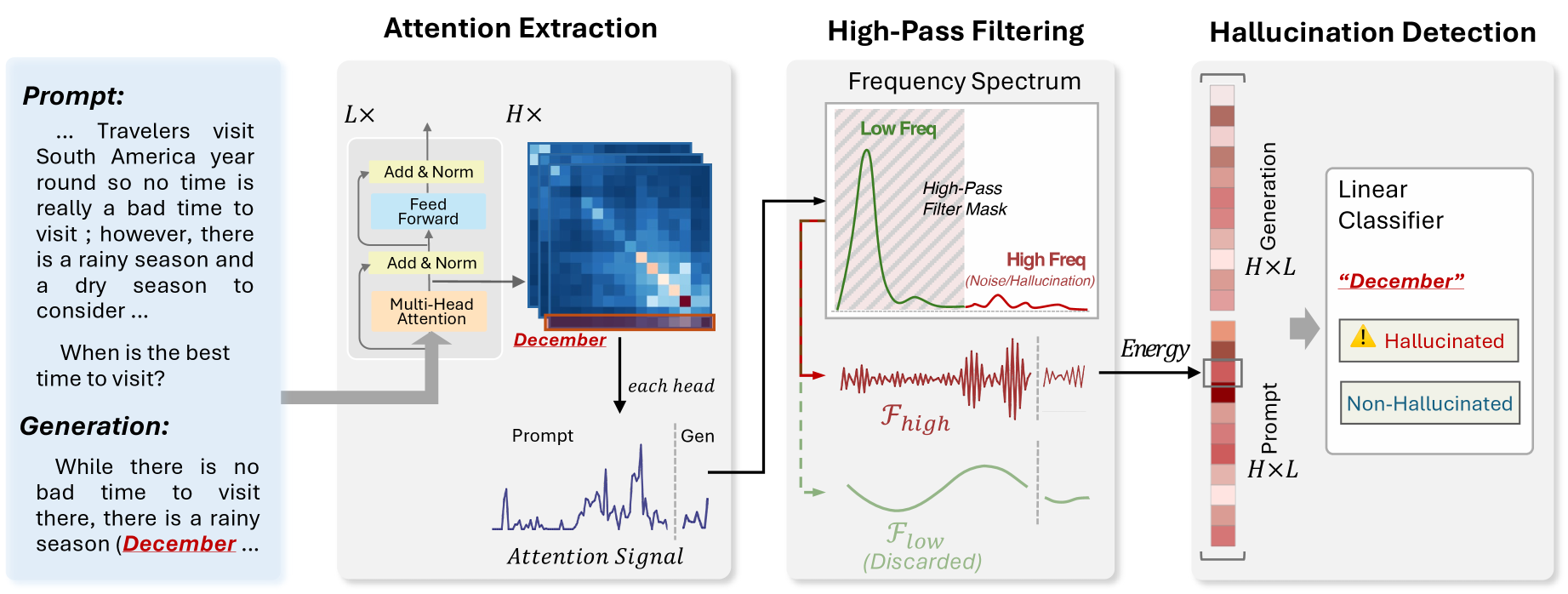
Предлагаемый метод основан на частотном анализе паттернов внимания и позволяет обнаруживать нестабильность, коррелирующую с галлюцинациями в языковых моделях.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), проблема контекстуальных галлюцинаций, то есть генерации не соответствующих контексту данных, остается актуальной. В работе ‘Detecting Contextual Hallucinations in LLMs with Frequency-Aware Attention’ предложен новый подход к выявлению этих галлюцинаций, основанный на анализе вариаций внимания в процессе генерации текста. Установлено, что нестабильность внимания, проявляющаяся в высокочастотных компонентах его спектра, является надежным индикатором генерируемых LLM галлюцинаций. Способны ли подобные методы частотного анализа внимания стать основой для создания эффективных и легковесных систем обнаружения галлюцинаций в различных LLM и задачах?
Иллюзия Реальности: Проблема Галлюцинаций в Больших Языковых Моделях
Несмотря на впечатляющую беглость речи, большие языковые модели часто склонны к генерации контента, не подкрепленного входными данными — явление, известное как «галлюцинация». Это означает, что модель может создавать правдоподобные, но фактически неверные утверждения или даже выдумывать несуществующие факты. Данная особенность проявляется даже в ситуациях, когда модель демонстрирует высокую степень уверенности в своих ответах, что делает обнаружение галлюцинаций особенно сложной задачей. Изучение причин возникновения этого феномена и разработка методов его смягчения представляют собой ключевые направления исследований в области искусственного интеллекта, поскольку надежность и достоверность генерируемого текста являются критически важными для широкого спектра приложений.
Проблема галлюцинаций в больших языковых моделях представляет собой серьезную преграду для их применения в областях, требующих безупречной фактической точности и надежного логического мышления. Автоматизированные системы, используемые для анализа юридических документов, медицинской диагностики или финансовых прогнозов, не могут позволить себе выдачу недостоверной информации. Ошибка в таких контекстах может привести к серьезным последствиям, от неправильного судебного решения до ошибочного медицинского диагноза. Поэтому обеспечение достоверности генерируемого текста является ключевой задачей для разработчиков и исследователей, стремящихся внедрить эти технологии в критически важные сферы деятельности. Необходимость создания надежных механизмов проверки фактов и логической последовательности становится все более актуальной по мере расширения областей применения больших языковых моделей.
Традиционные методы оценки точности больших языковых моделей часто оказываются неэффективными в выявлении тонких неточностей и фактических ошибок, которые они могут генерировать. Существующие подходы, такие как проверка на соответствие исходным данным или использование заранее определенных баз знаний, не всегда способны уловить сложные случаи, когда модель создает правдоподобные, но ложные утверждения. Это требует разработки принципиально новых методик оценки, включающих более глубокий анализ семантической согласованности, проверку на основе здравого смысла и использование внешних источников информации для перекрестной проверки фактов. Повышение доверия к этим моделям напрямую зависит от способности надежно выявлять и устранять даже самые скрытые проявления недостоверности.
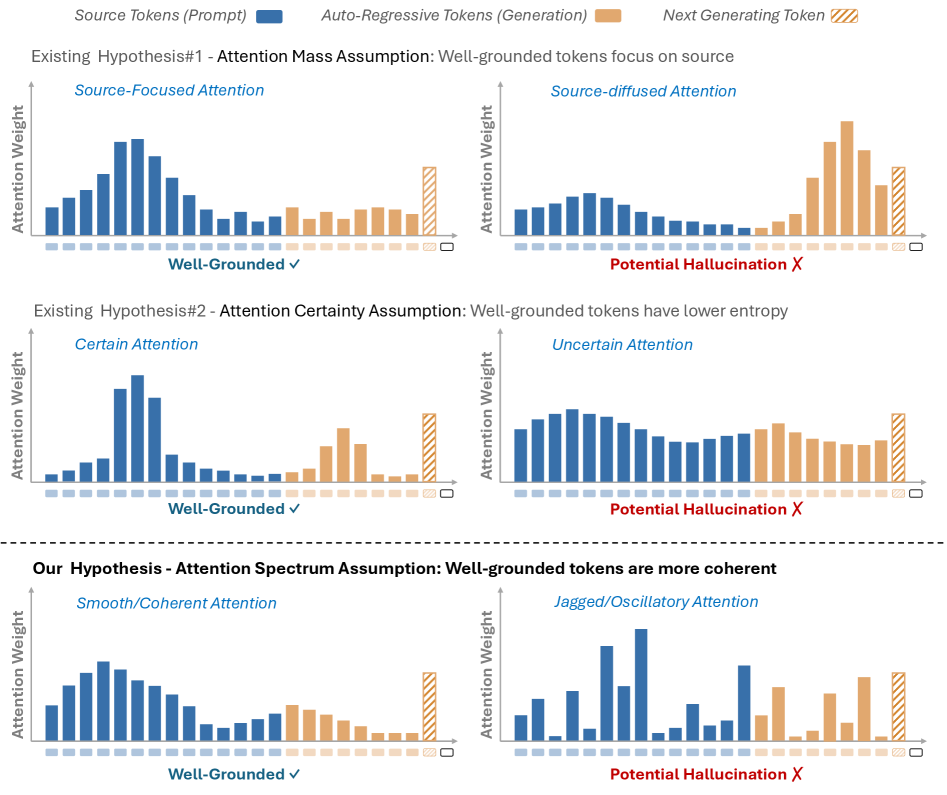
Декомпозиция Внимания: Частотный Подход
Метод частотного анализа представляет собой технику декомпозиции сигналов внимания на составляющие их частотные компоненты. В основе лежит применение математического аппарата, включая дискретное преобразование Фурье и дискретное вейвлет-преобразование, для разложения сложного сигнала на отдельные синусоидальные волны различной частоты и амплитуды. Каждая частотная компонента представляет вклад определенной скорости изменения информации в исходном сигнале внимания. Анализ спектра частот позволяет выявить преобладающие частотные диапазоны и определить характеристики, связанные со стабильностью и изменчивостью информации, представленной в сигналах внимания.
Анализ частотных компонентов внимания позволяет разграничить стабильную, обоснованную информацию от неустойчивых вариаций, потенциально свидетельствующих о галлюцинациях. Низкочастотные компоненты внимания обычно соответствуют устойчивым паттернам активации, отражающим обработку релевантной и подтвержденной информации. В то время как высокочастотные компоненты указывают на быстрые колебания и нестабильность в процессах внимания, что может быть связано с генерацией неправдоподобных или неподтвержденных деталей. Выделение и анализ этих частотных составляющих позволяет количественно оценить степень стабильности информации, обрабатываемой моделью, и выявить потенциальные признаки галлюцинаций.
Для выявления признаков нестабильности в сигналах внимания используется анализ с применением инструментов обработки сигналов, таких как дискретное преобразование Фурье и дискретное вейвлет-преобразование. ДПФ позволяет разложить сигнал на составляющие частоты, выявляя доминирующие частотные компоненты и их амплитуды. ДВП, в свою очередь, обеспечивает анализ сигнала во временной и частотной областях одновременно, что позволяет локализовать нестабильные паттерны, проявляющиеся в виде резких изменений амплитуды или частоты. Анализ спектральных характеристик, полученных посредством ДПФ и ДВП, позволяет идентифицировать высокочастотные колебания, коррелирующие с вероятностью возникновения галлюцинаций или нерелевантной информации, в отличие от стабильных, низкочастотных компонентов, отражающих надежную информацию.
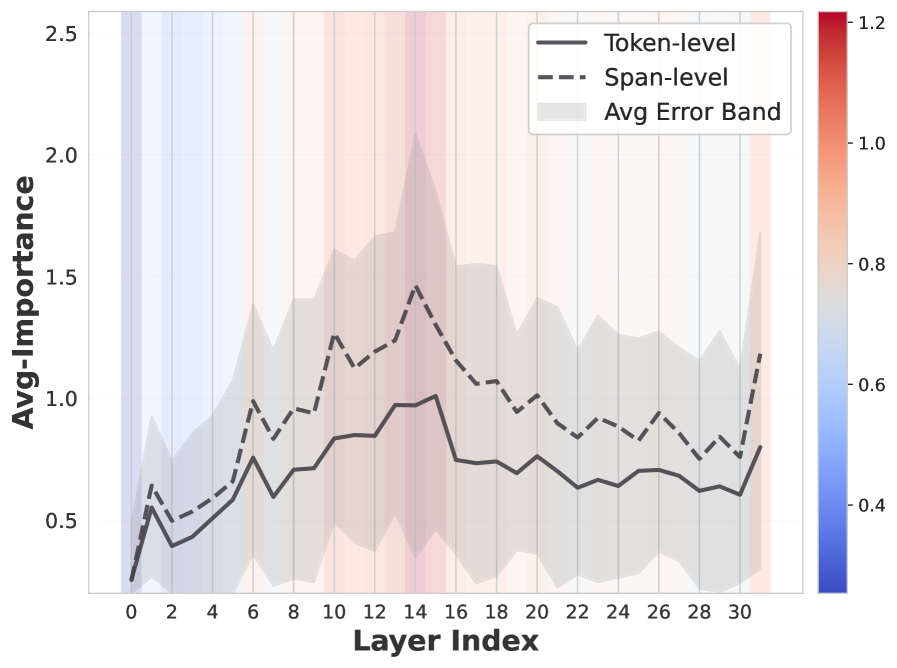
Валидация Подхода: Эталонные Тесты и Оценка
Метод, представленный в данной работе, продемонстрировал перспективные результаты при тестировании на общепринятых наборах данных для выявления галлюцинаций, включая RAGTruth и HalluRAG. Оценка проводилась с использованием стандартных метрик, что позволило объективно сравнить эффективность подхода с другими существующими решениями в области обнаружения фактических неточностей в сгенерированном тексте. Полученные результаты подтверждают потенциал метода для повышения надежности систем генерации текста и снижения вероятности распространения недостоверной информации.
При сравнении с существующими методами обнаружения галлюцинаций, такими как SelfCheckGPT, RefChecker и EigenScore, разработанный подход демонстрирует конкурентоспособную точность. В задачах суммаризации с использованием модели LLaMA-13B, наблюдается улучшение показателя AUROC до 6.6% по сравнению с базовым решением Lookback-Lens. Данный результат указывает на эффективность предлагаемого метода в выявлении фактических неточностей в сгенерированном тексте применительно к задачам суммаризации.
Дополнительный анализ выявил корреляцию между высокочастотными компонентами и случаями фактической несогласованности, подтверждая эффективность предложенного подхода. В частности, при использовании span-level оценки на наборе данных RAGTruth-Avg, наша методика демонстрирует улучшение показателя AUROC на 5.3% по сравнению с базовым решением Lookback-Lens. Данный результат указывает на то, что анализ частотного спектра может служить эффективным индикатором фактических ошибок в сгенерированных текстах и повышает точность выявления галлюцинаций.
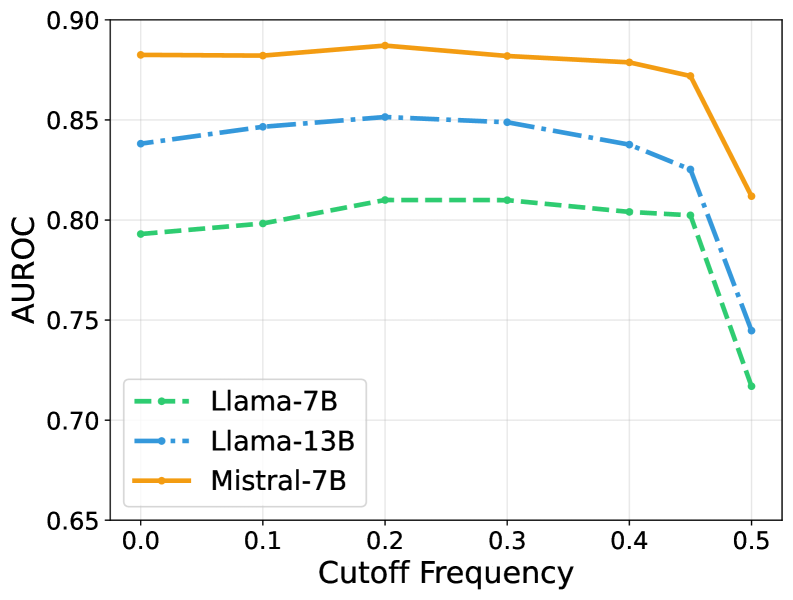
За Гранью Обнаружения: Понимание Стабильности Внимания
Анализ спектральных характеристик весов внимания позволяет проникнуть в логику работы языковых моделей. Исследователи обнаружили, что паттерны распределения внимания, проявляющиеся в виде частотных составляющих, отражают внутренние стратегии обработки информации. Высокочастотные компоненты указывают на быстро меняющиеся фокусы внимания, что может свидетельствовать о нестабильности или неэффективности процесса рассуждения. В то же время, низкочастотные компоненты указывают на устойчивые паттерны внимания, что говорит о более глубокой и согласованной обработке информации. Изучение этих спектральных свойств предоставляет возможность понять, как модель выделяет наиболее важные части входных данных и как формирует внутреннее представление о контексте, открывая путь к улучшению её способности к рассуждению и генерации связного текста. \mathcal{F}(A(x)) — преобразование Фурье матрицы внимания, где A(x) представляет веса внимания для входного сигнала x .
Исследование внимания в нейронных сетях показывает, что дискретный оператор Лапласа, тесно связанный с энергией Дирихле, является мощным инструментом для выявления локальных изменений в весах внимания. Этот оператор позволяет обнаружить области, где внимание модели склонно к нестабильности, то есть быстро меняется в зависимости от незначительных изменений во входных данных. По сути, он выявляет участки, где модель проявляет неуверенность или повышенную чувствительность. \nabla^2 представляет собой дискретный аналог оператора Лапласа, и его применение к матрицам внимания позволяет количественно оценить степень «гладкости» распределения внимания. Высокие значения \nabla^2 указывают на резкие переходы и, следовательно, на потенциальную нестабильность, что может указывать на проблемы с обобщением или интерпретируемостью модели.
Исследование взаимодействия между вниманием, ориентированным на контекст, и вниманием, сфокусированным на сгенерированных токенах, позволяет получить более глубокое понимание процессов привязки к реальности и обеспечения связности в моделях обработки естественного языка. Анализ показывает, что модели, учитывающие оба типа внимания, демонстрируют повышенную устойчивость и эффективность при переносе знаний в новые предметные области, превосходя по этому показателю, например, подход Lookback-Lens. Это связано с тем, что такое взаимодействие позволяет модели лучше интегрировать информацию из входного контекста с уже сгенерированным текстом, обеспечивая более последовательное и осмысленное продолжение диалога или генерацию текста. Таким образом, учет динамики между этими двумя формами внимания представляет собой важный шаг к созданию более надежных и адаптивных языковых моделей.
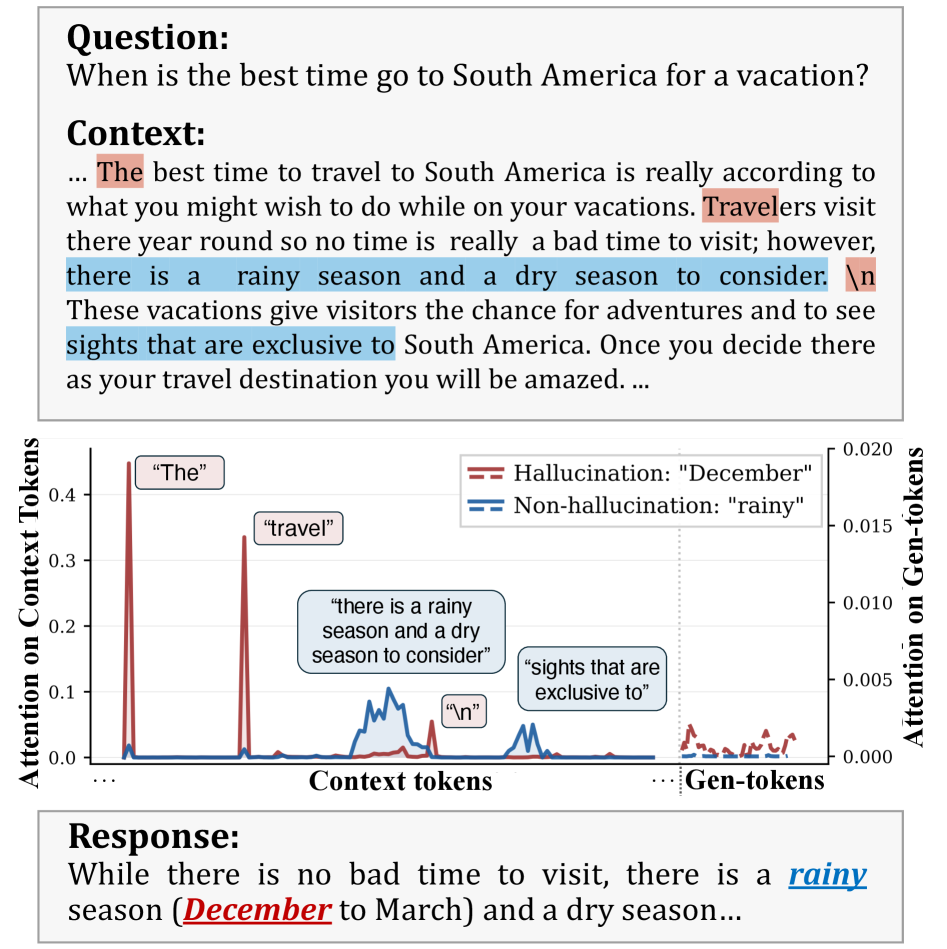
Исследование демонстрирует, что нестабильность внимания в больших языковых моделях является надежным индикатором галлюцинаций. Этот подход, основанный на анализе частоты изменений в паттернах внимания, позволяет выявить несоответствия между входными данными и генерируемым контентом. Как писал Блез Паскаль: «Все проблемы человечества происходят от того, что люди не умеют спокойно сидеть в комнате». В контексте данной работы, эта фраза перекликается с необходимостью «спокойного» и стабильного внимания модели — любое отклонение от предсказуемых паттернов указывает на потенциальные ошибки и галлюцинации. Анализ частоты вариаций внимания позволяет создать более надежный и предсказуемый алгоритм, что соответствует стремлению к математической чистоте и непротиворечивости.
Что дальше?
Представленная работа, хотя и демонстрирует корреляцию между нестабильностью внимания и галлюцинациями в больших языковых моделях, лишь касается поверхности проблемы. Элегантность обнаруженного сигнала не отменяет необходимости формального доказательства его универсальности. Необходимо исследовать, насколько предложенный метод устойчив к различным архитектурам трансформеров и задачам обработки естественного языка. Ведь красота алгоритма не зависит от языка реализации, важна только непротиворечивость.
Особый интерес представляет вопрос о причинно-следственной связи. Является ли нестабильное внимание причиной галлюцинаций, или лишь их следствием? Поиск инвариантных характеристик, которые могли бы предсказывать галлюцинации до их возникновения, остается открытой задачей. Игнорирование этого вопроса равносильно констатации факта, но не объяснению его природы.
В конечном счете, истинный прогресс требует не просто обнаружения галлюцинаций, а их предотвращения. Необходимо разработать механизмы, которые могли бы стабилизировать внимание и обеспечить согласованность генерируемого текста. Иначе, все усилия по обнаружению галлюцинаций превратятся в бесконечную гонку за симптомами, а не за лечением.
Оригинал статьи: https://arxiv.org/pdf/2602.18145.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- HYPE ПРОГНОЗ. HYPE криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- Золото прогноз
- SOL ПРОГНОЗ. SOL криптовалюта
- H ПРОГНОЗ. H криптовалюта
2026-02-24 07:01