Автор: Денис Аветисян
Новый подход к обучению генеративных нейронных сетей позволяет значительно повысить эффективность поиска оптимальных решений за счет тонкой настройки баланса между исследованием и использованием накопленного опыта.

В статье представлена методика Adaptive Complementary Exploration (ACE), использующая функцию потерь ‘divergent trajectory balance’ для улучшения стратегий исследования в Generative Flow Networks и повышения эффективности обучения с подкреплением.
Обучение генеративных моделей часто сталкивается с проблемой неэффективного исследования пространства состояний, особенно при работе с дискретными и композиционными данными. В данной работе, озаглавленной ‘Avoid What You Know: Divergent Trajectory Balance for GFlowNets’, предложен новый алгоритм Adaptive Complementary Exploration (ACE) для улучшения исследования в Generative Flow Networks (GFlowNets). ACE использует принцип баланса между исследованием и эксплуатацией, вводя дополнительную сеть для поиска перспективных, но недостаточно изученных областей пространства состояний, что позволяет значительно повысить точность аппроксимации целевого распределения и скорость обучения. Сможет ли предложенный подход открыть новые возможности для обучения генеративных моделей в сложных задачах, требующих эффективного исследования пространства состояний?
Моделирование Сложности: Вызов Композиционных Данных
Многие реальные наборы данных демонстрируют композиционную структуру, где поведение системы определяется взаимодействием её компонентов, а не суммой их индивидуальных свойств. Это означает, что для адекватного описания и моделирования таких данных необходимо учитывать не просто значения отдельных частей, но и их пропорциональное соотношение друг к другу. Например, состав почвы, определяемый процентным содержанием песка, глины и гумуса, или распределение питательных веществ в биологической системе, где изменения в концентрации одного компонента неминуемо влияют на все остальные. Игнорирование этих взаимосвязей приводит к упрощенным моделям, которые не способны точно воспроизвести сложность наблюдаемых явлений и, как следствие, дают неверные прогнозы или неадекватные результаты анализа. Понимание и учет композиционной природы данных является ключевым для построения эффективных и достоверных моделей в различных областях науки и техники.
Традиционные генеративные модели зачастую оказываются неспособны эффективно улавливать сложные взаимосвязи в композиционных данных, что приводит к некачественной генерации выборок и ограниченной выразительности. Вместо того чтобы моделировать данные как отдельные, независимые элементы, такие модели игнорируют ключевой аспект — зависимость между компонентами, а также их суммарные ограничения. Это проявляется в нереалистичных или неправдоподобных сгенерированных образцах, а также в неспособности модели адекватно представлять разнообразие данных. Например, при моделировании состава почвы или спектрального анализа, игнорирование взаимосвязей между различными элементами приводит к неточным прогнозам и нереалистичным синтетическим данным, что снижает применимость модели в практических задачах.
Для адекватного моделирования данных с композиционным строением необходим подход, который явно учитывает и использует их внутреннюю структуру. Традиционные методы часто рассматривают компоненты данных как независимые переменные, игнорируя взаимосвязи и ограничения, присущие этим системам. Эффективная модель должна представлять данные не как набор отдельных значений, а как композицию, где суммарное значение всех компонентов фиксировано, например, процентное содержание различных веществ в сплаве или распределение вероятностей в статистической модели. Такой подход позволяет избежать нереалистичных или физически невозможных выборок, а также повысить точность прогнозов и обобщающую способность модели. Использование специализированных архитектур, учитывающих эти ограничения, например, путем применения преобразований, сохраняющих композиционную структуру, открывает новые возможности для анализа и синтеза сложных данных.
GFlowNets: Графовый Подход к Генеративному Моделированию
GFlowNets используют графы состояний для представления композиционных данных, что обеспечивает гибкое и масштабируемое моделирование сложных систем. В основе подхода лежит представление данных в виде набора узлов (состояний), связанных между собой переходами. Такая структура позволяет эффективно кодировать сложные зависимости и взаимосвязи внутри данных, в отличие от традиционных методов, требующих фиксированной размерности или предположений о распределении данных. Использование графов позволяет моделировать данные произвольной сложности, масштабируясь по количеству состояний и переходов без существенного увеличения вычислительных затрат. Граф состояния представляет собой дискретизацию непрерывного пространства данных, что упрощает процесс обучения и генерации новых образцов.
В GFlowNets используются прямые и обратные политики для навигации по графу состояний, что позволяет генерировать образцы путем перехода между состояниями и оценивать соответствующие вероятности. Прямая политика определяет процесс генерации, начиная с начального состояния и последовательно выбирая следующие состояния на основе вероятностного распределения. Обратная политика, напротив, используется для оценки вероятности траектории, то есть последовательности состояний, что необходимо для обучения модели и оценки качества сгенерированных образцов. Вероятности переходов между состояниями определяются параметрами модели и обновляются в процессе обучения с использованием методов, таких как обучение с подкреплением или градиентный спуск. Комбинация этих двух политик позволяет эффективно исследовать пространство состояний и генерировать разнообразные и реалистичные образцы.
В отличие от традиционных генеративных моделей, которые часто полагаются на неструктурированные латентные пространства или авторегрессионные подходы, GFlowNets напрямую моделируют базовую структуру данных посредством графа состояний. Это позволяет сети изучать и использовать взаимосвязи между различными компонентами данных, что приводит к повышению эффективности генерации и более качественным результатам, особенно в задачах, где важна композиционность и учет зависимостей. Прямое моделирование структуры позволяет избежать проблем, связанных с экспоненциальным ростом сложности в традиционных методах при работе со сложными данными, и обеспечивает более эффективное представление и генерацию выборок.

Адаптивное Дополнительное Исследование для Надежной Генерации Выборок
Эффективное исследование графа состояний является критически важным для генерации разнообразных и качественных выборок с использованием GFlowNets. Недостаточное исследование приводит к концентрации выборок в ограниченных областях графа, что снижает качество генерируемых данных и замедляет сходимость алгоритма. Полноценное исследование, напротив, позволяет охватить большее количество состояний, выявлять неочевидные решения и генерировать более репрезентативные выборки, необходимые для обучения и оценки моделей. Таким образом, стратегии, направленные на оптимизацию исследования графа состояний, напрямую влияют на производительность и надежность GFlowNets в различных задачах.
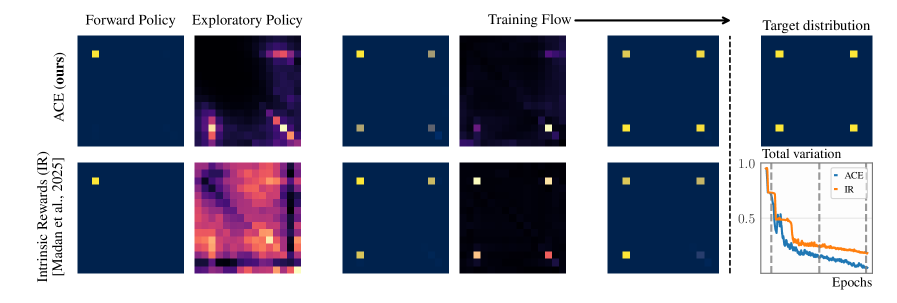
Адаптивное дополнительное исследование объединяет GFlowNets с методами, такими как Балансировка Расходящихся Траекторий (Divergent Trajectory Balance, DTB), для преодоления ограничений стандартных политик исследования. Стандартные методы часто сталкиваются с проблемами в поддержании корректности выборки и эффективном исследовании всего пространства состояний. DTB, являясь расширением принципа Балансировки Траекторий, обеспечивает корректность выборки, одновременно активно штрафуя передискретизированные области пространства состояний. Это стимулирует исследование недостаточно представленных областей, что приводит к ускоренной сходимости алгоритма в различных средах, включая задачи проектирования последовательностей, битовых последовательностей, задачи о рюкзаке, сетки, мешки, случайные блуждания и задачи AMP. Такой подход позволяет улучшить производительность и стабильность алгоритма по сравнению с традиционными методами исследования.
Метод Divergent Trajectory Balance (DTB), развивающий концепцию Trajectory Balance, обеспечивает корректность выборки, активно наказывая переsampled регионы пространства состояний. Это достигается путем введения штрафов для траекторий, которые посещают уже хорошо изученные области, тем самым направляя процесс исследования в недостаточно представленные области. В результате, DTB демонстрирует ускоренную сходимость в различных средах, включая задачи проектирования последовательностей, генерацию битовых последовательностей, решение задачи о рюкзаке, навигацию в сетках, задачи с мешками, случайные блуждания и задачи AMP (Accelerated Molecular Properties). Эффективность DTB подтверждена экспериментально в этих разнообразных средах, что указывает на его общую применимость и устойчивость.
Эффективность предложенного подхода подтверждается значительным снижением расстояния ТВ (Total Variation Distance) в среде Rings. В ходе экспериментов наблюдалось устойчивое функционирование алгоритма при широком диапазоне значений гиперпараметров α и β, что свидетельствует о его робастности и применимости к различным задачам. Уменьшение расстояния ТВ указывает на улучшение качества генерируемых выборок и более точное представление целевого распределения вероятностей, а стабильность при изменении гиперпараметров упрощает процесс настройки и адаптации алгоритма к новым условиям.
Повышение Исследования с Помощью Внутренней Мотивации
Для более эффективного исследования новых состояний, используется специальная стратегия, основанная на вознаграждении за новизну. Вместо того чтобы полагаться исключительно на внешние сигналы, система самостоятельно определяет, насколько неожиданным или новым является каждое посещенное состояние. Это достигается путем присвоения более высокой “ценности” тем состояниям, которые отличаются от уже известных, стимулируя тем самым дальнейшее исследование неизведанных областей. Такой подход позволяет агенту активно искать и изучать разнообразные варианты, даже если они не приводят к немедленному внешнему вознаграждению, что особенно важно при решении сложных задач, требующих открытия новых закономерностей и адаптации к меняющимся условиям.
Для обеспечения эффективного исследования окружающей среды, используется механизм случайной дистилляции сети (Random Network Distillation, RND), представляющий собой способ количественной оценки новизны наблюдаемых состояний. Суть метода заключается в обучении двух нейронных сетей — целевой и прогнозирующей. Целевая сеть получает входные данные и генерирует предсказания, в то время как прогнозирующая сеть пытается предсказать выходные данные целевой сети на основе тех же входных данных. Разница между предсказаниями этих двух сетей служит мерой новизны — чем больше расхождение, тем более необычным считается текущее состояние. Этот сигнал новизны, полученный посредством RND, используется в качестве внутренней награды, стимулируя агента исследовать ранее не встречавшиеся состояния и расширять свои знания об окружающей среде, что критически важно для успешного обучения и генерации данных.
Разработанная платформа, объединяющая GFlowNets, базу данных DTB и механизм исследования, основанный на внутренней мотивации, демонстрирует высокую эффективность в генеративном моделировании композиционных данных. Этот подход позволяет предсказывать антимикробную активность с впечатляющей точностью: для E. coli показатель AUC составляет 0.944, для S. aureus — 0.942, для P. aeruginosa — 0.913, для B. subtilis — 0.905, а для C. albicans — 0.930. Такие результаты указывают на значительный потенциал данной системы в разработке новых антимикробных препаратов и понимании механизмов устойчивости бактерий к лекарствам, открывая возможности для более эффективной борьбы с инфекционными заболеваниями.

Исследование равновесия траекторий, представленное в данной работе, стремится к оптимизации процесса обучения генеративных сетей. Подобный подход к балансу между исследованием и использованием напоминает слова Винтона Серфа: «Интернет — это не просто технология, это способ организации информации». Стремление к ясности в определении оптимального пути исследования, к удалению избыточных элементов в процессе обучения, отражает суть минимализма, где каждая операция должна способствовать общей цели. В конечном счете, простота и эффективность являются ключевыми принципами, определяющими истинный прогресс в области машинного обучения, и баланс траекторий — лишь один из способов приблизиться к этой идеальной форме.
Что Дальше?
Представленная работа, несмотря на достигнутый прогресс в управлении исследованием генеративных потоковых сетей, не снимает фундаментального вопроса: достаточно ли метрики «дивергенции траектории» для полного описания оптимального баланса между исследованием и эксплуатацией? Очевидно, что простая количественная оценка отклонения от известного не учитывает качественные различия в потенциальной полезности этих отклонений. Поиск более тонких показателей, учитывающих структуру пространства состояний и специфику решаемой задачи, представляется необходимым шагом.
Ограничения текущего подхода особенно заметны при решении задач, требующих долгосрочного планирования и сложной стратегии. Потеря информации о первоначальном намерении агента при адаптивном формировании вознаграждения может привести к появлению локальных оптимумов и субоптимальным решениям. В перспективе, интеграция методов, учитывающих историю взаимодействий и контекст задачи, представляется перспективным направлением.
В конечном счете, истинное совершенство в области обучения с подкреплением заключается не в усложнении алгоритмов, а в их упрощении. Задача состоит в том, чтобы найти минимальный набор принципов, достаточных для эффективного исследования и обучения в широком спектре задач. И, возможно, в этом поиске следует отдать предпочтение ясности, а не избыточности.
Оригинал статьи: https://arxiv.org/pdf/2602.17827.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ORDI ПРОГНОЗ. ORDI криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-23 21:08