Автор: Денис Аветисян
Новое исследование выявляет основные причины неудач при извлечении информации из длинных финансовых документов, используемых в системах генерации ответов.
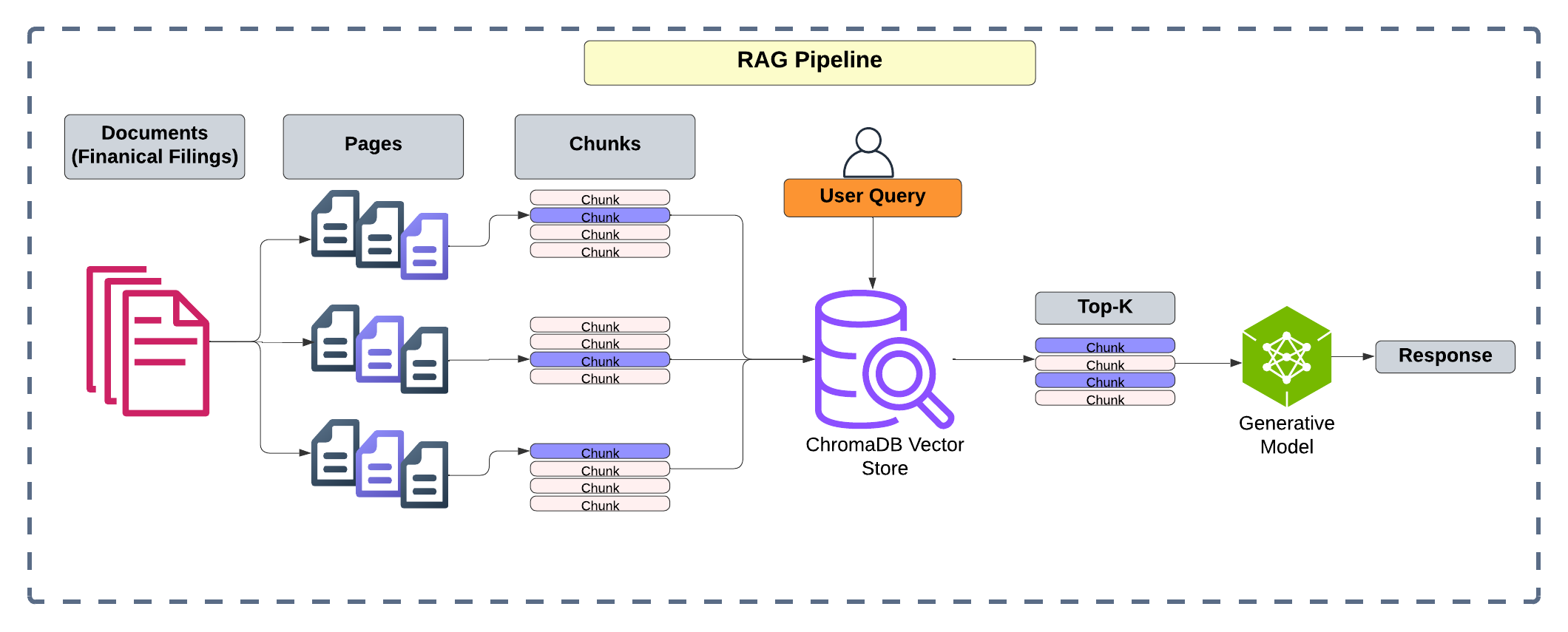
Анализ показывает, что на уровне извлечения страниц возникают значительные затруднения, и предлагается специализированный оценщик страниц для повышения точности поиска.
Несмотря на растущую популярность генеративных моделей с поисковым дополнением (RAG) для ответа на финансовые вопросы, надежность таких систем критически зависит от точного извлечения релевантного контекста. В работе ‘Decomposing Retrieval Failures in RAG for Long-Document Financial Question Answering’ исследуется частая проблема, когда извлекается правильный документ, но пропускается страница или фрагмент, содержащий ответ, что приводит к экстраполяции модели на основе неполных данных. Авторы демонстрируют, что слабое место RAG для длинных финансовых документов — это поиск на уровне страниц, и предлагают дообученную модель оценки релевантности страниц для повышения точности извлечения. Какие еще методы можно разработать для оптимизации многоуровневого поиска и обеспечения надежности RAG-систем в критически важных финансовых приложениях?
Вызов масштаба в вопросно-ответных системах для финансов
Традиционные методы поиска информации испытывают значительные трудности при работе с постоянно растущим объемом финансовых данных, особенно когда речь идет о длинных документах, таких как годовые отчеты 10-K. Эти документы, содержащие детальную финансовую информацию, часто насчитывают сотни страниц, что делает невозможным эффективный поиск релевантных фрагментов с использованием простых алгоритмов, основанных на совпадении ключевых слов. Стандартные методы индексации и ранжирования оказываются неспособными выделить из обширного текста именно те данные, необходимые для ответа на конкретный финансовый вопрос, что требует разработки принципиально новых подходов к извлечению и анализу информации из больших объемов финансовых документов.
Поиск ответов на сложные финансовые вопросы в огромных объемах текстовых данных, таких как годовые отчеты, представляет собой серьезную задачу, превосходящую возможности простого поиска по ключевым словам. Традиционные методы, основанные на сопоставлении ключевых слов, часто упускают из виду важные нюансы и контекст, скрытые в длинных документах. Для точного извлечения релевантной информации требуется понимание сложных финансовых терминов, взаимосвязей между данными и умение выделять критически важные фрагменты текста, что требует применения более продвинутых методов обработки естественного языка и машинного обучения. Эффективное решение данной проблемы позволит автоматизировать анализ финансовых документов и предоставлять точные и своевременные ответы на сложные вопросы, что значительно повысит эффективность принятия решений.
Специфика финансового языка и логики требует принципиально новых подходов к поиску информации и ответам на вопросы. В отличие от обычной речи, финансовые тексты изобилуют специализированной терминологией, сложными синтаксическими конструкциями и подразумевают глубокое понимание экономических принципов. Простые методы поиска, основанные на сопоставлении ключевых слов, часто оказываются неэффективными, поскольку не учитывают контекст, семантические нюансы и взаимосвязи между различными финансовыми показателями. Для адекватного анализа необходимо учитывать не только буквальное значение слов, но и подразумеваемые значения, а также способность к логическим умозаключениям и экстраполяции данных, что требует разработки более сложных алгоритмов и моделей, способных к глубокому пониманию и интерпретации финансовой информации.
RAG: Мост между поиском и генерацией
Технология Retrieval-Augmented Generation (RAG) объединяет преимущества поисковых и генеративных моделей для решения ограничений, присущих каждому из подходов в отдельности. Автономные генеративные модели часто страдают от недостатка актуальных знаний и склонны к галлюцинациям, в то время как чисто поисковые системы ограничены в способности синтезировать информацию и предоставлять сложные, связные ответы. RAG решает эту проблему, сначала извлекая релевантные документы из базы знаний на основе входного запроса, а затем используя эти документы в качестве контекста для генеративной модели, что позволяет ей создавать более точные, обоснованные и информативные ответы.
В основе RAG лежит использование методов плотного поиска, где запросы и документы преобразуются в семантические векторы — векторные представления, отражающие их смысл. Модели, такие как BGE-M3, позволяют создавать эти векторы (встраивания) таким образом, чтобы семантически близкие запросы и документы имели близкие векторы в векторном пространстве. Это позволяет системе находить релевантные документы, даже если в них не содержатся точные ключевые слова из запроса, обеспечивая более точные совпадения по смыслу, чем традиционные методы, основанные на сопоставлении ключевых слов.
Гибридные методы поиска информации, сочетающие разреженный (sparse) и плотный (dense) поиск, позволяют достичь баланса между точностью (precision) и полнотой (recall) извлечения релевантных документов. Разреженный поиск, основанный на лексическом совпадении ключевых слов, обеспечивает высокую точность, но может упускать семантически близкие документы. Плотный поиск, использующий векторные представления запросов и документов, улучшает полноту, находя документы, соответствующие смыслу запроса, даже при отсутствии лексического совпадения. Комбинирование этих подходов позволяет использовать преимущества обоих методов, повышая общую эффективность системы за счет более полного и точного извлечения релевантной информации.
Уточнение результатов: От извлечения к точности
Методы переранжирования играют ключевую роль в улучшении точности поиска путем изменения порядка результатов, полученных на начальном этапе извлечения. Изначально отобранные документы могут содержать как релевантную, так и нерелевантную информацию, и переранжирование позволяет поднять в верхнюю часть списка наиболее соответствующие запросу документы. Эти методы используют различные сигналы, включая семантическое сходство запроса и документа, качество контента, и поведенческие факторы пользователей, для определения релевантности. В результате, переранжирование существенно повышает вероятность того, что пользователь найдет наиболее полезную информацию в первых нескольких результатах поиска.
Иерархический поиск значительно повышает эффективность работы с большими коллекциями документов за счет поэтапного подхода. Сначала идентифицируются грубые, релевантные разделы (например, главы или категории), что позволяет существенно сократить объем данных для детального анализа. После этого поиск уточняется на более мелком уровне гранулярности — внутри выделенных разделов. Такой подход позволяет избежать полного сканирования всей коллекции, снижая вычислительные затраты и время отклика, особенно при работе с очень большими базами данных.
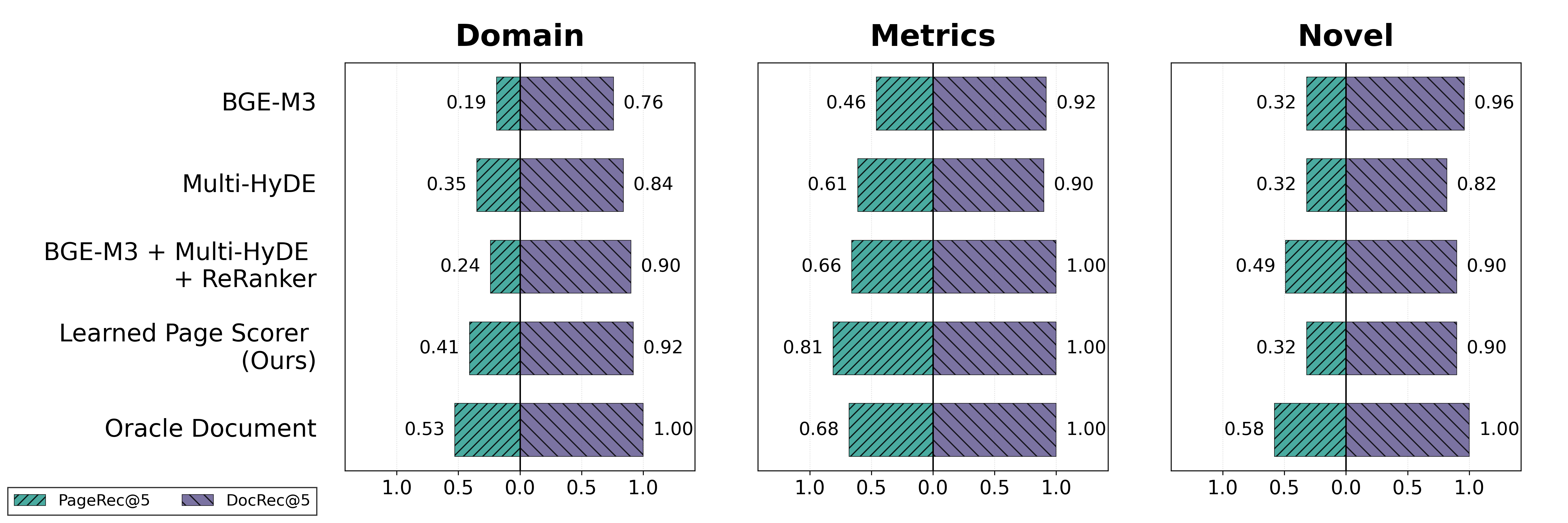
Модели оценки страниц (Page Scorer) позволяют ранжировать страницы внутри документа на основе их релевантности запросу, что способствует повышению точности поиска. Возможность дообучения таких моделей на данных конкретной предметной области (domain fine-tuning) дополнительно улучшает их эффективность. На датасете FinanceBench, использование моделей оценки страниц позволило достичь показателя Page Recall в 55%, что демонстрирует их способность выделять наиболее релевантные страницы в финансовых документах.
Проверка производительности: Бенчмарки и метрики
Для надежной оценки систем, решающих задачи финансового вопросно-ответного поиска, разработан комплексный набор данных FinanceBench. Этот бенчмарк не только содержит обширную коллекцию финансовых вопросов, но и включает в себя аннотации с указанием источников достоверных ответов — так называемые «золотые доказательства». Наличие таких аннотаций позволяет проводить объективную и воспроизводимую оценку качества работы систем, выявляя их сильные и слабые стороны в извлечении информации из финансовых документов и предоставлении точных ответов на сложные вопросы. Такой подход к оценке критически важен для развития надежных и эффективных инструментов анализа финансовых данных.
Для оценки эффективности компонента поиска релевантной информации, используемого в системах ответа на финансовые вопросы, ключевыми показателями выступают точность извлечения документов (Document Recall) и страниц (Page Recall). Точность извлечения документов демонстрирует, какая доля релевантных документов была успешно найдена системой, в то время как точность извлечения страниц показывает, насколько эффективно система определяет конкретные страницы внутри этих документов, содержащие необходимые данные. Высокие значения этих показателей свидетельствуют о способности системы находить и извлекать наиболее важную информацию из большого объема финансовых отчетов и документов, что критически важно для обеспечения достоверности и полезности предоставляемых ответов. Именно поэтому, при разработке и оценке подобных систем, эти метрики рассматриваются как одни из наиболее значимых.
Разработанный алгоритм оценки страниц демонстрирует высокую эффективность в извлечении релевантной информации из финансовых документов, достигая показателя Page Recall в 55% на наборе данных FinanceBench. Этот результат приближается к теоретическому пределу, заданному “Оракулом Документов” (60%), и значительно превосходит производительность базовых моделей. Данный показатель свидетельствует о способности системы точно идентифицировать страницы, содержащие ответы на финансовые вопросы, что является критически важным для обеспечения надежности и точности ответов в системах автоматизированного анализа финансовых данных.
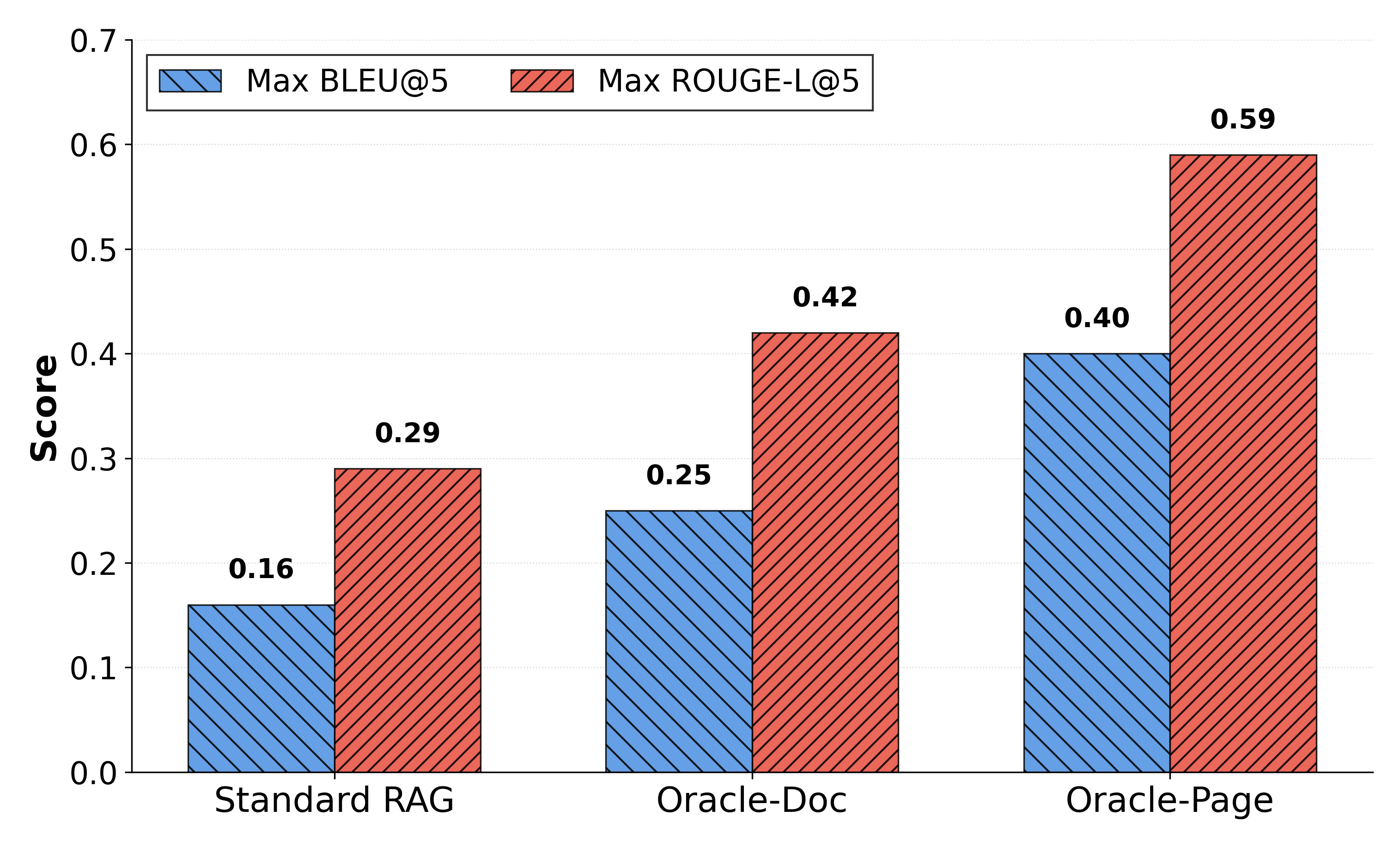
Исследования показали, что предложенный подход демонстрирует значительное улучшение в точности сопоставления числовых данных, достигая показателя 0.30. Этот результат существенно превосходит базовый уровень в 0.12 и приближается к результату, достигаемому идеальной системой выбора документов (0.26). Высокая точность сопоставления числовой информации критически важна для задач финансового анализа и позволяет системе более надежно извлекать и интерпретировать ключевые данные из финансовых отчетов, что подтверждает эффективность предложенного метода в контексте обработки и понимания финансовой информации.
Исследования показали, что предложенный подход демонстрирует ведущий показатель ROUGE-L, достигающий значения 0.46, что свидетельствует о высоком качестве генерируемых ответов. Более того, при анализе 10 тысяч финансовых отчетов (10K filings) удалось достичь показателя Page Recall в 0.62, что превосходит даже результаты, полученные с использованием «оракула документов» (Oracle Document setting) — 0.56. Данные результаты указывают на значительное улучшение в способности системы извлекать релевантную информацию из больших объемов финансовых данных и предоставлять точные и полные ответы на поставленные вопросы, подтверждая эффективность разработанной методики.
Исследование показывает, что при работе с большими финансовыми документами, именно этап извлечения информации становится узким местом. Авторы статьи акцентируют внимание на важности оценки релевантности страниц, чтобы обеспечить более точный ответ на запрос. В этом контексте, слова Винтона Серфа: «Интернет — это не просто технология, это способ мышления» — особенно актуальны. Подобно тому, как интернет требует структурированного подхода к информации, так и эффективная система Retrieval-Augmented Generation (RAG) нуждается в тщательно настроенном механизме оценки страниц, чтобы ‘понять’ запрос и предоставить наиболее релевантный фрагмент информации. Оптимизация этого процесса позволяет взглянуть на информацию под новым углом, раскрывая скрытые связи и закономерности.
Что Дальше?
Исследование выявляет, что узкое место в системах извлечения ответов на финансовые вопросы из длинных документов лежит не в самой генерации, а в предварительном поиске релевантной информации. Это, конечно, не открытие, достойное Нобелевской премии — всегда есть более слабое звено, и задача лишь в том, чтобы его найти. Однако, акцент на оценке страниц как ключевом элементе — это интересный сдвиг, демонстрирующий, что иногда для взлома системы нужно не изобретать новый алгоритм, а уделить внимание базовым компонентам.
Не стоит, однако, забывать о фундаментальной проблеме: оценка релевантности — это субъективная задача, а любая «домен-специфичная» оценка — это лишь попытка формализовать интуицию эксперта. Каждый новый «патч» в виде улучшенного скорера — это молчаливое признание несовершенства самой системы, её неспособности к абсолютно объективной оценке. Дальнейшие исследования должны быть направлены не только на улучшение существующих алгоритмов, но и на поиск принципиально новых подходов к пониманию и оценке информации.
В конечном итоге, настоящая задача заключается не в создании идеальной системы извлечения информации, а в понимании того, как информация вообще функционирует в сложном контексте финансовых данных. Понимание системы — это и есть её взлом, будь то через код или через осознание принципов её работы.
Оригинал статьи: https://arxiv.org/pdf/2602.17981.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- FARTCOIN ПРОГНОЗ. FARTCOIN криптовалюта
2026-02-23 19:17