Автор: Денис Аветисян
Новый подход к генерации синтетических финансовых данных позволяет повысить точность прогнозирования, особенно в условиях нестабильного рынка.
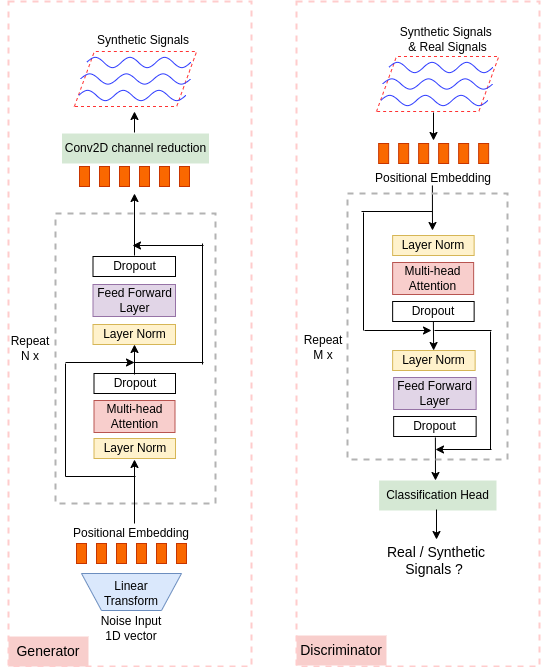
В статье рассматривается использование генеративно-состязательных сетей на основе архитектуры Transformer для аугментации финансовых временных рядов и повышения эффективности моделей глубокого обучения.
Несмотря на успехи глубокого обучения в прогнозировании временных рядов, финансовые данные, характеризующиеся волатильностью и ограниченным объемом, представляют особую проблему. В статье ‘Financial time series augmentation using transformer based GAN architecture’ предложена методика увеличения объема данных посредством генеративно-состязательных сетей (GAN) на основе архитектуры Transformer. Показано, что обучение модели LSTM на расширенном наборе данных, сгенерированном предложенной GAN, значительно повышает точность прогнозирования финансовых временных рядов, таких как Bitcoin и S&P500. Возможно ли дальнейшее улучшение качества сгенерированных данных и адаптация данной методики для прогнозирования других сложных финансовых инструментов?
Проблема Ограниченных Данных в Финансовом Прогнозировании
Точное прогнозирование временных рядов имеет решающее значение для принятия обоснованных решений в финансовой сфере, однако данные, необходимые для этого, часто бывают ограничены и нестационарны. Нестационарность, то есть изменение статистических свойств данных во времени, требует применения сложных методов анализа и предобработки. Ограниченность исторических данных, в свою очередь, снижает надежность прогнозов, особенно в периоды высокой волатильности рынка. Это создает серьезную проблему для финансовых аналитиков и инвесторов, поскольку стандартные статистические модели могут оказаться неэффективными в условиях недостатка информации, что подчеркивает необходимость разработки новых подходов к прогнозированию, способных эффективно работать с ограниченными и динамически меняющимися данными.
Традиционные модели глубокого обучения, несмотря на свою эффективность в задачах, требующих большого объема данных, часто демонстрируют ограниченную применимость в сфере финансовых прогнозов из-за дефицита исторических данных. Эта нехватка приводит к переобучению — модели начинает запоминать шум и специфические особенности имеющегося набора данных, вместо выявления истинных закономерностей. В результате, способность к обобщению, то есть к корректному прогнозированию на новых, ранее не встречавшихся данных, существенно снижается. Динамичность финансовых рынков, характеризующаяся постоянными изменениями и непредсказуемостью, усугубляет эту проблему, поскольку модели, обученные на ограниченном наборе данных, не способны адаптироваться к новым рыночным условиям и выдают неточные прогнозы, что снижает их практическую ценность для принятия обоснованных финансовых решений.
Нестабильность финансовых рынков и ограниченность исторических данных представляют собой серьезную проблему для создания надежных прогностических моделей. Волатильность, присущая ценам активов и экономическим показателям, затрудняет выявление устойчивых закономерностей, а краткий период доступных данных не позволяет моделям адекватно адаптироваться к меняющимся условиям. Это особенно актуально для новых финансовых инструментов или рынков, где исторических данных попросту недостаточно для обучения сложных алгоритмов. В результате, даже самые передовые методы машинного обучения могут оказаться неэффективными при прогнозировании будущих изменений, что подчеркивает необходимость разработки инновационных подходов, способных эффективно работать в условиях дефицита информации и высокой неопределенности.
Несмотря на сложность и изысканность современных прогностических моделей, их эффективность напрямую зависит от объема доступных данных. Отсутствие достаточного количества исторических данных, особенно в условиях высокой волатильности финансовых рынков, приводит к тому, что даже самые передовые алгоритмы не способны выявить истинные тенденции и закономерности. Модели, обученные на ограниченном объеме информации, часто демонстрируют переобучение, что делает их неспособными к адекватной генерализации и точным прогнозам будущих изменений. Таким образом, недостаток данных становится критическим ограничивающим фактором для надежного финансового прогнозирования, подчеркивая необходимость разработки методов, способных эффективно работать в условиях дефицита информации.
TTS-GAN: Новая Стратегия Аугментации Данных
TTS-GAN представляет собой генеративно-состязательную сеть (GAN), основанную на архитектуре Transformer, разработанную для увеличения объема ограниченных данных финансовых временных рядов. В основе TTS-GAN лежит использование механизма самовнимания (self-attention), что позволяет модели эффективно улавливать зависимости во временных рядах и генерировать синтетические данные, статистически схожие с реальными. Данная архитектура предназначена для решения проблемы недостатка данных, часто возникающей при обучении моделей глубокого обучения в финансовой сфере, и направлена на повышение их производительности и обобщающей способности.
TTS-GAN использует механизмы самовнимания (self-attention) для генерации синтетических данных временных рядов, что позволяет расширить обучающую выборку. В основе лежит архитектура Transformer, позволяющая модели устанавливать зависимости между различными точками временного ряда и генерировать последовательности, имитирующие статистические характеристики реальных финансовых данных. Механизмы самовнимания позволяют модели динамически взвешивать важность различных сегментов входной последовательности при генерации новых данных, что способствует созданию более реалистичных и правдоподобных синтетических временных рядов, расширяющих разнообразие обучающей выборки и улучшающих обобщающую способность моделей машинного обучения.
Недостаток данных является распространенной проблемой при обучении моделей глубокого обучения для анализа финансовых временных рядов. TTS-GAN решает эту проблему, генерируя синтетические данные, которые расширяют исходный обучающий набор. Увеличение объема данных позволяет моделям более эффективно обучаться, снижая риск переобучения и улучшая способность к обобщению на новых, ранее не встречавшихся данных. Экспериментальные результаты демонстрируют, что модели, обученные с использованием данных, дополненных TTS-GAN, показывают повышение точности прогнозирования и улучшенную устойчивость к шуму и рыночным колебаниям, особенно в условиях ограниченного количества исходных данных.
Архитектура TTS-GAN включает упрощенный механизм градиентного штрафа (simplified gradient penalty) для стабилизации процесса обучения генеративно-состязательной сети. Данный метод, основанный на ограничении нормы градиента дискриминатора, предотвращает исчезновение или взрыв градиентов, что особенно важно при работе с временными рядами. Применение градиентного штрафа способствует более эффективной сходимости обучения и обеспечивает соответствие генерируемых синтетических данных реальным паттернам, повышая их реалистичность и полезность для расширения обучающей выборки.
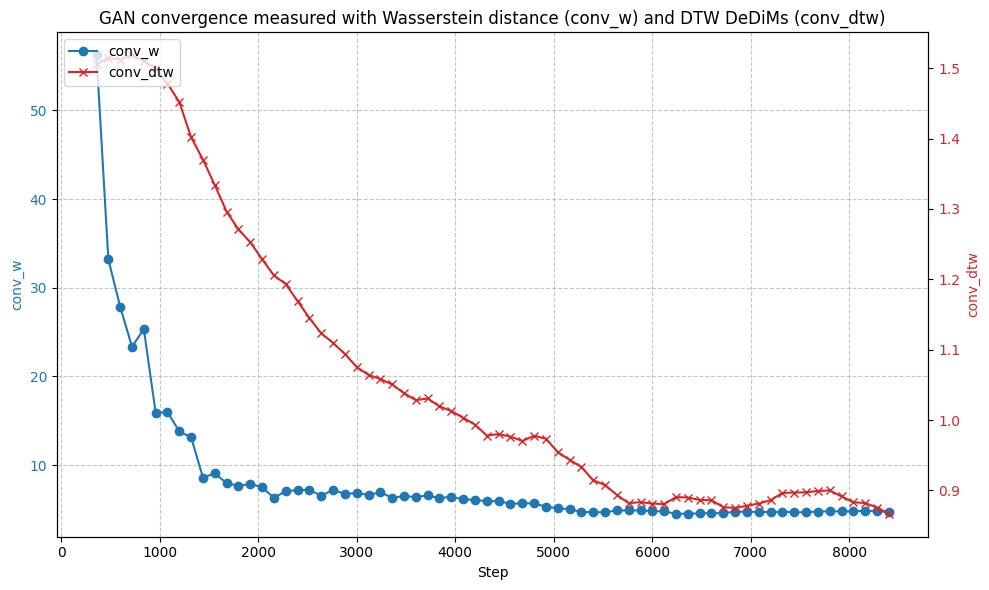
Экспериментальная Валидация и Прирост Производительности
Эксперименты, проведенные на данных S&P500 и Bitcoin, показали, что TTS-GAN значительно улучшает точность прогнозирования по сравнению с базовыми моделями, такими как LSTM. В ходе тестирования TTS-GAN использовалась для генерации дополнительных данных, которые затем применялись для обучения LSTM. Результаты демонстрируют статистически значимое повышение точности прогнозов, что подтверждается снижением метрики ошибки, в частности, Mean Squared Error (MSE), при использовании данных, дополненных TTS-GAN, по сравнению с обучением LSTM только на исходных данных. Повышение точности прогнозирования наблюдалось как на исторических данных S&P500, так и на данных о ценах Bitcoin.
Для обеспечения оптимальной производительности модели TTS-GAN применяются методы предварительной обработки данных, включающие нормализацию MinMaxScaler и сглаживание экспоненциальным скользящим средним (Exponential Moving Average). MinMaxScaler масштабирует значения признаков в диапазон [0, 1], что способствует ускорению обучения и повышению устойчивости модели. Экспоненциальное скользящее среднее, в свою очередь, уменьшает шум и выделяет тренды во временных рядах, что улучшает способность модели к прогнозированию. Комбинация этих методов позволяет добиться более точных и стабильных результатов при анализе финансовых данных, таких как котировки акций и криптовалют.
Эффективность TTS-GAN количественно оценивалась с использованием среднеквадратичной ошибки (Mean Squared Error, MSE), стандартной метрики для оценки точности прогнозирования. В ходе экспериментов, проведенных на 40 различных наборах финансовых временных рядов, наблюдалось устойчивое снижение значения MSE при обучении модели LSTM с использованием данных, дополненных с помощью TTS-GAN. Данный результат подтверждает, что генерация синтетических данных TTS-GAN способствует повышению точности прогнозирования LSTM в задачах анализа финансовых временных рядов.
Для дополнительной валидации качества сгенерированных данных использовалась метрика Deep Dataset Dissimilarity Measure (DDDM), оценивающая степень реалистичности и соответствия сгенерированных данных исходному распределению. В ходе экспериментов, проведенных с использованием различных наборов финансовых временных рядов, статистическая значимость результатов была подтверждена с использованием p-value, который оказался меньше 0.05 во всех проведенных экспериментах. Данный результат указывает на то, что сгенерированные данные обладают достаточным качеством и могут быть использованы для улучшения производительности моделей прогнозирования.
Последствия и Перспективы Развития
Модель TTS-GAN представляет собой перспективное решение для повышения надежности и точности прогнозирования временных рядов в условиях ограниченного объема данных. В ситуациях, когда исторические данные для анализа недостаточны, TTS-GAN использует генеративно-состязательные сети для создания синтетических данных, которые расширяют обучающую выборку. Этот подход позволяет алгоритмам прогнозирования лучше обобщать закономерности и снижать погрешность, особенно в условиях нестабильности рынка или при анализе новых финансовых инструментов. Синтетические данные, сгенерированные TTS-GAN, позволяют эффективно обучать модели прогнозирования даже при минимальном количестве исходных данных, что открывает возможности для анализа ранее недоступных временных рядов и более точного предсказания будущих тенденций.
Метод TTS-GAN демонстрирует свою универсальность, находя применение в анализе широкого спектра финансовых инструментов — от акций и облигаций до валютных пар и товарных рынков. Исследования показывают, что техника эффективно работает в различных рыночных условиях, включая периоды высокой волатильности и низкой ликвидности, что делает её ценным инструментом для инвесторов и финансовых аналитиков. Способность генерировать реалистичные синтетические данные позволяет повысить точность прогнозирования временных рядов даже при ограниченном объеме исторических данных, открывая новые возможности для оптимизации инвестиционных стратегий и управления рисками в динамично меняющейся финансовой среде.
Перспективные исследования в области TTS-GAN направлены на углубленное изучение более сложных архитектур генеративно-состязательных сетей. В частности, планируется экспериментировать с новыми подходами к обучению, позволяющими генерировать еще более реалистичные и правдоподобные временные ряды. Ключевым направлением является интеграция специфических знаний о финансовых рынках, включая экономические модели и экспертные оценки, непосредственно в процесс генерации данных. Такой подход позволит не только повысить качество генерируемых данных, но и обеспечить их соответствие реальным рыночным закономерностям, что, в свою очередь, улучшит точность прогнозирования и надежность моделей, используемых в финансовом анализе и управлении рисками.
Решение проблемы нехватки данных, предложенное TTS-GAN, оказывает значительное влияние на процессы принятия решений и управления рисками в финансовых рынках. Традиционные методы прогнозирования временных рядов часто сталкиваются с ограничениями при работе с недостаточным объемом исторических данных, что приводит к снижению точности и надежности прогнозов. TTS-GAN, генерируя синтетические данные, дополняет существующие наборы, позволяя создавать более устойчивые и точные модели. Это особенно важно для новых финансовых инструментов или рынков, где исторические данные ограничены, и позволяет инвесторам и аналитикам принимать более взвешенные решения, снижая потенциальные риски и повышая эффективность инвестиционных стратегий. Таким образом, технология открывает новые возможности для анализа и прогнозирования в условиях информационной неопределенности.
Исследование демонстрирует, что искусственное расширение наборов финансовых данных с помощью генеративных состязательных сетей (GAN), основанных на трансформерах, повышает точность прогнозирования, особенно в условиях высокой волатильности и ограниченности исходных данных. Это подтверждает мысль Алана Тьюринга: «Я не думаю, что машина может думать». Ведь само обучение модели — это не воспроизведение существующей реальности, а создание новой, вероятностной модели, способной предсказывать будущее, опираясь на ограниченный опыт. По сути, система не просто повторяет паттерны, а создает их, подобно тому, как живой организм адаптируется к изменяющимся условиям. Ошибка в системе — это не провал, а возможность для самокоррекции и улучшения, сигнал о том, что система способна к эволюции.
Что же дальше?
Исследование демонстрирует, что искусственное увеличение объёма финансовых временных рядов с помощью генеративных состязательных сетей, основанных на трансформерах, может улучшить точность прогнозирования. Однако, следует помнить: каждая попытка построить идеальную модель — это пророчество о будущем сбое. Улучшение точности в сегодняшних волатильных условиях — лишь отсрочка неизбежного столкновения с непредсказуемым. Система не становится устойчивее, она лишь становится более подготовленной к определенному виду хаоса.
Особый интерес представляет вопрос о природе самих данных. Динамическое выравнивание времени (DTW) и среднеквадратичная ошибка (MSE) — это лишь инструменты для измерения различий. Но что, если сама суть финансовых рядов заключается в их непредсказуемости, в их способности постоянно меняться? Увеличение данных не создает новой информации, оно лишь множит существующую, создавая иллюзию стабильности, которая рано или поздно рухнет.
Будущие исследования должны сосредоточиться не на улучшении точности, а на понимании пределов предсказуемости. Не на создании более совершенных моделей, а на разработке систем, способных адаптироваться к непредсказуемым изменениям. Ведь если система молчит, это не признак её совершенства, а признак того, что она готовит сюрприз. И отладка никогда не закончится — просто однажды перестанут смотреть.
Оригинал статьи: https://arxiv.org/pdf/2602.17865.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
2026-02-23 07:38