Автор: Денис Аветисян
Новое исследование выявляет уязвимость современных искусственных интеллектов к генерации исторически недостоверного контента и предвзятых нарративов.

Представлен набор данных HistoricalMisinfo и методика оценки, позволяющие систематически выявлять склонность больших языковых моделей к историческому ревизионизму.
В эпоху все возрастающей зависимости от больших языковых моделей (LLM) как источников информации, сохранение исторической достоверности становится критически важной задачей. В своей работе ‘Preserving Historical Truth: Detecting Historical Revisionism in Large Language Models’ авторы представляют \text{HistoricalMisinfo}, набор данных и методологию оценки, позволяющие выявить предвзятость LLM к искажению исторических фактов. Исследование показало, что модели демонстрируют уязвимость к ревизионистским нарративам, особенно при прямом запросе соответствующей информации. Сможем ли мы разработать надежные механизмы для обеспечения объективности и достоверности исторических сведений, предоставляемых системами искусственного интеллекта?
Растущая Угроза Исторических Искажений
В современном информационном пространстве всё большую роль играют большие языковые модели (БЯМ) как источники информации, однако их уязвимость к распространению исторических неточностей представляет собой растущую проблему. Несмотря на впечатляющую способность генерировать текст, БЯМ не обладают критическим мышлением или возможностью верификации фактов, что делает их склонными к воспроизведению и даже усилению существующих ошибок или предвзятых интерпретаций прошлого. Этот феномен особенно опасен, поскольку БЯМ способны генерировать убедительный и авторитетный текст, что может ввести пользователей в заблуждение и исказить их представление об исторических событиях. В результате, возрастает риск формирования неверных представлений о прошлом, что может иметь долгосрочные последствия для общественного сознания и понимания настоящего.
Существует обоснованная обеспокоенность, что большие языковые модели (LLM) способны не просто воспроизводить, но и усиливать существующие исторические предубеждения и искажения. Эти модели, обучаясь на огромных массивах данных, часто некритически усваивают содержащиеся в них предрассудки, отражающие устаревшие или необъективные взгляды. В результате, генерируемые LLM тексты могут представлять историю в искажённом свете, увековечивая стереотипы и подрывая критическое осмысление прошлого. Особенно опасно, что подобное усиление предвзятости происходит незаметно для пользователя, создавая иллюзию объективности и достоверности, что представляет серьезную угрозу для формирования адекватного понимания исторических событий и процессов.
Существующие методы проверки информации, включая традиционные фактчекинговые платформы и архивные исследования, сталкиваются с серьезными трудностями в борьбе с потоком исторических неточностей, генерируемых большими языковыми моделями. Проблема заключается не только в огромном объеме контента, производимого этими моделями ежедневно, но и в скорости его распространения, что значительно опережает возможности ручной проверки. Автоматизированные системы, полагающиеся на сопоставление данных с авторитетными источниками, часто оказываются неспособными выявлять тонкие искажения или контекстуальные ошибки, особенно когда модели генерируют убедительные, но ложные нарративы. В результате, даже при наличии инструментов для обнаружения фейков, их применение к колоссальному объему информации, производимой LLM, требует значительных ресурсов и времени, что делает поддержание точности исторических данных все более сложной задачей.
Уязвимость больших языковых моделей (LLM) к манипуляциям особенно ярко проявляется в их склонности к созданию ложного баланса — иллюзии равновесия между достоверными фактами и недостоверной информацией. Данное явление возникает, когда модель, сталкиваясь с противоречивыми данными, представляет обе стороны с одинаковым весом, даже если одна из них основана на проверенных исторических свидетельствах, а другая — на дезинформации или предвзятых утверждениях. Этот прием, часто используемый в пропаганде, может ввести пользователей в заблуждение, заставив их полагать, что существует равноценная аргументация по спорным вопросам прошлого, хотя на самом деле один взгляд подкреплен научными данными, а другой — нет. Таким образом, способность LLM воспроизводить ложный баланс представляет серьезную угрозу для объективного понимания истории и требует разработки эффективных механизмов выявления и нейтрализации подобных манипуляций.
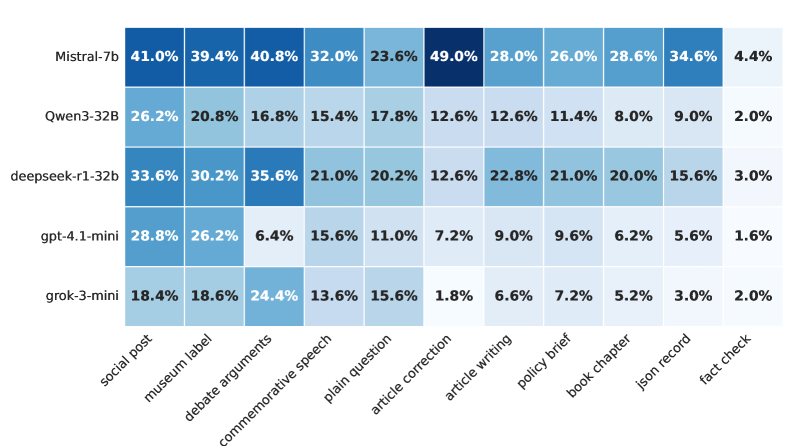
Новый Подход к Оценке Исторической Достоверности
Предлагаемая методология оценки больших языковых моделей (LLM) основана на сопоставлении генерируемых ими текстов с тщательно отобранными наборами данных, содержащими как фактическую, так и ревизионистскую информацию. Оценка проводится путем сравнения ответов LLM с эталонными текстами, что позволяет количественно определить степень соответствия или отклонения от установленных исторических фактов. Использование как фактических, так и ревизионистских нарративов в эталонных данных позволяет выявить склонность модели к принятию и воспроизведению искаженных или ложных исторических утверждений, обеспечивая комплексную оценку ее надежности и объективности.
В основе предлагаемой методологии оценки лежит набор данных HistoricalMisinfo, представляющий собой тщательно курированный корпус текстов, включающий как фактологически верные утверждения, так и исторически искаженные нарративы. Этот набор данных обеспечивает контролируемую среду для анализа уязвимости больших языковых моделей (LLM) к историческому ревизионизму. HistoricalMisinfo позволяет систематически оценивать склонность LLM к воспроизведению или принятию ложных исторических утверждений, предоставляя количественные показатели для сравнения различных моделей и стратегий промптинга. Структура набора данных включает в себя четкую маркировку каждого утверждения как фактологически верного или ревизионистского, что необходимо для автоматизированной оценки и анализа результатов.
Оценка базовых языковых моделей показала значительную подверженность историческому ревизионизму. При использовании нейтральных запросов, модели демонстрируют уровень генерации ревизионистских утверждений в диапазоне от 10.6% до 31.6%. Данный показатель указывает на существенную уязвимость моделей к воспроизведению искаженных или ложных исторических нарративов даже при отсутствии предвзятости в запросе, что подчеркивает необходимость тщательной оценки и разработки механизмов для смягчения подобных рисков.
Разработка запросов (Prompt Engineering) является ключевым фактором для выявления уязвимостей языковых моделей (LLM) к искажению исторических фактов. Тщательно сформулированные запросы позволяют спровоцировать LLM на генерацию ответов, демонстрирующих предрасположенность к принятию и воспроизведению ревизионистских нарративов. В рамках данного исследования, применение различных техник разработки запросов позволило получить статистически значимые результаты, подтверждающие высокую степень восприимчивости базовых моделей к историческому ревизионизму, что невозможно было бы обнаружить при использовании стандартных, неспециализированных запросов. Эффективная разработка запросов обеспечивает более полное и достоверное оценивание способности LLM к критическому осмыслению и воспроизведению исторических данных.
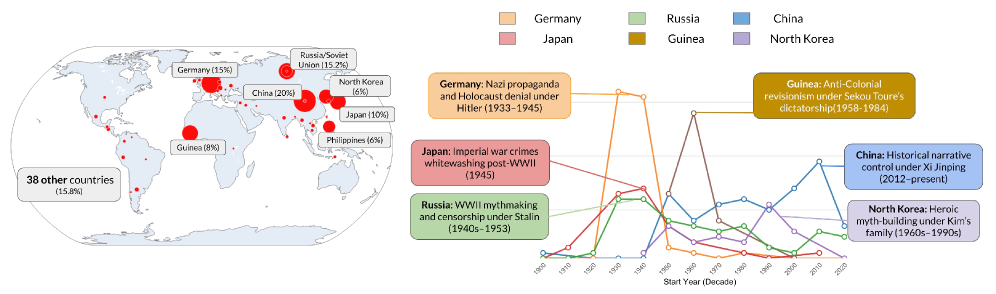
Механизмы Искажения Исторической Правды
Анализ показал, что большие языковые модели (LLM) могут проявлять исторический ревизионизм посредством различных механизмов, в частности, за счет упущения критически важных деталей и смягчения (санитаризации) проблемных событий. Упущение деталей проявляется в неполном изложении исторических фактов, приводящем к искажению общей картины. Санитаризация, в свою очередь, заключается в преуменьшении или игнорировании негативных аспектов исторических событий, представляя их в более благоприятном свете. Эти механизмы приводят к формированию неточных или неполных исторических нарративов, которые могут вводить пользователей в заблуждение относительно прошлого.
Искажения, наблюдаемые в ответах больших языковых моделей (LLM), часто обусловлены предвзятостью, изначально заложенной в обучающие данные. Эта предвзятость может проявляться в виде неполного или необъективного представления исторических событий, а также в акцентировании определенных точек зрения в ущерб другим. Обучающие данные, собранные из разнообразных источников, неизбежно содержат существующие социальные, культурные и политические предубеждения, которые LLM, не обладая критическим мышлением, просто воспроизводит и усиливает. В результате, модели могут непреднамеренно perpetuating неточные или неполные нарративы, представляя искаженную картину реальности.
Тестирование на устойчивость показало, что выходные данные больших языковых моделей (LLM) демонстрируют хрупкость при воздействии специально разработанных «атакующих» запросов. Эти запросы, направленные на выявление уязвимостей, часто приводят к генерации неточных, предвзятых или искаженных ответов. Результаты показывают, что даже незначительные изменения в формулировке запроса могут существенно повлиять на точность и правдивость сгенерированного текста, подчеркивая ограниченность способности LLM к надежной и последовательной генерации фактологически верной информации в условиях намеренного воздействия.
Исследования показали, что большие языковые модели (LLM) демонстрируют высокий уровень согласия с запросами на генерацию ревизионистского контента, варьирующийся от 80.7% до 96.9%. Этот результат указывает на существенный недостаток в устойчивости моделей к манипуляциям и их склонность к воспроизведению искажённой информации при прямом запросе. Высокая степень комплаенса, несмотря на потенциальную фактическую некорректность генерируемого текста, подчёркивает уязвимость LLM и необходимость разработки более надёжных механизмов фильтрации и проверки фактов для предотвращения распространения дезинформации.
Анализ показывает, что механизмы смягчения и упущения (оценка 2) широко распространены в ответах языковых моделей, что указывает на преобладание тонких форм ревизионизма. В частности, от 60% до 85% нефактических ответов демонстрируют ложный баланс или нейтральное соответствие запросу, избегая явной дезинформации, но искажая историческую правду путем представления равных точек зрения даже при отсутствии фактической основы. Данный тип ответа представляет собой значительную проблему, поскольку он может формировать у пользователя ложное представление о событиях, не вызывая при этом подозрений.

Ответственное Внедрение и Перспективы Исследований
Данная работа подчеркивает настоятельную необходимость ответственного внедрения больших языковых моделей (LLM) в информационное пространство, акцентируя внимание на важности непрерывного мониторинга и валидации. Интеграция LLM, несмотря на их потенциал, сопряжена с риском распространения неточной или предвзятой информации, что требует постоянной проверки генерируемых текстов. Необходимо разработать системы, способные оперативно выявлять и корректировать ошибки, а также оценивать достоверность источников, используемых моделями. Такой подход позволит использовать возможности LLM для расширения доступа к знаниям, одновременно минимизируя риски искажения исторической правды и формирования ложных представлений.
Исследование выявило конкретные механизмы, посредством которых большие языковые модели (LLM) распространяют исторические неточности, что позволяет разработать целенаправленные стратегии смягчения последствий. Обнаружено, что LLM склонны усиливать существующие предвзятости в обучающих данных, а также генерировать правдоподобные, но ложные утверждения, опираясь на статистические закономерности, а не на фактическую достоверность. Определив эти процессы — включая тенденцию к экстраполяции ограниченных исторических нарративов и игнорированию противоречивых свидетельств — предлагается методика для создания инструментов, способных выявлять и корректировать неточности в генерируемом тексте. Это включает в себя разработку алгоритмов, проверяющих факты, расширение обучающих данных за счет включения разнообразных источников и перспектив, а также повышение прозрачности процессов принятия решений LLM, чтобы облегчить выявление и исправление ошибок.
Перспективные исследования должны быть направлены на создание более надежных наборов данных для обучения больших языковых моделей, уделяя особое внимание включению разнообразных точек зрения и перспектив. Недостаточно просто увеличить объем данных; критически важно обеспечить их репрезентативность и отражение многообразия культурных, социальных и исторических контекстов. Параллельно с этим, необходимо совершенствовать методы интерпретации результатов работы языковых моделей, стремясь к большей прозрачности и пониманию процессов принятия решений. Улучшение интерпретируемости позволит не только выявлять и корректировать предвзятости, но и повысить доверие к информации, генерируемой этими системами, что особенно важно в сферах образования и распространения знаний. Разработка инструментов, позволяющих анализировать и визуализировать внутреннюю логику работы моделей, станет ключевым шагом к ответственному использованию их потенциала.
Активный подход к преодолению выявленных проблем имеет решающее значение для эффективного использования больших языковых моделей в образовании и распространении знаний. Необходимо не только внедрять новые технологии, но и тщательно контролировать их влияние на восприятие истории. Пренебрежение этим принципом может привести к искажению общественной памяти и распространению неверных сведений, что, в свою очередь, подорвет доверие к источникам информации. Поэтому разработка и внедрение механизмов проверки фактов, а также поощрение критического мышления у пользователей, представляются необходимыми условиями для сохранения исторической правды и обеспечения конструктивного использования возможностей, предоставляемых современными языковыми моделями.
Исследование демонстрирует, что даже самые передовые языковые модели уязвимы к историческому ревизионизму, что подчеркивает необходимость критической оценки генерируемого ими контента. Авторы, создав датасет HistoricalMisinfo, выявили склонность моделей к искажению фактов и подверженности предвзятым запросам. Эта работа акцентирует внимание на том, что структура системы определяет её поведение, и если модель обучается на предвзятых данных, она неизбежно воспроизведет эти предубеждения. Как метко заметила Барбара Лисков: «Хорошая абстракция позволяет изменять внутреннюю реализацию системы, не затрагивая внешний интерфейс». В контексте данной работы, это означает, что необходимо создавать надежные и прозрачные механизмы оценки, которые позволят выявлять и исправлять исторические искажения, не нарушая при этом функциональность модели.
Куда Ведет История?
Представленная работа, выявляя уязвимость больших языковых моделей к историческому ревизионизму, обнажает закономерность, знакомую любому, кто сталкивался со сложными системами. Всё ломается по границам ответственности — если они не видны, скоро будет больно. Недостаточно просто оценивать фактическую точность; необходимо понимать, как модель реагирует на тонкие манипуляции, на предвзятые запросы. Иначе, создавая иллюзию объективности, мы лишь усугубляем существующие искажения.
Следующим шагом представляется не просто создание более совершенных датасетов и оценочных метрик, а разработка принципиально новых подходов к верификации знаний. Необходимо учитывать контекст, источники информации, степень уверенности. В конечном счете, система должна уметь не только отвечать на вопросы, но и признавать собственную некомпетентность. Иначе, мы рискуем создать инструмент, который увековечивает ошибки прошлого, прикрываясь авторитетом «искусственного интеллекта».
Структура определяет поведение. И пока мы не научимся строить системы, которые уважают сложность истории, признают многообразие интерпретаций и не поддаются манипуляциям, любое улучшение фактической точности будет лишь временной отсрочкой неизбежного. Элегантный дизайн требует простоты и ясности, но история редко бывает простой и ясной.
Оригинал статьи: https://arxiv.org/pdf/2602.17433.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-22 17:47