Автор: Денис Аветисян
Новый набор данных BankMathBench призван оценить и улучшить способность больших языковых моделей решать численные задачи, возникающие в реальных банковских операциях.
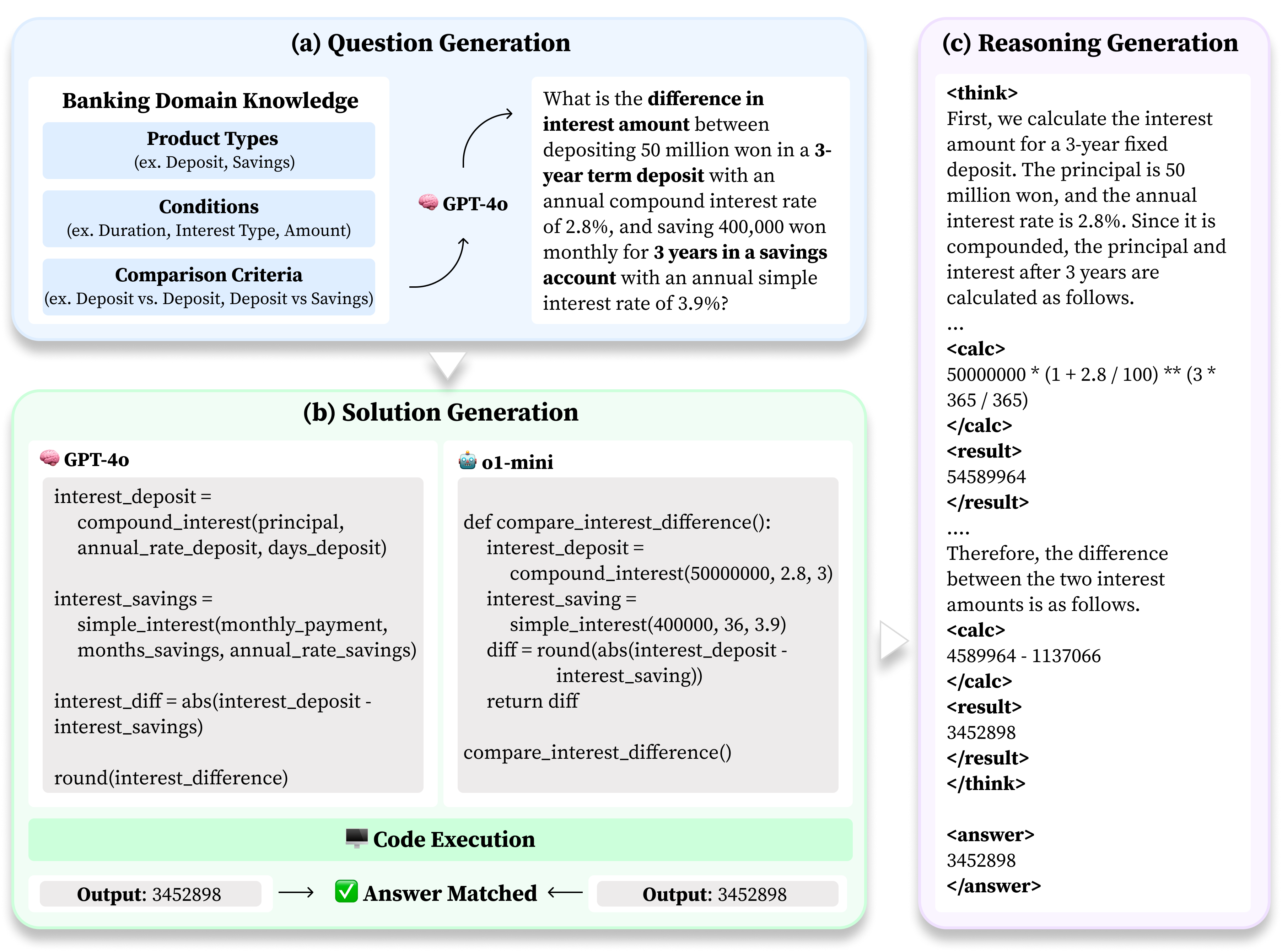
Представлен BankMathBench — эталонный набор данных для оценки и повышения численного рассуждения больших языковых моделей в банковских сценариях, демонстрирующий значительные улучшения за счёт тонкой настройки и расширения возможностей с помощью инструментов.
Несмотря на растущее внедрение больших языковых моделей (LLM) в финансовый сектор, их точность в решении базовых банковских вычислений остается проблемой. В настоящей работе представлена новая специализированная база данных ‘BankMathBench: A Benchmark for Numerical Reasoning in Banking Scenarios’ для оценки и улучшения способности LLM к числовому рассуждению в реалистичных банковских сценариях. Показано, что обучение на BankMathBench значительно повышает точность формулирования и вычислений, особенно при использовании методов дообучения с инструментальной поддержкой, что приводит к приросту точности до 75.1% для задач средней сложности. Может ли BankMathBench стать стандартом для оценки и дальнейшего развития численного интеллекта LLM в сфере финансовых услуг?
Сложность численного мышления в финансах: вызов для современных моделей
Несмотря на впечатляющие успехи в обработке естественного языка, современные большие языковые модели (LLM) сталкиваются со значительными трудностями при решении задач, требующих сложного численного анализа, что особенно критично в финансовой сфере. В то время как LLM демонстрируют способность к генерации текста и пониманию контекста, точность выполнения математических операций и логических выводов, основанных на числовых данных, зачастую оказывается недостаточной для надежного применения в банковском деле, инвестициях и других финансовых приложениях. Эта проблема связана с архитектурными особенностями LLM, которые оптимизированы для работы с текстовой информацией, а не для точных вычислений, и требует разработки специализированных подходов к обучению и оценке моделей для повышения их эффективности в решении финансовых задач.
Традиционные архитектуры больших языковых моделей (LLM) зачастую демонстрируют недостаточную точность в сценариях, связанных с банковским делом и финансами. Это связано с тем, что LLM, изначально разработанные для обработки естественного языка, испытывают трудности при выполнении сложных вычислений и логических операций, необходимых для финансовых задач. Неточности в расчетах, даже незначительные, могут приводить к серьезным ошибкам в принятии решений, влияя на инвестиционные стратегии, оценку рисков и другие критически важные аспекты финансовой деятельности. В отличие от систем, специализирующихся на числовых вычислениях, LLM склонны к ошибкам округления и не всегда последовательны в применении математических правил, что делает их применение в чувствительных к точности финансовых приложениях проблематичным. Для решения этой проблемы требуется разработка новых архитектур или адаптация существующих, направленных на повышение точности числовых расчетов и обеспечение надежности в финансовых сценариях.
Оценка возможностей больших языковых моделей (LLM) в финансовой сфере требует создания специализированных критериев, отражающих реальную сложность финансовых операций и рынков. Существующие наборы данных и метрики зачастую упрощают финансовые задачи, не учитывая нюансы, такие как волатильность активов, риски контрагентов и регуляторные ограничения. Это создает значительную проблему, поскольку модели, успешно проходящие тесты на упрощенных данных, могут демонстрировать существенные ошибки при работе с реальными финансовыми сценариями. Необходимы комплексные бенчмарки, включающие широкий спектр финансовых задач — от анализа отчетов до прогнозирования рыночных трендов и оценки кредитных рисков — для достоверной оценки пригодности LLM к применению в банковской сфере и инвестиционном менеджменте. Разработка таких инструментов позволит более точно выявить слабые места моделей и направить усилия по их совершенствованию в наиболее критичные области.

BankMathBench: Строгий критерий оценки численного мышления
BankMathBench представляет собой специализированный оценочный набор данных, предназначенный для анализа численных рассуждений больших языковых моделей (LLM) в контексте типичных банковских операций. Набор данных охватывает основные банковские продукты, такие как депозиты, сберегательные счета и кредиты, и включает в себя задачи, требующие выполнения математических вычислений и логических выводов, характерных для финансовых сценариев. BankMathBench предназначен для количественной оценки способности LLM решать практические задачи, связанные с финансовыми расчетами и принятием решений в банковской сфере.
Для создания разнообразного и всестороннего набора данных финансовых задач, включающего вопросы, решения и шаги рассуждений, был разработан автоматизированный конвейер генерации данных, работающий на базе модели GPT-4o. Этот конвейер использует возможности GPT-4o для автоматической генерации проблем, соответствующих типичным банковским сценариям, и последующего создания пошаговых решений. Каждый сгенерированный пример включает в себя исходный вопрос, точное числовое решение и подробное описание процесса рассуждений, ведущего к ответу. Автоматизация процесса позволяет масштабировать создание набора данных и обеспечивать его согласованность, что необходимо для объективной оценки и улучшения производительности больших языковых моделей (LLM) в области финансовых вычислений.
Автоматизированный конвейер генерации данных обеспечивает масштабируемость и воспроизводимость процесса создания набора данных BankMathBench. Использование GPT-4o в качестве основы конвейера позволяет генерировать большое количество финансовых задач с решениями и обоснованиями, что необходимо для всесторонней оценки производительности больших языковых моделей (LLM). Возможность непрерывной генерации данных позволяет регулярно проводить оценку LLM, выявлять слабые места и отслеживать прогресс в улучшении их способности к числовому рассуждению в банковских сценариях, обеспечивая надежную основу для дальнейшей разработки и оптимизации моделей.
Улучшение производительности LLM: тонкая настройка и расширение возможностей
Применение методов тонкой настройки предварительно обученных больших языковых моделей (LLM), таких как QLoRA, демонстрирует значительное повышение их производительности в решении задач BankMathBench. Это позволяет моделям улучшить понимание и решение финансовых задач, достигая прироста точности до 72.7% на промежуточных и продвинутых наборах данных. Тонкая настройка позволяет адаптировать общую языковую способность модели к специфике финансовых расчетов и логических выводов, что критически важно для достижения высокой точности в этой области.
Интеграция внешних инструментов, таких как калькуляторы, в архитектуру больших языковых моделей (LLM) значительно повышает точность и надежность выполнения численных расчетов. Использование Tool Augmentation позволяет LLM делегировать сложные арифметические операции специализированным инструментам, избегая ошибок, возникающих при непосредственном выполнении вычислений самой моделью. Это особенно важно для задач, требующих высокой точности, таких как финансовые расчеты или научные вычисления, где даже небольшие погрешности могут привести к значительным последствиям. По сути, Tool Augmentation расширяет возможности LLM, позволяя ей эффективно использовать существующие инструменты для решения конкретных задач и повышая общую производительность.
Оценка эффективности стратегий оптимизации, таких как тонкая настройка, осуществляется с использованием метрики точного совпадения (Exact-Match Accuracy). Применение данной метрики к модели Qwen3-8B на продвинутом корейском наборе данных показало достижение точности в 54.4% после тонкой настройки. Важно отметить, что дисперсия результатов снизилась с σ = 15.8 до σ = 9.5, что свидетельствует о повышении стабильности и надежности модели после оптимизации. Данный показатель позволяет объективно сравнивать различные подходы к улучшению производительности больших языковых моделей.

Расширение языкового охвата и обеспечение надежности моделей
Набор данных BankMathBench был расширен за счет включения примеров на корейском языке, что значительно увеличивает возможности применения больших языковых моделей (LLM) в глобальном финансовом секторе. Это нововведение позволяет оценивать производительность LLM не только в англоязычной среде, но и в контексте финансовых задач, специфичных для корейского рынка. Включение примеров на корейском языке не просто расширяет географию применения моделей, но и способствует развитию более универсальных и адаптивных финансовых инструментов, способных обрабатывать данные и решать задачи в различных лингвистических и культурных контекстах. Результаты показывают, что после тонкой настройки модели демонстрируют высокую точность и надежность при работе с финансовыми данными на корейском языке, что открывает новые перспективы для автоматизации и оптимизации финансовых процессов в различных странах.
Включение примеров на корейском языке в датасет BankMathBench принципиально расширяет возможности оценки больших языковых моделей (LLM) за пределами англоязычной среды. Такой подход не просто увеличивает охват, но и обеспечивает более справедливую и всеобъемлющую оценку, учитывая потребности и особенности пользователей, для которых английский язык не является родным. Это способствует созданию более инклюзивных финансовых инструментов и сервисов, делая их доступными для более широкой аудитории и снижая риск предвзятости, связанной с лингвистическими ограничениями в исходных данных. Подобное расширение лингвистического охвата критически важно для глобальной применимости и этичности разрабатываемых моделей в сфере финансовых технологий.
Включение разнообразных лингвистических данных значительно повышает устойчивость и обобщающую способность больших языковых моделей (LLM) в практических финансовых приложениях. Проведенные исследования показали, что после тонкой настройки, модели демонстрируют медианную относительную погрешность в 1.28% для корейского и 1.89% для английского языка, при этом использование инструментов для дополнения данных практически сводит эту погрешность к нулю. В частности, модель Qwen3-8B после тонкой настройки продемонстрировала увеличение точности на 42.0% для корейского и 44.6% для английского языков при решении задач базового уровня, что подтверждает эффективность многоязычного подхода к обучению и оценке LLM в финансовой сфере.
Представленная работа демонстрирует стремление к упрощению сложного. Создание BankMathBench, как эталонного набора данных для оценки численного рассуждения, подчеркивает необходимость ясности в оценке возможностей больших языковых моделей в практических банковских сценариях. Авторы не стремятся к избыточной сложности, а концентрируются на создании эффективного инструмента для измерения и улучшения конкретных навыков. Как заметил Линус Торвальдс: «Я предпочитаю решение, которое работает, даже если оно не элегантно, элегантному решению, которое не работает». Это особенно актуально в контексте BankMathBench, где главная цель — надежность и точность численных расчетов, а не абстрактная красота алгоритмов.
Что дальше?
Представленный набор данных, BankMathBench, бесспорно, фиксирует определённый уровень сложности в области численного рассуждения, применительно к банковским сценариям. Однако, иллюзия прогресса часто маскирует глубину нерешённых вопросов. Улучшение показателей посредством тонкой настройки и использования внешних инструментов — это не столько прорыв, сколько демонстрация способности моделей к запоминанию и механическому применению процедур. Истинное понимание, способность к абстракции и обобщению, остаются за пределами текущего досягаемого.
Будущие исследования должны сместить фокус с количественной оценки на качественный анализ. Необходимо не просто увеличивать точность, но и исследовать природу ошибок, выявлять случаи, когда модель демонстрирует видимость понимания, не обладая им на самом деле. Особое внимание следует уделить созданию наборов данных, требующих не просто численных вычислений, но и интерпретации контекста, понимания финансовых принципов и способности к критическому мышлению.
В конечном счёте, ценность подобных работ определяется не столько достигнутыми результатами, сколько умением признать границы текущего знания. Стремление к совершенству заключается не в увеличении сложности, а в достижении максимальной ясности, в выявлении и устранении фундаментальных ограничений, а не в их маскировке под впечатляющими метриками.
Оригинал статьи: https://arxiv.org/pdf/2602.17072.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- HYPE ПРОГНОЗ. HYPE криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-20 15:32