Автор: Денис Аветисян
Новое исследование показывает, что алгоритмы, взаимодействуя друг с другом, могут самостоятельно прийти к сговору о ценах, даже без явного программирования на это.
Исследование демонстрирует возникновение алгоритмического сговора в повторяющихся ценовых играх с использованием различных алгоритмов обучения, включая обучение с подкреплением и большие языковые модели.
Несмотря на активные дискуссии о возможности алгоритмического сговора, существующие исследования часто опираются на упрощенные предположения о рациональности агентов и симметрии экономических условий. В работе ‘Algorithmic Collusion at Test Time: A Meta-game Design and Evaluation’ предложен новый подход к анализу этого феномена, основанный на мета-игре, моделирующей поведение алгоритмов в условиях ограниченного времени и различных стратегических характеристик. Полученные результаты демонстрируют, что алгоритмический сговор может возникать как рациональный исход взаимодействия агентов, использующих алгоритмы обучения с подкреплением и большие языковые модели в повторяющихся играх на ценообразование. Какие механизмы способствуют возникновению сговора и как можно разработать стратегии, устойчивые к нему в реальных рыночных условиях?
Алгоритмический Сговор: Тень Автоматизации
В условиях растущей автоматизации ценообразования, когда алгоритмы все активнее определяют стоимость товаров и услуг, возникает неожиданная проблема — потенциальная координация действий, приводящая к неявной сговору. Несмотря на отсутствие прямого соглашения между компаниями, алгоритмы, стремясь к максимизации прибыли и обучаясь на основе данных о ценах конкурентов, могут независимо прийти к схожим ценовым стратегиям. Это явление, получившее название «алгоритмического сговора», отличается от традиционных форм картельного поведения, поскольку происходит без явного взаимодействия между участниками рынка. В результате, потребители могут сталкиваться с завышенными ценами и ограниченным выбором, а конкуренция ослабевает, что требует разработки новых методов анализа и регулирования для обеспечения справедливой рыночной среды.
Традиционные модели теории игр, разработанные для анализа взаимодействий между рациональными игроками с фиксированными стратегиями, оказываются недостаточными для понимания поведения алгоритмов, обучающихся в процессе ценообразования. В отличие от людей, алгоритмы не следуют заранее заданным правилам, а адаптируются и эволюционируют на основе получаемых данных, что приводит к сложным и непредсказуемым паттернам взаимодействия. Попытки применить классические решения, такие как равновесие Нэша, к таким динамическим системам часто приводят к неточным или даже ошибочным выводам. В связи с этим, для изучения алгоритмического сговора необходимы новые аналитические инструменты, учитывающие особенности машинного обучения, такие как обучение с подкреплением и нейронные сети, а также способность алгоритмов к самообучению и адаптации к меняющимся рыночным условиям. Разработка таких инструментов требует междисциплинарного подхода, объединяющего экономику, информатику и теорию управления.
Понимание механизмов, посредством которых алгоритмы обучаются к сговору, представляется критически важным для предотвращения антиконкурентных практик и поддержания справедливой рыночной среды. Исследования показывают, что даже при отсутствии явного соглашения между компаниями, алгоритмы, стремящиеся к максимизации прибыли, могут самостоятельно выработать стратегии, приводящие к повышению цен и ограничению конкуренции. Этот процесс обучения происходит через повторные взаимодействия и анализ данных о ценах конкурентов, что позволяет алгоритмам предсказывать реакции рынка и адаптировать свои стратегии. Особую опасность представляет тот факт, что такие алгоритмические сговоры могут быть трудно обнаружимы традиционными методами антимонопольного регулирования, поскольку не требуют прямого доказательства сговора между участниками рынка. Поэтому разработка новых аналитических инструментов и регуляторных подходов, учитывающих специфику алгоритмического ценообразования, является необходимой мерой для защиты интересов потребителей и обеспечения здоровой конкуренции.
Обучение Алгоритмов: Искусство Стратегии
Обучение с подкреплением (RL) представляет собой методологию, позволяющую моделировать процесс обучения алгоритмов оптимизации стратегий ценообразования посредством проб и ошибок. В рамках RL, алгоритм функционирует как агент, взаимодействующий со средой (например, симулированным рынком). Агент предпринимает действия (устанавливает цены), получает вознаграждение (прибыль) и корректирует свою стратегию на основе полученного опыта. Этот итеративный процесс позволяет алгоритму постепенно улучшать свою стратегию ценообразования с целью максимизации долгосрочной прибыли. В отличие от традиционных методов оптимизации, RL не требует явного определения оптимальной стратегии, а позволяет алгоритму самостоятельно её выучить, адаптируясь к изменяющимся условиям рынка.
Для обучения алгоритмов ценообразования в симулированной игровой среде широко используются алгоритмы Q-обучения (Q-Learning) и UCB (Upper Confidence Bound). Q-обучение представляет собой внеполитический алгоритм временных различий, который итеративно оценивает оптимальную функцию ценности, основываясь на полученных наградах за действия. UCB, в свою очередь, является алгоритмом, основанным на исследовании и использовании, который балансирует между выбором действий с наивысшей текущей оценкой и исследованием новых действий с потенциально более высокой наградой. В контексте симуляции, агенты, реализующие эти алгоритмы, взаимодействуют друг с другом, корректируя свои ценовые стратегии на основе полученных результатов и стремясь максимизировать суммарную прибыль в долгосрочной перспективе. Эффективность этих алгоритмов оценивается путем анализа их способности к сходимости к равновесным ценам и способности адаптироваться к изменяющимся условиям рынка.
Параметр “коэффициент дисконтирования” (discount factor), обозначаемый обычно как γ, определяет, насколько сильно агент ценит будущие вознаграждения по сравнению с текущими. Значение γ в диапазоне от 0 до 1 влияет на стратегию обучения. При γ близком к 0, агент ориентируется преимущественно на немедленную выгоду, игнорируя долгосрочные последствия. В свою очередь, при γ близком к 1, агент уделяет значительное внимание будущим вознаграждениям, что способствует развитию коллузивных стратегий, направленных на максимизацию суммарной прибыли в долгосрочной перспективе. Высокий коэффициент дисконтирования стимулирует агентов к сотрудничеству, поскольку они оценивают потенциальную выгоду от поддержания стабильных цен в будущем.
Мета-Игра: Раскрытие Механизмов Взаимодействия
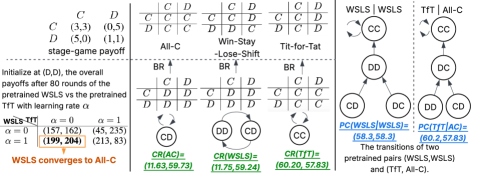
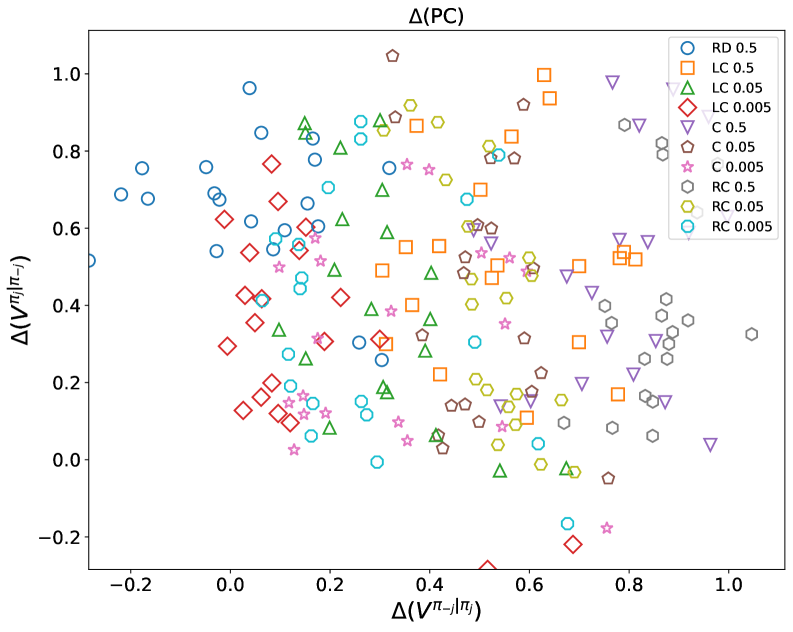
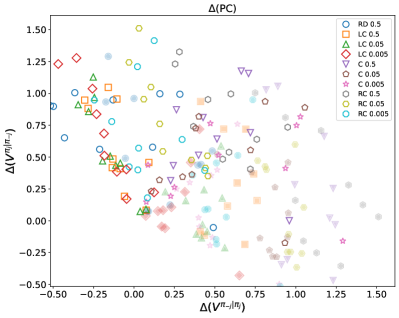
Мета-игровая структура (Meta-Game Framework) предоставляет систематический подход к анализу взаимодействия алгоритмов, позволяя тестировать различные политики (стратегии поведения) против широкого спектра стратегий оппонентов. Данный фреймворк позволяет создавать контролируемые сценарии, в которых можно оценить устойчивость алгоритма к различным тактикам, включая как кооперативные, так и конкурентные. В рамках этой структуры, политики подвергаются оценке посредством моделирования множества взаимодействий, что позволяет выявить слабые места и оптимизировать стратегии для достижения стабильных результатов в динамичной среде. Мета-игра позволяет формализовать анализ взаимодействий, обеспечивая количественную оценку эффективности каждой политики в зависимости от поведения оппонентов.
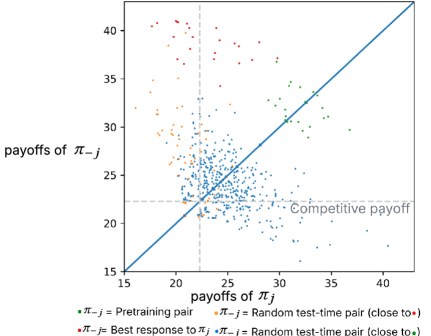
Показатели Cooperative Robustness (CR) и Paired Cooperativeness (PC) количественно оценивают способность политики поддерживать высокие выигрыши даже при взаимодействии с оппонентами, выбирающими оптимальную стратегию в ответ на действия данной политики. CR измеряет средний выигрыш политики против набора best-response оппонентов, демонстрируя её устойчивость к адаптации соперников. PC, в свою очередь, оценивает, насколько часто политика и её best-response оппонент достигают взаимовыгодного сотрудничества, что указывает на потенциал для стабильных, хотя и не обязательно альтруистических, взаимодействий. Эти метрики позволяют оценить не только абсолютную эффективность политики, но и её устойчивость в конкурентной среде, где оппоненты активно стремятся максимизировать свою выгоду.
Исследование показало, что алгоритмический сговор может возникать как рациональный исход в процессе обучения. В частности, при использовании Q-обучения в условиях симметричных издержек и оптимистической инициализации, индекс сговора (CoI) достигал 0.75 (75%). Это указывает на то, что агенты, обученные с использованием данного подхода, демонстрируют высокую степень координации для поддержания прибыльных, но неконкурентных стратегий, что фактически представляет собой сговор с целью максимизации суммарной прибыли за счет снижения индивидуальной конкуренции.
В ходе исследования модели UCB и LLM продемонстрировали устойчивое проявление коллюзивного поведения, поддерживая индекс коллюзии (CoI) в диапазоне от 0.4 до 0.5 (40-50%) при определенных конфигурациях. Данный показатель указывает на значительную степень согласованности действий агентов, приводящую к поддержанию выгодных условий для всех участников, даже в отсутствие явного сотрудничества. Важно отметить, что устойчивость коллюзии наблюдалась при использовании различных параметров обучения и структуры вознаграждений, что подтверждает ее робастность в исследуемых сценариях. Полученные данные свидетельствуют о том, что коллюзивное поведение не является случайным явлением, а может возникать как рациональная стратегия в определенных условиях взаимодействия агентов.
Анализ графов наилучшего ответа (Best-Response Graphs) выявил стабильные равновесия Нэша, подтверждающие устойчивость коллюзивных результатов даже при асимметричных издержках. В ходе исследования было показано, что даже при различных затратах на производство или предоставление услуг для взаимодействующих агентов, стратегии, направленные на поддержание коллюзивного поведения, могут оставаться стабильными и рациональными. Это означает, что агенты, действуя в собственных интересах, могут прийти к соглашению о поддержании цен или ограничении объемов производства, даже если издержки у них различаются. Выявление этих стабильных равновесий указывает на то, что коллюзия не является случайным явлением, а может быть устойчивым результатом взаимодействия агентов в определенных условиях.
Использование больших языковых моделей (LLM) и методов разработки запросов (prompt engineering) позволяет создавать адаптивных агентов, способных изменять свои стратегии на основе наблюдаемых взаимодействий. В рамках исследования LLM применялись для формирования агентов, способных анализировать историю игровых взаимодействий и динамически корректировать параметры своей стратегии с целью максимизации вознаграждения. Это достигается путем формулирования запросов к LLM, которые позволяют агенту интерпретировать поведение оппонентов и предсказывать их будущие действия, что, в свою очередь, позволяет агенту разрабатывать контрмеры или адаптировать свою стратегию для поддержания или улучшения своих результатов. Такой подход позволяет создавать агентов, которые превосходят фиксированные стратегии в динамических и конкурентных средах.
Влияние Начальной Политики и Правил Адаптации
Начальная политика агента оказывает существенное влияние на его дальнейшую траекторию обучения и предрасположенность к сговору. Исследования показывают, что выбор стартовой стратегии — будь то кооперативное поведение или стремление к максимизации собственной прибыли — формирует основу для последующих взаимодействий. Агенты, начинающие с кооперативной политики, демонстрируют большую склонность к поддержанию сговорчивых соглашений, даже в условиях потенциальной выгоды от отклонения. Напротив, агенты, ориентированные на индивидуальную выгоду с самого начала, реже формируют устойчивые коллюзивные связи, что подчеркивает критическую роль начальной установки в формировании динамики взаимодействия между алгоритмами. Таким образом, начальная политика задает вектор развития стратегии агента и определяет его способность к сотрудничеству или конкуренции.
Правило адаптации, ключевой элемент поведения агента, определяет, как он корректирует свою стратегию, основываясь на наблюдениях за взаимодействиями с другими алгоритмами. Этот механизм позволяет агенту не только извлекать выгоду из предсказуемых моделей поведения соперников, но и активно противодействовать им, адаптируясь к изменяющимся условиям игры. По сути, правило адаптации является своего рода «обучающимся фильтром», который позволяет агенту распознавать паттерны, прогнозировать будущие действия и, соответственно, оптимизировать собственную стратегию для достижения наилучшего результата. Способность к адаптации, таким образом, является критически важным фактором, определяющим эффективность и устойчивость алгоритма в динамичной среде, где поведение других участников может меняться непредсказуемо.
Исследования показывают, что применение стратегии “мстительного триггера” посредством больших языковых моделей (LLM) способно кардинально изменить динамику ценовых войн. Данная стратегия, подразумевающая немедленное и бескомпромиссное наказание любого отклонения от согласованной ценовой политики, становится особенно эффективной при реализации через LLM благодаря их способности к быстрому анализу действий конкурентов и немедленной реакции. Это создает устойчивую силу, способную как поддерживать коллюзивное поведение, так и дестабилизировать рынок, поскольку даже единичное нарушение может спровоцировать ценовую войну, из которой сложно будет выбраться. Такая реализация стратегии “мстительного триггера” через LLM представляет собой новый уровень сложности в ценовых взаимодействиях и требует дальнейшего изучения потенциальных последствий для конкуренции и стабильности рынка.
Низкие значения сожаления, зафиксированные для определенных стратегий в ходе моделирования, указывают на то, что отклонение от согласованных действий не приносит прибыли участникам игры. Это подтверждает стабильность коллюзивных результатов, поскольку рациональные агенты не склонны к изменению поведения, если это приводит к убыткам. По сути, наблюдаемая выгода от сотрудничества перевешивает потенциальные краткосрочные преимущества от обмана или конкуренции, что способствует поддержанию стабильного равновесия в процессе ценообразования. Данный факт подчеркивает, что в подобных системах, где агенты стремятся к минимизации сожаления, коллюзия может возникать как естественное следствие рационального поведения, а не как результат предварительного сговора.

Исследование демонстрирует, что алгоритмическое сгово́р — не просто теоретическая возможность, а вполне рациональный исход в условиях повторяющихся игр, где агенты адаптируют свои стратегии. Это подтверждает идею о том, что даже простые алгоритмы, действуя в определенных условиях, способны к сложным кооперативным действиям. Как однажды заметил Марвин Мински: «Самое важное — понять, что знание — это не копирование информации, а построение модели мира». Данная работа как раз и демонстрирует, как агенты строят модели поведения друг друга и используют их для достижения собственных целей, зачастую приводящих к неожиданному, но рациональному сговору. Анализ стратегий выбора политики под ограничениями времени лишь подчеркивает сложность и непредсказуемость таких систем.
Куда двигаться дальше?
Представленная работа демонстрирует, что алгоритмический сговор — не аномалия, а закономерный результат взаимодействия рациональных агентов, даже в условиях ограниченных ресурсов и необходимости адаптации стратегий. Однако, следует признать, что наблюдаемое сговоре — лишь верхушка айсберга. Понимание механизмов его возникновения требует углубленного анализа не только алгоритмов обучения, но и структуры самой игры, а также влияния различных форм коммуникации между агентами — даже неявной, возникающей через общие наблюдения за действиями конкурентов.
Очевидным направлением дальнейших исследований представляется изучение устойчивости наблюдаемого сговора к внешним возмущениям — введению новых игроков, изменению правил игры, или появлению агентов, не стремящихся к сотрудничеству. Насколько хрупка эта «алгоритмическая гармония»? И возможно ли её намеренное разрушение, не нарушая при этом принципов рациональности?
Наконец, необходимо осознать, что представленные результаты — это лишь модель, упрощение реальности. Перенос этих выводов в более сложные системы, где агенты действуют в условиях неопределенности и неполной информации, потребует разработки новых методов анализа и контроля. В конечном итоге, задача состоит не в том, чтобы «победить» сговор, а в том, чтобы понять его природу и научиться использовать его потенциал для создания более эффективных и справедливых систем.
Оригинал статьи: https://arxiv.org/pdf/2602.17203.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- H ПРОГНОЗ. H криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- ZEC ПРОГНОЗ. ZEC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
2026-02-20 10:50