Автор: Денис Аветисян
Исследование демонстрирует, как большие языковые модели могут автоматизировать разработку алгоритмов для обучения нескольких агентов, открывая возможности для создания инновационных стратегий в сложных играх.
В статье показано, что большие языковые модели способны не просто настраивать параметры существующих алгоритмов, а эволюционировать код, создавая принципиально новые подходы к обучению мультиагентных систем в условиях неполной информации.
Разработка алгоритмов обучения с подкреплением для многоагентных сред часто требует трудоемкой ручной настройки и эвристических подходов. В работе ‘Discovering Multiagent Learning Algorithms with Large Language Models’ предлагается автоматизировать этот процесс, используя эволюционные алгоритмы, управляемые большими языковыми моделями, для поиска новых стратегий в играх с неполной информацией. Авторы продемонстрировали, что данный подход позволяет создавать эффективные алгоритмы, такие как VAD-CFR и SHOR-PSRO, превосходящие существующие решения за счет нетривиальных механизмов, автоматизированного перехода от исследования к эксплуатации и адаптивного управления дисконтированием. Не откроет ли это путь к созданию принципиально новых алгоритмов обучения, превосходящих возможности, заданные человеческой интуицией?
Ограничения ручного проектирования алгоритмов
Традиционные алгоритмы теории игр, такие как DCFR и PCFR+, демонстрируют высокую эффективность лишь при условии тщательной ручной настройки параметров. Этот процесс требует глубокого понимания как самой игры, так и принципов работы алгоритма, а также значительных временных затрат со стороны экспертов. Настройка включает в себя оптимизацию различных аспектов, включая стратегию выбора действий, частоту обновлений и параметры обучения, чтобы добиться оптимальной производительности в конкретной игровой среде. Без этой тонкой настройки алгоритмы зачастую демонстрируют суб-оптимальное поведение, неспособное конкурировать с более простыми, но правильно адаптированными стратегиями. Таким образом, зависимость от ручной настройки становится серьезным препятствием для широкого применения этих мощных алгоритмов в более сложных и динамичных игровых сценариях.
Зависимость от экспертных знаний создает узкое место в развитии алгоритмов, особенно в сложных областях. Традиционные подходы, требующие ручной настройки и глубокого понимания предметной области, замедляют прогресс и ограничивают способность систем адаптироваться к новым ситуациям. Необходимость привлечения высококвалифицированных специалистов для каждого конкретного сценария становится серьезным препятствием для масштабирования и широкого применения алгоритмов, поскольку не позволяет оперативно реагировать на изменения в окружающей среде или решать задачи в областях, где таких экспертов недостаточно. Это, в свою очередь, сдерживает инновации и препятствует автоматизации сложных процессов, требующих гибкости и способности к самообучению.
Разработка алгоритмов, основанная на ручной настройке, представляет собой трудоемкий и длительный процесс, особенно применительно к сложным игровым сценариям. Каждая итерация требует значительных усилий экспертов для анализа результатов и внесения корректировок, что замедляет прогресс и ограничивает возможности масштабирования. По мере увеличения сложности игры, количество параметров, требующих ручной оптимизации, экспоненциально растет, что делает традиционный подход практически невозможным. В результате, алгоритмы, созданные таким образом, зачастую оказываются неспособными эффективно работать в динамически меняющихся условиях или в играх с большим количеством участников и стратегий, подчеркивая необходимость в автоматизированных подходах к разработке алгоритмов.
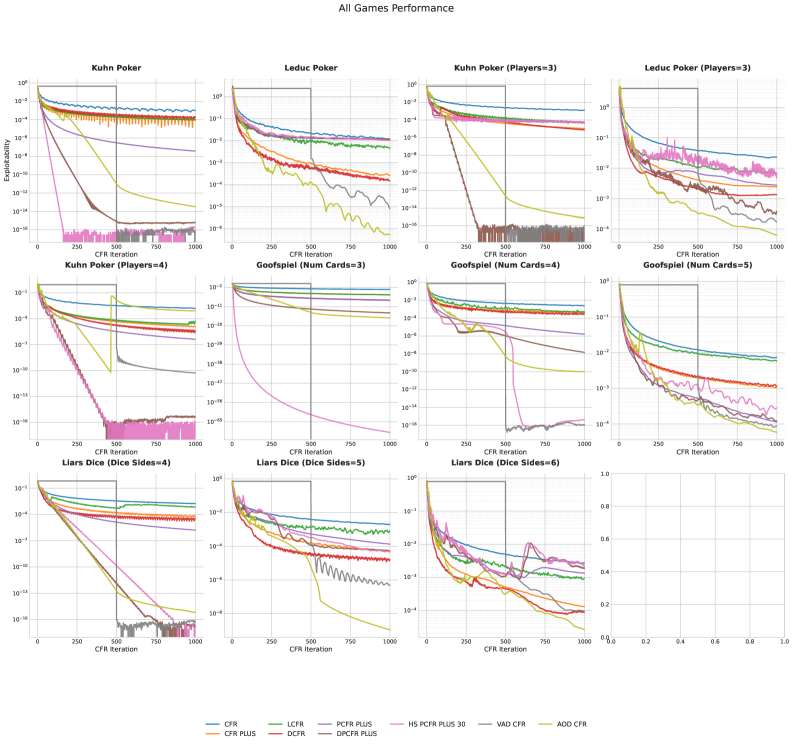
Автоматизация проектирования алгоритмов с помощью AlphaEvolve
AlphaEvolve представляет собой распределенную эволюционную систему, предназначенную для автоматизированной разработки алгоритмов, используемых в теории игр. Система функционирует путем итеративного улучшения алгоритмов, используя принципы эволюционного вычисления. Распределенная архитектура позволяет параллельно оценивать и мутировать множество алгоритмов, значительно ускоряя процесс поиска оптимальных решений. В основе системы лежит концепция автоматического проектирования алгоритмов, освобождающая разработчиков от рутинных задач и позволяющая исследовать более широкий спектр возможных решений в сложных игровых сценариях.
В системе AlphaEvolve для эволюции алгоритмов используются большие языковые модели (LLM), такие как Gemini, осуществляющие семантическую модификацию кода. В отличие от традиционных эволюционных алгоритмов, применяющих случайные мутации, AlphaEvolve анализирует смысл кода и вносит изменения, направленные на улучшение производительности, основываясь на понимании логики алгоритма. Этот подход позволяет сохранять функциональность и структуру кода при внесении изменений, что повышает эффективность и скорость эволюционного процесса и позволяет избежать деградации производительности, часто возникающей при случайных мутациях.
Автоматизация процесса разработки алгоритмов в AlphaEvolve позволяет значительно ускорить инновации и достичь новых уровней производительности в сложных играх, особенно в областях, связанных с теорией игр. Система способна генерировать алгоритмы, превосходящие существующие решения в определенных игровых сценариях, благодаря чему обеспечивается достижение передовых результатов. Это достигается за счет оптимизации и улучшения алгоритмов без необходимости ручного вмешательства, что позволяет исследователям и разработчикам сосредоточиться на более высоких уровнях абстракции и стратегическом планировании.
Эволюция за пределы традиционного CFR: VAD-CFR и SHOR-PSRO
Алгоритм VAD-CFR, разработанный в рамках AlphaEvolve, представляет собой модификацию алгоритма Counterfactual Regret Minimization (CFR), использующую механизм динамической адаптации параметров дисконтирования посредством Volatility-Adaptive Discounting. В отличие от стандартного CFR, где параметры дисконтирования фиксированы, VAD-CFR автоматически корректирует их значение на основе волатильности игрового процесса. Это позволяет алгоритму более эффективно исследовать пространство стратегий, особенно в сложных играх с высокой степенью неопределенности, что приводит к улучшению сходимости и снижению exploitability. Использование адаптивного дисконтирования позволяет VAD-CFR более оперативно реагировать на изменения в стратегии противника и находить оптимальные решения в условиях динамичного игрового окружения.
Алгоритм SHOR-PSRO представляет собой усовершенствованную версию Policy-Space Response Oracles (PSRO), предназначенную для повышения скорости сходимости. Улучшение достигается за счет внедрения гибридного правила обновления (Hybrid Update Rule), которое комбинирует различные стратегии обновления политик для более эффективного исследования пространства стратегий. Дополнительно, в алгоритм включен график отжига (Annealing Schedule), который динамически регулирует параметры обучения в процессе тренировки, способствуя более стабильной и быстрой сходимости к оптимальным стратегиям. Данные нововведения позволяют SHOR-PSRO превосходить стандартный PSRO в задачах, требующих эффективного исследования больших пространств стратегий.
Алгоритмы, разработанные в рамках AlphaEvolve, такие как VAD-CFR и SHOR-PSRO, продемонстрировали превосходство над алгоритмами, созданными вручную, в сложных игровых сценариях. В ходе тестирования на различных играх достигнута эксплуатируемость менее 10-3, что свидетельствует о высокой устойчивости стратегий. AlphaEvolve превзошел современные аналоги (SOTA) в 8 из 11 протестированных игр, а также показал более быструю сходимость в процессе обучения, особенно в рамках алгоритма PSRO.
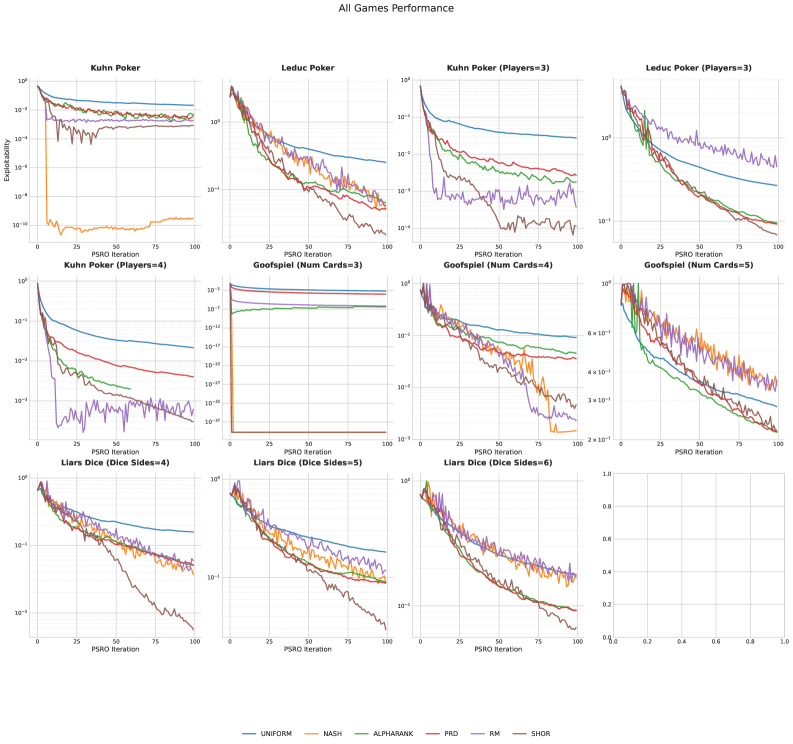
Влияние на многоагентное обучение с подкреплением и за его пределами
Автоматическое проектирование алгоритмов открывает широкие перспективы в области многоагентного обучения с подкреплением, позволяя создавать агентов, способных обучаться и адаптироваться в сложных и динамичных средах. Вместо ручной разработки, требующей значительных усилий и экспертных знаний, системы вроде AlphaEvolve способны самостоятельно генерировать и оптимизировать алгоритмы, предназначенные для взаимодействия нескольких агентов. Это особенно важно в сценариях, где агенты должны координировать свои действия для достижения общих целей, например, в робототехнике, управлении транспортными потоками или даже в экономических моделях. Возможность автоматической адаптации алгоритмов к изменяющимся условиям среды делает систему более устойчивой и эффективной, позволяя агентам успешно функционировать в ситуациях, которые ранее были бы непредсказуемыми или требовали постоянного вмешательства человека.
Подход, реализованный в AlphaEvolve, не ограничивается рамками теории игр, представляя собой мощную платформу для автоматизации проектирования алгоритмов в самых различных областях. Эта система способна генерировать и оптимизировать алгоритмы, применимые не только к стратегическим взаимодействиям, но и к задачам, возникающим в робототехнике, управлении ресурсами, финансовом моделировании и многих других дисциплинах. Способность AlphaEvolve адаптировать алгоритмическую структуру под конкретные требования задачи открывает новые возможности для решения сложных проблем, ранее требовавших значительных усилий по ручному проектированию и настройке. Вместо того чтобы полагаться на предвзятые представления исследователей, система самостоятельно исследует пространство алгоритмов, находя оптимальные решения, которые могут превзойти существующие подходы и привести к прорывам в различных областях науки и техники.
Переход от ручного создания алгоритмов к их автоматическому обнаружению, реализованный в AlphaEvolve, знаменует собой наступление новой эры в области алгоритмических инноваций. Традиционно, разработка алгоритмов требовала значительных усилий и экспертных знаний, представляя собой трудоемкий и итеративный процесс. AlphaEvolve предлагает принципиально иной подход, позволяя системе самостоятельно генерировать и оптимизировать алгоритмы, превосходящие по эффективности разработанные вручную. Это открывает перспективы для решения сложных задач в различных областях, от робототехники и управления ресурсами до финансового моделирования и научных исследований, где адаптивные и самообучающиеся алгоритмы могут существенно повысить производительность и эффективность систем.
Исследование демонстрирует, что сложные алгоритмы обучения мультиагентов могут быть найдены не путем ручной настройки параметров, а через эволюцию самого кода. Это подтверждает философию упрощения и избавления от избыточности. Как однажды заметил Линус Торвальдс: «Единственный способ сделать что-то круто — это начать делать». Поиск оптимальных стратегий в играх с неполной информацией требует ясности и элегантности решения. Эволюция кода, управляемая большими языковыми моделями, позволяет достичь этой ясности, создавая алгоритмы, которые легко понять и реализовать, а значит — и улучшить. Стремление к понятности — это не просто вежливость, но и залог успеха в разработке сложных систем.
Что дальше?
Представленная работа, хотя и демонстрирует потенциал больших языковых моделей в автоматизации проектирования алгоритмов обучения для многоагентных систем, обнажает более глубокую проблему: не столько в создании новых алгоритмов, сколько в понимании принципов, лежащих в основе эффективного обучения в сложных, неполноценных информационных средах. Эволюция кода, хоть и плодотворна, остается, по сути, методом «грубой силы». Более элегантное решение потребует не просто генерации вариантов, но и построения формальных моделей, предсказывающих эффективность алгоритма до его реализации.
Ограничением остается зависимость от специфики игровой среды. Перенос разработанных стратегий на принципиально иные задачи, не являющиеся играми в привычном понимании, представляется нетривиальным. Необходимо исследовать, возможно ли извлечение общих принципов обучения, инвариантных к конкретному контексту. Иначе, прогресс останется набором специализированных решений, лишенных универсальности.
В конечном итоге, истинный вызов заключается в преодолении парадокса: автоматизация творчества. Можно ли создать систему, способную не просто генерировать алгоритмы, но и оценивать их эстетическую ценность — то есть, их простоту, элегантность и общую интеллектуальную красоту? Лишь тогда можно будет говорить о настоящем прорыве, выходящем за рамки простой оптимизации производительности.
Оригинал статьи: https://arxiv.org/pdf/2602.16928.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- H ПРОГНОЗ. H криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- ZEC ПРОГНОЗ. ZEC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
2026-02-20 07:03