Автор: Денис Аветисян
Новый подход к организации долговременной памяти в искусственном интеллекте позволяет агентам не просто хранить информацию, а извлекать из неё глубокие знания и делиться ими.
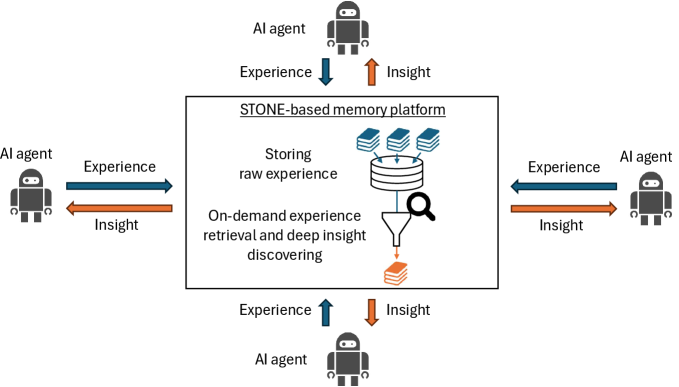
В статье рассматривается переход к сохранению необработанных данных опыта и последующей оптимизации извлечения знаний для создания более адаптивных и эффективных ИИ-агентов.
Несмотря на значительный прогресс в области искусственного интеллекта, создание действительно долгосрочной и гибкой памяти для агентов остается сложной задачей. В работе ‘Revolutionizing Long-Term Memory in AI: New Horizons with High-Capacity and High-Speed Storage’ рассматривается концепция памяти, необходимой для достижения искусственного суперинтеллекта, с акцентом на альтернативные подходы к сохранению и обработке опыта. Авторы предлагают сместить фокус с извлечения и хранения лишь «полезной» информации на сохранение необработанных данных и извлечение знаний по мере необходимости, а также на эффективный обмен опытом между агентами, что позволит преодолеть ограничения традиционных методов. Какие новые горизонты откроются при создании систем искусственного интеллекта, способных эффективно использовать весь объем накоренной информации?
Пределы Внутреннего Знания
Языковые модели, основанные на глубоком обучении, действительно совершили прорыв в области искусственного интеллекта, демонстрируя впечатляющую способность генерировать текст, переводить языки и отвечать на вопросы. Однако, несмотря на эти достижения, фундаментальное ограничение заключается в их неспособности к непрерывному обучению, свойственному живому разуму. В отличие от человека, способного накапливать знания и адаптироваться к новым ситуациям на протяжении всей жизни, современные языковые модели испытывают трудности с интеграцией новой информации, не забывая при этом старую. Этот феномен, известный как «катастрофическое забывание», серьезно препятствует развитию подлинного интеллекта и приближению к цели создания общего искусственного интеллекта (AGI), способного решать широкий спектр задач, аналогично человеческому разуму.
Современные большие языковые модели (LLM) хранят накопленные знания непосредственно в своих параметрах — весах нейронной сети. Этот подход, известный как параметрическая память, отличается от того, как учится человек или животное, полагаясь на внешние источники и долгосрочную, неструктурированную память. В то время как параметрическое хранение позволяет LLM быстро извлекать информацию, оно крайне неэффективно с точки зрения использования ресурсов и подвержено катастрофическому забыванию — потере ранее усвоенных знаний при обучении новым данным. По сути, каждое новое обучение переписывает часть весов модели, потенциально стирая ценную информацию. Это ограничивает способность LLM к непрерывному обучению и адаптации к меняющимся условиям, создавая существенный барьер на пути к созданию искусственного общего интеллекта (AGI).
Ограниченность параметрической памяти создает серьезное препятствие для адаптации больших языковых моделей (LLM) к динамично меняющимся условиям реального мира. В отличие от человеческого интеллекта, способного непрерывно учиться и интегрировать новую информацию без потери старых знаний, LLM сталкиваются с проблемой “катастрофического забывания”. Это означает, что при обучении новым данным, модель может потерять способность выполнять ранее освоенные задачи. Такая неспособность к гибкому и устойчивому обучению является ключевым фактором, препятствующим достижению общего искусственного интеллекта (AGI) — системы, способной решать широкий спектр задач, подобно человеку, и адаптироваться к новым, ранее не встречавшимся ситуациям. Таким образом, преодоление этого «узкого горлышка» в архитектуре LLM представляется необходимым условием для создания действительно интеллектуальных систем.
Внешняя Память: Ключ к Масштабируемому Интеллекту
Внешняя память представляет собой решение проблемы масштабируемости больших языковых моделей (LLM) за счет отделения хранения знаний от параметров самой модели. Традиционно, LLM хранят все знания внутри своих весов, что ограничивает их способность к обучению и адаптации к новым данным без переобучения всей модели. Использование внешней памяти позволяет LLM обращаться к внешним базам знаний для получения необходимой информации в процессе работы, что существенно снижает потребность в постоянном обновлении параметров модели. Это обеспечивает возможность непрерывного обучения и адаптации к меняющимся условиям без значительных вычислительных затрат и позволяет LLM сохранять и использовать информацию, превышающую объем, который может быть эффективно сохранен в параметрах модели.
Методы, такие как Retrieval-Augmented Generation (RAG) и In-Context Learning (ICL), расширяют возможности больших языковых моделей (LLM) за счет интеграции внешних источников знаний. RAG предполагает извлечение релевантной информации из внешних баз данных или документов непосредственно во время генерации ответа, что позволяет LLM предоставлять более точную и контекстуально обоснованную информацию. In-Context Learning, в свою очередь, использует примеры, предоставляемые непосредственно в запросе, чтобы направлять LLM к желаемому результату без необходимости переобучения модели. Оба подхода позволяют LLM решать задачи, требующие знаний, которые не были включены в исходный набор данных для обучения, тем самым повышая их гибкость и адаптивность.
Эффективность использования внешних источников знаний для больших языковых моделей (LLM) напрямую зависит не только от доступа к этим данным, но и от способа их организации и применения. Простое извлечение релевантной информации недостаточно; ключевым фактором является структурирование данных для быстрого и точного поиска, а также выбор оптимального метода интеграции этой информации в процесс генерации ответа. Неэффективная организация данных приводит к увеличению времени поиска и снижению релевантности полученных результатов, что негативно сказывается на производительности LLM и качестве генерируемого контента. Оптимизация хранения и использования внешних знаний включает в себя выбор подходящих форматов данных, индексацию для быстрого поиска и использование алгоритмов ранжирования для определения наиболее релевантных фрагментов информации.
Смена Парадигмы: От Извлечения к Сохранению
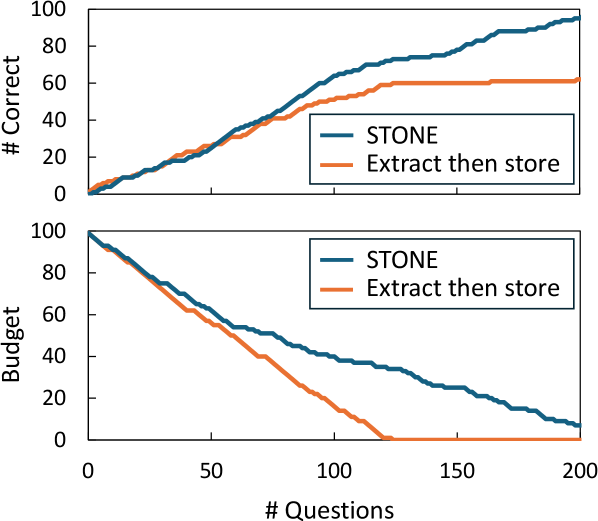
Традиционные методы “Извлечение, а затем Хранение” предполагают предварительную компрессию опыта в виде обобщенных данных перед сохранением. Этот подход часто приводит к потере важных нюансов и деталей, поскольку информация подвергается упрощению и категоризации для оптимизации хранения. В процессе суммирования происходит отбрасывание потенциально значимых элементов, которые могут оказаться полезными для последующего анализа или открытия новых закономерностей. В результате, восстановление полного и детального представления об исходном опыте становится невозможным, ограничивая возможности для глубокого понимания и извлечения максимальной ценности из хранимых данных.
Парадигма «Сохранить, а затем извлечь по требованию» (STONE) предполагает сохранение исходных данных опыта в полном объеме, а не их предварительную обработку и сжатие. Это позволяет осуществлять повторный анализ данных с использованием различных критериев и методов, выявляя более глубокие взаимосвязи и ранее незамеченные закономерности. В отличие от традиционных методов, где информация упрощается перед сохранением, STONE обеспечивает возможность многократной интерпретации и извлечения информации в зависимости от текущих задач и потребностей исследователя или системы.
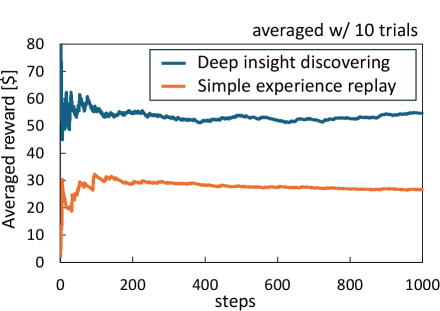
Подход, основанный на сохранении необработанных данных опыта (STONE), значительно усиливается при совместном использовании с методами углубленного обнаружения закономерностей (Deeper Insight Discovery). Эти методы используют внешнюю память для анализа множества сохраненных опытов, выявляя скрытые корреляции и паттерны, которые могли бы быть упущены при традиционном извлечении и хранении суммарной информации. Использование внешней памяти позволяет обрабатывать более широкий объем данных и более сложные взаимосвязи, что приводит к более глубокому пониманию и новым открытиям, основанным на анализе полного спектра доступной информации.
Для оптимизации доступа к сохраненным опытам в рамках парадигмы STONE (Store Then ON-demand Extract) эффективно использовать кэш типа «ключ-значение» (KV-Cache). Данный подход предполагает сохранение данных опыта, связанных с определенным ключом (например, идентификатором события или контекстом), в легкодоступной памяти. При запросе опыта, система сначала проверяет наличие соответствующего ключа в KV-Cache. Если ключ найден, данные извлекаются непосредственно из кэша, что значительно сокращает время отклика по сравнению с извлечением из основного хранилища. В случае отсутствия ключа в кэше, данные извлекаются из основного хранилища и одновременно добавляются в KV-Cache для последующего быстрого доступа. Размер KV-Cache необходимо тщательно подбирать, учитывая частоту запросов к различным опытам и доступные ресурсы памяти.
Масштабирование Интеллекта через Общий Опыт
Обучение на основе обмена опытом позволяет множеству искусственных интеллектов извлекать уроки из пережитого другими, значительно снижая индивидуальные затраты на обучение и ускоряя развитие коллективного интеллекта. Вместо того чтобы каждый агент самостоятельно накапливал знания, проходя через все этапы проб и ошибок, система позволяет им совместно использовать полученные знания. Этот подход создает эффект синергии, где опыт одного агента становится ценным ресурсом для остальных, позволяя им быстрее адаптироваться к новым задачам и эффективно решать сложные проблемы. Подобный механизм не только повышает общую производительность системы, но и способствует развитию более устойчивых и надежных моделей искусственного интеллекта, способных к более гибкому и эффективному обучению.
Для эффективного обмена опытом между искусственными интеллектами используется сеть доставки знаний, представляющая собой распределенную систему, оптимизированную для передачи релевантной информации. Эта сеть функционирует по принципу децентрализованного хранения и обмена данными, позволяя агентам быстро получать доступ к знаниям, полученным другими участниками системы. Вместо централизованного репозитория, сеть доставки знаний использует peer-to-peer соединения и алгоритмы маршрутизации, чтобы минимизировать задержки и максимизировать пропускную способность. Такой подход не только ускоряет процесс обучения, но и повышает устойчивость системы к сбоям, поскольку потеря одного агента не влияет на доступность знаний для остальных. Эффективность данной сети обусловлена динамической адаптацией к изменяющимся потребностям агентов и приоритезацией наиболее ценной информации, что позволяет значительно снизить затраты на обучение и повысить общую производительность системы.
В рамках повышения эффективности обучения искусственного интеллекта, применяются алгоритмы многоруких бандитов для отбора наиболее информативных опытов. Этот подход позволяет агентам динамически оценивать ценность каждого полученного опыта и фокусироваться на тех, которые приносят наибольшую пользу для адаптации и улучшения производительности. Вместо случайного выбора или равномерного распределения, алгоритм определяет приоритетность опытов, основываясь на полученных вознаграждениях — то есть, на том, насколько успешно агент использовал полученные знания для решения задачи. Такой механизм позволяет значительно ускорить процесс обучения, так как агенты концентрируются на наиболее релевантных данных, избегая избыточной обработки менее полезной информации и оптимизируя использование ресурсов.
В рамках данной системы искусственного интеллекта интеграция эпизодической и семантической памяти позволяет агентам не только восстанавливать конкретные события из прошлого опыта, но и обобщать полученные знания для формирования общих принципов и правил. Эпизодическая память, подобно личным воспоминаниям, сохраняет детализированные сведения о каждом отдельном событии, включая контекст и последствия. В то же время, семантическая память структурирует эти воспоминания, выделяя общие закономерности и формируя абстрактные понятия. Благодаря такому сочетанию, агенты способны эффективно адаптироваться к новым ситуациям, используя как конкретный опыт, так и накопленные общие знания, что значительно повышает их способность к обучению и решению задач.
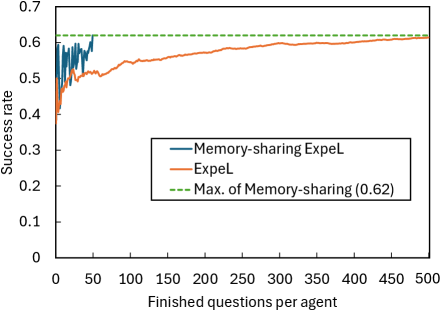
Исследование демонстрирует значительное повышение эффективности обучения искусственного интеллекта за счет совместного использования опыта. Агенты, использующие механизм обмена воспоминаниями, достигают уровня успешности в 0.62 после обработки всего 50 вопросов, в то время как одиночному агенту для достижения аналогичного результата требуется обработать все 500 вопросов. Таким образом, предложенный подход обеспечивает десятикратное увеличение скорости обучения и адаптации, что свидетельствует о потенциале масштабирования интеллекта посредством коллективного опыта и эффективного распространения знаний в сети агентов.
Исследование, представленное в статье, подчеркивает необходимость перехода к удержанию необработанных переживаний и извлечению знаний по требованию. Это напоминает о глубокой проницательности Карла Фридриха Гаусса: «Если бы кто-нибудь спросил меня, какова самая большая ошибка в математике, я бы сказал, что это попытка обобщить слишком рано». Действительно, стремление к немедленному извлечению и хранению информации может привести к преждевременным обобщениям и упущению ценных нюансов. Сохранение ‘сырых’ данных опыта, как предлагается, позволяет агентам глубже анализировать информацию и извлекать более надежные знания, способствуя развитию более адаптивных и устойчивых систем искусственного интеллекта. Порядок, в данном случае, предстает как временный кеш между потенциальными сбоями, а долгосрочная память — как фундамент для выживания в сложных условиях.
Что впереди?
Предложенный подход, фокусирующийся на сохранении необработанного опыта и последующем извлечении знаний по требованию, не столько решает проблему долгосрочной памяти, сколько смещает акцент. Система — это не машина, это сад: если не взращивать весь спектр переживаний, а сразу пытаться вычленить “полезное”, рискуем получить лишь унылую монокультуру. Текущая тенденция к немедленной обработке и хранению лишь самых “важных” моментов напоминает попытку создать идеальный архив, забывая, что ценность часто скрывается в случайных, казалось бы, незначительных деталях.
Очевидно, что масштабирование обмена опытом между агентами — задача нетривиальная. Недостаточно просто “поделиться” данными; необходимо создать механизмы для оценки их релевантности, разрешения конфликтов и адаптации к различным контекстам. Устойчивость не в изоляции компонентов, а в их способности прощать ошибки друг друга, принимать противоречивые данные и учиться на чужих неудачах. Остается открытым вопрос, как избежать эффекта “информационного шума” и гарантировать, что обмен опытом действительно приводит к улучшению общей производительности.
В конечном счете, развитие долгосрочной памяти в ИИ требует переосмысления самой концепции “знания”. Знание — это не статичный набор фактов, а динамичный процесс обучения и адаптации. Архитектурный выбор — это пророчество о будущем сбое: стремясь к совершенству, мы рискуем создать системы, неспособные к самовосстановлению и эволюции. Настоящий прогресс заключается не в создании все более сложных алгоритмов, а в создании систем, способных к смирению и обучению на собственном опыте — и на опыте других.
Оригинал статьи: https://arxiv.org/pdf/2602.16192.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
2026-02-19 09:20