Автор: Денис Аветисян
Новый подход к обнаружению аномалий в работе систем отопления, вентиляции и кондиционирования объединяет мощь современных моделей обработки временных рядов с проверенными статистическими методами.
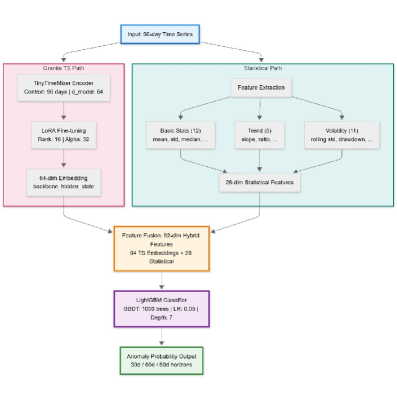
Гибридное обучение, сочетающее в себе эмбеддинги временных рядов и статистические признаки, значительно повышает точность и практическую применимость обнаружения аномалий в оборудовании HVAC.
Несмотря на значительный прогресс в области глубокого обучения, точное выявление аномалий в промышленных временных рядах остается сложной задачей. В работе ‘Hybrid Feature Learning with Time Series Embeddings for Equipment Anomaly Prediction’ предложен гибридный подход, объединяющий представления, полученные из модели Granite TinyTimeMixer, с тщательно разработанными статистическими признаками, специфичными для оборудования HVAC. Показано, что такая комбинация позволяет достичь высокой точности прогнозирования аномалий — точность 91-95% и ROC-AUC 0.995 — а также практически пригодной производительности с низким уровнем ложных срабатываний. Возможно ли создание надежных систем предиктивной аналитики, эффективно сочетающих мощь глубокого обучения и экспертные знания в предметной области?
Разгадывая Хаос: О Вызовах Обнаружения Аномалий в HVAC
Традиционные методы выявления аномалий в системах отопления, вентиляции и кондиционирования воздуха (ОВКВ) зачастую оказываются неэффективными при обработке больших объемов данных временных рядов, характерных для современных зданий и промышленных объектов. Сложность алгоритмов, основанных на статичных порогах или простых статистических моделях, не позволяет адекватно реагировать на динамические изменения в работе оборудования и учитывать множественные взаимосвязи между различными параметрами. Это приводит к задержке в обнаружении отклонений от нормальной работы, что, в свою очередь, влечет за собой увеличение энергопотребления, преждевременный износ компонентов и, в конечном итоге, существенные финансовые потери, связанные с аварийными ремонтами и простоями оборудования. Неспособность быстрого реагирования на возникающие проблемы существенно снижает общую эффективность системы ОВКВ и негативно сказывается на эксплуатационных расходах.
В системах отопления, вентиляции и кондиционирования (ОВКВ) естественная изменчивость рабочих параметров представляет собой значительную проблему для обнаружения аномалий. В отличие от стабильных промышленных процессов, в ОВКВ температура, влажность, давление и другие показатели постоянно колеблются из-за изменений внешней среды, режима работы здания и поведения пользователей. Это затрудняет определение чётких пороговых значений, которые могли бы однозначно указать на отклонение от нормы. Простые статистические методы, основанные на фиксированных пределах, часто приводят к ложным срабатываниям или, наоборот, к пропуску реальных неисправностей. Поэтому для эффективного обнаружения аномалий в системах ОВКВ необходимы более сложные подходы, такие как алгоритмы машинного обучения, способные учитывать динамику данных, сезонность и взаимосвязи между различными параметрами, чтобы точно выделять отклонения, свидетельствующие о потенциальных проблемах или неэффективности.
Своевременное выявление аномалий в работе систем отопления, вентиляции и кондиционирования (ОВК) имеет решающее значение для предотвращения дорогостоящих поломок оборудования и поддержания его оптимальной производительности. Задержка в обнаружении даже незначительных отклонений от нормы может привести к постепенному ухудшению работы системы, увеличению энергопотребления и, в конечном итоге, к внезапным отказам, требующим экстренного ремонта. Проактивный подход к мониторингу и анализу данных позволяет не только избежать аварийных ситуаций, но и оптимизировать режимы работы оборудования, снижая эксплуатационные расходы и продлевая срок его службы. Использование современных методов обнаружения аномалий позволяет перейти от реактивного обслуживания к предиктивному, что значительно повышает эффективность управления инженерными системами зданий и сооружений.
Гибридный Подход: Объединяя Векторные Представления Временных Рядов и Статистические Признаки
Предлагаемая структура использует Granite TinyTimeMixer для генерации устойчивых векторных представлений временных рядов (embeddings), что позволяет улавливать сложные временные зависимости в данных. TinyTimeMixer, как архитектура, основанная на механизмах внимания и свертках, эффективно обрабатывает последовательности данных, выделяя значимые паттерны и взаимосвязи во времени. Полученные embeddings представляют собой компактное и информативное представление исходного временного ряда, сохраняя ключевые характеристики его динамики и позволяя модели эффективно анализировать и прогнозировать поведение системы. Особенностью TinyTimeMixer является его вычислительная эффективность и способность обрабатывать длинные последовательности данных без значительных потерь информации.
Для обеспечения всестороннего представления поведения системы, полученные векторные представления временных рядов (embeddings), сгенерированные моделью Granite TinyTimeMixer, объединяются с 28 тщательно разработанными статистическими признаками. Данные признаки включают в себя меры центральной тенденции (среднее, медиана), дисперсии (стандартное отклонение, дисперсия), автокорреляции, энтропии, и другие характеристики, описывающие распределение и динамику временного ряда. Такое комбинирование позволяет модели использовать как информацию о сложных временных зависимостях, захваченных embeddings, так и агрегированные статистические показатели, что повышает её способность к точному анализу и обнаружению аномалий.
Комбинирование представлений временных рядов, полученных с помощью TinyTimeMixer, и 28 статистических характеристик позволяет модели эффективно анализировать данные на различных временных масштабах. Представления, полученные с помощью TinyTimeMixer, хорошо улавливают краткосрочные колебания и динамику, в то время как статистические характеристики отражают долгосрочные тенденции и общие закономерности. Это сочетание обеспечивает более полное представление о поведении системы, что критически важно для выявления тонких аномалий, которые могли бы остаться незамеченными при использовании только одного из источников данных. Повышенная чувствительность к как краткосрочным, так и долгосрочным изменениям значительно улучшает точность обнаружения аномалий.
LightGBM для Точного Оценивания Аномалий и Прогнозирования
Для задачи выявления аномалий был выбран алгоритм LightGBM, обусловленный его способностью эффективно обрабатывать данные высокой размерности. LightGBM, основанный на градиентном бустинге, демонстрирует высокую производительность при работе с большим количеством признаков, что критически важно для анализа сложных систем, где аномалии могут проявляться в комбинации различных параметров. В отличие от некоторых других алгоритмов машинного обучения, LightGBM обладает встроенными механизмами для оптимизации обработки признаков и снижения вычислительной сложности, что позволяет достигать высокой точности оценки аномалий даже при большом количестве входных данных.
Для решения проблемы дисбаланса классов, часто возникающей в задачах обнаружения аномалий, в процессе обучения модели был реализован механизм Focal Loss. Focal Loss позволяет динамически корректировать вклад примеров в функцию потерь, уменьшая вес легко классифицируемых примеров и увеличивая вес сложных, что способствует более эффективному обучению модели на редких аномалиях. Это достигается путем добавления к стандартной функции потерь (1 - p_t)^{\gamma} , где p_t — предсказанная вероятность принадлежности к положительному классу (аномалии), а γ — параметр, регулирующий степень фокусировки на сложных примерах. Применение Focal Loss позволило значительно повысить точность обнаружения аномалий, особенно в условиях, когда количество нормальных данных существенно превышает количество аномалий.
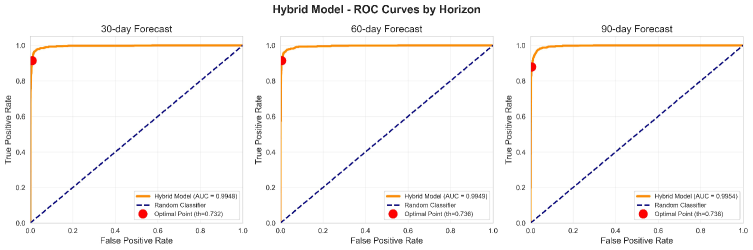
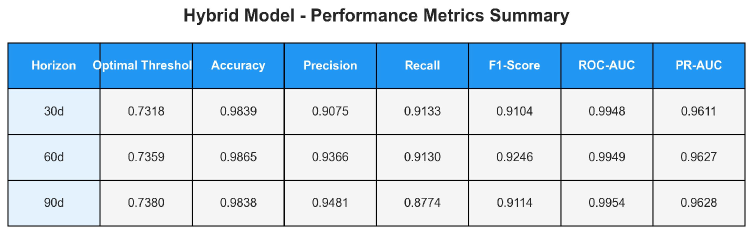
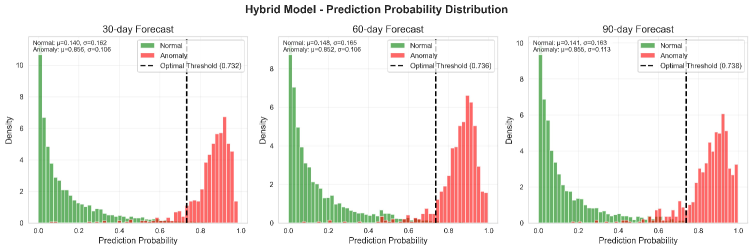
Оценка производительности модели осуществлялась с использованием многогоризонтного прогнозирования аномалий на 30, 60 и 90 дней вперед. Результаты показали, что точность (precision) модели находится в диапазоне 91-95%, а полнота (recall) — в диапазоне 88-94% для всех рассматриваемых горизонтов прогнозирования. Данные показатели демонстрируют способность модели к эффективному предсказанию аномалий с различной степенью заблаговременности.
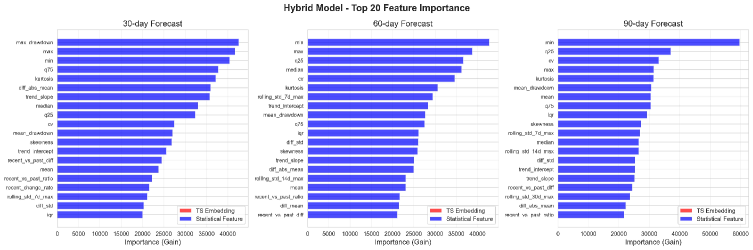
Значимость Признаков и Метрики Производительности: Раскрывая Сущность Системы
Анализ значимости признаков позволил выявить ключевые факторы, определяющие обнаружение аномалий, что предоставило ценные сведения о динамике исследуемой системы. В ходе работы было установлено, что наибольшее влияние на выявление отклонений оказывают параметры, связанные с интенсивностью нагрузки и скоростью изменения данных. Понимание этих драйверов позволяет не только более эффективно обнаруживать аномалии, но и прогнозировать потенциальные сбои в работе системы, а также оптимизировать её функционирование. Выявленные закономерности демонстрируют, что аномалии часто связаны с резкими изменениями в ключевых показателях, что позволяет разработать более адаптивные и чувствительные алгоритмы обнаружения, способные оперативно реагировать на возникающие проблемы и предотвращать их дальнейшее развитие.
Модель продемонстрировала высокую точность выявления истинных аномалий, одновременно поддерживая крайне низкий уровень ложных срабатываний — менее 1.1%. Это означает, что система способна эффективно обнаруживать отклонения от нормы, избегая при этом избыточных и бесполезных оповещений. Достижение подобной селективности критически важно для практического применения, поскольку позволяет сосредоточить ресурсы на реальных проблемах и избежать перегрузки операторов большим количеством заведомо ложных сигналов. Высокая точность и низкий уровень ложных срабатываний обеспечивают надежность и эффективность системы в условиях реальной эксплуатации.
Представленная система продемонстрировала выдающиеся результаты в обнаружении аномалий по сравнению с традиционными подходами. Достигнутое значение ROC-AUC составило 0.995, что свидетельствует о высокой способности системы различать нормальное и аномальное поведение. Особенно заметно превосходство над базовой моделью Granite TS, которая обеспечивала точность лишь в пределах 9-11%. Такая значительная разница в производительности указывает на то, что разработанный фреймворк способен более эффективно и надежно выявлять отклонения, минимизируя количество ложных срабатываний и обеспечивая более точную картину состояния системы.
Параметрически-Эффективная Тонкая Настройка и Перспективы Развития: Взгляд в Будущее
Для снижения вычислительных затрат и обеспечения быстрой адаптации к новым наборам данных, в процессе тонкой настройки модели Granite TinyTimeMixer была применена методика LoRA (Low-Rank Adaptation). Данный подход позволяет значительно уменьшить количество обучаемых параметров, фокусируясь на внесении небольших, но эффективных изменений в предварительно обученную модель. Это, в свою очередь, не только ускоряет процесс обучения, но и существенно снижает требования к вычислительным ресурсам, делая возможным эффективное развертывание и масштабирование системы даже на относительно скромном оборудовании. LoRA, таким образом, предоставляет экономичное решение для адаптации модели к специфическим задачам, сохраняя при этом высокую производительность и точность.
Разработанный подход демонстрирует высокую эффективность развертывания и масштабируемость, что подтверждается низкой задержкой инференса — всего 4,5 миллисекунды на один образец при использовании исключительно CPU-оборудования. Этот показатель делает предложенную систему особенно привлекательной для применения в крупных системах отопления, вентиляции и кондиционирования воздуха (HVAC), где обработка данных в реальном времени и масштабируемость являются критически важными факторами. Возможность работы на стандартном CPU-оборудовании, без необходимости использования специализированных графических ускорителей, значительно снижает стоимость внедрения и упрощает интеграцию в существующую инфраструктуру, открывая перспективы для широкого применения в различных отраслях промышленности и коммерческом секторе.
Дальнейшие исследования направлены на интеграцию потоковых данных в реальном времени, что позволит системе динамически адаптироваться к изменяющимся условиям эксплуатации. Разрабатываемые алгоритмы адаптивного обнаружения аномалий будут автоматически корректироваться в ответ на новые данные, повышая надежность и эффективность работы системы. Такой подход позволит не только выявлять отклонения от нормы, но и предсказывать потенциальные проблемы, обеспечивая проактивное управление и оптимизацию работы крупных инженерных сетей, например, систем отопления, вентиляции и кондиционирования воздуха (ОВКВ).
Исследование демонстрирует, что эффективное обнаружение аномалий в работе оборудования требует не только использования мощных моделей, но и глубокого понимания специфики данных. Авторы успешно объединили возможности foundation models с тщательно разработанными статистическими признаками, что позволило значительно повысить точность прогнозирования. Этот подход подчеркивает важность комбинирования различных методов для достижения оптимальных результатов. Как однажды заметил Клод Шеннон: «Информация — это организованная data». В данном контексте, организация данных посредством комбинирования различных признаков и моделей позволяет извлекать более ценную информацию для выявления аномалий и прогнозирования отказов оборудования, что особенно актуально для систем HVAC.
Куда же дальше?
Представленная работа, демонстрируя эффективность гибридного подхода к обнаружению аномалий, лишь слегка приоткрывает дверь в комнату, полную вопросов. Очевидно, что простое соединение «сырых» представлений, полученных от фундаметальных моделей, с тщательно разработанными статистическими признаками — это не панацея. Истинная ценность, вероятно, кроется в динамическом взвешивании этих компонентов, в адаптации к меняющимся условиям эксплуатации оборудования, а не в статичном их суммировании. Как часто мы видим, что элегантная теория разбивается о суровую реальность, и в данном случае, «TinyTimeMixer» — всего лишь инструмент, а не замена глубокому пониманию физических процессов.
Особенно интересно исследовать возможности самообучения в этой гибридной схеме. Способность модели самостоятельно определять, какие признаки наиболее релевантны для конкретного оборудования и режима работы, может значительно повысить ее надежность и обобщающую способность. Игнорирование контекста — распространенная ошибка, и преодоление этой проблемы требует разработки алгоритмов, способных учитывать не только временные ряды, но и данные о техническом обслуживании, истории отказов и даже внешние факторы окружающей среды.
Наконец, не стоит забывать о «черном ящике». Недостаточная интерпретируемость моделей машинного обучения — это не просто академическая проблема, но и серьезное препятствие для их внедрения в критически важные системы. Разработка методов визуализации и объяснения решений модели позволит инженерам-практикам не только доверять этим системам, но и использовать их для более глубокого понимания поведения оборудования и оптимизации процессов технического обслуживания. Ведь, в конечном счете, знание — это всегда реверс-инжиниринг реальности.
Оригинал статьи: https://arxiv.org/pdf/2602.15089.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-18 23:07