Автор: Денис Аветисян
Новый метод выявляет тексты, созданные искусственным интеллектом, анализируя структуру предложений, а не просто содержание.
Предлагается DependencyAI — система обнаружения текстов, сгенерированных ИИ, основанная на анализе синтаксической структуры с помощью парсинга зависимостей.
Растущая распространенность больших языковых моделей (LLM) ставит задачу надежного определения текстов, сгенерированных искусственным интеллектом. В данной работе, озаглавленной ‘DependencyAI: Detecting AI Generated Text through Dependency Parsing’, представлен новый подход к обнаружению AI-генерируемых текстов, основанный исключительно на анализе синтаксической структуры предложений с помощью парсинга зависимостей. Показано, что предложенный метод демонстрирует конкурентоспособные результаты в моно- и многоязычных сценариях, обеспечивая при этом высокую интерпретируемость и не требуя использования нейронных сетей. Какие еще лингвистические особенности могут служить надежными индикаторами авторства текстов, созданных искусственным интеллектом, и как можно использовать эти знания для повышения точности и надежности систем обнаружения?
Истинная Сущность ИИ-Текста: Вызов Подлинности
В последнее время наблюдается экспоненциальный рост объемов текста, созданного искусственным интеллектом, что представляет собой серьезную проблему для подтверждения подлинности контента. Появление сложных языковых моделей позволяет создавать тексты, практически неотличимые от написанных человеком, что затрудняет определение их происхождения. Это распространение сгенерированного ИИ контента ставит под угрозу достоверность информации в сети, влияя на доверие к новостям, научным публикациям и другим источникам. В результате, проверка авторства и выявление искусственно созданного текста становятся все более актуальными задачами, требующими разработки новых, эффективных методов и инструментов.
Традиционные методы выявления текстов, сгенерированных искусственным интеллектом, оказываются недостаточно эффективными при анализе сложных и нюансированных результатов работы современных моделей. Ранее полагавшиеся на статистический анализ частотности слов или поиск явных грамматических ошибок, эти подходы легко обманываются продвинутыми алгоритмами, способными создавать текст, неотличимый от человеческого. Необходимость в более совершенных инструментах, учитывающих семантические особенности, стилистические приемы и контекст, становится все более очевидной. Исследователи активно работают над разработкой методов, использующих машинное обучение и нейронные сети для выявления скрытых закономерностей, свойственных текстам, созданным искусственным интеллектом, даже если они кажутся безупречными с точки зрения традиционных критериев.
Сохранение доверия к информации, распространяемой в сети, напрямую зависит от способности достоверно определять авторство текста. В условиях стремительного развития технологий искусственного интеллекта и повсеместного создания контента при помощи нейросетей, разграничение между текстом, созданным человеком, и машинным становится всё более сложной задачей. Неспособность точно идентифицировать происхождение текста подрывает уверенность пользователей в достоверности новостей, научных публикаций, и даже личных сообщений, создавая благоприятную почву для дезинформации и манипуляций. Успешное решение этой проблемы имеет критическое значение для поддержания информационной безопасности и формирования ответственного онлайн-пространства, где пользователи могут быть уверены в подлинности получаемой информации.
DependencyAI: Синтаксический Анализ как Ключ к Распознаванию
Метод DependencyAI представляет собой легковесный подход к выявлению текстов, сгенерированных искусственным интеллектом, основанный на анализе последовательностей зависимостных связей. В отличие от методов, требующих значительных вычислительных ресурсов или больших объемов обучающих данных, DependencyAI использует результаты синтаксического анализа зависимостей для извлечения последовательности отношений между словами в предложении. Эта последовательность, представляющая собой специфическую структуру текста, служит признаком для различения текстов, созданных человеком, и текстов, сгенерированных моделями искусственного интеллекта. Легковесность метода заключается в использовании только последовательности зависимостей, что снижает сложность вычислений и требования к памяти, обеспечивая быструю и эффективную детекцию.
Метод DependencyAI использует синтаксический анализ зависимостей (dependency parsing) для извлечения и представления внутренней синтаксической структуры текста. Данный процесс предполагает разбор предложения на составляющие его элементы и установление грамматических связей между ними, определяя, например, какие слова являются глаголами, существительными, прилагательными и как они связаны друг с другом в рамках предложения. Результатом является древовидная структура зависимостей, отражающая отношения между словами и позволяющая количественно оценивать особенности синтаксиса, такие как глубина дерева, типы связей и частота использования определенных синтаксических конструкций. Анализ этих структурных характеристик позволяет выявлять различия в синтаксическом стиле между текстами, созданными человеком и искусственным интеллектом.
Метод DependencyAI позволяет эффективно различать тексты, созданные человеком и искусственным интеллектом, посредством анализа последовательностей зависимостей, полученных в результате синтаксического разбора. В отличие от подходов, ориентированных на поверхностные признаки, DependencyAI фокусируется на глубинной синтаксической структуре предложений. Анализ этих структур выявляет статистически значимые различия в паттернах использования зависимостей между человеческой и машинной генерацией текста, что позволяет построить классификатор с высокой точностью. Например, AI-тексты часто демонстрируют более простую и линейную структуру зависимостей, в то время как тексты, написанные человеком, характеризуются большей сложностью и разнообразием связей между словами.
Раскрытие Скрытых Индикаторов: Анализ Важности Признаков
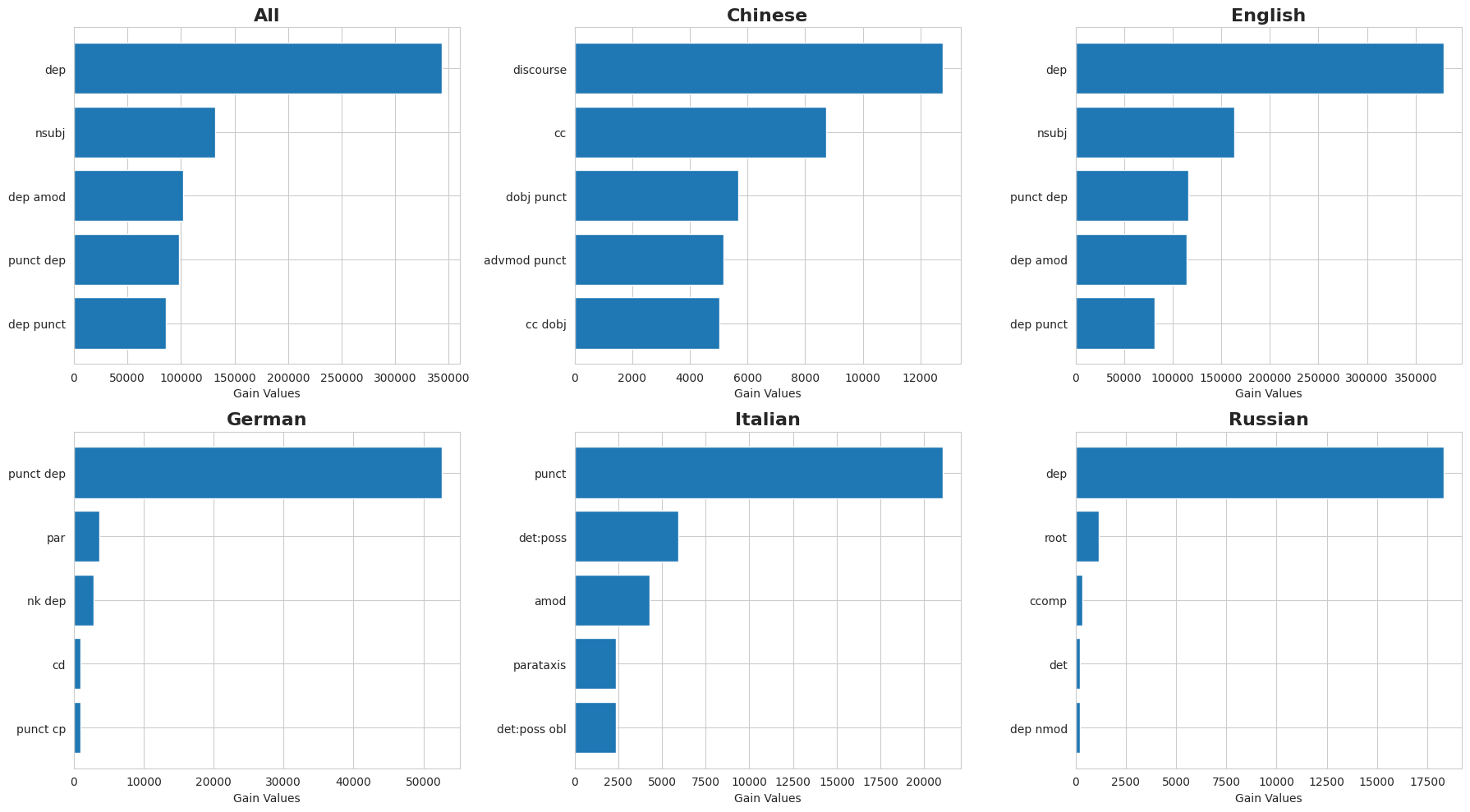
Для определения наиболее информативных зависимостей в тексте, сгенерированном искусственным интеллектом, был проведен анализ важности признаков (Feature Importance Analysis) в системе DependencyAI. В рамках данного анализа рассчитывалось влияние каждого типа синтаксической зависимости на точность классификации текста как сгенерированного ИИ, так и написанного человеком. Целью исследования являлось выявление ключевых зависимостей, которые позволяют наиболее эффективно отличать тексты, созданные нейронными сетями, от текстов, написанных людьми, что необходимо для повышения эффективности систем обнаружения ИИ-контента.
Анализ важности признаков в DependencyAI выявил, что определенные типы зависимостных связей оказывают существенное влияние на точность обнаружения текстов, сгенерированных искусственным интеллектом. В частности, зависимостная связь, обозначенная как ‘Неопределенная зависимостная связь’, продемонстрировала значительный вклад в общую производительность модели. Это указывает на то, что специфические грамматические конструкции и отношения между словами, не классифицированные в стандартные типы зависимостей, являются важными индикаторами машинного происхождения текста и могут использоваться для повышения эффективности систем обнаружения.
Метрика «Gain» оказалась ключевой при количественной оценке влияния каждого типа зависимости на производительность модели DependencyAI. Она представляет собой уменьшение значения функции потерь (например, log loss) при разделении выборки данных по значениям конкретной зависимости. Более высокие значения метрики «Gain» указывают на то, что данная зависимость вносит значительный вклад в способность модели различать сгенерированный искусственным интеллектом текст и текст, написанный человеком. Фактически, это мера информативности конкретной зависимости для задачи обнаружения AI-генерированного текста, позволяющая ранжировать зависимости по степени важности и оптимизировать модель для повышения точности.
Надежность и Обобщение: Мульти-Языковая и Мульти-Доменная Эффективность
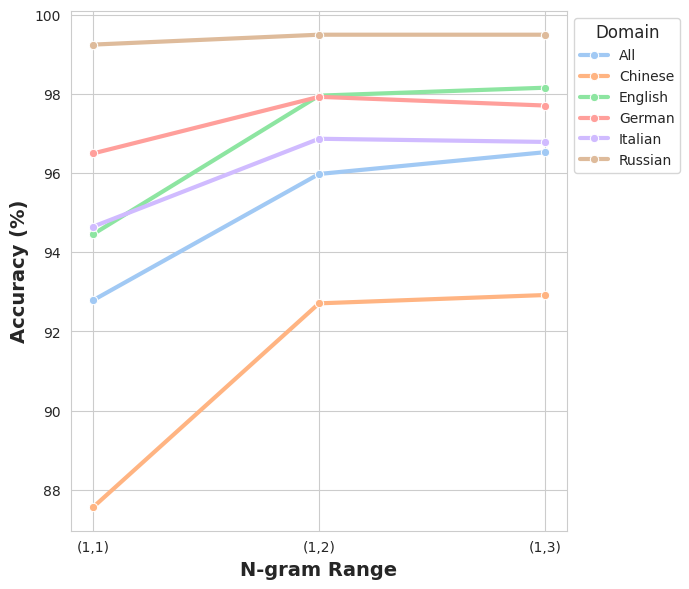
Система DependencyAI продемонстрировала выдающиеся результаты на мульти-языковом и мульти-доменном бенчмарке M4GT-Bench. В ходе тестирования была достигнута общая точность в 88.85% при многовариантной детекции в условиях работы с неизвестными доменами. При этом, показатель F1, характеризующий баланс между точностью и полнотой, составил 88.94% при аналогичных условиях. Данные результаты свидетельствуют о высокой эффективности системы в обработке разнообразных текстов на различных языках и в разных предметных областях, что подтверждает её потенциал для широкого спектра практических приложений, требующих надежной и точной обработки лингвистических данных.
Методика демонстрирует высокую эффективность при обработке текстов различной структуры и на разных языках, что открывает широкие возможности для практического применения. Особенно впечатляющие результаты достигнуты при многоязычном определении зависимостей, где точность и F1-мера для русского языка составили 99.50% каждая. Данный показатель свидетельствует о способности модели успешно адаптироваться к лингвистическим особенностям различных языков и обеспечивать надежное распознавание грамматических связей даже в сложных текстовых конструкциях. Такая универсальность делает DependencyAI ценным инструментом для задач обработки естественного языка, требующих анализа текстов на разных языках и в разных предметных областях.
Успешное выполнение многоязыковой задачи обнаружения демонстрирует способность модели к обобщению на различные области применения. В ходе исследований было установлено, что расширение диапазона n-грамм зависимостей от униграмм до биграмм позволило повысить точность обнаружения на китайском языке примерно на 5 процентных пунктов. Это свидетельствует о том, что учёт контекста зависимостей в предложении существенно улучшает производительность модели, делая её надежным инструментом для обработки текстов на разных языках и в различных предметных областях. Подобная способность к обобщению имеет важное значение для практического применения модели в реальных задачах, где данные могут значительно отличаться от тех, на которых она обучалась.
Без точного определения задачи любое решение — шум. Исследование, представленное в данной работе, демонстрирует это в полной мере. Методика DependencyAI, основанная на анализе синтаксической структуры текста посредством зависимостного парсинга, подтверждает, что даже без учета лексического содержания возможно достоверно отличить текст, созданный искусственным интеллектом, от написанного человеком. Тим Бернерс-Ли однажды сказал: «Интернет — это для всех». Подобно тому, как Интернет стремится к всеобщей доступности информации, DependencyAI стремится к всеобщей доступности надежного метода определения происхождения текста, не зависящего от языковых особенностей или лексического наполнения.
Куда двигаться дальше?
Представленная работа, несмотря на свою эффективность в выявлении текстов, сгенерированных искусственным интеллектом посредством анализа синтаксической структуры, лишь обнажает глубину нерешенных проблем. Истинная элегантность алгоритма заключается не в достижении высокой точности на текущем наборе данных, а в его способности сохранять корректность при столкновении с непредсказуемыми изменениями в моделях генерации текста. В конечном счете, зависимость от синтаксиса — это лишь один из уровней защиты, и новые модели, безусловно, найдут способы обхода этих ограничений, возможно, путем имитации не только смысла, но и структуры языка.
Особое внимание следует уделить исследованию устойчивости метода DependencyAI к намеренным искажениям синтаксиса, направленным на обман детектора. Иллюзорно полагаться на статистическую значимость признаков, если не существует доказательства их инвариантности к будущим манипуляциям. Более того, перспективным направлением представляется разработка методов, способных оценивать правдоподобие текста, а не просто его происхождение — ведь даже идеально сгенерированный текст может быть бессмысленным. В хаосе данных спасает только математическая дисциплина.
В конечном счете, задача обнаружения текстов, сгенерированных ИИ, — это не столько технологическая, сколько философская проблема. Попытки создания “детекторов лжи” для машин — это отражение нашего собственного стремления к порядку в мире, где случайность и неопределенность являются фундаментальными принципами. Истинная победа будет достигнута не тогда, когда машина будет обнаружена, а когда она научится создавать тексты, неотличимые от человеческих — и тогда вопрос о происхождении текста потеряет всякий смысл.
Оригинал статьи: https://arxiv.org/pdf/2602.15514.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-18 13:08