Автор: Денис Аветисян
В новой статье рассказывается о разработке интеллектуального веб-краулера, способного эффективно извлекать статистические данные из сети.
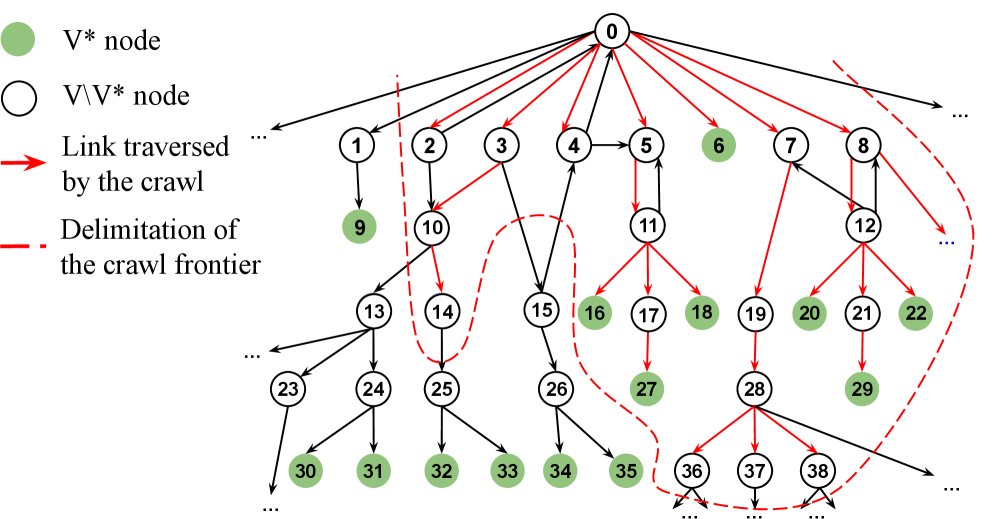
Представлен алгоритм SB-CLASSIFIER, использующий обучение с подкреплением для оптимизации приоритетов при обходе веб-страниц и повышения масштабируемости сбора данных.
Получение масштабных и качественных статистических данных из открытых источников в сети Интернет часто сопряжено со значительными трудностями и неэффективностью. В данной работе, ‘Efficient Crawling for Scalable Web Data Acquisition (Extended Version)’, предложен новый алгоритм фокусированного веб-краулинга, использующий обучение с подкреплением для эффективного извлечения целевых ресурсов с веб-сайтов. Ключевым результатом является разработка краулера SB-CLASSIFIER, который оптимизирует процесс поиска, основываясь на анализе путей к тегам, и демонстрирует высокую производительность при минимальном обходе веб-сайта. Сможет ли предложенный подход значительно упростить доступ к статистическим данным и повысить эффективность исследований в различных областях?
Неизбежность Веб-Масштаба: Вызовы Автоматизированного Сбора Данных
Неуклонный рост объемов данных в сети Интернет создает серьезные трудности для автоматизированного сбора информации. Ежедневно в глобальную сеть добавляются петабайты новой информации, что значительно усложняет задачу извлечения релевантных данных. Традиционные методы веб-краулинга, основанные на последовательном обходе ссылок, становятся все менее эффективными и требуют все больших вычислительных ресурсов. Огромный масштаб данных требует разработки новых, более интеллектуальных подходов к сбору информации, способных фильтровать ненужные данные и фокусироваться на конкретных целях, чтобы избежать перегрузки систем и обеспечить получение актуальных и полных наборов данных.
Традиционные методы веб-краулинга, основанные на последовательном переходе по ссылкам, часто оказываются неэффективными при работе с огромными объемами данных в современном интернете. Попытки охватить весь веб приводят к избыточному потреблению ресурсов — времени процессора, пропускной способности сети и дискового пространства — при этом значительная часть собранной информации оказывается нерелевантной поставленной задаче. В результате, формируемые наборы данных оказываются неполными, содержат много «шума» и требуют значительных усилий по очистке и фильтрации. Такой подход особенно проблематичен при поиске конкретных сведений, когда необходимо извлечь лишь небольшую часть информации из огромного количества веб-страниц, а стандартные алгоритмы сканирования не способны эффективно выделить целевые данные.
Для эффективного поиска и извлечения конкретных данных из сети требуется применение интеллектуальных стратегий, выходящих за рамки простого обхода по ссылкам. Вместо слепого сканирования, современные системы используют методы, основанные на анализе содержимого страниц, семантическом понимании запросов и машинном обучении для идентификации релевантной информации. Это позволяет им фокусироваться на целевых данных, игнорируя нерелевантный контент и значительно повышая эффективность сбора информации. В частности, применяются алгоритмы, определяющие структуру веб-сайтов, выявляющие шаблоны данных и предсказывающие вероятность нахождения необходимой информации на определенных страницах. Такой подход не только ускоряет процесс сбора данных, но и обеспечивает более высокую точность и полноту получаемых результатов, что критически важно для анализа больших данных и принятия обоснованных решений.
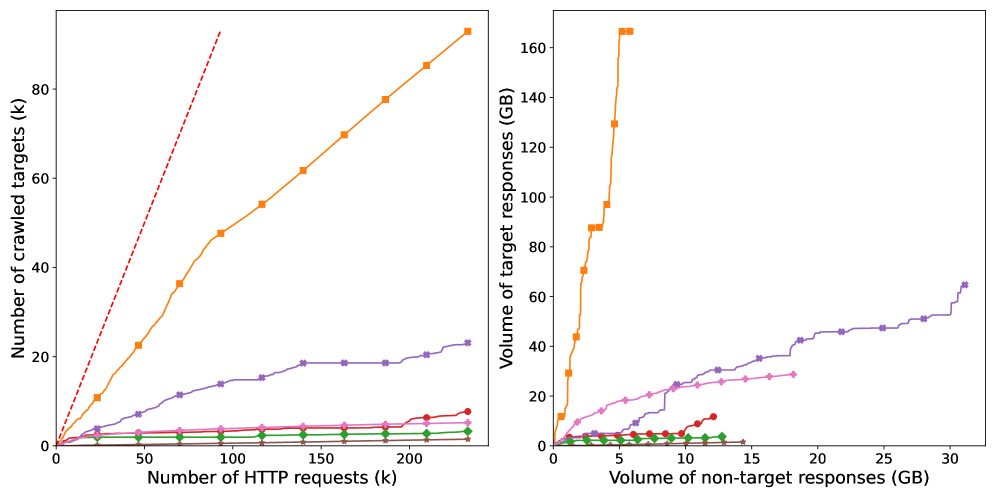
SB-CLASSIFIER: Рождение Самообучающегося Краулера
SB-CLASSIFIER представляет собой новый тип веб-краулера, разработанный для эффективного извлечения целевых данных с веб-сайтов. В отличие от традиционных краулеров, работающих по заранее заданным правилам, SB-CLASSIFIER использует алгоритмы машинного обучения для динамической адаптации стратегии обхода страниц. Это позволяет ему оптимизировать процесс сбора информации, фокусируясь на релевантных источниках и минимизируя время, затрачиваемое на обработку неважных данных. Эффективность достигается за счет способности краулера быстро адаптироваться к структуре различных веб-сайтов и находить нужную информацию даже при отсутствии четко определенных шаблонов.
SB-CLASSIFIER использует обучение с подкреплением для оптимизации стратегии обхода веб-сайтов. В процессе работы, агент постоянно оценивает эффективность различных действий (например, переход по ссылкам, заполнение форм) и корректирует свою политику на основе полученных вознаграждений. Баланс между исследованием (exploration) новых путей и использованием (exploitation) известных, эффективных стратегий достигается посредством алгоритмов, максимизирующих суммарное вознаграждение за период работы. Это позволяет краулеру динамически адаптироваться к структуре веб-сайта и повышать эффективность сбора целевых данных, избегая зацикливания и неэффективного обхода.
Для интеллектуальной навигации по веб-сайтам и локализации релевантных источников данных, SB-CLASSIFIER использует анализ путей тегов (Tag Path Analysis). Данный метод предполагает построение графа, отражающего структуру HTML-документа, где узлами являются HTML-теги, а ребрами — отношения между ними. Анализируя последовательность тегов, ведущую к целевым данным, система выявляет закономерности и формирует эффективные стратегии обхода, позволяющие оптимизировать процесс извлечения информации и снизить количество нерелевантных запросов. Это позволяет SB-CLASSIFIER динамически адаптироваться к различной структуре веб-сайтов и повысить точность поиска необходимых данных.
Оптимизация: Искусство Минимизации Энтропии
В SB-CLASSIFIER реализован механизм ранней остановки, который автоматически прекращает обход веб-сайта при снижении скорости обнаружения новых целевых страниц ниже заданного порогового значения. Данный механизм позволяет существенно повысить эффективность работы краулера за счет предотвращения дальнейшего обхода страниц, на которых вероятность нахождения релевантного контента крайне низка, что приводит к экономии ресурсов и снижению времени выполнения задачи.
Эффективность работы краулера значительно повышается за счет использования классификатора URL, который позволяет приоритизировать перспективные ссылки и отфильтровывать нерелевантный контент. Данный классификатор анализирует URL-адреса и оценивает вероятность того, что переход по ссылке приведет к целевой странице. В результате, краулер концентрируется на наиболее вероятных кандидатах, снижая количество запросов к серверу и ускоряя процесс обнаружения целевых ресурсов. Применение классификатора URL позволяет более эффективно использовать ресурсы краулера и повысить общую производительность системы.
В ходе тестирования SB-CLASSIFIER продемонстрировал превосходство над базовыми алгоритмами обхода, достигнув значительного сокращения количества запросов, необходимых для обнаружения 90% целевых страниц (см. Таблицу 2). В частности, SB-CLASSIFIER показал более высокую эффективность по сравнению со стандартными фокусированными обходчиками, такими как FOCUSED, что подтверждает его способность оптимизировать процесс сбора информации и снижать нагрузку на серверы.
Согласно данным, представленным в Таблице 2, SB-CLASSIFIER демонстрирует существенное снижение объема нецелевых страниц, обрабатываемых в процессе сканирования, по сравнению с базовыми моделями. Это снижение объема нецелевых страниц напрямую влияет на эффективность работы краулера, уменьшая нагрузку на сеть и вычислительные ресурсы, и позволяя сосредоточиться на релевантном контенте. Конкретные значения снижения объема нецелевых страниц, полученные в ходе тестирования, представлены в Таблице 2 и демонстрируют количественное преимущество SB-CLASSIFIER в оптимизации процесса сканирования.
Влияние и Возможности: Статистическая Картина Мира
Система SB-CLASSIFIER значительно упрощает сбор статистических данных, представляющих собой основу для современных исследований и аналитических работ. Эффективный сбор структурированных наборов данных позволяет исследователям оперативно получать необходимые материалы для проверки гипотез, выявления закономерностей и принятия обоснованных решений. Автоматизация процесса сбора данных не только экономит время и ресурсы, но и минимизирует вероятность ошибок, связанных с ручным извлечением информации. Благодаря SB-CLASSIFIER, ученые и аналитики получают возможность сосредоточиться на интерпретации данных и получении значимых результатов, а не на трудоемком поиске и обработке информации из различных источников. Доступ к обширным и актуальным статистическим данным становится ключевым фактором для продвижения научных знаний и разработки инновационных решений в различных областях.
Особая ценность SB-CLASSIFIER заключается в его способности находить и извлекать данные из таблиц, ориентированных на конкретные сущности. Такой подход значительно облегчает проведение структурированного анализа, поскольку информация представляется в организованном и легко обрабатываемом формате. В отличие от неструктурированных данных, требующих предварительной обработки и очистки, данные из этих таблиц сразу пригодны для статистического анализа и моделирования. Это позволяет исследователям и аналитикам экономить время и ресурсы, фокусируясь непосредственно на интерпретации результатов, а не на подготовке данных. Возможность автоматизированного извлечения структурированной информации открывает новые перспективы для масштабных исследований и разработки передовых аналитических инструментов.
Сочетание свободно доступных данных и возможностей SB-CLASSIFIER открывает принципиально новые горизонты для масштабного анализа данных и извлечения знаний. В эпоху экспоненциального роста информации, доступ к структурированным статистическим данным является ключевым фактором для прогресса в различных областях — от экономики и здравоохранения до социальных наук и экологии. SB-CLASSIFIER, эффективно извлекая данные из открытых источников, позволяет исследователям и аналитикам проводить крупномасштабные исследования, выявлять закономерности и тенденции, которые ранее оставались скрытыми из-за сложностей сбора и обработки информации. Это, в свою очередь, способствует принятию обоснованных решений, разработке инновационных стратегий и углублению понимания сложных процессов, происходящих в мире.
Исследования показали, что SB-CLASSIFIER демонстрирует повышенную эффективность извлечения целевой информации по сравнению со стандартными веб-краулерами, особенно при работе со сложными веб-сайтами, характеризующимися нестандартной структурой и динамическим контентом. Это достигается благодаря алгоритмам, оптимизированным для идентификации и извлечения статистических данных из таблиц и других структурированных элементов, что позволяет значительно сократить время и ресурсы, необходимые для сбора больших объемов информации. Превосходство SB-CLASSIFIER над базовыми краулерами особенно заметно на сайтах, где данные представлены в сложных форматах или требуют специфических методов парсинга, обеспечивая более полное и точное извлечение нужной информации для дальнейшего анализа.
Оценка точности классификации целевых страниц, проведенная на основе ручного анализа, демонстрирует показатель в пределах 70-80%. Это свидетельствует о достаточно высокой способности системы SB-CLASSIFIER к надежному определению веб-страниц, содержащих статистические данные. Такая точность позволяет эффективно фильтровать релевантную информацию из обширного информационного пространства, минимизируя количество ложных срабатываний и обеспечивая получение достоверных результатов для дальнейшего анализа и исследований. Полученные данные указывают на перспективность использования системы для автоматизированного сбора и обработки статистических данных из открытых источников.
Исследование демонстрирует, что системы сбора данных, подобно живым организмам, наиболее эффективно развиваются, адаптируясь к изменяющейся среде веб-сайтов. SB-CLASSIFIER, представляя собой подход, основанный на обучении с подкреплением, не просто извлекает статистические данные, но и учится предсказывать и обходить потенциальные «узкие места» в структуре сайтов. Как точно заметил Алан Тьюринг: «Я не думаю, что машина может думать, но она может делать все, что мы можем». Этот принцип находит отражение в способности SB-CLASSIFIER имитировать и превосходить традиционные методы обхода, приспосабливаясь к непредсказуемым изменениям веб-сайтов и, тем самым, обеспечивая более надежный и масштабируемый сбор данных. Система не просто функционирует, она эволюционирует.
Что же дальше?
Представленная работа, как и любая попытка обуздать хаос сети, лишь приоткрывает завесу над бездной нерешенных вопросов. Автоматизация сбора статистических данных, пусть и основанная на обучении с подкреплением, неизбежно сталкивается с фундаментальной проблемой: веб — это не статичная библиотека, а живой организм. Каждый рефакторинг сайта — это мутация, каждое обновление — эволюционный скачок. Алгоритм, вчера казавшийся совершенным, сегодня оказывается неспособным адаптироваться к новым условиям.
Не стоит обольщаться иллюзией полного контроля. Вместо того чтобы стремиться к созданию всеобъемлющей системы, возможно, стоит обратить внимание на принципы самоорганизации. Система, способная к самовосстановлению и эволюции, окажется куда более живучей, чем тщательно спроектированный монолит. В конце концов, каждое изменение структуры данных — это не ошибка, а неизбежный этап взросления.
Перспективы кроются не в усложнении алгоритмов, а в упрощении самой задачи. Вместо того чтобы гоняться за данными, возможно, стоит научиться слушать сеть. Пусть она сама подсказывает, где искать ценную информацию. Ведь, как известно, лучший способ понять систему — не строить ее, а наблюдать за ее ростом.
Оригинал статьи: https://arxiv.org/pdf/2602.11874.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-15 14:15