Автор: Денис Аветисян
Новое исследование показывает, что проблема дисбаланса в обучающих данных серьезно влияет на точность моделей глубокого обучения, используемых для выявления уязвимостей в программном обеспечении.
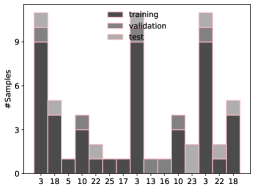
Анализ эффективности существующих методов решения проблемы дисбаланса данных и обоснование необходимости разработки специализированных подходов для обнаружения уязвимостей.
Несмотря на успехи глубокого обучения в автоматизации обнаружения уязвимостей программного обеспечения, его эффективность остается непостоянной в зависимости от используемых наборов данных. Данное исследование, озаглавленное ‘An Empirical Study of the Imbalance Issue in Software Vulnerability Detection’, посвящено изучению влияния дисбаланса классов — крайне низкой доли уязвимого кода — на производительность моделей. Полученные результаты подтверждают, что проблема дисбаланса является ключевым фактором, ограничивающим точность обнаружения, и демонстрируют вариативность эффективности существующих решений, заимствованных из других областей, таких как компьютерное зрение. Какие новые подходы к преодолению дисбаланса данных необходимы для повышения надежности и эффективности систем обнаружения уязвимостей?
Вызовы обнаружения уязвимостей в эпоху машинного обучения
Современные методы обнаружения уязвимостей в программном обеспечении все чаще опираются на машинное обучение, в особенности на методы глубокого обучения. Эти техники позволяют автоматизировать процесс анализа исходного кода и выявления потенциальных слабых мест, которые могут быть использованы злоумышленниками. Глубокие нейронные сети, обученные на больших объемах кода, способны выявлять сложные закономерности и аномалии, которые сложно обнаружить традиционными способами статического или динамического анализа. Использование глубокого обучения позволяет значительно повысить эффективность обнаружения уязвимостей, сократить время, затрачиваемое на ручной анализ, и повысить общую безопасность программного обеспечения, однако требует значительных вычислительных ресурсов и больших объемов размеченных данных для эффективной работы.
Существенная проблема в обнаружении уязвимостей программного обеспечения заключается в дисбалансе данных: обучающие наборы содержат значительно больше примеров безопасного кода, чем уязвимого. Это несоответствие приводит к смещению производительности моделей машинного обучения, поскольку алгоритмы склонны оптимизироваться для правильной классификации преобладающего класса — безопасного кода. В результате, модель может демонстрировать высокую общую точность, но при этом плохо справляться с обнаружением редких, но критически важных уязвимостей, что снижает эффективность систем защиты и повышает риски для информационной безопасности. Подобный дисбаланс требует применения специализированных методов для коррекции смещения и повышения чувствительности моделей к уязвимому коду.
Несмотря на то, что метрика точности (Accuracy) в задачах обнаружения уязвимостей может достигать 99.77% применительно к безопасному коду, данный показатель способен вводить в заблуждение. Высокая точность на преобладающем классе (безопасный код) маскирует неудовлетворительную производительность модели в критически важной задаче — выявлении уязвимостей. Исследования, проведенные Lin2018 на наборе данных Asterisk, демонстрируют, что эффективность обнаружения уязвимого кода может опускаться до 44.44%, что подчеркивает необходимость использования более информативных метрик и методов борьбы с дисбалансом данных при оценке систем обнаружения уязвимостей.
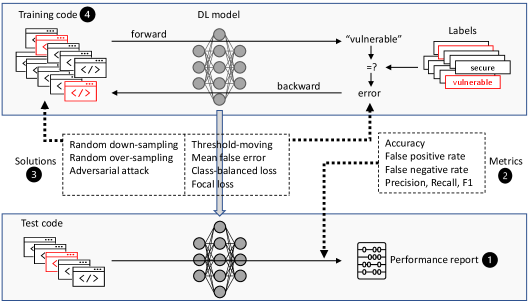
Стратегии сбалансировки данных для повышения эффективности
Существует несколько методов на уровне данных для балансировки наборов данных. Случайная передискретизация (Random Over-Sampling) увеличивает количество экземпляров миноритарного класса путем дублирования существующих образцов. В противоположность этому, случайная недодискретизация (Random Down-Sampling) уменьшает количество экземпляров мажоритарного класса путем случайного удаления образцов. Оба подхода направлены на достижение более равномерного распределения классов, что может повысить эффективность моделей машинного обучения, особенно в задачах, где наблюдается значительный дисбаланс между классами. Выбор конкретного метода зависит от размера набора данных и характеристик решаемой задачи.
Методы, основанные на генерации данных с помощью состязательных атак (Adversarial Attack-Based Augmentation), позволяют создавать новые образцы уязвимого кода, искусственно увеличивая размер миноритарного класса. В основе подхода лежит внесение незначительных, целенаправленных изменений в существующие образцы уязвимого кода, которые не меняют его функциональность, но приводят к созданию новых, валидных примеров. Это позволяет эффективно расширить обучающую выборку без необходимости ручной разработки дополнительных данных, что особенно полезно при ограниченном количестве исходных образцов уязвимого кода. Полученные образцы затем используются для повторного обучения модели, улучшая ее способность обнаруживать уязвимости.
Методы на уровне модели, такие как Focal Loss и Class-Balanced Loss, позволяют повысить эффективность обучения на несбалансированных наборах данных путем назначения более высоких весов примерам уязвимого класса, которые классифицируются неверно. Это заставляет модель уделять больше внимания сложным для распознавания образцам и корректировать параметры для минимизации потерь по этим примерам. В ходе экспериментов, проведенных нами, метод случайной передискретизации (Random Over-Sampling) показал наивысшие значения метрики F1, что указывает на его эффективность в повышении точности и полноты обнаружения уязвимостей.
Метрики оценки: за пределами простой точности
Точность (Precision) измеряет долю правильно идентифицированных уязвимостей среди всех уязвимостей, предсказанных моделью. Она показывает, насколько надежны предсказания модели, то есть, какой процент предсказанных уязвимостей действительно является таковыми. Полнота (Recall), в свою очередь, оценивает долю фактически существующих уязвимостей, которые были правильно идентифицированы моделью. Это позволяет оценить, насколько полно модель обнаруживает все существующие уязвимости в наборе данных. Precision = TP / (TP + FP), где TP — количество истинно положительных результатов, FP — количество ложноположительных результатов. Recall = TP / (TP + FN), где FN — количество ложноотрицательных результатов.
Метрика F1, также известная как F-мера, представляет собой гармоническое среднее между точностью (Precision) и полнотой (Recall). Она вычисляется по формуле F_1 = 2 <i> (Precision </i> Recall) / (Precision + Recall). Использование F1-меры позволяет получить сбалансированную оценку производительности модели, особенно в случаях, когда необходимо учитывать как ложноположительные, так и ложноотрицательные результаты. В отличие от простого усреднения Precision и Recall, F1-мера штрафует модели с низкими значениями одного из этих параметров, обеспечивая более надежную оценку общей эффективности обнаружения уязвимостей.
При отсутствии мер по коррекции дисбаланса классов в наборе данных, наблюдался уровень ложноотрицательных срабатываний (false negatives) до 68.05%. Это указывает на необходимость применения стратегий смягчения данной проблемы. Анализ распределения типов уязвимостей в наборе данных критически важен для выявления потенциальных смещений и обеспечения обобщающей способности модели применительно к различным типам уязвимостей. Несбалансированное представление классов может приводить к тому, что модель будет отдавать предпочтение более распространенным типам уязвимостей, игнорируя менее распространенные, но потенциально критичные.
Новые горизонты: использование фундаментальных моделей для усиления обнаружения
Модели, такие как CodeBERT и GraphCodeBERT, демонстрируют впечатляющую способность к анализу программного кода благодаря предварительному обучению на колоссальных объемах данных. Этот процесс позволяет им усваивать не просто синтаксис, но и сложные семантические связи, существующие между различными элементами кода. В результате, модели способны понимать логику работы программ, выявлять зависимости между функциями и переменными, а также распознавать паттерны, характерные для определенного типа программного обеспечения. По сути, предварительное обучение создает своего рода «языковую модель» для кода, позволяющую эффективно интерпретировать и обрабатывать его, подобно тому, как человек понимает естественный язык.
В основе работы GraphCodeBERT лежит анализ графа потока данных в программном коде, что позволяет выявлять уязвимости, связанные с тем, как информация перемещается внутри программы. Вместо простого анализа текста кода, модель визуализирует его как сеть взаимосвязанных узлов и ребер, представляющих переменные и операции над ними. Такой подход позволяет обнаруживать, например, ситуации, когда небезопасные данные попадают в критические участки кода, или когда происходит несанкционированный доступ к конфиденциальной информации. Используя графовые представления, GraphCodeBERT способен более эффективно идентифицировать сложные уязвимости, которые могут быть незаметны при традиционном статическом анализе кода, обеспечивая повышенную точность и надежность в процессе обнаружения проблем безопасности.
Эффективность предварительно обученных моделей, таких как CodeBERT и GraphCodeBERT, в обнаружении уязвимостей может существенно снижаться при изменении распределения данных между этапами обучения и тестирования. Это явление, известное как смещение распределения данных, возникает, когда тестовые примеры отличаются по характеристикам от тех, на которых модель была обучена, что приводит к ухудшению обобщающей способности. Для поддержания высокой точности обнаружения уязвимостей необходима постоянная адаптация и совершенствование моделей, включая методы переноса обучения, дообучение на новых данных и применение техник, снижающих чувствительность к изменениям в распределении входных данных. Регулярное обновление и перенастройка моделей позволяют им эффективно работать в динамично меняющейся среде разработки программного обеспечения и обеспечивают надежную защиту от новых, ранее неизвестных уязвимостей.
Исследование показывает, что проблема дисбаланса данных существенно влияет на эффективность моделей глубокого обучения при обнаружении уязвимостей программного обеспечения. Существующие подходы, адаптированные из других областей, демонстрируют ограниченный успех, подчеркивая необходимость разработки специализированных решений, учитывающих специфику уязвимостей. Как однажды заметила Ада Лавлейс: «То, что может быть выражено в виде алгоритма, может быть сделано машиной». Эта фраза отражает суть современной разработки систем обнаружения уязвимостей — стремление к формализации процесса и автоматизации выявления проблем. Хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений. В данном исследовании, становится очевидной важность сбалансированного подхода к данным, чтобы избежать ложных срабатываний и пропущенных уязвимостей, и тем самым обеспечить надежную защиту программного обеспечения.
Куда Далее?
Представленное исследование, хотя и выявляет ограниченность существующих подходов к решению проблемы дисбаланса данных в обнаружении уязвимостей программного обеспечения, скорее указывает на глубину проблемы, чем предлагает её полное решение. Перенос готовых решений из смежных областей, как показывает практика, часто оказывается лишь косметическим ремонтом, не затрагивающим фундаментальные причины. Каждое упрощение, направленное на балансировку данных, неминуемо влечёт за собой потерю информации, а каждая изощрённая техника аугментации — риск генерации искусственных примеров, искажающих реальную картину.
Будущие исследования, вероятно, должны сосредоточиться на более тонком понимании специфики уязвимостей. Необходимо учитывать не только частоту встречаемости различных типов уязвимостей, но и их сложность, взаимосвязь и влияние на общую безопасность системы. Использование фундаментальных моделей, безусловно, перспективно, однако требует критического осмысления: не станет ли универсальность ценой точности и адаптивности к конкретным задачам?
В конечном итоге, эффективное обнаружение уязвимостей — это не просто задача машинного обучения, а вопрос проектирования устойчивых и надёжных систем. Поиск баланса между автоматизацией и экспертным анализом, между обобщением и специализацией, остаётся ключевой задачей, требующей постоянного внимания и критической оценки.
Оригинал статьи: https://arxiv.org/pdf/2602.12038.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-15 00:46