Автор: Денис Аветисян
Новый подход позволяет большим языковым моделям развивать навыки рассуждения, не требуя дорогостоящей ручной разметки данных или внешних инструментов проверки.
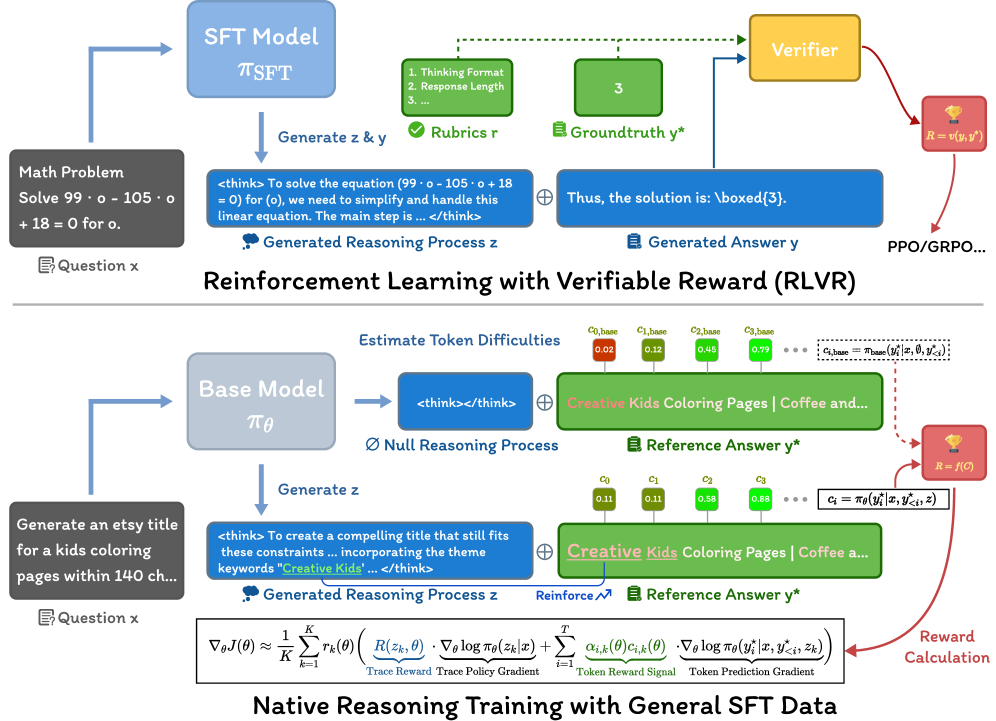
В статье представлена методика Native Reasoning Training (NRT), позволяющая языковым моделям обучаться рассуждениям, используя внутренние сигналы уверенности в правильности ответа.
Существующий подход к обучению больших языковых моделей, основанный на контролируемом обучении и обучении с подкреплением с использованием проверяемых наград, сталкивается с ограничениями, связанными с дороговизной разметки данных и риском внедрения когнитивных искажений. В статье ‘Native Reasoning Models: Training Language Models to Reason on Unverifiable Data’ предложен новый метод — Native Reasoning Training (NRT), который позволяет моделям развивать навыки рассуждения, генерируя собственные цепочки рассуждений без необходимости в экспертных демонстрациях или внешних верификаторах. NRT рассматривает процесс рассуждения как латентную переменную и использует единую целевую функцию, вознаграждающую пути, повышающие уверенность модели в правильном ответе. Способны ли подобные подходы создать более мощные и универсальные системы рассуждения, способные решать задачи, выходящие за рамки объективно оцениваемых областей?
Пределы Обучения с Учителем в Области Рассуждений
Современные языковые модели, часто использующие метод обучения с учителем (Supervised Fine-Tuning, SFT), демонстрируют впечатляющую способность к распознаванию закономерностей в данных. Однако, несмотря на успехи в имитации человеческой речи и выполнении задач, основанных на статистических связях, эти модели испытывают трудности с настоящим рассуждением. Они эффективно находят и воспроизводят существующие корреляции, но не способны к генерации новых, логически обоснованных решений, особенно в ситуациях, требующих абстрактного мышления или экстраполяции за пределы наблюдаемых данных. Фактически, модель, обученная на большом объеме текста, может успешно предсказывать следующее слово в предложении, но не обязательно понимать смысл этого предложения или уметь применять полученные знания в новом контексте, что свидетельствует о разнице между статистическим соответствием и истинным пониманием.
Исследования показывают, что увеличение масштаба современных языковых моделей, основанных на обучении с учителем, приносит всё меньше ощутимого прогресса в решении сложных задач, требующих логического мышления. Несмотря на впечатляющие результаты в распознавании образов и генерации текста, эти модели демонстрируют тенденцию к насыщению: добавление большего количества параметров и данных приводит к незначительному улучшению способности к рассуждениям, требующим не просто запоминания, а активного построения логических цепочек. Это указывает на фундаментальное ограничение подхода, основанного исключительно на статистическом анализе больших объемов данных, и подчеркивает необходимость разработки принципиально новых архитектур, способных к более глубокому пониманию и решению проблем.
Для достижения надежного рассуждения недостаточно просто распознавать закономерности в данных; необходимы системы, которые активно конструируют решения. Вместо пассивного сопоставления с ранее увиденными примерами, такие системы должны уметь разбивать сложные задачи на более простые шаги, формулировать гипотезы и проверять их, подобно тому, как это делает человеческий мозг. Такой подход предполагает не просто запоминание ответов, а развитие способности к логическому выводу и построению аргументов, что позволяет преодолеть ограничения, присущие моделям, основанным исключительно на статистическом сопоставлении. По сути, речь идет о переходе от «угадывания» правильного ответа к его созданию на основе фундаментальных принципов логики и знаний.
Введение в Обучение с Встроенным Рассуждением (NRT)
Обучение на основе встроенного рассуждения (Native Reasoning Training, NRT) представляет собой новый подход к развитию навыков логического мышления у моделей искусственного интеллекта, отличающийся отсутствием необходимости в явном контроле или разметке данных. В отличие от традиционных методов, требующих предварительно размеченных примеров рассуждений, NRT позволяет модели самостоятельно осваивать логические цепочки и процессы принятия решений, опираясь на внутренние механизмы оценки и самокоррекции. Это достигается за счет оптимизации не только конечного результата, но и промежуточных шагов рассуждений, что позволяет модели более эффективно обобщать знания и решать сложные задачи.
Метод Native Reasoning Training (NRT) развивает существующие подходы, такие как Supervised Fine-Tuning (SFT) и обучение с подкреплением с использованием проверяемых наград (Reinforcement Learning with Verifiable Rewards — RLVR), для непосредственной оптимизации этапов рассуждений. В отличие от традиционных методов, которые фокусируются на конечном результате, NRT направлен на улучшение способности модели последовательно и логически выстраивать процесс решения задачи. Это достигается путем обучения модели не только давать правильные ответы, но и демонстрировать корректные промежуточные шаги, что позволяет повысить надежность и интерпретируемость принимаемых решений. Оптимизация непосредственно этапов рассуждений позволяет модели эффективно обобщать знания и решать более сложные задачи, требующие многоступенчатого анализа.
В рамках Native Reasoning Training (NRT) ключевым элементом является использование внутреннего сигнала вознаграждения (Intrinsic Reward), основанного на уверенности модели в её ответе. Этот сигнал генерируется на основе оценки вероятности, присвоенной моделью выбранному варианту ответа, и служит для направления процесса обучения. Экспериментальные данные демонстрируют, что применение данного подхода позволяет добиться улучшения результатов в среднем на 10.2 пункта на различных бенчмарках, что свидетельствует о повышении способности модели к последовательному и обоснованному рассуждению.
Оптимизация Агрегации Вознаграждений в NRT
В системе NRT (Neural Reward Training) для агрегации сигналов вознаграждения используются два основных подхода: взвешенная сумма (Weighted Sum) и геометрическое среднее (Geometric Mean). Взвешенная сумма позволяет комбинировать различные компоненты вознаграждения с учетом их относительной важности, определяемой весовыми коэффициентами. Геометрическое среднее, в свою очередь, более чувствительно к наименьшим значениям вознаграждения, что может быть полезно в задачах, где важно избегать даже незначительных ошибок. Выбор конкретной функции агрегации зависит от специфики решаемой задачи и характеристик используемых сигналов вознаграждения. Оба подхода, NRT-WS и NRT-GM, используют Group Relative Policy Optimization (GRPO) для эффективного обновления политики модели.
Оба подхода NRT-WS (Weighted Sum) и NRT-GM (Geometric Mean) используют алгоритм Group Relative Policy Optimization (GRPO) для эффективного обновления политики модели. GRPO позволяет оптимизировать политику, учитывая относительные преимущества действий в группе, что повышает стабильность обучения и ускоряет сходимость. В основе GRPO лежит вычисление преимуществ действий относительно среднего преимущества в группе, что позволяет снизить дисперсию оценок и улучшить качество обновления политики. Этот метод особенно эффективен в задачах, где действия могут быть взаимосвязаны, и важно учитывать контекст группы при принятии решений.
Оценка производительности модели требует использования метрик, таких как вероятность последовательности, и следования стандартизированным фреймворкам, например, Open Language Model Evaluation Standard. В частности, NRT демонстрирует результат в 76.0 баллов по тесту GSM8K, что значительно превосходит базовый показатель SFT, составляющий 29.0. Данное улучшение указывает на эффективность предложенного подхода к агрегации вознаграждений и его влияние на способность модели решать задачи математического рассуждения.
Значение и Перспективы Развития
Исследования демонстрируют, что новый подход, известный как NRT, открывает перспективные пути к созданию языковых моделей, способных к подлинному рассуждению, а не просто к поверхностному распознаванию закономерностей. В отличие от традиционных методов обучения, полагающихся на большие объемы размеченных данных, NRT фокусируется на вознаграждении модели за каждый логический шаг в процессе решения задачи. Это позволяет языковой модели самостоятельно развивать навыки рассуждения, а не просто запоминать связи между входными данными и ожидаемыми ответами. Такой подход потенциально способен преодолеть ограничения существующих моделей, которые часто демонстрируют впечатляющую производительность на простых задачах, но терпят неудачу, когда сталкиваются с более сложными сценариями, требующими логического мышления и анализа.
Метод NRT преодолевает ограничения традиционных подходов к обучению с учителем, фокусируясь на вознаграждении за каждый этап логических рассуждений, а не только за конечный результат. В отличие от систем, которые стремятся просто сопоставить входные данные с ответами, NRT стимулирует модель к последовательному и обоснованному мышлению. Внедрение внутренних вознаграждений позволяет модели самостоятельно оценивать качество своих промежуточных шагов, тем самым улучшая способность к обобщению и решению новых, сложных задач. Такой подход позволяет создавать языковые модели, которые демонстрируют не просто распознавание закономерностей, а подлинное умение рассуждать и обосновывать свои выводы.
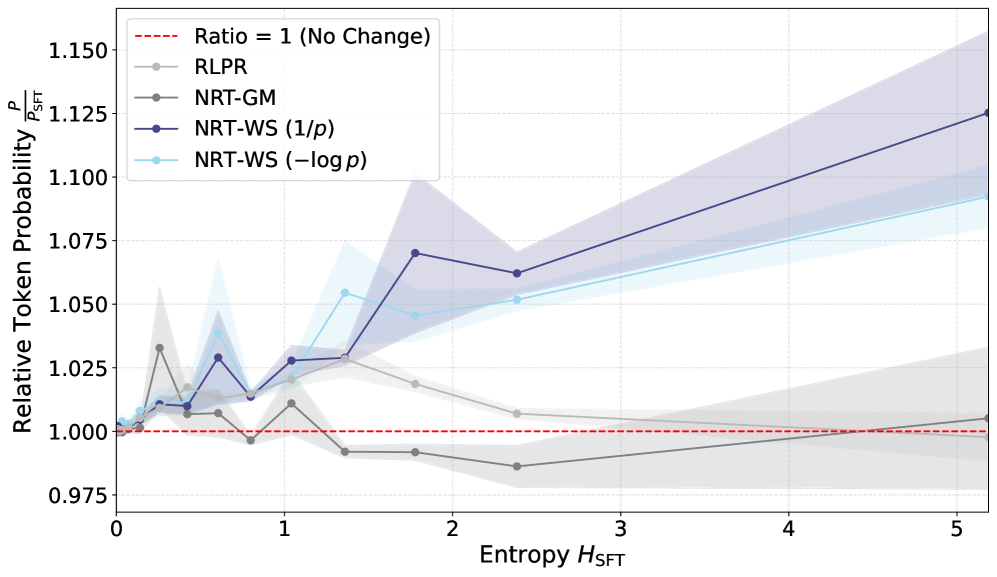
Дальнейшие исследования направлены на усовершенствование функций вознаграждения и изучение различных алгоритмов оптимизации для расширения возможностей NRT при решении более сложных задач, требующих логического мышления. Особое внимание уделяется применению методов оценки преимущества \hat{A} для повышения стабильности процесса обучения. Результаты показывают значительный прогресс: NRT демонстрирует относительное увеличение уверенности в прогнозах на 63% при ответах на вопросы, основанные на фактах, по сравнению с базовым показателем в 30.8% для моделей, обученных с помощью традиционного контролируемого обучения (SFT). Это указывает на перспективность подхода NRT для создания языковых моделей, способных не просто распознавать закономерности, но и демонстрировать подлинные навыки рассуждения.
Исследование представляет собой элегантный подход к обучению моделей рассуждения, избегая дорогостоящей необходимости в человеческой аннотации или внешних верификаторах. Вместо этого, акцент делается на внутреннем вознаграждении за генерацию логичных цепочек рассуждений, повышающих уверенность модели в правильном ответе. Как однажды заметил Кен Томпсон: «Простота — это высшая степень изысканности». Эта фраза прекрасно отражает суть представленного подхода: стремление к созданию системы, которая может рассуждать самостоятельно, опираясь на внутреннюю логику и уверенность, а не на внешние подтверждения. Подобная структура, где поведение системы определяется ее внутренней уверенностью, позволяет избежать переусложнения и добиться большей надежности.
Что Дальше?
Представленный подход к обучению языковых моделей рассуждению, избегая внешних верификаторов и дорогостоящей ручной разметки, кажется элегантным решением. Однако, истинная ценность подобной архитектуры станет видна лишь со временем. Существующие системы вознаграждения, основанные на увеличении уверенности модели, могут оказаться недостаточными для преодоления врожденной склонности к самообману. Необходимо тщательно исследовать, как избежать ситуаций, когда модель уверенно, но ошибочно, приходит к неверным выводам.
Особый интерес представляет вопрос о масштабируемости. Насколько хорошо предложенный метод будет работать с моделями, значительно превосходящими современные по размеру и сложности? Не приведёт ли увеличение числа параметров к усилению внутренних противоречий и, как следствие, к снижению надёжности рассуждений? Поиск оптимального баланса между сложностью модели и эффективностью обучения представляется ключевой задачей.
В конечном счёте, хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений. Будущие исследования должны быть направлены не только на повышение точности, но и на разработку методов оценки внутренней согласованности и устойчивости систем рассуждений. Иначе, мы рискуем создать сложные, но хрупкие конструкции, способные обмануть самих себя и нас.
Оригинал статьи: https://arxiv.org/pdf/2602.11549.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-14 23:18