Автор: Денис Аветисян
Новая методика позволяет значительно снизить вычислительные затраты AI-агентов, основанных на эволюционных алгоритмах, без потери качества их работы.
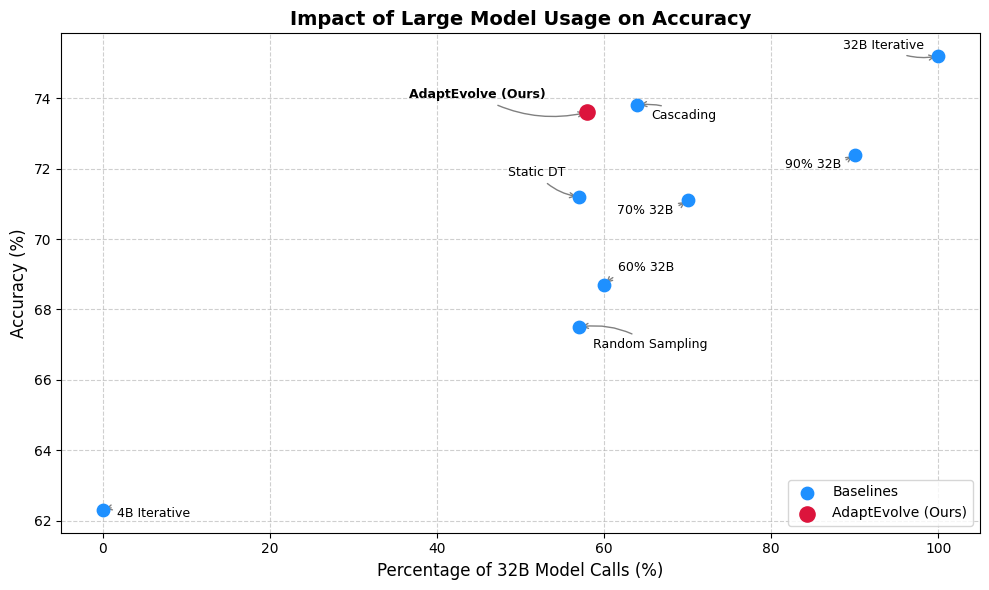
В статье представлена система AdaptEvolve, динамически выбирающая оптимальную модель (от малых до больших языковых моделей) на основе оценки неопределенности, что повышает эффективность агентного мышления и снижает потребность в вычислительных ресурсах.
Эволюционные агентные системы сталкиваются с противоречием между вычислительной эффективностью и способностью к рассуждению, особенно при многократном обращении к большим языковым моделям (LLM) в процессе работы. В данной работе, ‘AdaptEvolve: Improving Efficiency of Evolutionary AI Agents through Adaptive Model Selection’, представлен новый подход к динамическому выбору LLM, основанный на оценке внутренней неопределенности модели для каждого этапа эволюции. Предложенный фреймворк позволяет снизить общую вычислительную стоимость на 37.9% при сохранении 97.5% от производительности статических моделей-эталонов. Возможно ли дальнейшее повышение эффективности адаптивного выбора моделей за счет учета дополнительных факторов, таких как сложность задачи или доступные ресурсы?
Неизбежный Техдолг: О Глубине Рассуждений и Экономической Эффективности
Несмотря на впечатляющие возможности, современные большие языковые модели (БЯМ) сталкиваются с серьезными проблемами в области глубины рассуждений и экономической эффективности. Исследования показывают, что статические модели, обладающие огромным количеством параметров, потребляют на 30% больше вычислительных ресурсов по сравнению с более оптимизированными подходами. Это связано с тем, что простое увеличение масштаба трансформаторных сетей дает все меньше отдачи, и для достижения значительного прогресса необходимо разрабатывать новые архитектуры, способные эффективно обрабатывать информацию и снижать затраты на вычисления. Таким образом, повышение вычислительной эффективности становится ключевой задачей для дальнейшего развития и широкого внедрения БЯМ.
Несмотря на впечатляющие возможности, простое увеличение размера трансформерных моделей демонстрирует эффект убывающей отдачи. Дальнейшее масштабирование требует перехода к более эффективным архитектурам, способным оптимизировать вычислительные ресурсы. Исследования показывают, что внедрение таких инноваций может привести к значительному снижению затрат на инференс — до 37.9%. Это означает, что при сохранении или даже улучшении качества работы моделей, можно существенно уменьшить потребляемую энергию и стоимость их эксплуатации, открывая новые возможности для широкого применения в различных областях, от обработки естественного языка до компьютерного зрения.
Традиционные подходы к обработке данных, как правило, не учитывают разницу в сложности различных входных запросов, относясь ко всем одинаково. Это приводит к неэффективному использованию вычислительных ресурсов, поскольку сложные задачи требуют больше внимания, а простые — меньше. Исследования показывают, что оптимизация распределения ресурсов в зависимости от сложности входных данных может значительно повысить эффективность обработки. Вместо равномерного распределения, системы могут динамически выделять больше мощности для ресурсоемких задач, и наоборот, экономя энергию и снижая задержки. Такой подход позволяет добиться существенного улучшения производительности, не увеличивая общую вычислительную нагрузку, и открывает возможности для создания более адаптивных и экономичных систем обработки информации.

Многомодельный Вывод: Баланс Между Качеством и Затратами
Многомодельный вывод (Multi-Model Inference) представляет собой принципиально новый подход к оптимизации процесса инференса, позволяющий находить баланс между качеством результатов и вычислительными затратами. Вместо использования единой модели для всех запросов, данный подход предполагает использование нескольких моделей с различными характеристиками. Более компактные и быстрые модели применяются для простых запросов, требующих минимальных ресурсов, в то время как более сложные и ресурсоемкие модели задействуются для задач, требующих высокой точности и детализации. Это позволяет существенно снизить общую стоимость инференса без потери качества для критически важных задач, что особенно актуально в условиях ограниченных вычислительных ресурсов или при обработке больших объемов данных.
Фреймворк AdaptEvolve реализует динамическую маршрутизацию входящих запросов между двумя моделями: Qwen3-4B, оптимизированной по затратам, и Qwen3-32B, обладающей высокой производительностью. В процессе работы система автоматически направляет простые запросы в Qwen3-4B для снижения вычислительных издержек, а сложные — в Qwen3-32B, обеспечивая высокое качество ответов. Такая стратегия позволяет достичь снижения общего объема вычислений, необходимых для обработки запросов, на 37.9% по сравнению со статической моделью.
Маршрутизация запросов в AdaptEvolve осуществляется посредством дерева решений, обученного на оценке сложности входных данных. Дерево решений анализирует характеристики запроса и, на основе полученной оценки, направляет его либо к вычислительно-эффективной модели Qwen3-4B, либо к более мощной Qwen3-32B. Процесс обучения дерева решений основан на данных о производительности моделей на различных типах входных данных, что позволяет оптимизировать баланс между скоростью и точностью. Принцип работы напоминает эффективные биологические системы, где ресурсы распределяются в зависимости от текущей потребности и сложности задачи.
Уверенность в Решении: Оценка Сложности и Маршрутизация Запросов
AdaptEvolve использует внутренние сигналы неопределенности, такие как уверенность в токенах (Token Confidence), для оценки сложности входных данных и принятия решений о маршрутизации запросов. Этот подход позволяет системе динамически определять, какие модели наиболее подходят для обработки конкретного ввода, основываясь на оценке сложности, выраженной через уверенность модели в каждом токене. Более низкая уверенность в токенах указывает на более сложный ввод, что может привести к перенаправлению запроса на более мощную, но ресурсоемкую модель, или, наоборот, на более быструю, но менее точную модель, в зависимости от установленных приоритетов и баланса между скоростью и точностью.
Для оценки неопределенности модели AdaptEvolve используется набор метрик уверенности, включающий среднюю уверенность (Mean Confidence), определяющую общую уверенность модели в токенах; уверенность в «хвосте» распределения (Tail Confidence), фиксирующую уверенность в наименее вероятных предсказаниях; уверенность в наихудшей группе токенов (Lowest Group Confidence), выявляющую участки ввода, вызывающие наибольшие затруднения; и уверенность в нижних K% токенов (Bottom-K% Confidence), позволяющую отслеживать уровень неопределенности в наименее уверенных предсказаниях. Использование комбинации этих метрик позволяет комплексно оценить сложность входных данных и эффективно направлять процесс маршрутизации запросов.
Дерево решений обучается с целью максимизации Парето-эффективности, что позволяет находить оптимальный баланс между стоимостью вычислений и точностью предсказаний путем выбора подходящей модели для каждого конкретного запроса. Обучение направлено на поддержание не менее 97.5% от верхней границы производительности, достигаемой статичными, крупными моделями, при одновременном снижении вычислительных затрат за счет динамического выбора моделей меньшего размера для менее сложных входных данных.
Онлайн-Адаптация и Эволюционная Оптимизация: Эффективность в Действии
AdaptEvolve использует архитектуру OpenEvolve для обеспечения онлайн-адаптации маршрутизатора на основе дерева решений. OpenEvolve предоставляет базовый каркас для эволюционных алгоритмов, позволяя AdaptEvolve динамически изменять структуру дерева решений в процессе работы. Это достигается за счет непрерывного мониторинга производительности маршрутизатора и внесения корректировок в его параметры на основе поступающих данных. Такой подход позволяет маршрутизатору адаптироваться к меняющимся условиям сети и оптимизировать свою работу в реальном времени, без необходимости перезагрузки или ручной настройки.
Дерево Хоффдинга представляет собой расширение базового дерева решений, предназначенное для непрерывного обучения и адаптации в нестационарных средах. В отличие от статических деревьев решений, дерево Хоффдинга использует статистический подход, основанный на неравенстве Хоффдинга, для оценки значимости изменений в данных. Это позволяет дереву динамически обновлять свою структуру, добавляя или удаляя узлы и ветви по мере поступления новых данных, без необходимости полной перестройки. Такой подход особенно эффективен в средах, где распределение данных меняется со временем, поскольку дерево способно быстро адаптироваться к новым условиям и поддерживать высокую точность прогнозов. В основе работы лежит оценка статистической значимости каждого признака, позволяющая избежать переобучения на небольших изменениях в данных и сосредоточиться на действительно важных закономерностях.
Динамическая стратегия маршрутизации, реализованная в AdaptEvolve, способствует ускорению итеративной генерации, мутации и отбора кандидатов решений в рамках Agentic Reasoning. Ускорение достигается за счет адаптации Decision Tree роутера в режиме реального времени, позволяя системе оперативно реагировать на изменения в среде и быстро оценивать эффективность различных вариантов маршрутизации. Это позволяет Agentic Reasoning быстрее находить оптимальные решения, оптимизируя процесс поиска и повышая общую производительность системы. Быстрая оценка кандидатов решений является ключевым фактором для эффективного Agentic Reasoning, особенно в сложных и динамических средах.
Эмпирические Результаты и Перспективы Развития: Взгляд в Будущее
Исследование AdaptEvolve на эталонных наборах данных LiveCodeBench и MBPP продемонстрировало существенное повышение экономичности без потери производительности. В частности, удалось снизить вычислительные затраты на этапе вывода на 41.5% при работе с MBPP, при этом сохранив 97.1% от максимальной достижимой точности. Такой результат указывает на эффективность разработанного подхода к адаптивному выбору маршрутов, позволяющего оптимизировать баланс между сложностью модели и скоростью вычислений, что делает AdaptEvolve перспективным решением для задач, требующих высокой производительности и ограниченных ресурсов.
Адаптивная стратегия маршрутизации, лежащая в основе данной системы, позволяет эффективно сбалансировать компромисс между сложностью модели и скоростью вычислений. В ходе тестирования на наборе данных MBPP, она продемонстрировала впечатляющую эффективность, достигнув показателя 132.3, что почти вдвое превышает эффективность использования чистой большой модели, зафиксированную на уровне 79.7. Этот результат указывает на способность системы динамически выбирать оптимальный путь обработки информации, снижая вычислительные затраты без существенной потери в производительности, что делает ее перспективной для задач, требующих быстрого и эффективного решения.
Адаптация дерева решений позволила повысить точность на 2,4% при работе с набором данных LiveCodeBench, что свидетельствует о потенциале данного подхода для улучшения производительности в задачах, требующих сложного логического вывода. В дальнейшем планируется усовершенствовать систему оценки достоверности принимаемых решений, используя более сложные метрики, что позволит более эффективно направлять процесс адаптации. Исследователи также намерены расширить возможности AdaptEvolve, применив его к другим задачам, требующим комплексного анализа и рассуждений, с целью подтвердить универсальность и эффективность предложенного фреймворка в различных областях применения.
В рамках исследования AdaptEvolve, где динамический выбор между малыми и большими языковыми моделями призван оптимизировать вычислительные затраты, особенно ярко проявляется неизбежность технического долга. Каждая инновация, как бы элегантно она ни была спроектирована, рано или поздно столкнется с суровой реальностью продакшена. Как говорил Джон фон Нейманн: «В науке не бывает принципиальных отличий между прошлым, настоящим и будущим». Идея AdaptEvolve, заключающаяся в адаптивном выборе моделей на основе оценки неопределенности, — это попытка отсрочить неизбежное, но, в конечном счете, даже самые продвинутые системы столкнутся с необходимостью рефакторинга и оптимизации. Всё, что можно задеплоить, однажды упадёт — это закономерность, которую AdaptEvolve лишь элегантно обходит, а не отменяет.
Что дальше?
Представленная работа, безусловно, демонстрирует, как можно временно замедлить неизбежный рост аппетитов современных алгоритмов. Динамический выбор между «маленькими» и «большими» моделями — это, скорее, тактический манёвр, чем стратегическое решение. Продакшен, как известно, найдет способ и из «маленькой» модели выжать все соки, а затем потребует ещё больше. И не стоит забывать: любая метрика «уверенности» — это лишь очередная аппроксимация, которая рано или поздно даст сбой. Оптимизация ради оптимизации — занятие, конечно, полезное, пока не превращается в самоцель.
Более интересным представляется вопрос не столько о выборе модели, сколько о самой парадигме эволюционных алгоритмов. Всё новое — это старое, только с другим именем и теми же багами. Необходимо задуматься о фундаментальных ограничениях подхода, основанного на случайных мутациях и отборе. Возможно, истинный прогресс лежит в области разработки принципиально новых методов обучения, способных к самоанализу и коррекции собственных ошибок — то есть, в создании алгоритмов, способных предвидеть, где именно их начнут ломать в продакшене.
В конечном счёте, эта работа — лишь ещё один шаг в бесконечном цикле: разработка, оптимизация, взлом, повторная оптимизация. И если всё работает сейчас — просто подождите. Продакшен не дремлет.
Оригинал статьи: https://arxiv.org/pdf/2602.11931.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
2026-02-14 01:18