Автор: Денис Аветисян
Новое исследование объясняет, почему методы, основанные на оценке вероятности, часто оказываются эффективными для поиска необычных данных в таблицах, в отличие от изображений.

Анализ показывает, что контринтуитивное явление, наблюдаемое при аномальном обнаружении изображений, редко встречается в табличных данных, что делает нормализующие потоки перспективным решением.
Неожиданно, что методы, эффективно выявляющие аномалии в изображениях на основе правдоподобия, демонстрируют иные результаты применительно к табличным данным. В работе, озаглавленной ‘Why the Counterintuitive Phenomenon of Likelihood Rarely Appears in Tabular Anomaly Detection with Deep Generative Models?’, исследуется причина редкого проявления контринтуитивного феномена, когда модели генеративного типа ошибочно назначают высокую вероятность аномальным данным в табличных выборках. Полученные результаты, основанные на анализе 47 табличных и 10 встраивающих датасетов, подтверждают, что подобное поведение встречается крайне редко, что указывает на надежность использования нормализующих потоков для обнаружения аномалий в табличных данных. Возможно ли, что свойства корреляции признаков и размерность данных являются ключевыми факторами, определяющими эффективность likelihood-based методов в различных доменах?
Аномалии: вызов за пределами привычных границ
Выявление аномалий играет ключевую роль в самых разных областях — от обнаружения мошеннических операций и обеспечения кибербезопасности до прогностического обслуживания оборудования и контроля качества продукции. Однако, традиционные методы анализа данных зачастую оказываются неэффективными при работе со сложными, многомерными наборами данных. Это связано с тем, что алгоритмы, разработанные для более простых сценариев, не способны адекватно учитывать взаимосвязи между большим количеством параметров и выявлять отклонения, которые могут указывать на действительно значимые аномалии. В результате, такие подходы часто приводят к ложным срабатываниям или, что еще опаснее, к пропуску критически важных событий, требующих немедленного внимания.
Суть проблемы заключается в точном моделировании “нормального” поведения для эффективного выявления отклонений, задача, осложняемая внутренними характеристиками данных. Данные, по своей природе, редко соответствуют простым статистическим распределениям; они могут демонстрировать нелинейные зависимости, сезонность, тренды и сложные взаимосвязи между признаками. Это делает построение адекватной модели “нормальности” крайне сложной задачей, поскольку любое упрощение неизбежно приводит к ошибкам. Более того, “нормальность” может быть динамичной и меняться со временем, требуя от моделей способности к адаптации и самообучению. Игнорирование этих внутренних характеристик приводит к тому, что алгоритмы, основанные на упрощенных предположениях, либо генерируют большое количество ложных срабатываний, классифицируя нормальные данные как аномальные, либо пропускают действительно важные отклонения, что снижает эффективность всей системы обнаружения аномалий.
По мере увеличения объемов данных и усложнения их структуры, упрощенные предположения о распределении данных часто приводят к высокой частоте ложных срабатываний и упущению критически важных аномалий. Традиционные методы, основанные на нормальном распределении или линейных моделях, оказываются неэффективными при работе с многомерными данными, содержащими нелинейные зависимости и сложные взаимосвязи. В результате, незначительные отклонения, не несущие реальной угрозы, ошибочно идентифицируются как аномалии, в то время как действительно важные отклонения, указывающие на серьезные проблемы, остаются незамеченными. Эта проблема особенно актуальна в сферах, где стоимость пропущенной аномалии значительно превышает стоимость ложного срабатывания, например, в системах обнаружения мошенничества или в прогнозировании отказов оборудования. Поэтому, разработка более сложных и адаптивных методов анализа данных, учитывающих нюансы реальных распределений, является ключевой задачей для повышения эффективности обнаружения аномалий.
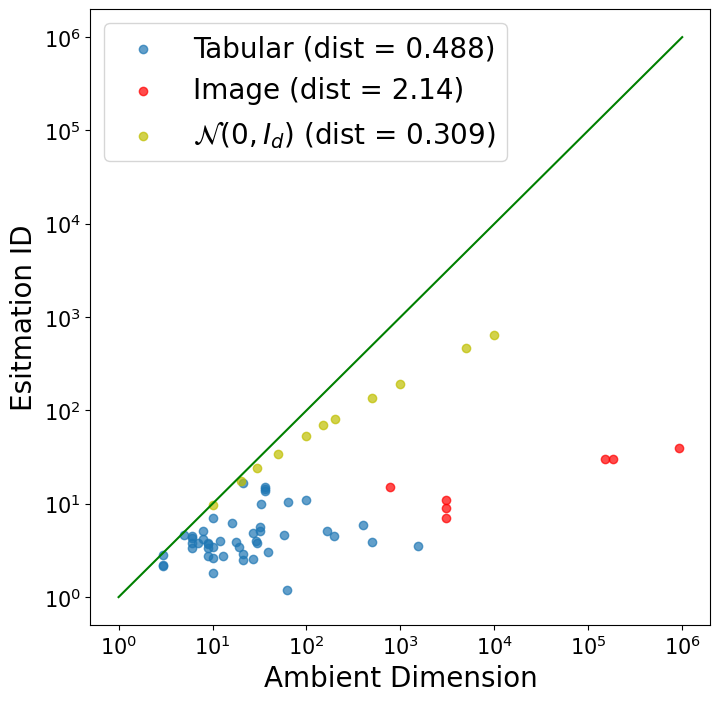
Внутренняя размерность и связи признаков: ключ к пониманию
Понимание внутренней размерности набора данных имеет решающее значение, поскольку увеличение размерности пространства признаков приводит к усугублению проблем обнаружения аномалий, что обусловлено так называемым «проклятием размерности». В пространствах высокой размерности, расстояние между точками данных становится более однородным, что затрудняет выделение аномальных объектов, которые по определению отличаются от основной массы данных. Кроме того, для адекватного представления данных в пространстве высокой размерности требуется экспоненциально возрастающее количество данных, что делает задачу оценки плотности распределения и, следовательно, выявления отклонений, статистически ненадежной. O(n) — сложность алгоритмов поиска ближайших соседей, резко возрастает с ростом размерности d.
Взаимосвязь между признаками играет критическую роль в обнаружении аномалий. Сильная корреляция между признаками может привести к маскировке незначительных отклонений, поскольку аномалия в одном признаке может быть компенсирована ожидаемым изменением в другом, что искажает общую картину. Это приводит к ложноотрицательным результатам при анализе данных. Кроме того, высокая корреляция может приводить к неверной интерпретации распределения данных, поскольку традиционные статистические методы, предполагающие независимость признаков, становятся неприменимыми или дают неточные результаты. Анализ матриц корреляции и применение методов, учитывающих взаимозависимости признаков, таких как анализ главных компонент или методы на основе деревьев решений, необходимы для корректной идентификации аномалий в данных с высокой степенью корреляции.
Для точного выявления взаимосвязей между признаками, помимо простых статистических мер, таких как коэффициент корреляции Пирсона, необходимо использовать методы, способные учитывать нелинейные зависимости и сложные взаимодействия. К ним относятся методы на основе теории информации (например, взаимная информация), методы, основанные на графах (например, оценка условной зависимости), и методы машинного обучения, такие как случайные леса и нейронные сети. Эти методы позволяют более полно описать структуру данных и выявить аномалии, которые могут быть скрыты при использовании только линейных статистических показателей. Оценка этих взаимосвязей критически важна для построения эффективных моделей обнаружения аномалий, особенно в высокоразмерных пространствах, где линейные модели могут оказаться неадекватными.
Современные подходы к обнаружению аномалий: разнообразный инструментарий
Для обнаружения аномалий используется широкий спектр методов, включая One-Class SVM (OCSVM), Isolation Forest (IF) и COPOD. OCSVM эффективно работает с данными высокой размерности, но чувствителен к выбору ядра и параметров регуляризации. Isolation Forest основан на принципе, что аномалии легче изолировать, чем нормальные данные, и демонстрирует высокую скорость работы, особенно на больших наборах данных. COPOD (Class-based Outlier Prediction using Ordered Distribution) использует статистические характеристики данных для оценки аномальности, эффективно обнаруживая контекстные аномалии, однако может требовать значительных вычислительных ресурсов. Выбор конкретного метода зависит от характеристик данных, таких как размерность, распределение и наличие шума, а также от требований к скорости работы и интерпретируемости результатов.
Современные подходы к обнаружению аномалий активно используют возможности глубокого обучения для построения сложных представлений данных. Методы, такие как Deep Autoencoding Gaussian Mixture Models (DAGMM), объединяют автоэнкодеры для снижения размерности и Gaussian Mixture Models для моделирования нормального распределения данных, позволяя эффективно выявлять отклонения. Neural Trajectory Learning (NeuTraLAD) фокусируется на изучении траекторий данных и выявлении аномальных последовательностей, особенно эффективных при работе с временными рядами и данными о поведении. Оба подхода позволяют автоматически извлекать признаки и адаптироваться к сложным, нелинейным зависимостям в данных, что повышает точность обнаружения аномалий по сравнению с традиционными методами.
Методы нормализующих потоков (Normalizing Flows, NF), такие как NF-SLT, представляют собой генеративные модели, способные отображать простое распределение (например, гауссовское) в сложное распределение данных посредством серии обратимых преобразований. В отличие от других методов обнаружения аномалий, NF моделируют распределение нормальных данных, позволяя точно оценивать вероятность каждой точки данных. Аномалии, как точки с низкой вероятностью согласно обученной модели, получают низкий «счет аномальности», что обеспечивает надежное выявление отклонений. NF-SLT, в частности, использует слои с разреженными соединениями для повышения эффективности и масштабируемости при работе с многомерными данными.
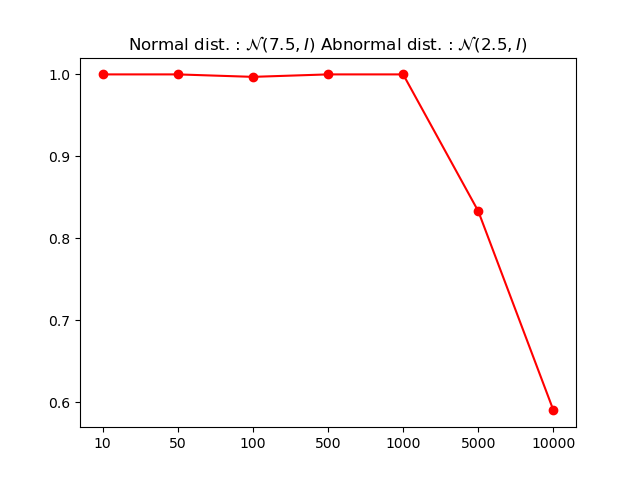
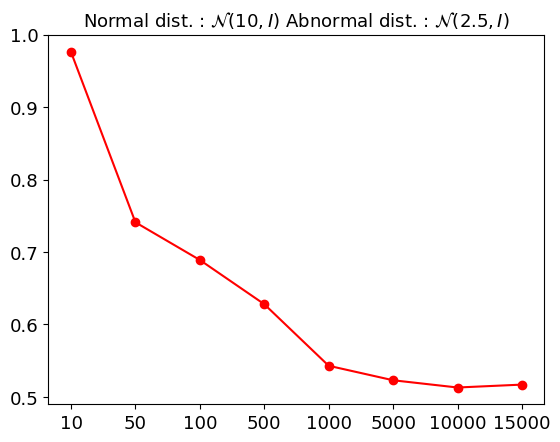
Уточнение подхода: когда оценки правдоподобия вводят в заблуждение
Наблюдаемое “контринтуитивное явление” подчеркивает ограничения, возникающие при использовании исключительно оценок правдоподобия для обнаружения аномалий. Суть проблемы заключается в том, что модели часто испытывают трудности с точным представлением сложных распределений данных. Когда распределение не может быть адекватно смоделировано, оценки правдоподобия могут оказаться ненадёжными индикаторами аномалий, приводя к ложным срабатываниям или ложноотрицательным результатам. В таких ситуациях объекты, действительно отличающиеся от основной массы данных, могут быть ошибочно классифицированы как нормальные, если модель недооценивает вероятность их возникновения в рамках заданного распределения. Это особенно актуально для данных высокой размерности или сложных зависимостей, где точное моделирование распределения представляет значительную вычислительную задачу.
Методы, такие как взаимное соответствие (Mutual Consistency Matching, MCM) и неявное контрастное обучение (Implicit Contrastive Learning, ICL), представляют собой альтернативный подход к обнаружению аномалий, стремясь обойти ограничения, связанные с прямой оценкой правдоподобия. Вместо того, чтобы полагаться на абсолютные значения вероятности, эти методы акцентируют внимание на внутренней согласованности данных и отношениях между ними. MCM, например, стремится обеспечить, чтобы небольшие возмущения входных данных не приводили к существенным изменениям в прогнозах модели, тем самым выявляя аномалии как несоответствия в этой согласованности. ICL, в свою очередь, использует контрастное обучение для создания представлений, в которых похожие данные располагаются ближе друг к другу, а аномалии — дальше, что позволяет эффективно отделять нормальное поведение от отклонений. Такой подход, ориентированный на отношения и согласованность, демонстрирует повышенную устойчивость к сложным распределениям данных и позволяет более надежно идентифицировать аномалии, которые могли бы остаться незамеченными при использовании традиционных методов, основанных на правдоподобии.
Для объективной оценки эффективности различных подходов к обнаружению аномалий, критически важна надежная проверка с использованием метрик, таких как площадь под ROC-кривой (AUROC), на стандартных наборах данных, например, ADBench. Проведенное исследование демонстрирует, что модель NF-SLT превосходит другие методы на табличных данных ADBench, достигая высоких показателей AUROC. Это указывает на способность NF-SLT более точно различать нормальные и аномальные образцы, что делает её перспективным инструментом для решения задач выявления отклонений в табличных данных. Высокие результаты, полученные на ADBench, подтверждают эффективность предложенного подхода и его потенциал для практического применения в различных областях, где требуется надежное обнаружение аномалий.
Анализ данных, представленных в табличной форме, демонстрирует значительно более низкое отношение размерности внутренних представлений к размерности исходного пространства — приблизительно 1%, в отличие от изображений, где это отношение гораздо выше. Это указывает на менее выраженный эффект “проклятия размерности” для табличных данных. В результате, контринтуитивное поведение, связанное с использованием оценок правдоподобия для обнаружения аномалий, встречается в табличных данных значительно реже, что подтверждается низкой частотой ошибок, определенной в рамках определения 3.3. Такая особенность позволяет более эффективно применять стандартные методы анализа аномалий к табличным данным, поскольку риск получения неверных результатов, обусловленных высокой размерностью, существенно снижен.
Исследование показывает, что контринтуитивное явление, часто встречающееся при обнаружении аномалий в изображениях, редко проявляется в табличных данных. Это указывает на эффективность нормализующих потоков для анализа табличных данных, поскольку корреляция признаков играет ключевую роль в формировании вероятностного пространства. Как однажды заметил Г.Х. Харди: «Математика — это наука о том, что можно логически заключить, а не о том, что очевидно». Эта фраза отражает суть представленной работы: кажущаяся очевидность эффективности likelihood-based тестов в одном контексте (изображениях) не переносится на другой (табличные данные), требуя глубокого анализа и понимания лежащих в основе принципов.
Куда Далее?
Наблюдаемая устойчивость нормализующих потоков к контринтуитивному феномену в обнаружении аномалий в табличных данных — это не триумф, а скорее указание на фундаментальное различие между структурой данных. Изображения, с их высокой размерностью и сложными корреляциями, требуют иного подхода, чем таблицы, где значимость признаков и их взаимодействие часто более прямолинейны. Вопрос не в том, что мы сделали правильно с таблицами, а в том, что мы упускаем в изобразительных данных.
Вместо того чтобы углубляться в оптимизацию архитектур нормализующих потоков, возможно, стоит обратить внимание на предобработку данных и представление признаков. Сможем ли мы спроектировать изображения таким образом, чтобы их внутренние корреляции стали более явными и поддающимися моделированию? Или, что еще более радикально, не пора ли признать, что сама концепция «правдоподобия» как критерия аномалии несовершенна, и искать более надежные метрики, основанные на информационно-теоретических принципах?
И, наконец, не следует забывать о проблеме оценки. Любое утверждение об эффективности алгоритма обнаружения аномалий зависит от качества тестовых данных. Пока не будет разработан строгий и воспроизводимый способ генерации реалистичных аномалий для табличных и изобразительных данных, все наши усилия останутся в значительной степени эмпирическими упражнениями. И в этом — простая красота науки: бесконечный поиск ясности сквозь завесу сложности.
Оригинал статьи: https://arxiv.org/pdf/2602.09593.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- HYPE ПРОГНОЗ. HYPE криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- Золото прогноз
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-11 22:56