Автор: Денис Аветисян
Исследование демонстрирует, как обучение представлений данных позволяет значительно улучшить поиск схожих облигаций и построение кривых спрэдов, особенно в условиях неполной информации.

Применение методов обучения представлений для категорических атрибутов облигаций превосходит традиционное one-hot кодирование и повышает эффективность анализа фиксированного дохода.
Поиск схожих облигаций представляет собой сложную задачу в анализе фиксированного дохода, поскольку количественные финансовые показатели часто затмевают категориальные нефинансовые характеристики, такие как отрасль эмитента и местонахождение. В данной работе, ‘Financial Bond Similarity Search Using Representation Learning’, показано, что именно категориальные атрибуты оказывают определяющее влияние на предсказуемость кривых спредов, и предложены модели встраивания для улавливания их семантической схожести, превосходящие традиционные методы one-hot кодирования. Подход, протестированный с использованием аугментации разреженных данных, позволяет улучшить моделирование рисков и построение кривых. Способны ли эти модели обеспечить более точную оценку и управление портфелем облигаций в условиях недостатка данных?
Тайны Рынка Облигаций: От Ручного Труда к Автоматизации
Традиционный анализ рынков фиксированного дохода исторически опирался на ручной сбор и обработку данных, а также на экспертные оценки, что неизбежно замедляло процесс и требовало значительных финансовых затрат. Такой подход, хотя и позволял учитывать нюансы, оказался недостаточно эффективным в условиях растущих объемов торгов и усложняющихся финансовых инструментов. В результате, принятие решений часто задерживалось, а оценка рисков оказывалась менее точной, что негативно сказывалось на доходности инвестиций и увеличивало операционные издержки. Необходимость в автоматизации и использовании современных технологий анализа данных стала очевидной для повышения эффективности и конкурентоспособности на рынке.
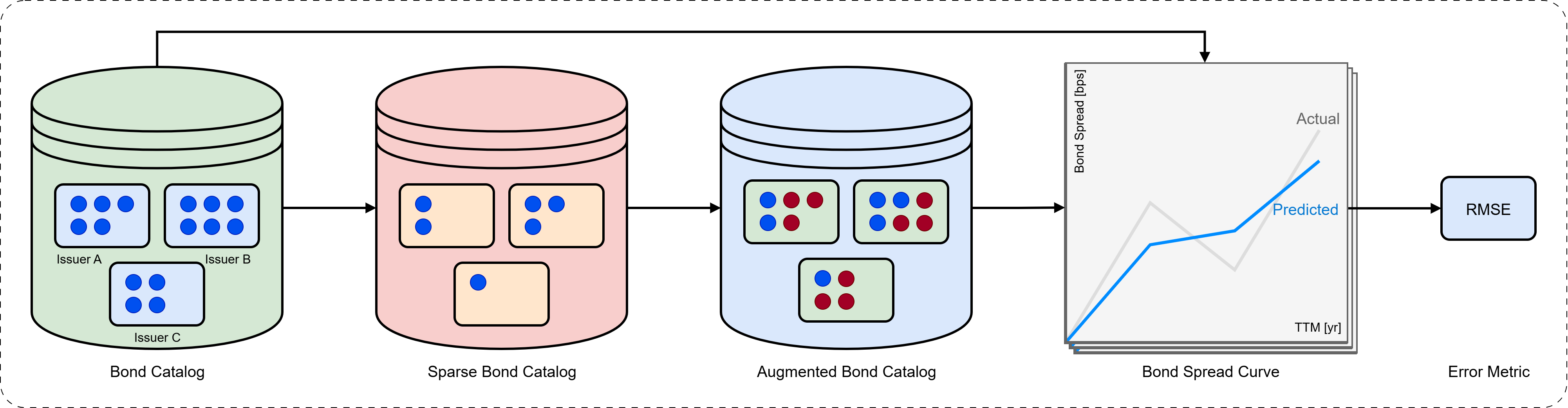
Анализ облигаций эмитентов с неполными каталогами данных представляет собой серьезную проблему для традиционных методов построения кривых доходности. В ситуациях, когда информация о конкретном эмитенте ограничена — например, отсутствуют данные по всем выпускам облигаций или истории торгов — стандартные алгоритмы экстраполяции и интерполяции становятся менее надежными. Это приводит к неточной оценке процентных ставок по различным срокам и, как следствие, к ошибочным решениям об инвестировании и управлении рисками. Исследователи активно разрабатывают новые подходы, использующие методы машинного обучения и статистического моделирования, для более эффективной работы с неполными данными и повышения точности оценки кривых доходности в условиях дефицита информации.
Точная оценка рисков на рынке облигаций требует глубокого понимания нюансов, характеризующих каждую облигацию, однако часто доступная информация оказывается неполной или искаженной. Даже незначительные различия в условиях выпуска, кредитном рейтинге эмитента или сроке погашения могут существенно влиять на итоговую доходность и подверженность риску. Исследования показывают, что традиционные методы анализа, опирающиеся на усредненные показатели, зачастую не способны выявить эти тонкие различия, приводя к недооценке или переоценке реальных рисков. Поэтому, для формирования надежной стратегии инвестирования в облигации, необходимо применять продвинутые методы анализа данных, позволяющие извлекать максимум информации даже из ограниченных источников и учитывать мельчайшие детали, влияющие на стоимость и риски конкретных инструментов.
Обучение Представлений: Автоматизация Анализа Облигаций
Обучение представлений (Representation Learning) представляет собой эффективный подход к автоматическому выявлению значимых признаков из данных об облигациях, обходя ограничения, присущие ручному анализу. Традиционные методы требуют экспертных знаний для определения и кодирования релевантных характеристик, что является трудоемким и субъективным процессом. Обучение представлений, напротив, позволяет алгоритмам самостоятельно извлекать полезные признаки непосредственно из исходных данных, обнаруживая сложные зависимости и паттерны, которые могут быть упущены при ручном анализе. Это особенно полезно при работе с большими объемами данных и высокоразмерными признаками, где ручной анализ становится практически невозможным. Автоматическое извлечение признаков повышает эффективность анализа и позволяет создавать более точные и надежные модели оценки и прогнозирования.
Модели внедрения (embedding models) позволяют преобразовать сложные характеристики химических связей, включая признаки, представленные переменными с высокой кардинальностью (например, типы атомов, функциональные группы), в непрерывное векторное пространство. В отличие от традиционных методов кодирования категориальных признаков, таких как one-hot encoding, модели внедрения генерируют плотные векторные представления, отражающие семантические отношения между различными категориями. Это достигается путем обучения модели на большом наборе данных связей, в результате чего схожие связи получают близкие векторы в многомерном пространстве. Такое представление позволяет применять математические операции, такие как вычисление косинусного сходства, для количественной оценки взаимосвязей между различными типами связей и выявления закономерностей в данных.
Применение косинусной близости (Cosine Similarity) к векторным представлениям химических связей позволяет количественно оценить степень их сходства на основе извлеченных характеристик. Косинусная близость измеряет косинус угла между двумя векторами, значения которого варьируются от -1 до 1, где 1 указывает на полную идентичность, 0 — на ортогональность (отсутствие корреляции), а -1 — на полную противоположность. Таким образом, чем ближе значение косинусной близости к 1, тем более похожими являются соответствующие химические связи, что позволяет выявлять закономерности и проводить сравнительный анализ на основе автоматически извлеченных признаков, без необходимости ручного определения критериев сходства.
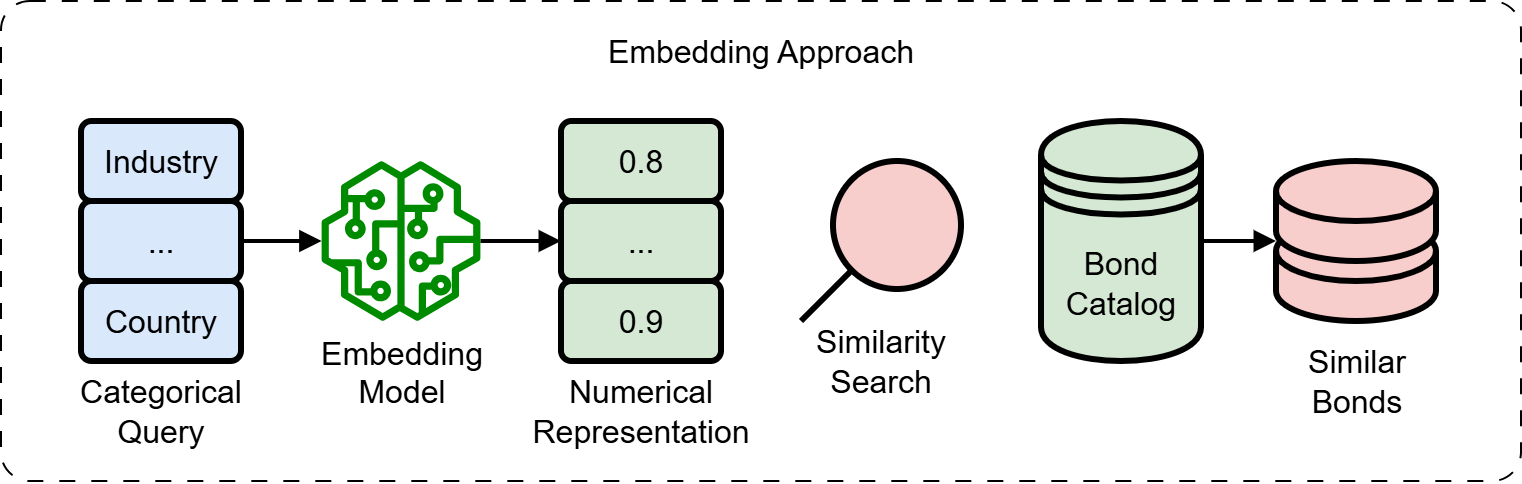
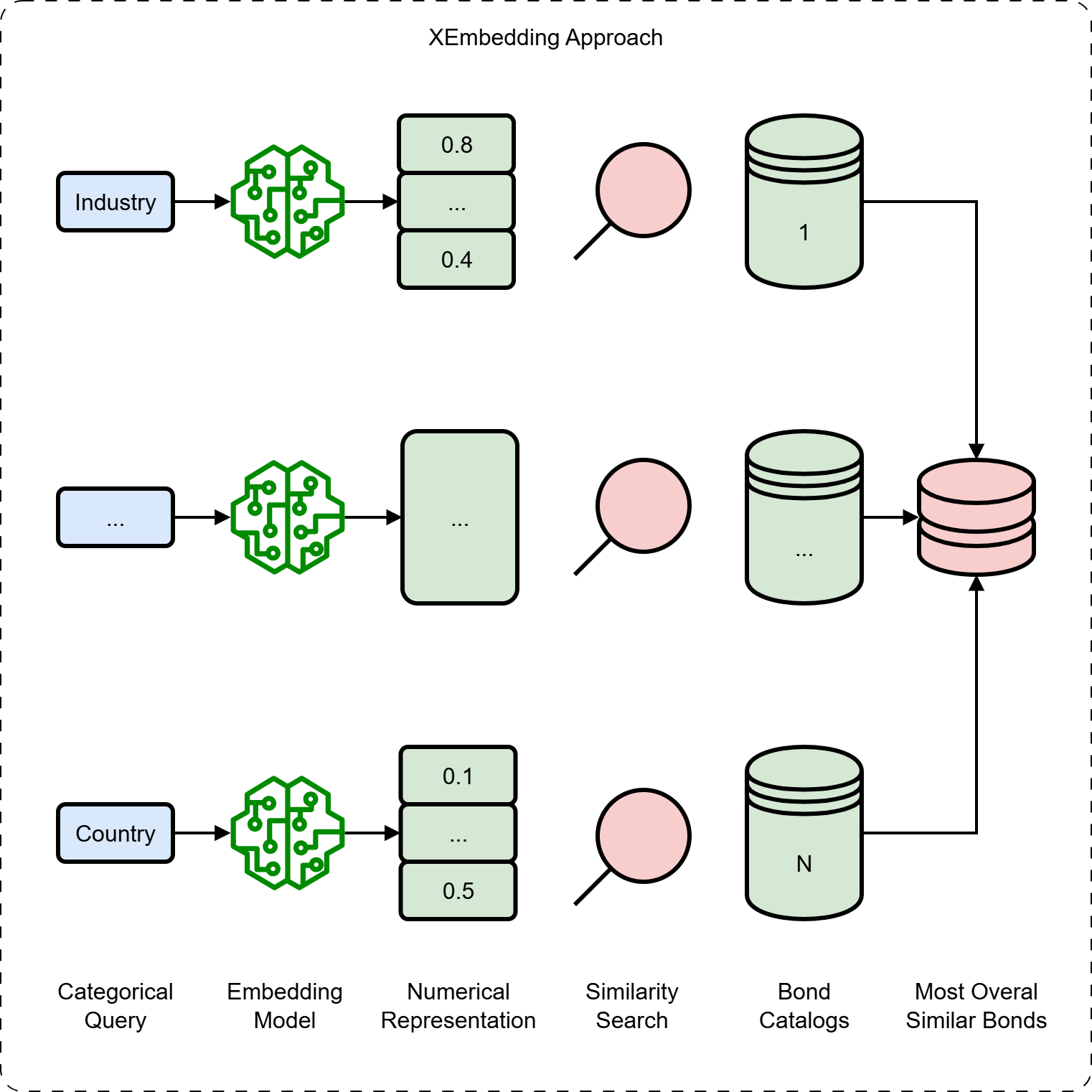
Поиск По Сходству: Раскрывая Скрытые Связи в Данных об Облигациях
Поиск по схожести позволяет выявлять облигации с сопоставимыми характеристиками, даже при наличии неполных данных. Это достигается путем анализа доступных параметров, таких как кредитный рейтинг, срок погашения, тип ставки и отраслевая принадлежность, и сопоставления их с другими облигациями в базе данных. Использование алгоритмов поиска ближайших соседей позволяет находить облигации, демонстрирующие аналогичные профили риска и доходности, что особенно ценно при оценке облигаций с ограниченной историей торгов или недостаточной информацией. В результате, аналитики получают возможность более точно оценивать риски, связанные с конкретной облигацией, и проводить сравнительный анализ с аналогичными инструментами, что способствует принятию обоснованных инвестиционных решений.
В основе возможности поиска схожих облигаций лежит обучение метрике расстояний (Distance Metric Learning), представляющее собой метод машинного обучения, направленный на оптимизацию пространства вложений (embedding space). Вместо использования стандартных метрик, таких как евклидово расстояние, обучение метрике расстояний позволяет создать кастомную метрику, которая наилучшим образом отражает семантические отношения между облигациями. Это достигается путем минимизации расстояния между схожими облигациями и максимизации расстояния между различными. В результате формируется пространство вложений, где близость облигаций коррелирует с их финансовыми характеристиками и риском, что повышает точность и релевантность результатов поиска.
Применение поиска по схожести значительно повышает эффективность извлечения релевантных облигаций, предоставляя аналитикам более полную картину рынка. Традиционные методы поиска часто не позволяют выявить облигации, обладающие схожими характеристиками, но не совпадающие по всем критериям. Новый подход позволяет находить облигации, близкие по параметрам риска, доходности, отраслевой принадлежности и другим ключевым показателям, даже при неполноте данных. Это расширяет возможности анализа, позволяя учитывать более широкий спектр доступных инструментов и формировать более обоснованные инвестиционные решения. Улучшенное извлечение информации сокращает время, затрачиваемое на поиск и анализ, и повышает точность оценки рисков и возможностей на рынке облигаций.
Подтверждение Эффективности: Анализ Результатов и Метрики
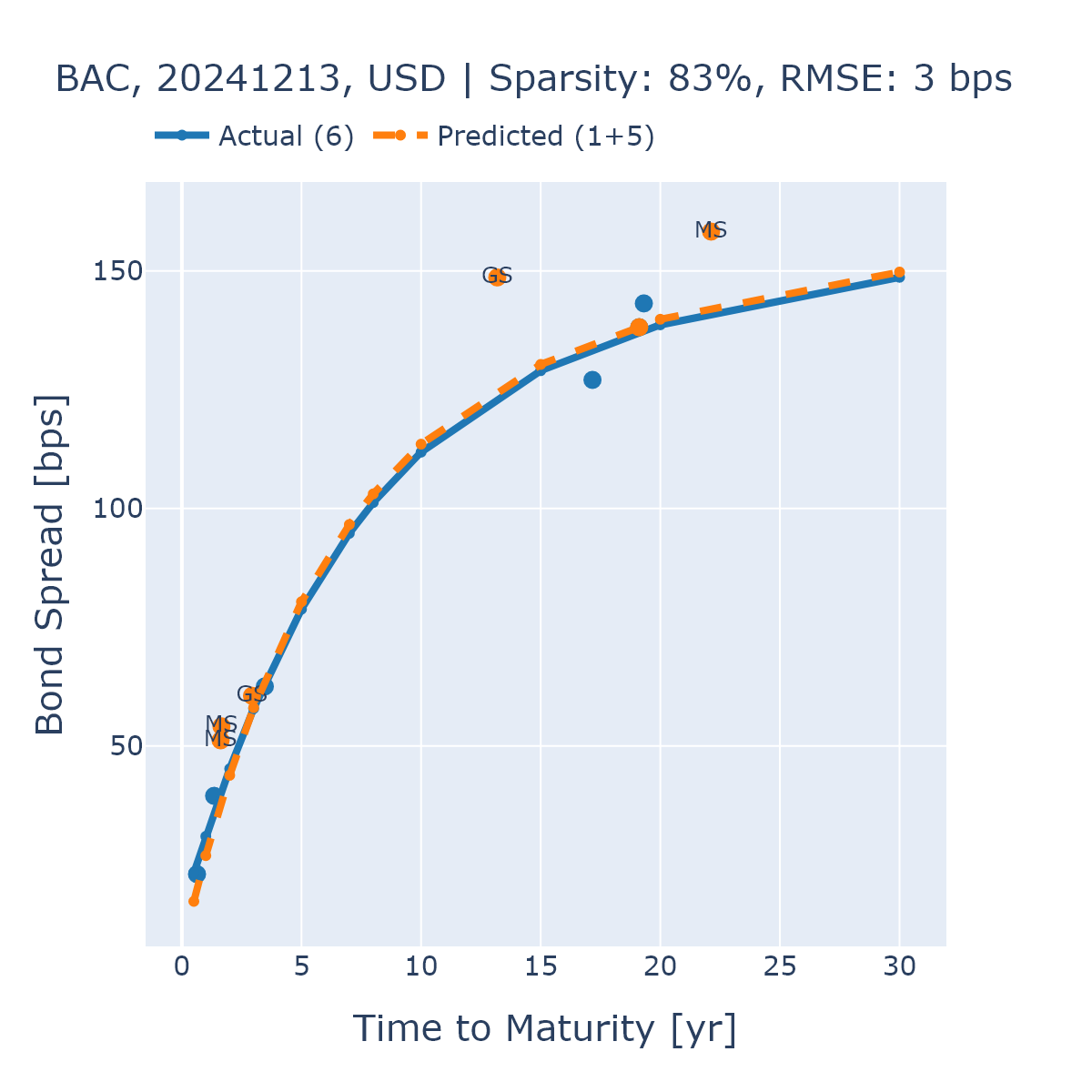
Для валидации точности разработанного подхода используется модель Нельсона-Сигеля для оценки кривой доходности и последующего сопоставления ее прогнозов с фактическими значениями. Модель Нельсона-Сигеля позволяет аппроксимировать кривую доходности с использованием ограниченного числа параметров, что делает ее удобным инструментом для оценки качества прогнозов. Сравнение прогнозируемых значений доходности с наблюдаемыми данными позволяет количественно оценить точность модели и выявить потенциальные отклонения, что необходимо для обеспечения надежности и корректности анализа облигаций.
Среднеквадратичная ошибка (RMSE) является количественной метрикой, используемой для оценки разницы между прогнозируемыми и фактическими доходностями облигаций. В рамках данной разработки, модель демонстрирует производительность, достигая значения RMSE в 18 базисных пунктов (bps). Это указывает на то, что в среднем, прогнозируемые доходности отклоняются от фактических значений на 0.18%, что позволяет оценить точность и надежность предложенного подхода к анализу рынка облигаций. Низкое значение RMSE свидетельствует о высокой степени соответствия между прогнозами модели и наблюдаемыми рыночными данными.
Валидация показала, что применение обучения представлений и поиска по схожести значительно повышает точность и эффективность анализа облигаций, особенно в условиях ограниченности данных. Для эмитентов KOREA и WFC была достигнута среднеквадратическая ошибка (RMSE) в размере 6 базисных пунктов (bps), что существенно ниже, чем 60 bps, полученных при использовании метода one-hot кодирования. Данный результат демонстрирует способность предложенного подхода к более точной экстраполяции и прогнозированию характеристик облигаций при недостатке исходной информации, что подтверждает его практическую ценность.
Взгляд в Будущее: Интеграция Фундаментальных Моделей Искусственного Интеллекта
Использование фундаментальных моделей искусственного интеллекта, таких как большие языковые модели, открывает перспективные возможности для углубленного анализа облигаций. Эти модели, обученные на огромных объемах данных, способны выявлять сложные взаимосвязи между характеристиками облигаций и рыночными условиями, которые могут быть упущены традиционными методами анализа. Способность этих моделей к обобщению и адаптации позволяет им не только прогнозировать ценовые движения, но и оценивать риски, связанные с конкретными эмитентами и секторами. Подобный подход позволяет автоматизировать процесс анализа и повысить его точность, что, в свою очередь, способствует принятию более обоснованных инвестиционных решений и оптимизации портфеля.
Современные модели искусственного интеллекта, известные как фундаментальные модели, обладают уникальной способностью выявлять сложные взаимосвязи между характеристиками облигаций и текущими рыночными условиями. Адаптация этих моделей позволяет учитывать нелинейные зависимости и скрытые факторы, которые традиционные методы анализа часто упускают из виду. В результате, повышается точность прогнозирования цен облигаций и оценки рисков, что особенно важно в условиях высокой волатильности рынка. Использование алгоритмов машинного обучения для анализа огромных массивов данных, включающих исторические цены, макроэкономические показатели и новости, позволяет выявлять закономерности и тенденции, недоступные для человеческого анализа, что в конечном итоге ведет к более эффективным инвестиционным стратегиям.
Автоматизация и оптимизация анализа облигаций представляет собой важный прорыв в сфере инвестиций с фиксированным доходом. Использование передовых алгоритмов позволяет существенно сократить время, затрачиваемое на обработку больших объемов данных и выявление ключевых факторов, влияющих на стоимость облигаций. В результате, появляется возможность принимать более обоснованные и оперативные инвестиционные решения, снижая риски и повышая потенциальную доходность. Данный подход не только улучшает эффективность работы профессиональных аналитиков, но и открывает новые возможности для широкого круга инвесторов, стремящихся к осознанному управлению своими активами. Внедрение подобных систем анализа способствует повышению прозрачности рынка и формированию более эффективного ценообразования на инструменты с фиксированным доходом.

Статья демонстрирует, что обучение представлений, или, проще говоря, «заклинание сжатия» информации о облигациях, позволяет находить схожие инструменты даже в условиях скудных данных. Это напоминает о том, как часто мы ищем порядок там, где его нет, и как легко «научить» модель выдавать желаемый результат. Ричард Фейнман однажды сказал: «Самый точный способ узнать, что вы знаете, — это попробовать объяснить это кому-нибудь другому». В данном случае, модель «объясняет» схожесть облигаций через векторные представления, но истинное понимание кроется в умении интерпретировать эти векторы и признать, что любое представление — лишь упрощение реальности, а не сама реальность. Использование косинусного сходства — лишь один из способов «уговорить» хаос данных, чтобы он хоть немного прислушался к нашим запросам.
Что дальше?
Работа с представлениями облигаций — это не поиск совершенной метрики сходства, а попытка уловить эхо скрытых связей в шуме финансовых рынков. Полученные в данной работе эмбеддинги — лишь карта, на которой ещё предстоит нанести границы хаоса. Особенно остро встаёт вопрос о динамике: как эти представления меняются во времени, отражая сдвиги в восприятии риска и ликвидности? Попытки «зафиксировать» облигацию в статичном векторе — наивны. Мир не дискретен, просто у нас нет памяти для float.
Особое внимание следует уделить обработке разреженных данных. Простое увеличение размерности эмбеддингов — это не решение, а откладывание проблемы. Необходимо искать методы, способные извлекать информацию из фрагментарных наблюдений, возможно, заимствуя идеи из теории информации и стохастических процессов. Корреляция — это мираж, а смысл кроется в понимании того, как облигации взаимодействуют друг с другом, формируя сложные, самоорганизующиеся структуры.
В конечном итоге, задача состоит не в том, чтобы построить идеальную модель, а в том, чтобы создать инструмент, способный адаптироваться к непредсказуемости рынков. Каждое развертывание в продакшене — это новый эксперимент, и каждое отклонение от ожидаемого результата — это не ошибка, а возможность учиться. Данные — это не цифры, а шёпот хаоса, и к ним нужно прислушиваться.
Оригинал статьи: https://arxiv.org/pdf/2602.07020.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-10 20:00