Автор: Денис Аветисян
Новое исследование показывает, что технологии создания реалистичных подделок опережают развитие методов их обнаружения, создавая серьезные риски для цифровой безопасности.
![В ходе исследования были получены высокореалистичные видео-дипфейки, демонстрирующие возможности различных методов синтеза, включая AniFaceDiff[4], FaceFusion[9], FaceVid[30], FADM[33], HyperReenact[2], Synctalk[20], TPSMM[34] и VASA-1[31].](https://arxiv.org/html/2602.07986v1/images/synthesis-methods-v1.png)
Анализ последних достижений в области генеративных состязательных сетей, диффузионных моделей и нейронных полей, демонстрирует растущий разрыв между синтезом и выявлением дипфейков.
Несмотря на значительные успехи в разработке методов обнаружения, технологии синтеза дипфейков демонстрируют опережающий рост реалистичности и доступности. В работе «Deepfake Synthesis vs. Detection: An Uneven Contest» проведено всестороннее эмпирическое исследование современных методов обнаружения, включая оценку человеком, в противостоянии с передовыми методами синтеза. Полученные результаты указывают на тревожную тенденцию: многие из наиболее эффективных моделей обнаружения показывают неудовлетворительную производительность при проверке на дипфейках, созданных с помощью современных технологий, включая и результаты оценки людьми. Необходимы ли более совершенные и адаптивные системы обнаружения, чтобы не отставать от быстро развивающихся возможностей генерации дипфейков и обеспечить надежную защиту от дезинформации?
Глубокие Подделки: Эволюция Реализма и Вызовы Достоверности
Технология дипфейков, использующая такие методы, как генеративно-состязательные сети (GAN), переживает стремительное развитие, создавая синтетические видеоролики, поражающие своей реалистичностью. Изначально ограниченные примитивными визуальными эффектами, дипфейки сегодня способны имитировать внешность, мимику и даже голос конкретных людей с беспрецедентной точностью. Этот прогресс обусловлен совершенствованием архитектур GAN, увеличением вычислительных мощностей и доступностью больших объемов данных для обучения нейронных сетей. В результате, отличить подлинное видео от искусно созданной подделки становится все сложнее, что порождает серьезные вопросы о достоверности цифрового контента и необходимости разработки эффективных методов обнаружения и аутентификации.
Появление технологий создания дипфейков ставит под сомнение подлинность цифрового контента и порождает серьезные вызовы для установления доверия к нему. В эпоху, когда видео- и аудиоматериалы становятся все более распространенным источником информации, способность достоверно определять их подлинность приобретает критическое значение. Необходимость разработки надежных методов обнаружения дипфейков обусловлена риском дезинформации, манипулирования общественным мнением и нанесения ущерба репутации. Современные исследования направлены на создание алгоритмов, способных выявлять даже самые реалистичные подделки, что требует постоянного совершенствования технологий и адаптации к новым методам создания синтетического контента. Успешное решение этой задачи позволит сохранить целостность информационного пространства и укрепить доверие к цифровым медиа.
Первые попытки обнаружения дипфейков, такие как методы TPSMM и FaceVid, заложили основу для дальнейших исследований, однако их возможности оказались недостаточными для распознавания современных, высокореалистичных подделок. В отличие от автоматизированных систем, которые сталкиваются с трудностями в оценке тонких манипуляций с изображением, человеческие эксперты демонстрируют впечатляющую точность — средний показатель AUC составляет 93.10, а AP — 94.81. Это свидетельствует о значительном превосходстве человеческого восприятия в выявлении дипфейков и подчеркивает необходимость разработки более совершенных алгоритмов, способных приблизиться к уровню эффективности, достижимому человеком в данной области.
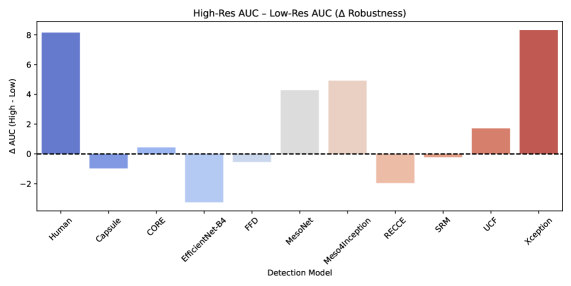
![Анализ результатов показал, что модели Xception[22] и CORE[18] демонстрируют наивысшую точность обнаружения дипфейков, особенно при работе с полным видео, в то время как человеческая оценка улучшается с повышением разрешения, что не характерно для большинства автоматизированных моделей, при этом MesoNet[1] и Meso4Inception[1] чувствительны к изменениям разрешения, а RECCE[3] и UCF[32] сохраняют стабильность при различных условиях.](https://arxiv.org/html/2602.07986v1/x5.png)
Диффузионные Модели: Новый Стандарт Генерации Глубоких Подделок
Диффузионные модели, такие как AniFaceDiff, DreamTalk и DiffusedHeads, в настоящее время являются передовыми технологиями в области создания дипфейков, демонстрируя значительное повышение реалистичности за счет итеративного процесса уточнения. В отличие от традиционных генеративных состязательных сетей (GAN), диффузионные модели начинают с добавления шума к обучающим данным, а затем обучаются обращать этот процесс, постепенно восстанавливая изображение из шума. Этот подход позволяет генерировать более детализированные и правдоподобные изображения, поскольку модель учится представлять сложное распределение данных. Итеративный характер процесса уточнения позволяет модели постепенно улучшать качество генерируемого контента на каждом шаге, что приводит к более реалистичным результатам.
Методы, такие как SyncTalk, активно используют Neural Radiance Fields (NeRF) для повышения 3D-согласованности и синхронизации губ в генерируемом контенте. NeRF представляют собой нейронные сети, обучающиеся представлять сцену как непрерывную функцию, что позволяет создавать более реалистичные и стабильные 3D-модели. В контексте deepfake, это позволяет точно воспроизводить геометрию лица и мимику, обеспечивая более убедительную синхронизацию движений губ с речью. Использование NeRF снижает артефакты и обеспечивает более высокую степень реализма по сравнению с традиционными методами, основанными на 2D-изображениях.
Модели VASA и FADM демонстрируют возможности диффузионных моделей в генерации высококачественного синтетического контента с управлением атрибутами и реалистичной мимикой. В частности, модель AniFaceDiff достигает показателей FID 6.02 и FVD 15.55, что свидетельствует о статистической близости сгенерированных образцов к реальным данным. Для сравнения, показатели для модели HyperReenact/GAN составляют FID 9.95 и FVD 19.10, что указывает на превосходство AniFaceDiff в плане реалистичности и качества генерируемого контента.
Выявление Невидимого: Продвинутые Подходы к Обнаружению Глубоких Подделок
Современные методы обнаружения дипфейков сталкиваются со значительными трудностями из-за постоянно растущего реализма генерируемого контента. Традиционные подходы, основанные на анализе отдельных пикселей или статистических аномалий изображения, становятся все менее эффективными по мере совершенствования алгоритмов генерации. Повышение качества синтетических изображений и видео требует перехода к методам, анализирующим более сложные характеристики, такие как физические несоответствия, нереалистичные движения, а также несогласованности в освещении и тенях. Необходимость анализа высокоуровневых признаков диктует использование архитектур глубокого обучения, способных выявлять тонкие артефакты и паттерны, невидимые для человеческого глаза и недоступные для простых алгоритмов обработки изображений.
Архитектуры MesoNet, XceptionNet и EfficientNet используют сверточные нейронные сети (CNN) для эффективного извлечения признаков из видео- и изобразительного контента. Эти сети оптимизированы для снижения вычислительной сложности и повышения скорости обработки, сохраняя при этом высокую точность обнаружения манипуляций. В отличие от традиционных CNN, Capsule Networks стремятся моделировать иерархические пространственные отношения между объектами на изображении, что позволяет им лучше понимать структуру сцены и более надежно идентифицировать несоответствия, характерные для дипфейков. Особенностью Capsule Networks является использование «капсул» — групп нейронов, представляющих объекты и их свойства, а также векторов, кодирующих положение и ориентацию этих объектов.
Контрастное обучение (Contrastive Learning) в моделях обнаружения дипфейков позволяет различать реальный и сгенерированный контент посредством изучения дискриминативных признаков. Суть метода заключается в обучении модели сближать представления (embeddings) реальных и других реальных изображений, одновременно отдаляя представления реальных изображений от сгенерированных. Это достигается за счет использования функций потерь, которые минимизируют расстояние между представлениями схожих образцов и максимизируют расстояние между несхожими. В результате модель учится выделять наиболее информативные признаки, позволяющие эффективно классифицировать контент как настоящий или поддельный, даже при наличии незначительных изменений или искажений.
Методы UCF и CoRe используют такие продвинутые техники, как разделение признаков (disentanglement) и обеспечение согласованности представлений (representation consistency), направленные на повышение обобщающей способности и устойчивости моделей обнаружения дипфейков. Однако, несмотря на эти усовершенствования, лучшая автоматизированная модель (FFD) в настоящее время демонстрирует AUC (Area Under the Curve) всего 69.38%, что значительно ниже, чем показатели, достигаемые человеком-экспертом (AUC 93.10%). Данный разрыв указывает на продолжающиеся трудности в автоматическом обнаружении дипфейков, особенно в сценариях, требующих высокой точности и надежности.
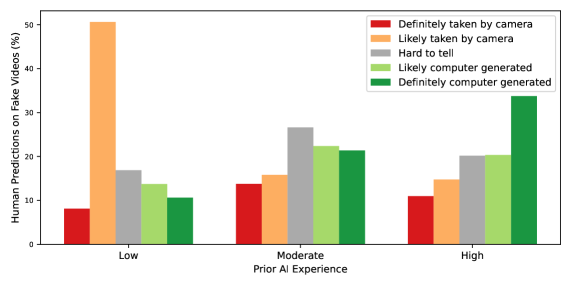
За Пределами Восприятия: Оценка и Совершенствование Технологий Глубоких Подделок
Оценка реалистичности контента, созданного с помощью технологий глубоких подделок, часто осуществляется посредством количественных метрик, таких как расстояние Фреше (Fréchet Inception Distance) и расстояние Фреше для видео (Fréchet Video Distance). Эти показатели позволяют численно оценить степень сходства между сгенерированными изображениями или видео и реальными данными. Расстояние Фреше, по сути, измеряет разницу в статистических характеристиках двух наборов данных, где меньшее значение указывает на более высокую степень реализма и визуального соответствия сгенерированного контента. Применение подобных метрик необходимо для объективной оценки прогресса в области генерации и обнаружения дипфейков, а также для сравнения эффективности различных алгоритмов и моделей.
Инструмент FaceFusion демонстрирует впечатляющую практическую реализацию технологии дипфейков, позволяя в реальном времени заменять лица на видео и изображениях. Данное программное обеспечение, доступное для широкого круга пользователей, открывает возможности для создания персонализированного контента, развлечений и даже виртуальных аватаров. В отличие от более сложных систем, требующих значительных вычислительных ресурсов и специализированных знаний, FaceFusion позволяет создавать дипфейки непосредственно на потребительском оборудовании, что подчеркивает растущую доступность и потенциальное влияние данной технологии на различные сферы жизни. Простота использования и скорость обработки делают его мощным инструментом для демонстрации возможностей дипфейков и одновременно поднимают вопросы об этических аспектах и необходимости разработки методов обнаружения.
Современные исследования в области создания и обнаружения дипфейков направлены на преодоление существующих ограничений, касающихся реалистичности выражений, сохранения идентичности и устойчивости к целенаправленным атакам. Особое внимание уделяется контенту, сгенерированному с использованием диффузионных моделей, который демонстрирует значительное снижение вероятности ошибки при обнаружении — на 39.5% для изображений и на 18.6% для видео — по сравнению с контентом, созданным с помощью генеративно-состязательных сетей (GAN). Этот факт указывает на то, что диффузионные модели генерируют более правдоподобные и сложные дипфейки, которые представляют собой более серьезную проблему для существующих систем обнаружения и требуют разработки новых, более совершенных алгоритмов анализа.
Для эффективного противодействия рискам, связанным с дипфейками, требуется комплексный подход, выходящий за рамки исключительно технических решений. Помимо разработки усовершенствованных методов обнаружения и создания более устойчивых к подделке систем, необходимы инициативы по повышению медиаграмотности населения. Важно, чтобы люди умели критически оценивать информацию, распознавать манипуляции и понимать принципы работы технологий создания дипфейков. Параллельно с этим, требуется разработка этических руководств и правовых норм, регулирующих создание и распространение дипфейков, особенно в контексте дезинформации, клеветы и нарушения приватности. Такой многогранный подход позволит не только снизить техническую уязвимость к дипфейкам, но и сформировать у общества устойчивость к их негативному воздействию.
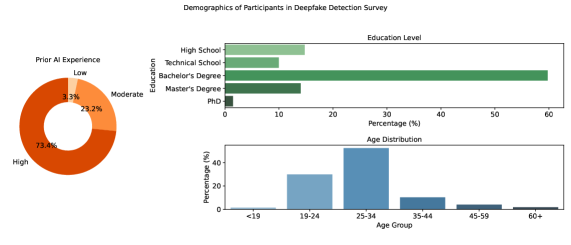
Исследование, посвященное синтезу и обнаружению дипфейков, отчетливо демонстрирует растущий разрыв между возможностями генеративных моделей и эффективностью существующих методов верификации. В частности, развитие диффузионных моделей и нейронных радиальных полей значительно опережает прогресс в области обнаружения, создавая серьезные вызовы для цифровой криминалистики. Как заметил Ян Лекун: «Машинное обучение — это программирование, но вместо того, чтобы писать правила, вы даете данные и позволяете машине учиться». Данное утверждение особенно актуально в контексте дипфейков, где сложность и реалистичность генерируемых изображений и видео требуют принципиально новых подходов к обнаружению, основанных на глубоком понимании структуры данных и математической строгости алгоритмов.
Куда ведет нас эта гонка?
Представленное исследование выявляет тревожную тенденцию: развитие методов генерации дипфейков опережает возможности их обнаружения. Пусть N стремится к бесконечности — что останется устойчивым? Нынешние детекторы, основанные на статистическом анализе артефактов, кажутся хрупкими перед лицом все более изощренных генеративных моделей — будь то GAN, диффузионные модели или нейронные поля излучения. Полагаться исключительно на «видимые» недостатки — значит строить защиту из песка перед надвигающимся штормом.
Основная проблема заключается не в улучшении существующих детекторов, а в изменении парадигмы. Необходимо отойти от поиска «отпечатков пальцев» генеративной модели и сосредоточиться на фундаментальных несоответствиях между синтетическим и реальным. Иными словами, вместо того чтобы пытаться определить, как был создан дипфейк, следует стремиться установить, мог ли он быть создан в принципе, учитывая физические ограничения и законы восприятия.
Будущие исследования должны быть направлены на разработку детекторов, устойчивых к adversarial атакам и способных адаптироваться к новым генеративным моделям без переобучения. Не менее важна разработка метрик, позволяющих оценивать не только точность обнаружения, но и степень уверенности в этом обнаружении. В конечном счете, вопрос заключается не в том, сможем ли мы всегда обнаруживать дипфейки, а в том, как минимизировать ущерб от тех, которые остаются незамеченными.
Оригинал статьи: https://arxiv.org/pdf/2602.07986.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- MYX ПРОГНОЗ. MYX криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-10 11:34