Автор: Денис Аветисян
Новый подход позволяет создавать более понятные и устойчивые объяснения для моделей, работающих с графами, используя методы, вдохновленные атаками на эти самые модели.
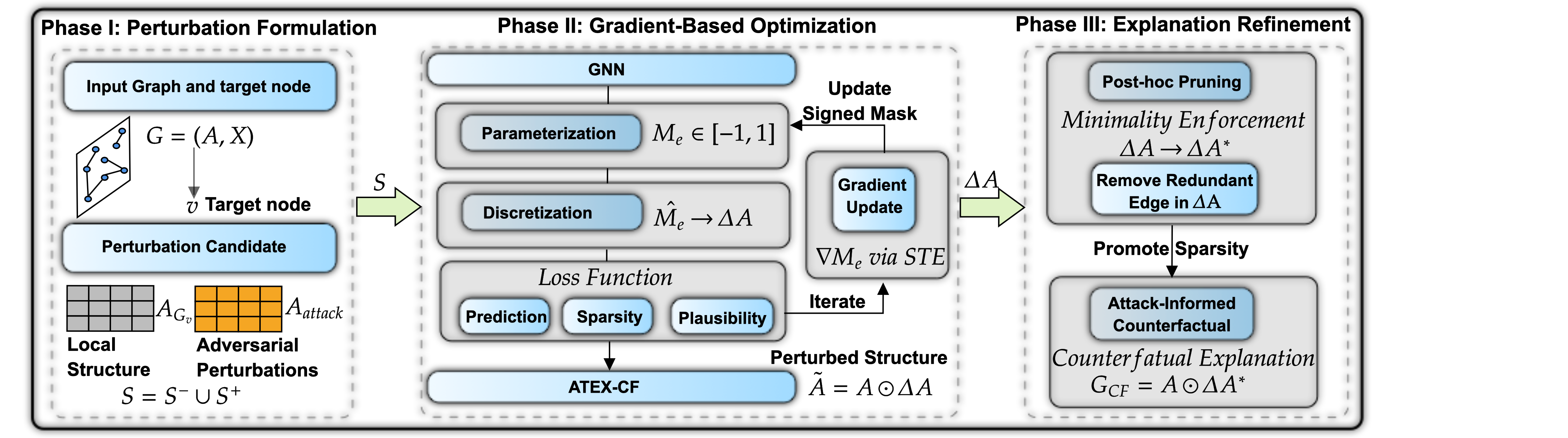
Предложена унифицированная структура ATEX-CF, использующая стратегии состязательных атак для улучшения интерпретируемости и надежности контрфактических объяснений графовых нейронных сетей.
Несмотря на растущую популярность графовых нейронных сетей (ГНС), интерпретация их решений остается сложной задачей. В данной работе представлена новая методика — ‘ATEX-CF: Attack-Informed Counterfactual Explanations for Graph Neural Networks’ — объединяющая принципы состязательных атак и генерации контрфактических объяснений для повышения прозрачности ГНС. Предложенный подход позволяет находить минимальные изменения в графе, необходимые для изменения предсказания модели, эффективно используя как добавление, так и удаление ребер. Может ли подобная интеграция методов повышения робастности и интерпретируемости стать ключом к более надежным и понятным графовым моделям?
Уязвимость графовых нейронных сетей: хрупкость элегантной теории
Графовые нейронные сети (ГНС) все активнее внедряются в решение задач, критичных к точности, таких как анализ социальных сетей, обнаружение мошенничества и прогнозирование в биологических системах. Однако, несмотря на впечатляющие результаты, устойчивость этих сетей к даже незначительным изменениям в структуре графа вызывает серьезную обеспокоенность. Небольшие возмущения, например, добавление или удаление нескольких ребер, могут приводить к существенному снижению производительности ГНС, ставя под вопрос их надежность в реальных приложениях, где данные часто бывают зашумленными или подвержены злонамеренным манипуляциям. Исследование этой уязвимости становится ключевым фактором для разработки более надежных и устойчивых систем машинного обучения, основанных на графах.
Исследования показывают, что даже незначительные изменения в структуре графа могут существенно снизить эффективность графовых нейронных сетей (ГНС). Атакующие могут намеренно вносить небольшие, но тщательно продуманные искажения в связи между узлами графа, вызывая значительные ошибки в предсказаниях ГНС. Это представляет серьезную проблему для применений в критически важных областях, таких как обнаружение мошенничества, рекомендательные системы и анализ социальных сетей, где надежность и точность имеют первостепенное значение. Уязвимость ГНС к подобным атакам ставит под вопрос их пригодность для использования в системах, где безопасность и стабильность являются ключевыми требованиями, и подчеркивает необходимость разработки более устойчивых и надежных архитектур ГНС.
Понимание уязвимостей графовых нейронных сетей имеет первостепенное значение для создания надежных и устойчивых систем машинного обучения, работающих с графами. Поскольку эти сети все шире применяются в критически важных областях, таких как анализ социальных сетей, обнаружение мошенничества и разработка лекарств, даже незначительные изменения в структуре графа могут привести к существенным ошибкам в их работе. Исследование этих уязвимостей позволяет разрабатывать методы защиты, повышающие робастность моделей к преднамеренным атакам и случайным возмущениям данных. Это, в свою очередь, способствует повышению доверия к графовым нейронным сетям и расширению области их практического применения, обеспечивая надежность и предсказуемость результатов в реальных условиях.
Контрфактические объяснения: выявление истинных причин
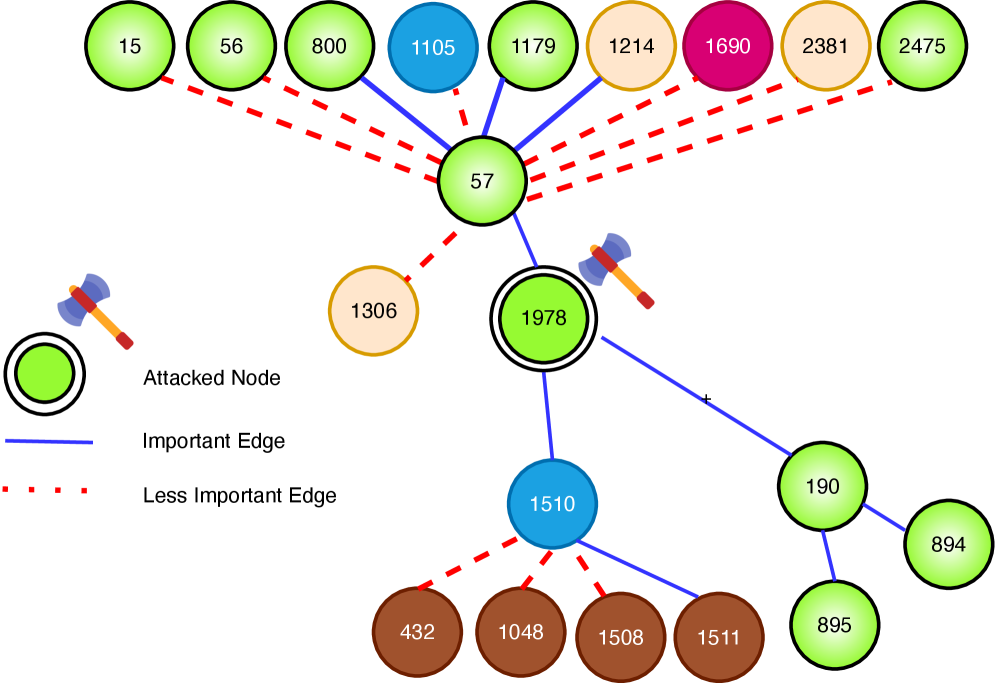
Контрфактические объяснения предоставляют возможность понять, почему графовая нейронная сеть (GNN) сделала конкретный прогноз, путем определения минимальных изменений во входном графе, которые бы изменили результат. В отличие от методов, определяющих важность признаков, контрфактические объяснения идентифицируют конкретные подструктуры и связи в графе, которые критически влияют на решение модели. Это достигается путем поиска наименьшего набора изменений — добавления или удаления ребер или узлов, или изменения атрибутов — которые приведут к желаемому изменению в прогнозе, тем самым раскрывая логику принятия решений GNN.
В отличие от методов, определяющих важность отдельных признаков, контрфактические объяснения выявляют критически важные подструктуры и связи в графе, которые непосредственно влияют на предсказание графовой нейронной сети (GNN). Вместо указания на наиболее значимые узлы или ребра, контрфактические объяснения демонстрируют, какие минимальные изменения в структуре графа (например, добавление или удаление связей, изменение атрибутов узлов) привели бы к иному результату. Такой подход позволяет понять, какие конкретные комбинации элементов графа являются решающими для принятия решения моделью, что дает более глубокое понимание логики работы GNN, чем простое определение важности признаков.
Эффективность контрфактических объяснений напрямую зависит от двух ключевых характеристик: разреженности и правдоподобности. Разреженность подразумевает минимальное количество изменений в исходном графе, необходимых для изменения предсказания модели; чем меньше модификаций требуется, тем более понятным и полезным является объяснение. Правдоподобность же означает, что эти изменения должны быть реалистичными и соответствовать структуре и особенностям анализируемого графа. Неправдоподобные или нереалистичные модификации, даже если они приводят к изменению предсказания, снижают доверие к объяснению и его практическую ценность. Обе эти характеристики критически важны для обеспечения интерпретируемости и надежности контрфактических объяснений в графовых нейронных сетях.
ATEX-CF: учёт семантики атак в объяснениях
ATEX-CF представляет собой новый фреймворк, который явно учитывает семантику атак при генерации контрфактических объяснений. В отличие от существующих методов, которые рассматривают изменения графа как чисто структурные, ATEX-CF анализирует, как атаки манипулируют графом для достижения определенного результата. Это позволяет фреймворку идентифицировать минимальные и наиболее релевантные изменения, необходимые для генерации объяснений, учитывая механизм воздействия атаки. Интеграция семантики атак в процесс генерации контрфактов обеспечивает более надежные и понятные объяснения, особенно в контексте, где модель подвержена целенаправленным атакам.
В основе ATEX-CF лежит анализ механизмов воздействия атак на графовые структуры. Вместо случайного поиска минимальных изменений для генерации объяснений, ATEX-CF учитывает, каким образом атаки модифицируют граф для достижения неправильной классификации. Это позволяет системе выявлять наиболее значимые узлы и связи, которые необходимо изменить для восстановления корректного результата, что приводит к созданию более релевантных и эффективных объяснений. Таким образом, ATEX-CF не просто идентифицирует минимальный набор изменений, а фокусируется на тех, которые напрямую связаны с механизмом атаки и наиболее вероятно приведут к исправлению ошибки.
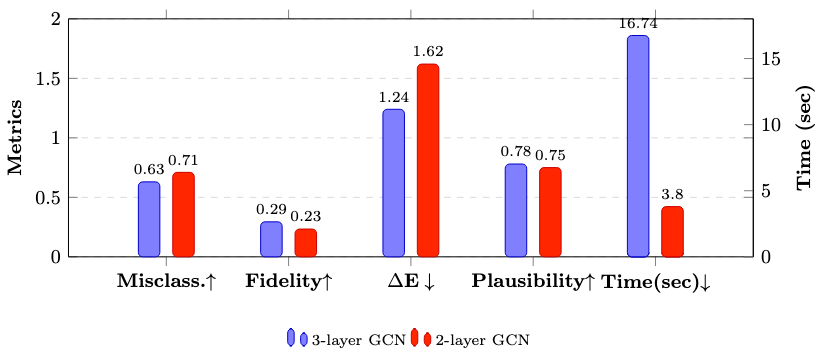
Внедрение ATEX-CF обеспечивает повышенную устойчивость и достоверность объяснений, особенно в условиях вероятных атак на модель. Экспериментальные результаты демонстрируют, что ATEX-CF достигает уровня ошибочной классификации в 0.83 на наборе данных BA-Shapes и 0.90 на ogbn-arxiv, превосходя показатели других методов в аналогичных сценариях. Данные результаты подтверждают эффективность подхода ATEX-CF в генерации объяснений, менее подверженных манипуляциям и более надежных в условиях враждебных атак.
В ходе экспериментов, фреймворк ATEX-CF продемонстрировал способность генерировать компактные объяснения, характеризующиеся средним размером изменений ΔE = 1.24. Это свидетельствует о минимальной необходимости вносить правки в граф для достижения желаемого изменения в предсказании. Более того, анализ схожести векторных представлений графа (GEV) для неправильно классифицированных узлов показал высокий уровень соответствия между изменениями, вносимыми атакующим, и объяснениями, предоставляемыми методом — коэффициент GEV составил 0.88. Данный результат подтверждает, что ATEX-CF не только предоставляет лаконичные объяснения, но и эффективно выявляет ключевые факторы, влияющие на решение модели, а также отражает уязвимость графа к целенаправленным изменениям.

Роль структуры графа и свойств модели
Успех генерации контрфактических объяснений тесно связан со структурой графа, в котором функционирует модель. Особенно важную роль играет феномен гомофилии — тенденция узлов быть связанными с другими узлами, имеющими схожие характеристики. Именно гомофилия определяет, какие изменения в графе будут восприняты как правдоподобные и эффективные для получения альтернативного результата. В графах с высокой гомофилией небольшие изменения в атрибутах узла, сохраняющие его принадлежность к определенной группе, будут более реалистичными и понятными, чем радикальные преобразования, нарушающие структуру сообщества. Понимание этого влияния позволяет создавать контрфактические объяснения, которые не только демонстрируют, как изменить входные данные для получения иного прогноза, но и делают это в рамках правдоподобного сценария, учитывающего особенности взаимосвязей в графе.
Свойства самой графовой нейронной сети (GNN) оказывают значительное влияние на её восприимчивость к изменениям входных данных. В частности, разница между уверенностью модели в правильном классе и уверенностью в конкурирующих классах — так называемый «отступ» — определяет, насколько незначительные модификации графа способны изменить предсказание. Более широкий отступ указывает на большую устойчивость модели, в то время как узкий отступ делает её более уязвимой к небольшим возмущениям. Кроме того, свойство, известное как липшицева непрерывность функций GNN, характеризует гладкость изменений в выходных данных при изменениях входных данных. Высокая липшицева непрерывность означает, что даже при значительных изменениях во входном графе, предсказания модели будут изменяться умеренно, что обеспечивает более стабильные и предсказуемые объяснения. Понимание этих характеристик GNN позволяет разрабатывать более эффективные методы генерации контрфактических объяснений, учитывающие внутреннюю чувствительность модели к возмущениям.
Понимание взаимосвязи между структурой графа, свойствами графовых нейронных сетей и эффективностью контрфактических объяснений открывает путь к разработке более целенаправленных и устойчивых методов интерпретации. Анализ этих взаимодействий позволяет учитывать особенности конкретного типа графа — например, влияние гомофилии на правдоподобность изменений — и архитектурные характеристики модели, такие как чувствительность к возмущениям. Такой подход позволяет создавать объяснения, которые не только точно отражают причины предсказаний, но и учитывают внутренние механизмы работы модели, обеспечивая более надежную и понятную интерпретацию результатов, особенно в критически важных приложениях, где требуется высокая степень доверия к принимаемым решениям.
Исследование демонстрирует, как попытки взломать систему, в данном случае, графовые нейронные сети, приводят к неожиданным улучшениям в её объяснимости. Авторы предлагают использовать стратегии, изначально предназначенные для проведения атак, для генерации более качественных и понятных объяснений. Это напоминает старый принцип: чтобы понять слабое место крепости, нужно попытаться её взять. Марвин Минский однажды заметил: «Наиболее эффективный способ научиться — это делать». В контексте графовых сетей, это означает, что постоянные попытки «взломать» модель, путем добавления или удаления ребер, помогают лучше понять, как она работает и как её можно улучшить. В итоге, всё сводится к тому, что стабильная работа системы — это иллюзия, а последовательные сбои — закономерность, которую можно использовать во благо.
Что дальше?
Представленный подход, использующий стратегии adversarial атак для генерации counterfactual объяснений в графовых нейронных сетях, лишь временно отодвигает проблему интерпретируемости. В конечном итоге, каждая «оптимизированная» минимальная модификация графа неизбежно станет точкой отказа при следующем, более изощрённом воздействии. Рассуждения о «более эффективных» объяснениях — это иллюзия контроля над системами, чья сложность превосходит возможности человеческого понимания.
Очевидно, что акцент на добавлении рёбер, наряду с их удалением, является шагом в сторону более реалистичных counterfactual сценариев. Однако, вопрос о том, насколько эти сценарии действительно «объясняют» поведение сети, остаётся открытым. Скорее, это лишь ещё один способ перефразировать вопрос: «Что сломало эту сеть?» — вместо того, чтобы понять, почему она вообще работает.
Вместо погони за «идеальными» объяснениями, возможно, стоит сосредоточиться на разработке систем, способных диагностировать собственные ошибки и адаптироваться к непредсказуемым воздействиям. Не нужно больше микросервисов — нам нужно меньше иллюзий. В конечном счёте, графовая нейронная сеть, как и любая другая сложная система, рано или поздно превратится в анекдот, который никто не сможет объяснить.
Оригинал статьи: https://arxiv.org/pdf/2602.06240.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- ZEC ПРОГНОЗ. ZEC криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-09 18:33