Автор: Денис Аветисян
Новый подход, основанный на многоагентном обучении с подкреплением и алгоритме Monte Carlo Tree Search, значительно упрощает и удешевляет процесс сбора данных для обучения агентов автоматизации графических интерфейсов.
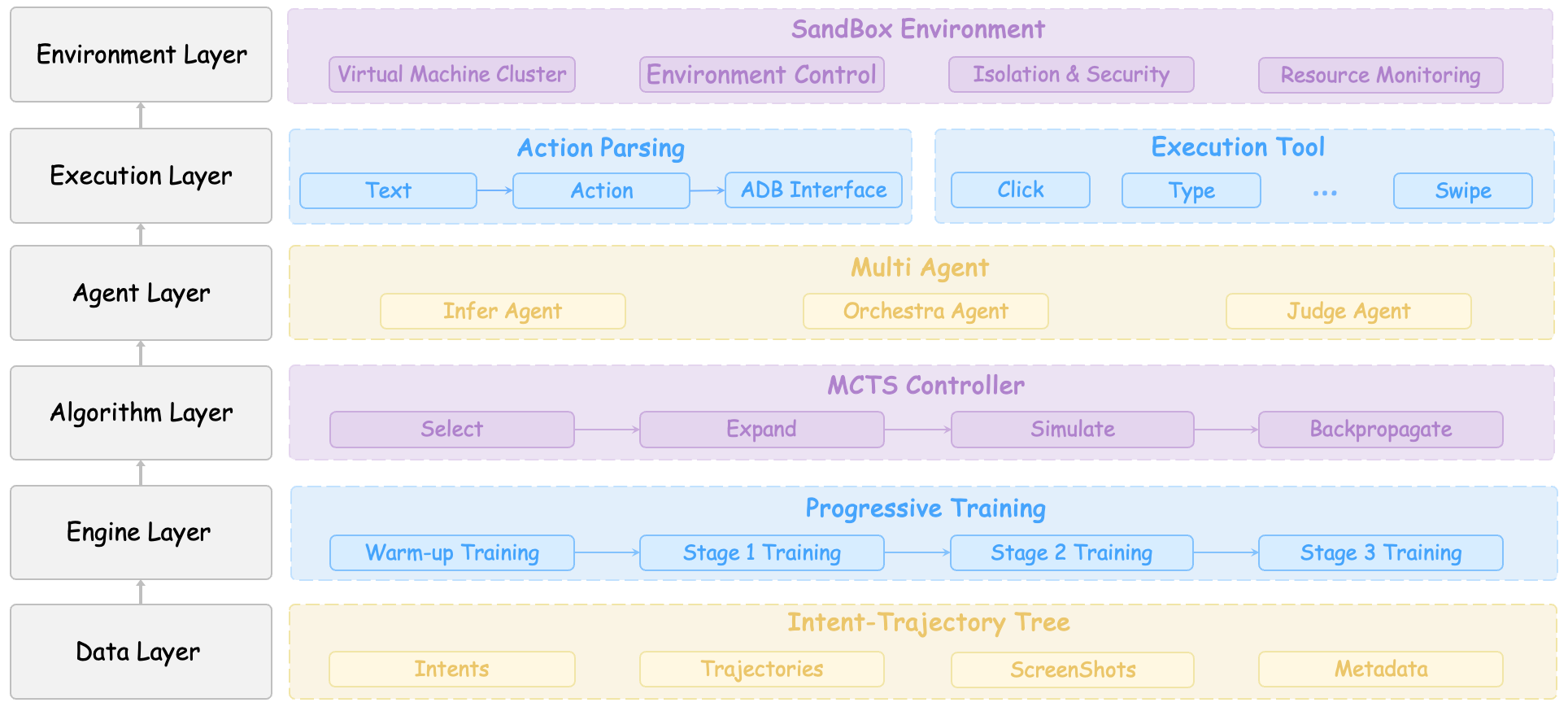
Представлен фреймворк M2-Miner, использующий многоагентную систему и алгоритм MCTS для эффективной добычи данных и обучения агентов автоматизации мобильных GUI.
Создание эффективных агентов для взаимодействия с графическим интерфейсом пользователя (GUI) требует обширных размеченных данных о траекториях действий, однако ручная разметка является дорогостоящей и не всегда обеспечивает высокое качество. В данной работе представлена система M^2-Miner: Multi-Agent Enhanced MCTS for Mobile GUI Agent Data Mining — автоматизированный фреймворк, использующий алгоритм поиска по дереву Монте-Карло и многоагентное взаимодействие для эффективной добычи данных для обучения GUI-агентов. Предложенная система демонстрирует превосходные результаты на стандартных бенчмарках, снижая затраты на сбор данных и повышая качество обучения. Какие перспективы открываются для дальнейшего развития систем автоматизированной добычи данных для обучения интеллектуальных агентов взаимодействия с GUI?
Проблема Нехватки Данных в Автоматизации Мобильных GUI
Традиционные методы автоматизации графического интерфейса мобильных приложений в значительной степени зависят от ручного создания траекторий взаимодействия, что представляет собой трудоемкий и неэффективный процесс. Разработчики вынуждены детально прописывать каждый шаг, необходимый для выполнения конкретной задачи в приложении, что требует значительных временных затрат и усилий. Эта ручная настройка особенно проблематична при работе со сложными приложениями, имеющими множество экранов и функций, и серьезно ограничивает масштабируемость автоматизированных тестов. В результате, создание и поддержка автоматизированных сценариев становится узким местом в процессе разработки и тестирования мобильных приложений, препятствуя быстрому внедрению изменений и новых функций.
Существующие наборы данных, такие как AITZ и AndroidControl, безусловно, представляют ценность для исследований автоматизации мобильных интерфейсов, однако они сталкиваются с трудностями в адекватном отображении всей сложности и разнообразия пользовательских взаимодействий в реальных условиях. Эти наборы данных зачастую ограничены определенным набором приложений, сценариев использования или типов устройств, что не позволяет в полной мере охватить вариативность, встречающуюся в повседневной практике. Недостаточное представление редких, но важных действий, а также отсутствие данных, собранных в различных сетевых условиях или с участием пользователей с разными навыками, снижает эффективность моделей, обученных на этих данных, при адаптации к новым, непредсказуемым ситуациям. Таким образом, несмотря на свою полезность, существующие наборы данных не способны полностью решить проблему недостатка данных для создания надежных и обобщающих агентов автоматизации мобильных GUI.
Недостаток высококачественных данных существенно затрудняет создание надежных и обобщающих агентов для автоматизации графического интерфейса мобильных устройств. Существующие подходы, требующие ручного создания траекторий взаимодействия, ограничены в масштабируемости и не способны охватить всё разнообразие пользовательских сценариев. Вследствие этого, разработанные агенты часто демонстрируют низкую производительность при столкновении с новыми приложениями или задачами, отличающимися от тех, на которых они были обучены. Преодоление этой проблемы требует разработки методов сбора и аннотации данных, позволяющих создавать более универсальные и адаптивные системы автоматизации, способные эффективно решать сложные задачи в реальных условиях использования мобильных приложений.
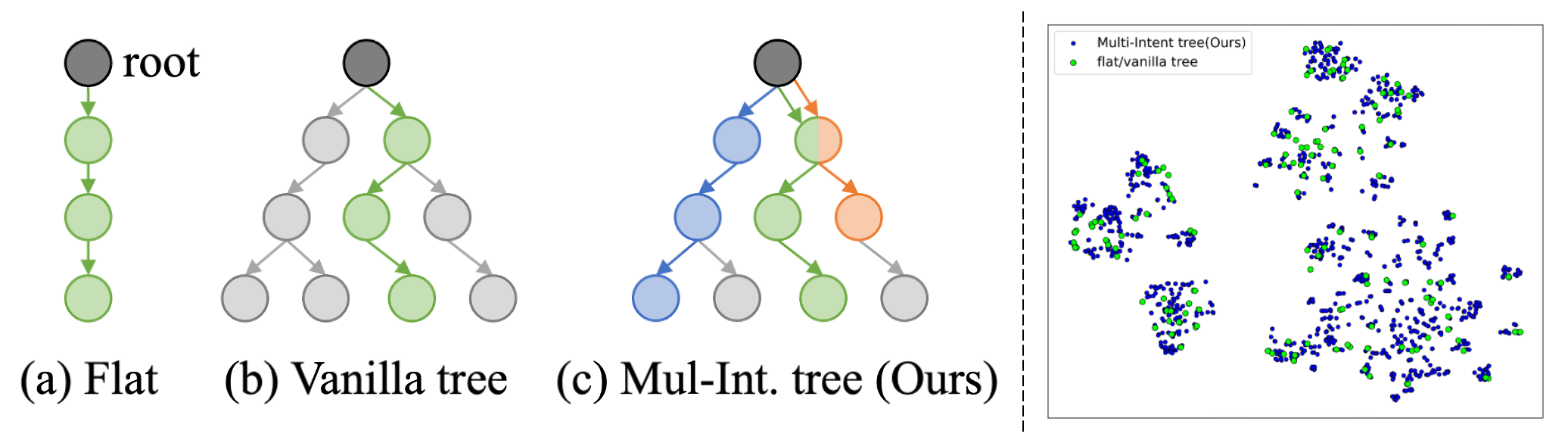
M2-Miner: Автоматизированный Фреймворк для Сбора Данных
В основе M2-Miner лежит алгоритм Монте-Карло поиска по дереву (MCTS), который позволяет эффективно исследовать огромное пространство возможных взаимодействий с графическим интерфейсом мобильных приложений. MCTS, в данном контексте, представляет собой метод принятия решений, основанный на случайном моделировании и статистическом анализе. Он итеративно строит дерево поиска, расширяя наиболее перспективные ветви на основе результатов симуляций. Каждая симуляция представляет собой последовательность действий пользователя, направленных на достижение определенной цели в приложении. Оценка каждой симуляции определяет ценность соответствующей ветви дерева, позволяя M2-Miner фокусироваться на наиболее вероятных и эффективных путях взаимодействия с GUI.
Ключевым нововведением в M2-Miner является Коллективная Многоагентная Система, состоящая из агентов InferAgent, OrchestraAgent и JudgeAgent. Данная система оптимизирует фазы расширения и симуляции алгоритма Monte Carlo Tree Search (MCTS). InferAgent отвечает за генерацию кандидатов на действия, OrchestraAgent — за их уточнение и приведение к релевантному виду, а JudgeAgent — за оценку полученных результатов и корректировку стратегии поиска. Взаимодействие между этими агентами позволяет более эффективно исследовать пространство возможных взаимодействий с мобильным графическим интерфейсом и повышает точность принимаемых решений.
Агент InferAgent, использующий большую мультимодальную модель Qwen2.5-VL, генерирует предложения по возможным действиям во время взаимодействия с графическим интерфейсом пользователя. Для повышения эффективности и релевантности этих предложений, агент OrchestraAgent осуществляет их фильтрацию и уточнение. Этот процесс позволяет сузить пространство поиска, фокусируясь на наиболее перспективных действиях и снижая вычислительную нагрузку при исследовании возможных сценариев взаимодействия.
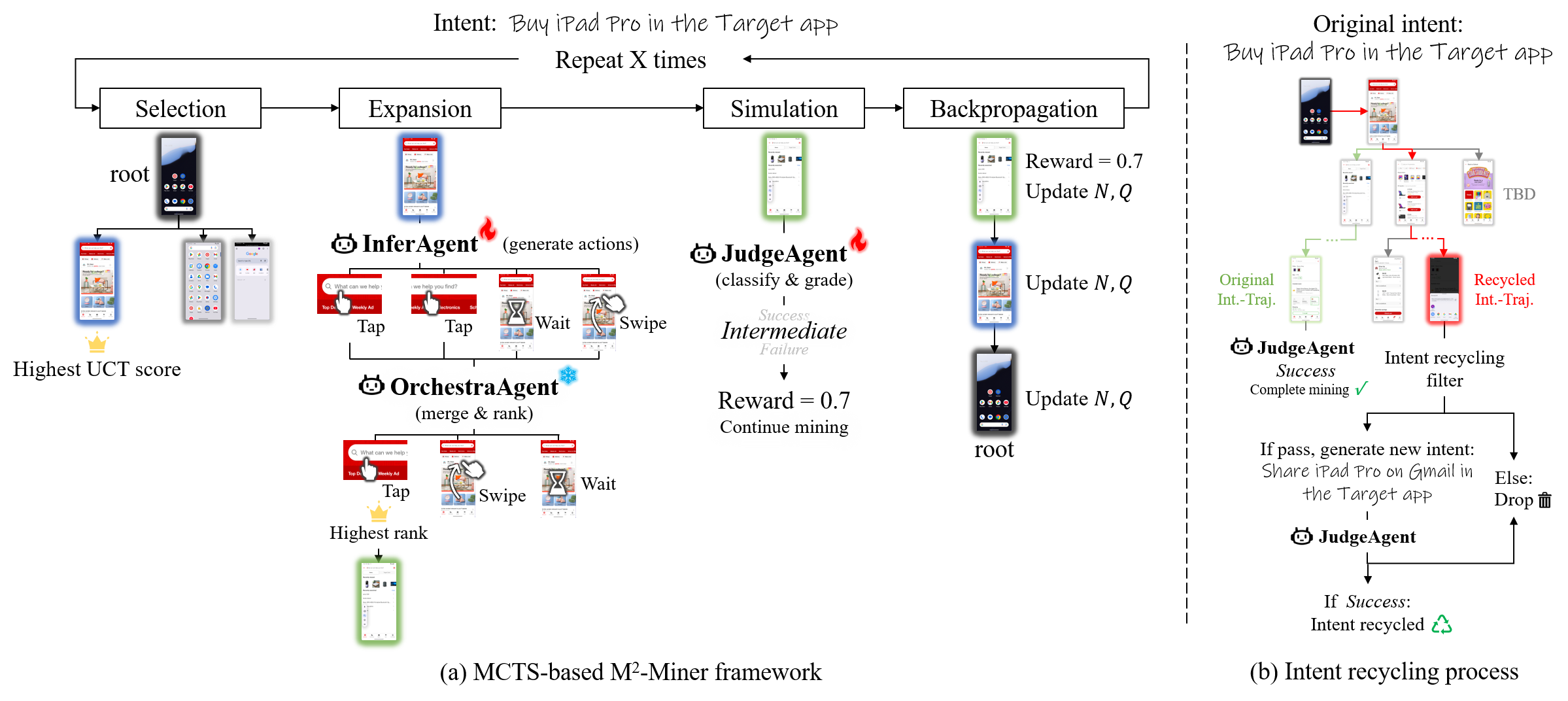
Оценка M2-Miner: Качество и Эффективность
Для оценки эффективности M2-Miner использовались метрики Mining Success Ratio (MSR) и Data Quality Accuracy (DQA). MSR определяет долю успешно завершенных траекторий взаимодействия, в то время как DQA измеряет точность и валидность сгенерированных данных. Результаты показали, что M2-Miner способен генерировать значительный объем валидных траекторий взаимодействия, что подтверждается высокими значениями обеих метрик. Это указывает на надежность и качество данных, полученных с использованием M2-Miner, и демонстрирует его способность к эффективному сбору данных для обучения моделей.
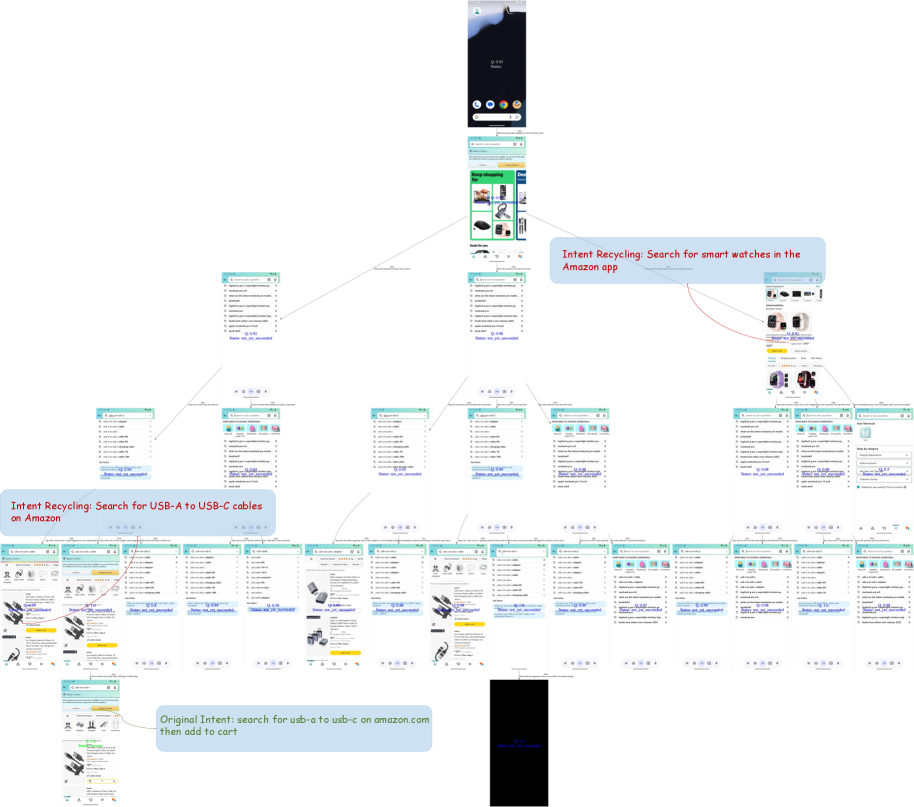
Стратегия переработки интентов (Intent Recycling) позволяет расширить разнообразие генерируемых данных за счет извлечения дополнительных ценных траекторий из существующих деревьев интентов-траекторий. Вместо полного отказа от частично исследованных путей, система повторно использует и адаптирует их, генерируя новые траектории, основанные на уже полученных знаниях. Этот подход позволяет эффективно использовать существующие данные, избегая избыточного повторного исследования одних и тех же состояний и увеличивая общее количество уникальных и полезных траекторий, доступных для обучения.
В ходе оценки производительности M2-Miner было установлено, что он обеспечивает 64-кратное увеличение эффективности сбора данных на задачах длиной 9 по сравнению с классическим алгоритмом Monte Carlo Tree Search (MCTS). Это существенное сокращение времени, необходимого для получения репрезентативной выборки траекторий взаимодействия. Кроме того, ручная проверка качества полученных данных показала, что точность данных (Data Quality Accuracy, DQA), генерируемых M2-Miner, превосходит показатели общедоступных наборов данных, что подтверждает высокую надежность и пригодность этих данных для обучения и оценки моделей.
Обобщение и Масштабируемость на Различных Тестовых Платформах
Исследования показали, что M2-Miner демонстрирует впечатляющую эффективность на различных тестовых платформах, включая AndroidControl, AITZ, GUI Odyssey и CAGUI, что свидетельствует о его способности к обобщению и адаптации к новым задачам. Способность успешно функционировать в столь разнообразных средах подтверждает, что M2-Miner не просто оптимизирован для конкретного сценария, но способен извлекать общие принципы и применять их для решения широкого спектра проблем автоматизации мобильных интерфейсов. Это особенно важно для разработки надежных и универсальных агентов, способных взаимодействовать с различными приложениями и устройствами, значительно расширяя область применения автоматизированного тестирования и взаимодействия с пользователем.
В ходе тестирования на платформе AndroidControl-High, система M2-Miner продемонстрировала выдающийся результат, достигнув показателя успешности выполнения шагов (Step Success Rate) в 97.5%, превзойдя результаты, показанные другими существующими методами. Кроме того, при использовании данных, собранных с помощью M2-Miner, модель, обученная на наборе данных CAGUI, достигла показателя успешности выполнения шагов в 70.2%. Эти результаты подчеркивают высокую эффективность M2-Miner в автоматизации сбора данных и создании надежных агентов для взаимодействия с мобильными графическими интерфейсами, что значительно повышает производительность и надежность подобных систем.
Автоматизация процесса сбора данных, реализованная в M2-Miner, значительно сокращает временные и финансовые затраты, необходимые для создания и оценки мобильных GUI-агентов. В ходе исследований было установлено, что использование M2-Miner позволяет снизить общую стоимость построения набора данных на 466 долларов. Эта экономия достигается за счет сокращения расходов на ручную проверку данных на 196 долларов и снижения вычислительных затрат на 270 долларов. Такое существенное уменьшение издержек делает разработку и тестирование GUI-агентов более доступной и эффективной, открывая новые возможности для исследований в области автоматизации мобильных интерфейсов.
Исследование, представленное в статье, демонстрирует типичную гонку за автоматизацией. Авторы предлагают M$^2$-Miner, систему, использующую многоагентный подход и алгоритм Monte Carlo Tree Search для сбора данных для обучения агентов GUI. Подобные решения всегда кажутся элегантными на бумаге, но, как известно, любые автоматизированные процессы рано или поздно сталкиваются с реальностью непредсказуемости пользовательского интерфейса. В этой связи вспоминается высказывание Пола Эрдеша: «Не беспокойтесь о том, что вы не знаете, беспокойтесь о том, что вам кажется, будто знаете». Авторы, конечно, стремятся к снижению затрат на сбор данных, но история показывает, что каждое «революционное» решение порождает новые, порой более сложные, проблемы. В конечном итоге, система будет ломаться, а документация к ней — лишь красивая иллюзия.
Что дальше?
Представленный фреймворк, M²-Miner, безусловно, демонстрирует снижение затрат на сбор данных для обучения агентов автоматизации GUI. Однако, как показывает история, каждая «оптимизация» — это лишь отложенный технический долг. Поиск траекторий, основанный на Monte Carlo Tree Search, элегантен, но не стоит забывать, что продюшн всегда найдёт способ сломать даже самую изящную теорию. Проблема обобщения, особенно в условиях динамически меняющихся интерфейсов, остаётся открытой. Сложные GUI часто проектируются без оглядки на автоматизацию, и никакая оптимизация дерева поиска не спасёт от необходимости ручной адаптации.
На горизонте маячат вопросы масштабируемости. Многоагентный подход, хоть и эффективен, требует координации и обмена информацией, что неизбежно влечёт за собой накладные расходы. Если код выглядит идеально — значит, его никто не развернул в реальной среде. Вполне вероятно, что дальнейшие исследования будут направлены на гибридные подходы, сочетающие преимущества MCTS с более простыми, но надёжными методами, такими как обучение с подкреплением на основе правил.
И, конечно, стоит помнить, что конечная цель — не просто автоматизация, а создание действительно интеллектуальных агентов. Распознавание намерений пользователя — это сложная задача, требующая не только анализа траекторий, но и понимания контекста и целей. Пока же, M²-Miner — это ещё один шаг к автоматизации, но далеко не финальный аккорд.
Оригинал статьи: https://arxiv.org/pdf/2602.05429.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-09 03:34