Автор: Денис Аветисян
Исследователи предложили метод, позволяющий более точно определять, насколько текст соответствует обучающим данным языковой модели.

В статье представлен AP-OOD — метод обнаружения текстов, выходящих за рамки распределения обучающих данных, использующий механизмы внимания и токено-уровневую информацию для повышения точности.
Обнаружение выходящих за рамки распределения данных (Out-of-Distribution, OOD) остается сложной задачей при надежном развертывании моделей машинного обучения, особенно в обработке естественного языка. В данной работе представлена методика ‘AP-OOD: Attention Pooling for Out-of-Distribution Detection’, использующая механизм внимания для агрегации токеновых представлений и повышения точности определения аномальных входных данных. Предложенный подход позволяет гибко переключаться между неконтролируемым и полуконтролируемым обучением, используя ограниченные данные об отклонениях. Сможет ли AP-OOD стать новым стандартом в области обнаружения OOD для текстовых данных и обеспечить более надежную работу генеративных языковых моделей?
Вне границ ожидаемого: вызов обнаружения аномалий
Современные модели обработки естественного языка, демонстрирующие впечатляющие результаты в различных задачах, зачастую сталкиваются с серьезными трудностями при обработке данных, существенно отличающихся от тех, на которых они обучались — эта проблема известна как обнаружение вне распределения (Out-of-Distribution detection). Несмотря на свою мощь, эти модели склонны к уверенным, но ошибочным предсказаниям, когда сталкиваются с незнакомыми входными данными, что может приводить к серьезным последствиям в критически важных приложениях, таких как медицинская диагностика или анализ финансовых рисков. Суть проблемы заключается в том, что модели, обученные на определенном наборе данных, экстраполируют полученные знания на новые данные, предполагая, что они соответствуют тем же закономерностям, что и обучающие примеры. Когда это предположение нарушается, точность модели резко падает, и она начинает выдавать неверные результаты, не имея возможности оценить свою собственную неуверенность.
Традиционные методы контролируемого обучения, направленные на выявление данных, выходящих за рамки распределения (Out-of-Distribution, OOD), требуют наличия размеченных примеров OOD, что часто является существенным препятствием. Процесс ручной разметки таких примеров не только трудоемок и требует значительных временных затрат, но и сопряжен с высокой стоимостью, особенно при работе с большими объемами данных или сложными задачами. Кроме того, получение репрезентативной выборки OOD, охватывающей все возможные отклонения от обучающего распределения, представляет собой сложную задачу, поскольку невозможно предвидеть все потенциальные сценарии, с которыми модель может столкнуться в реальных условиях. В связи с этим, практическая применимость подходов, основанных на размеченных OOD примерах, ограничена, что обуславливает необходимость разработки альтернативных, не требующих размеченных данных, методов обнаружения аномалий.
В связи с ограничениями, связанными с необходимостью размеченных данных для обнаружения выходящих за пределы распределения (OOD) примеров, возрастает интерес к разработке неконтролируемых методов. Эти подходы стремятся идентифицировать новые, незнакомые входные данные, не полагаясь на предварительно размеченные OOD-примеры, что делает их особенно ценными в реальных сценариях, где сбор и аннотация таких данных затруднительны или невозможны. Исследования в этой области фокусируются на анализе внутренней структуры данных и выявлении аномалий, отклоняющихся от ожидаемого поведения модели. Успешная реализация неконтролируемых методов позволит создавать более надежные и адаптивные системы обработки естественного языка, способные эффективно справляться с непредвиденными ситуациями и обеспечивать стабильную работу в динамично меняющейся среде.
AP-OOD: Токельный подход к обнаружению аномалий
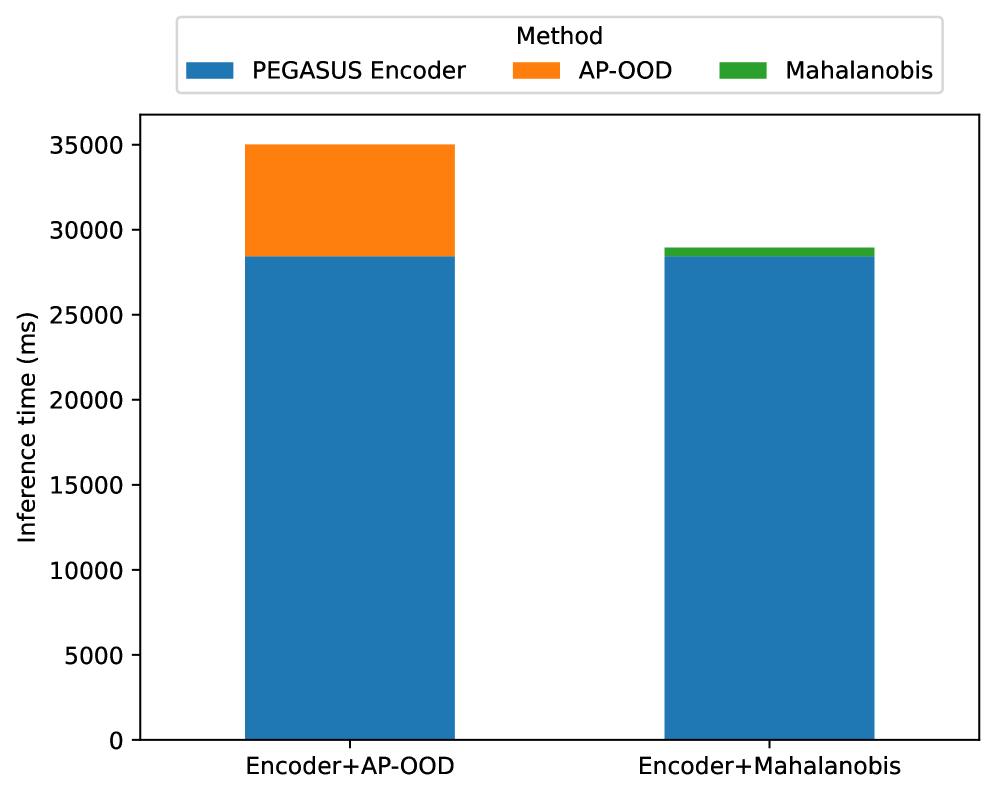
В основе метода AP-OOD лежит использование Transformer Encoder для генерации токеновых представлений (Token Embeddings) входных последовательностей. В отличие от подходов, использующих усредненные или суммарные векторы, Transformer Encoder позволяет получить контекстуализированные представления каждого токена, учитывая его взаимосвязь с другими токенами в последовательности. Это достигается за счет механизма self-attention, который вычисляет веса значимости каждого токена относительно остальных, формируя таким образом более детальное и информативное представление последовательности, способное улавливать тонкие семантические различия и зависимости. Полученные Token Embeddings служат основой для дальнейшего анализа и выявления аномальных входных данных.
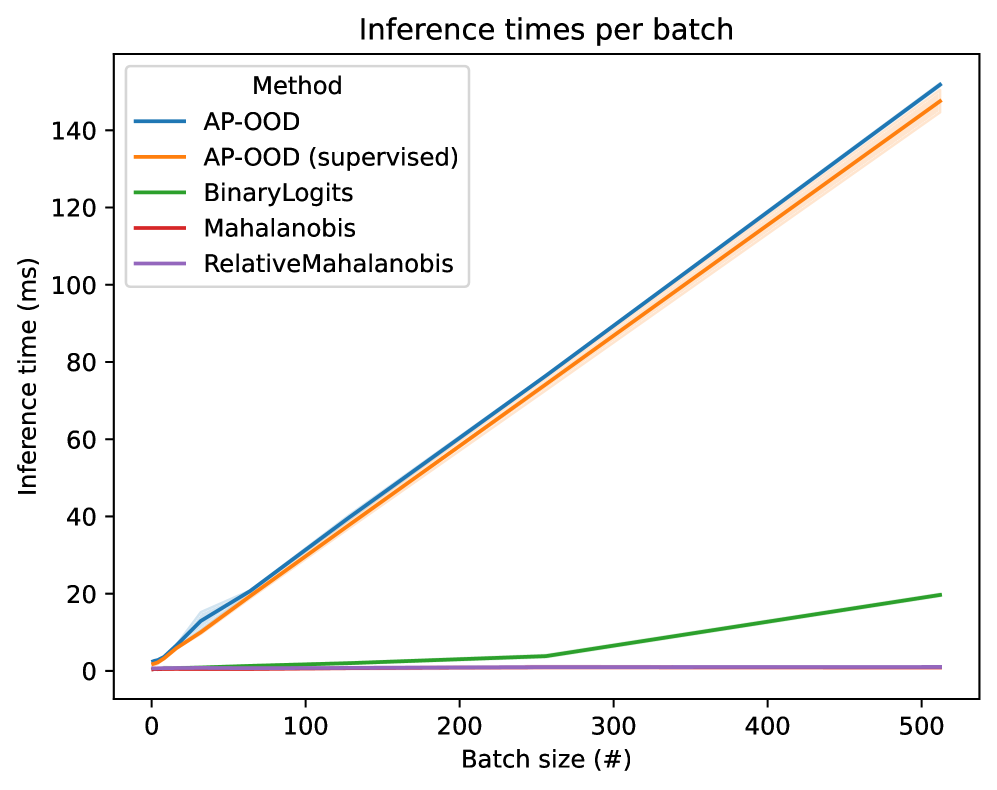
Для эффективного сравнения входных последовательностей, AP-OOD использует механизм Attention Pooling для сжатия векторных представлений токенов, полученных на этапе кодирования Transformer, в единое векторное представление последовательности. Attention Pooling позволяет присваивать различный вес каждому токену при формировании этого представления, учитывая его значимость для общей семантики последовательности. В результате формируется компактное и информативное представление всей входной последовательности, пригодное для последующего вычисления расстояния Махаланобиса и определения степени отклонения от ожидаемого распределения данных. Данный подход позволяет снизить вычислительные затраты по сравнению с анализом отдельных токенов, сохраняя при этом информативность представления последовательности.
Метод AP-OOD использует расстояние Махаланобиса для выявления аномальных входных данных. После получения представления последовательности посредством Attention Pooling, рассчитывается расстояние Махаланобиса между этим представлением и распределением представлений обучающей выборки. d^2(x) = (x - \mu)^T \Sigma^{-1} (x - \mu), где μ — среднее значение распределения обучающих данных, а Σ — ковариационная матрица. Более высокое значение расстояния Махаланобиса указывает на то, что входные данные значительно отличаются от ожидаемого распределения, что позволяет эффективно идентифицировать аномальные примеры (OOD — Out-of-Distribution).
Проверка и метрики эффективности
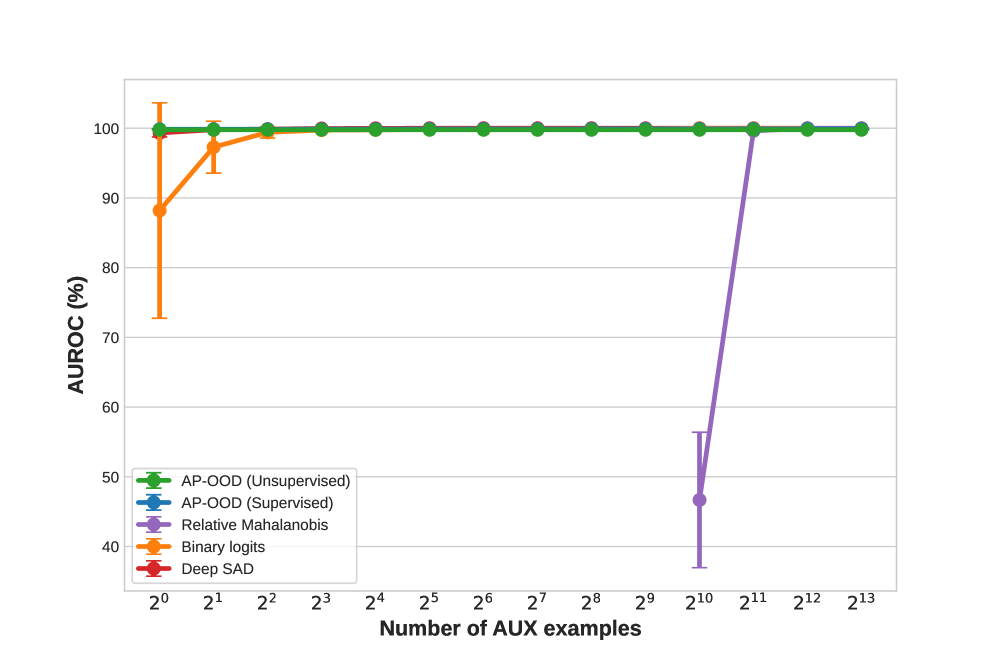
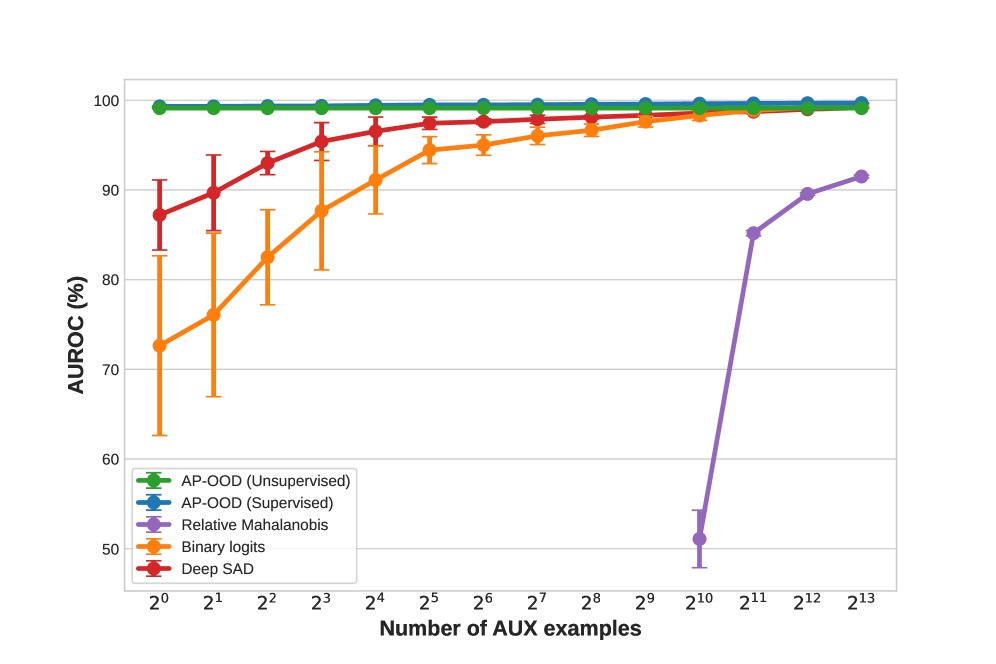
Для оценки производительности AP-OOD использовались стандартные метрики обнаружения объектов вне распределения (OOD), а именно площадь под ROC-кривой (AUROC) и частота ложноположительных срабатываний при 95% чувствительности (FPR95). Оценка проводилась на различных наборах данных для обеспечения обобщающей способности модели. AUROC измеряет способность модели различать данные внутри и вне распределения, в то время как FPR95 указывает на процент ложноположительных срабатываний при заданном уровне обнаружения истинно положительных случаев. Использование этих метрик позволяет количественно оценить эффективность AP-OOD в задачах обнаружения OOD.
В ходе экспериментов модель AP-OOD показала впечатляющие результаты по метрике AUROC (Area Under the Receiver Operating Characteristic curve). На наборе данных XSUM был достигнут показатель AUROC в 0.99. При оценке на всех использованных наборах данных для обнаружения аномалий (OOD), среднее значение AUROC составило 0.97, что свидетельствует о высокой эффективности модели в выявлении данных, отклоняющихся от обучающей выборки.
В полностью контролируемой среде обучения, AP-OOD демонстрирует существенно сниженный уровень ложноположительных срабатываний, составляющий 0.11%. Это значительное улучшение по сравнению с показателем в 0.97%, достигнутым при использовании бинарных логитов. Данный результат указывает на повышенную точность AP-OOD в идентификации нетипичных данных и снижении количества ошибочных срабатываний, что критически важно для надежности системы обнаружения аномалий.
Расширение возможностей AP-OOD: взгляд в будущее
Методология AP-OOD получает значительное усиление при интеграции с Непрерывными Современными Сетями Хопфилда, что существенно расширяет её возможности в области устойчивого распознавания образов. Эти сети, в отличие от классических, способны обрабатывать нечёткие и зашумленные данные, сохраняя при этом высокую точность идентификации. В процессе обучения, Непрерывные Сети Хопфилда адаптируются к сложным паттернам, формируя устойчивые представления о нормальном состоянии данных. Это позволяет AP-OOD эффективно выявлять отклонения от нормы, даже в условиях значительных изменений в входных данных. В результате, система становится более надежной и устойчивой к различным видам аномалий, открывая широкие перспективы для применения в задачах обнаружения необычного поведения, обеспечения безопасности данных и анализа сложных систем.
Для повышения эффективности и адаптивности методологии AP-OOD применялись современные методы уточнения больших языковых моделей (LLM). Этот подход позволил не только оптимизировать существующие параметры системы, но и генерировать принципиально новые исследовательские направления, выходящие за рамки традиционных подходов к обнаружению аномалий. Использование LLM в качестве инструмента для итеративной разработки и поиска инновационных решений обеспечило непрерывное улучшение системы, позволяя ей адаптироваться к меняющимся условиям и решать все более сложные задачи в области обнаружения внепространственных данных и обеспечения безопасности информации. Такая интеграция демонстрирует перспективность использования LLM для автоматизации научных исследований и ускорения темпов инноваций в различных областях науки и техники.
Сочетание усовершенствованной методологии AP-OOD с передовыми технологиями открывает широкие возможности для создания мощных систем обнаружения аномалий. Данный подход позволяет не только выявлять отклонения от нормы в различных данных, но и эффективно применять его в критически важных областях, таких как обеспечение информационной безопасности и предотвращение мошенничества. Система способна оперативно реагировать на нетипичное поведение, защищая от потенциальных угроз и обеспечивая надежную защиту конфиденциальной информации. Благодаря высокой точности и адаптивности, она находит применение в самых разных сферах — от мониторинга промышленных процессов до обнаружения вредоносного программного обеспечения, представляя собой перспективное решение для задач, требующих высокой степени надежности и защиты.
Исследование демонстрирует, что эффективное обнаружение аномалий в последовательностях токенов требует внимательного анализа механизмов внимания, присущих современным трансформерным моделям. Авторы предлагают метод AP-OOD, который фокусируется на агрегировании информации на уровне токенов, позволяя системе более точно оценивать степень отклонения входных данных от ожидаемого распределения. Это напоминает мудрость Брайана Кернигана: «Простота — это высшая степень утонченности». В данном случае, элегантность подхода заключается в использовании уже существующих механизмов внимания для решения сложной задачи обнаружения аномалий, не усложняя при этом общую архитектуру системы. Система, подобно опытному наблюдателю, учится различать закономерности и отклонения, не стремясь насильно вмешиваться в естественный процесс обработки информации.
Что впереди?
Представленный подход, фокусируясь на внимании как индикаторе распределения, лишь подчеркивает фундаментальную сложность различения нового и аномального в лингвистических системах. Версионирование моделей, как форма памяти об их ограничениях, становится необходимостью, но не решением. Ведь стрела времени всегда указывает на необходимость рефакторинга — даже самые совершенные системы неизбежно устаревают, их представления о “нормальном” теряют актуальность.
Очевидно, что работа с токенами, хотя и дает определенный контроль над деталями, не решает проблему контекстуальной неопределенности. Будущие исследования, вероятно, будут направлены на разработку более устойчивых к сдвигам в распределении представлений, возможно, за счет интеграции механизмов, имитирующих способность человека к абстракции и обобщению. Необходимо отойти от простой идентификации “неизвестного” к пониманию причины его появления.
В конечном счете, задача обнаружения аномалий в языке — это не столько техническая проблема, сколько философский вопрос о природе информации и ее интерпретации. Все системы стареют — вопрос лишь в том, делают ли они это достойно. Именно в этом направлении, вероятно, и кроется ключ к созданию действительно устойчивых и адаптивных лингвистических моделей.
Оригинал статьи: https://arxiv.org/pdf/2602.06031.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-09 01:47