Автор: Денис Аветисян
Новый алгоритм на основе глубинного обучения с подкреплением позволяет беспилотникам эффективно ориентироваться в сложных условиях, избегая препятствий и учитывая ограничения связи.
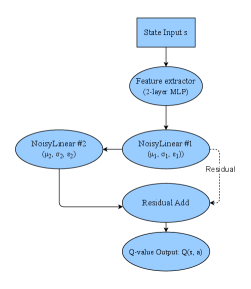
В статье представлена усовершенствованная версия алгоритма Noisy DQN для оптимизации траекторий беспилотных летательных аппаратов в условиях коммуникационных ограничений и наличия препятствий.
Оптимизация траекторий беспилотных летательных аппаратов (БПЛА) в сложных условиях, включающих коммуникационные ограничения и препятствия, представляет собой непростую задачу, требующую эффективных алгоритмов обучения с подкреплением. В данной работе, посвященной ‘UAV Trajectory Optimization via Improved Noisy Deep Q-Network’, предложен усовершенствованный алгоритм Noisy DQN, позволяющий повысить скорость сходимости и кумулятивное вознаграждение при навигации БПЛА в симулированной среде. Эксперименты показали, что предложенный подход обеспечивает до $+40$% увеличение вознаграждения и сокращение числа шагов, необходимых для выполнения задачи, по сравнению со стандартным DQN. Сможет ли данная оптимизация сети NoisyNet и повышение стабильности обучения способствовать созданию более надежных и эффективных систем управления БПЛА в реальных условиях?
Навигация БПЛА: Вызовы и Перспективы Автономности
Автономная навигация беспилотных летательных аппаратов (БПЛА) представляет собой сложную задачу, особенно в условиях реального мира. Необходимость функционирования в разнообразных и часто непредсказуемых окружениях требует от БПЛА способности самостоятельно оценивать обстановку, планировать маршрут и адаптироваться к изменениям без постоянного вмешательства оператора. Факторы, такие как городская застройка, лесные массивы, погодные условия и наличие динамических препятствий, значительно усложняют процесс навигации. Разработка надежных алгоритмов, способных эффективно справляться с этими ограничениями и обеспечивать безопасное и точное перемещение БПЛА, является ключевой задачей современной робототехники и находит применение в широком спектре областей — от доставки грузов и мониторинга инфраструктуры до поисково-спасательных операций и сельского хозяйства.
Эффективное функционирование беспилотных летательных аппаратов (БПЛА) напрямую зависит от преодоления ограничений, связанных с пропускной способностью каналов связи и затуханием сигнала. Особенно остро эта проблема проявляется в сложных городских условиях или в удаленных районах, где надежная передача данных критически важна для управления полетом и получения телеметрии. Исследования показывают, что даже незначительные помехи или потеря сигнала могут привести к серьезным ошибкам в навигации и, как следствие, к аварийным ситуациям. Для решения этой проблемы активно разрабатываются методы сжатия данных, адаптивной регулировки частоты передачи и использования резервных каналов связи. Также перспективным направлением является разработка алгоритмов, позволяющих БПЛА автономно функционировать в условиях временной потери связи, опираясь на локальные данные и встроенные сенсоры.
Успешная навигация беспилотных летательных аппаратов (БПЛА) требует не только планирования оптимального маршрута, но и надежного обхода препятствий в динамично меняющейся среде. Современные системы автономного управления БПЛА все чаще сталкиваются с необходимостью мгновенно реагировать на внезапно возникающие объекты — от других летательных аппаратов и птиц до зданий и меняющихся погодных условий. Для решения этой задачи разрабатываются сложные алгоритмы, сочетающие данные с различных сенсоров — лидаров, камер и радаров — для создания трехмерной карты окружения в реальном времени. Эффективные системы обхода препятствий не просто избегают столкновений, но и оптимизируют траекторию полета, минимизируя отклонения от запланированного маршрута и обеспечивая стабильное и безопасное передвижение в сложных городских и природных ландшафтах. Развитие таких систем является ключевым фактором для расширения сферы применения БПЛА, включая доставку грузов, мониторинг инфраструктуры и поисково-спасательные операции.
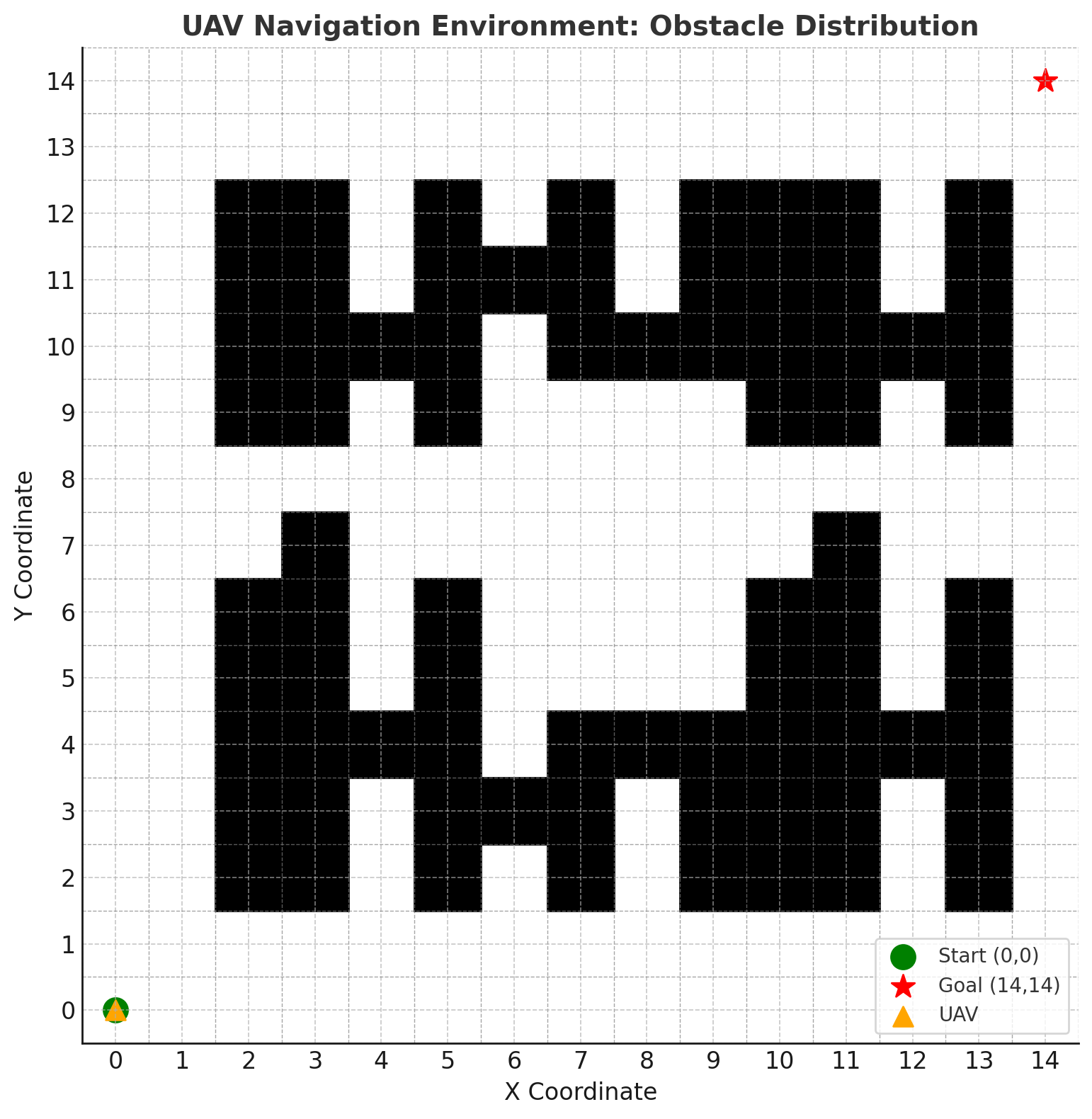
Обучение с Подкреплением: Основа Интеллектуального Управления БПЛА
Обучение с подкреплением (RL) представляет собой эффективный подход к автоматическому управлению беспилотными летательными аппаратами (БПЛА) посредством процесса проб и ошибок. В отличие от традиционных методов управления, требующих предварительного программирования всех возможных сценариев, RL позволяет БПЛА самостоятельно осваивать оптимальные стратегии навигации, взаимодействуя со средой и получая вознаграждение за успешные действия. Этот метод особенно полезен в сложных и динамических условиях, где точное предсказание всех возможных ситуаций невозможно. БПЛА, использующий RL, способен адаптироваться к изменяющимся условиям окружающей среды, избегать препятствий и достигать поставленных целей без непосредственного участия оператора.
Глубокие нейронные сети (Deep Q-Networks, DQN) расширяют возможности традиционного обучения с подкреплением, позволяя аппроксимировать оптимальные Q-функции. В классическом обучении с подкреплением Q-функция, определяющая ожидаемое вознаграждение за выполнение действия в определенном состоянии, обычно представляется таблицей. Однако, при работе со сложными, многомерными пространствами состояний, табличное представление становится непрактичным из-за экспоненциального роста требований к памяти. DQN заменяет эту таблицу глубокой нейронной сетью, которая обучается предсказывать Q-значения для каждого состояния и действия. Использование глубоких нейронных сетей позволяет эффективно обобщать знания, полученные в одних состояниях, на другие, похожие состояния, значительно улучшая производительность и масштабируемость алгоритма в сложных задачах управления БПЛА.
В основе обучения с подкреплением для БПЛА лежит метод временных различий (TD-learning), представляющий собой класс алгоритмов обучения, оценивающих функции ценности на основе разницы между текущими и будущими оценками. TD-learning позволяет БПЛА корректировать свою политику управления непосредственно на основе полученного опыта, без необходимости ждать завершения эпизода. Алгоритмы TD обновляют оценки ценности на каждом шаге, используя уравнение Беллмана, что обеспечивает более эффективное и быстрое обучение по сравнению с методами Монте-Карло. Ключевым аспектом является использование бутстрэппинга — оценки ценности обновляется на основе других оценок, что позволяет алгоритму обучаться даже при неполной информации о среде. Это итеративное обновление ценностей позволяет БПЛА постепенно совершенствовать свою стратегию управления и адаптироваться к сложным условиям полёта.
Усовершенствованные DQN: Баланс Исследования и Стабильности
Алгоритм Noisy DQN решает проблему эффективного исследования пространства действий путем прямого добавления шума к параметрам нейронной сети. В отличие от ε-жадного подхода или методов, использующих отдельные политики для исследования, Noisy DQN вводит коррелированный шум в слои сети, что приводит к систематическому исследованию различных действий. Шум добавляется после вычисления значений Q, что позволяет агенту исследовать даже те действия, которые изначально имеют низкие оценки. Такой подход способствует более эффективному исследованию, особенно в средах со сложными функциями вознаграждения или разреженными сигналами, поскольку позволяет агенту пробовать разнообразные действия без необходимости случайного выбора, что повышает скорость обучения и стабильность.
Для повышения стабильности процесса обучения в алгоритмах глубокого обучения с подкреплением, используется метод “мягких” (soft) обновлений целевой сети. Вместо полного копирования весов основной сети в целевую сеть после каждого шага обучения, применяется взвешенное усреднение. Это достигается путем обновления весов целевой сети по формуле: θ_t = τθ_{t-1} + (1-τ)θ_t , где θ_t — веса целевой сети на шаге t, θ_{t-1} — предыдущие веса целевой сети, а τ — коэффициент, определяющий степень усреднения (обычно в диапазоне 0 < τ < 1). Использование небольшого значения τ позволяет целевой сети изменяться постепенно, что снижает риск резких колебаний и способствует более устойчивому обучению.
Адаптивное планирование шума (Adaptive Noise Scheduling) в алгоритмах обучения с подкреплением, таких как Noisy DQN, обеспечивает динамическую регулировку уровня шума, добавляемого к параметрам нейронной сети, в процессе обучения. Изначально высокий уровень шума способствует широкому исследованию пространства действий, позволяя агенту обнаруживать потенциально полезные стратегии. По мере обучения и накопления опыта уровень шума постепенно снижается, что позволяет агенту сосредоточиться на эксплуатации уже выявленных эффективных действий и повысить стабильность процесса обучения. Данный подход позволяет сбалансировать исследование и эксплуатацию, избегая преждевременной сходимости к локальным оптимумам и обеспечивая более эффективное обучение агента.
Оптимизация Обучения: Передовые Стратегии и Эффективность
Стратегия прогрева скорости обучения (Learning Rate Warm-up) заключается в постепенном увеличении значения скорости обучения от минимального до целевого в начале тренировочного процесса. Это позволяет избежать резких изменений в весах нейронной сети, которые могут возникнуть при использовании высокой скорости обучения с самого начала. Особенно эффективно применение данной стратегии в задачах обучения с подкреплением и при использовании больших пакетов данных, где нестабильность обучения является распространенной проблемой. Начальные небольшие значения скорости обучения способствуют более плавному исследованию пространства параметров и предотвращают расхождение процесса обучения, обеспечивая более надежную сходимость к оптимальному решению. Как правило, прогрев скорости обучения длится несколько сотен или тысяч итераций, после чего скорость обучения стабилизируется на целевом значении или переходит к более сложным графикам изменения, таким как косинусное затухание.
Использование косинусного отжига в качестве стратегии изменения скорости обучения обеспечивает постепенное уменьшение значения α на протяжении всего процесса тренировки. Это позволяет более точно настроить политику агента и избежать нежелательных колебаний, которые могут возникать при использовании фиксированной или ступенчатой скорости обучения. Косинусный отжиг, в отличие от линейного уменьшения, обеспечивает более плавный переход к минимальной скорости обучения, что способствует улучшению сходимости и повышению стабильности обучения, особенно на поздних этапах, когда необходимо более тонкое «шлифование» параметров модели.
Для снижения вычислительных затрат в процессе обучения используется факторизованный гауссовский шум. Традиционные методы генерации случайного шума требуют значительных ресурсов, особенно при работе с многомерными пространствами. Факторизация предполагает разложение ковариационной матрицы шума на произведение одномерных матриц, что позволяет генерировать шум для каждой размерности независимо. Это существенно снижает сложность вычислений и уменьшает потребление памяти, не оказывая при этом значительного влияния на эффективность обучения. Вместо генерации многомерного гауссовского шума с полной ковариационной матрицей, генерируется набор независимых одномерных гауссовских случайных величин, что значительно упрощает процесс и повышает скорость обучения.
К Надежным и Интеллектуальным Системам Навигации БПЛА
Интеграция усовершенствованных вариантов алгоритма глубокого обучения с подкреплением (DQN) и инновационных стратегий обучения открывает новые возможности для повышения надежности и эффективности навигации беспилотных летательных аппаратов (БПЛА) в сложных условиях. Разработанные подходы позволяют БПЛА успешно ориентироваться в разнообразных и динамично меняющихся средах, преодолевая препятствия и оптимизируя маршруты. Это достигается за счет улучшения способности агента к обучению и адаптации, что критически важно для автономной работы в реальном мире, где предсказуемость ограничена, а требования к безопасности и производительности высоки. Такой подход позволяет создавать БПЛА, способные к уверенной и эффективной навигации даже в самых сложных и непредсказуемых условиях.
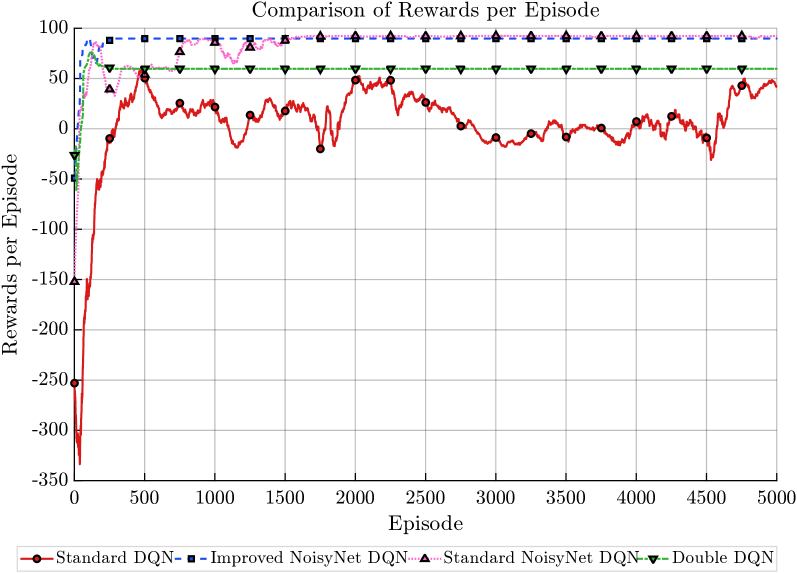
Предложенный усовершенствованный алгоритм Noisy DQN продемонстрировал значительно более быструю сходимость в задачах навигации беспилотных летательных аппаратов (БПЛА), требуя минимальное количество шагов для достижения оптимального решения. В ходе экспериментов алгоритм достиг нижней границы необходимого числа шагов, в то время как другие распространенные методы требовали приблизительно 40 шагов для достижения сопоставимых результатов. Данное ускорение обучения не только повышает эффективность процесса разработки систем навигации для БПЛА, но и открывает возможности для обучения в условиях ограниченных вычислительных ресурсов и времени, что особенно важно для применения в реальных условиях эксплуатации.
Предложенная архитектура демонстрирует стабильное вознаграждение, приближающееся к отметке в 100 единиц, что значительно превосходит показатели стандартного алгоритма DQN, достигающего примерно 60 единиц. Хотя полученный результат сопоставим с показателями стандартного Noisy DQN, новая разработка отличается повышенной стабильностью, что является критически важным фактором для надежной работы в реальных условиях. Данное достижение открывает перспективные возможности для создания полностью автономных беспилотных летательных аппаратов, способных эффективно и безопасно функционировать в сложных и непредсказуемых средах, приближая эру широкомасштабного применения БПЛА в различных отраслях.
Исследование, представленное в статье, демонстрирует, что оптимизация траектории БПЛА посредством усовершенствованного алгоритма Noisy DQN позволяет достичь более высокой скорости сходимости и, как следствие, больших наград. Этот подход, особенно в условиях ограниченной связи и наличия препятствий, подчеркивает важность последовательной проверки и корректировки моделей. Как заметил Альбер Камю: «Всё начинается с абсурда». В данном контексте, абсурд — это сложность реальных условий, а решение — это непрерывный процесс обучения и адаптации, который позволяет БПЛА успешно ориентироваться в окружающей среде, несмотря на непредсказуемость и помехи. Игнорирование отклонений от идеальной модели, как и пренебрежение ‘outliers’, может привести к ошибочным выводам и неоптимальным решениям.
Что дальше?
Представленная работа демонстрирует улучшение алгоритма Noisy DQN для навигации БПЛА в сложных условиях. Однако, следует признать, что ускорение сходимости и повышение награды — это лишь количественные показатели. Более фундаментальным вопросом остаётся устойчивость полученных решений к непредсказуемым изменениям в окружающей среде, которые неизбежно возникнут в реальных условиях эксплуатации. Корреляция между улучшенными показателями в симуляции и их воспроизводимостью в полевых испытаниях требует, как минимум, осторожной оценки.
Особое внимание заслуживает проблема масштабируемости. Алгоритм, успешно работающий в относительно простых сценариях с ограниченным числом препятствий и коммуникативных ограничений, может столкнуться с трудностями при увеличении сложности среды. Необходимо исследовать возможности применения иерархических подходов к обучению с подкреплением, позволяющих разложить сложную задачу на более простые подзадачи. Также, следует учитывать вычислительные затраты, связанные с обучением и развертыванием алгоритма на бортовых вычислительных системах БПЛА.
В конечном счете, истинный прогресс в области автономной навигации БПЛА заключается не в создании всё более сложных алгоритмов, а в разработке надежных и верифицируемых систем, способных адаптироваться к непредсказуемости реального мира. И, возможно, стоит задуматься о том, что иногда наиболее элегантное решение — это не алгоритм, а тщательное проектирование среды, в которой этот алгоритм работает.
Оригинал статьи: https://arxiv.org/pdf/2602.05644.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-09 00:17