Автор: Денис Аветисян
Новый масштабный набор данных SynthForensics позволяет оценить эффективность современных методов выявления синтетических видео, созданных передовыми генеративными моделями.
Представлен новый эталонный набор данных и протокол оценки для выявления высококачественных синтетических видео, демонстрирующий существенные ограничения существующих методов обнаружения дипфейков.
Существующие методы обнаружения дипфейков оказываются неэффективными в условиях стремительного развития генеративных моделей. В настоящей работе представлена новая платформа ‘SynthForensics: A Multi-Generator Benchmark for Detecting Synthetic Video Deepfakes’, предназначенная для оценки детекторов синтетических видео, созданных на основе современных моделей преобразования текста в видео. Мы продемонстрировали, что современные алгоритмы демонстрируют значительное снижение производительности 29.19\% AUC на этом новом наборе данных, а некоторые из них уступают случайному выбору, особенно при сильном сжатии. Сможет ли предложенный набор данных стимулировать разработку более устойчивых и обобщающих алгоритмов обнаружения дипфейков нового поколения?
Эволюция Синтетических Медиа и Проблема Обнаружения
Современные модели преобразования текста в видео (T2V) демонстрируют беспрецедентный прогресс в создании фотореалистичных видеороликов. Эти системы, используя лишь текстовое описание, способны генерировать сложные сцены с высокой степенью детализации и правдоподобности. Развитие алгоритмов, основанных на диффузионных моделях и генеративно-состязательных сетях (GAN), позволило значительно улучшить качество синтезированного видео, сделав его все труднее отличимым от реальных съемок. Наблюдается экспоненциальный рост возможностей T2V, что приводит к созданию видеоконтента, который ранее требовал значительных ресурсов и профессиональных навыков для производства. Это открывает новые перспективы в области искусства, развлечений и образования, но одновременно создает серьезные вызовы в контексте информационной безопасности и борьбы с дезинформацией.
Существующие эталонные наборы данных для выявления дипфейков, такие как DFDC, FaceForensics++ и Celeb-DF, преимущественно сосредоточены на анализе видео, где подверглись изменениям реальные кадры. Это означает, что алгоритмы, обученные на этих данных, оценивают различия между подлинным и измененным видеоматериалом. Однако, с появлением генеративных моделей, способных создавать видео полностью из текстового описания, возникает принципиальное несоответствие. Текущие методы обнаружения, оптимизированные для выявления манипуляций с существующими видео, оказываются недостаточно эффективными при анализе контента, который никогда не существовал в реальности, что создает серьезную проблему в контексте растущего объема синтедийных медиа.
Существующий разрыв между возможностями современных систем обнаружения дипфейков и новейшими моделями генерации видео из текста представляет серьезную проблему. Исследования показывают, что существующие алгоритмы, разработанные для выявления манипуляций в реальных видеороликах, демонстрируют крайне низкую эффективность — всего 50-58% по метрике AUC — при анализе контента, полностью сгенерированного на основе текстовых запросов. Этот значительный “доменный разрыв” указывает на то, что текущие детекторы не способны адекватно распознавать артефакты и особенности, присущие видео, созданным искусственным интеллектом “с нуля”, что ставит под угрозу достоверность визуальной информации и увеличивает риск распространения дезинформации.
Сохранение доверия к визуальной информации становится все более сложной задачей в эпоху стремительного развития технологий синтетических медиа. Появление реалистичных видео, созданных на основе текстовых запросов, представляет серьезную угрозу, поскольку существующие методы обнаружения дипфейков, ориентированные на манипуляции с реальными видеозаписями, демонстрируют низкую эффективность при анализе полностью синтетического контента. Это несоответствие между возможностями генерации и обнаружения открывает широкие возможности для распространения дезинформации и подрыва общественного доверия к визуальным источникам. Преодоление этого разрыва требует разработки принципиально новых подходов к обнаружению, способных отличать сгенерированные изображения и видео от подлинных, и является критически важным шагом для защиты от манипуляций и поддержания информационной безопасности.

SynthForensics: Эталон для Эпохи Синтетического Контента
SynthForensics представляет собой новый эталон, разработанный специально для оценки детекторов на исключительно синтетических видеоматериалах. В отличие от существующих бенчмарков, которые часто используют смешанные наборы данных, SynthForensics фокусируется исключительно на оценке способности детекторов выявлять видео, сгенерированные искусственным интеллектом. Это позволяет более точно измерить эффективность детекторов в сценариях, где присутствует только синтетический контент, и выявить их слабые места в условиях, приближенных к реальным угрозам, связанным с дипфейками и другими формами сгенерированного видео.
В основе SynthForensics лежит протокол парных источников, использующий реальные видеоматериалы в качестве опорных данных для генерации соответствующих синтетических аналогов. Такой подход гарантирует семантическую согласованность между исходным и синтезированным контентом, что достигается путем сопоставления сцен, объектов и действий в обоих видео. Это позволяет более точно оценивать способность детекторов различать реальные и сгенерированные видео, поскольку изменения в синтетическом видео происходят на основе существующего реального контента, а не являются полностью случайными.
В основе SynthForensics лежит генерация синтетических видеороликов с использованием различных моделей преобразования текста в видео (T2V), включая Wan2.1, CogVideoX и SkyReels-V2. Применение нескольких моделей T2V позволяет создать разнообразный набор синтетических данных, отличающихся по стилю, качеству и артефактам. Это разнообразие необходимо для всесторонней оценки детекторов, поскольку позволяет проверить их устойчивость к различным типам синтетических манипуляций и не допускает переобучения на специфических особенностях одной конкретной модели генерации видео.
В SynthForensics применяется строгая процедура валидации, осуществляемая людьми, для оценки семантической согласованности сгенерированных видео и обеспечения соответствия этическим нормам. Этот процесс включает в себя проверку соответствия между исходными реальными видео и их синтетическими аналогами, что позволяет добиться высокой точности работы детекторов — до 99.99% AUC на генераторах, используемых для создания набора данных, таких как Wan2.1, CogVideoX и SkyReels-V2. Данный подход гарантирует, что детекторы не только эффективно распознают синтетический контент, но и учитывают контекст и смысл изображаемых сцен.
Под Капотом: Эволюция Генеративных Архитектур
Современные модели преобразования текста в видео (T2V) всё чаще строятся на основе диффузионных трансформеров, постепенно заменяя конволюционные U-сети. Этот переход обусловлен необходимостью улучшения пространственно-временной когерентности генерируемого видео. В отличие от U-сетей, трансформеры, благодаря механизму внимания, способны более эффективно моделировать долгосрочные зависимости между кадрами, что критически важно для создания реалистичного и плавного движения. Использование диффузионных трансформеров позволяет генерировать видео с более высокой детализацией и меньшим количеством артефактов, особенно в сложных сценах с множеством движущихся объектов. Такая архитектура обеспечивает более стабильный процесс обучения и позволяет достичь лучшего качества генерируемого контента по сравнению с традиционными подходами на основе конволюционных сетей.
Диффузионные модели, лежащие в основе диффузионных трансформеров, функционируют путем постепенного добавления гауссовского шума к исходному изображению или видео до тех пор, пока не будет получен чистый шум. Затем модель обучается обращать этот процесс, итеративно удаляя шум для восстановления исходных данных. Этот процесс, называемый диффузионным обратным процессом, выполняется многократно, на каждом шаге уточняя изображение или видео и повышая его качество. Итеративная природа процесса позволяет модели создавать высокодетализированные и реалистичные результаты, что и обеспечивает высокую точность синтезированного контента.
Первые генеративные модели, такие как генеративно-состязательные сети (GAN), продемонстрировали значительный прогресс в создании реалистичных изображений и видео, однако страдали от проблем, таких как «коллапс моды» (mode collapse), когда модель генерировала ограниченный набор образцов, и нестабильность обучения, требующая тонкой настройки гиперпараметров. В отличие от GAN, диффузионные модели решают эти проблемы за счет постепенного добавления шума к данным, а затем обучения модели обратного процесса для восстановления исходного сигнала. Этот подход обеспечивает более стабильное обучение и позволяет генерировать более разнообразные и высококачественные образцы, значительно превосходя GAN по метрикам оценки качества и разнообразия генерируемого контента.
Понимание эволюции архитектур генеративных моделей, таких как переход от GAN к диффузионным трансформерам, критически важно для разработки эффективных стратегий обнаружения синтетических видео. Каждая архитектура оставляет уникальные “отпечатки пальцев” в генерируемом контенте — специфические артефакты и закономерности, связанные с особенностями процесса генерации. Эти “отпечатки” проявляются в частотной области, статистических характеристиках пикселей и других параметрах, которые могут быть использованы для различения реальных и сгенерированных видео. Различия в архитектуре напрямую влияют на эти артефакты, поэтому знание принципов работы каждой модели необходимо для создания надежных детекторов, способных выявлять манипуляции и подделки.

Оценка Стратегий Обнаружения: От Тонкой Настройки до Обучения с Нуля
SynthForensics предоставляет уникальную возможность для всесторонней оценки различных стратегий обнаружения синтетических видео, начиная от тонкой настройки предварительно обученных моделей и заканчивая обучением с нуля. Этот комплексный подход позволяет исследователям детально изучить эффективность каждой стратегии в различных условиях и при использовании различных генераторов синтетического контента. Использование платформы позволяет не только определить, какие методы наиболее эффективны в текущий момент, но и выявить слабые места существующих детекторов, что способствует разработке более надежных и устойчивых алгоритмов распознавания поддельных видеоматериалов. Такой подход к оценке особенно важен в условиях быстрого развития технологий генерации контента, когда существующие методы могут быстро устаревать.
Оценка способности детектора обобщать информацию, то есть выявлять синтетические видео, которые он ранее не видел, является ключевым аспектом в современной криминалистике цифровых изображений. Платформа SynthForensics предоставляет уникальную возможность протестировать эту способность в условиях “нулевого выстрела” (zero-shot), когда детектор сталкивается с новыми, ранее не встречавшимися образцами синтетических видео. Такой подход позволяет оценить, насколько хорошо детектор способен экстраполировать знания, полученные при анализе известных синтетических данных, на совершенно новые типы подделок. Низкий показатель обобщения указывает на уязвимость детектора и необходимость совершенствования алгоритмов, в то время как высокая способность к обобщению свидетельствует о надежности и универсальности решения в борьбе с растущей угрозой дипфейков и манипулированных видеоматериалов.
Для обеспечения воспроизводимости и контроля над процессом создания обучающих данных, в SynthForensics используется подход, основанный на моделях «зрение-язык» (Vision-Language Models, VLMs). Вместо ручного создания или использования фиксированных наборов данных, VLMs позволяют генерировать разнообразные и детализированные текстовые запросы, которые затем используются для синтеза видеоматериалов. Такой подход дает возможность стандартизировать процесс генерации данных, варьируя параметры запросов и обеспечивая более точное управление характеристиками синтезируемых видеороликов. Это, в свою очередь, способствует более объективной оценке эффективности алгоритмов обнаружения, поскольку позволяет целенаправленно создавать обучающие наборы, отражающие конкретные типы манипуляций и артефактов, характерные для синтетических видео.
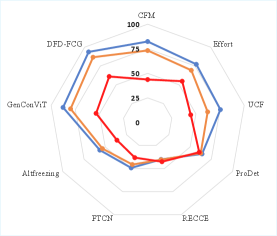
Возможность SynthForensics изолировать исключительно синтетические видео позволяет провести детальный анализ сильных и слабых сторон детекторов. Исследования выявили значительные различия в производительности: показатели Equal Error Rate (EER) варьируются от практически идеальных (0.00%) до 20.00% в зависимости от используемого генератора. В то время как Average Precision (AP) достигает 99.99% при оценке на генераторах, используемых в процессе обучения, она существенно снижается до 51.77% при тестировании на генераторе MAGI-1 с использованием архитектуры GenConViT. Эти данные подчеркивают важность оценки детекторов на разнообразных и ранее не встречавшихся синтетических данных для выявления уязвимостей и улучшения их обобщающей способности.
Представленное исследование демонстрирует, что существующие методы обнаружения дипфейков часто оказываются несостоятельными перед лицом высококачественных синтетических видео, созданных современными генеративными моделями. Это подчеркивает необходимость в более строгих и всесторонних критериях оценки, способных выявить даже незначительные артефакты, указывающие на манипуляции. В этой связи, примечательна фраза Андрея Николаевича Колмогорова: «Математика — это искусство невозможного». И подобно тому, как математик стремится к абсолютной точности, так и исследователи в области обнаружения дипфейков должны стремиться к созданию алгоритмов, способных безошибочно отличать реальность от симуляции, даже когда разница становится практически незаметной. Работа над SynthForensics, как и любое научное исследование, является постоянным поиском доказательств и отладкой моделей, соответствующих самым строгим требованиям к достоверности.
Что Дальше?
Представленный анализ, хоть и демонстрирует уязвимость существующих методов обнаружения синтетических видео, в сущности лишь констатирует очевидное: если решение кажется магией — значит, инвариант не раскрыт. Проблема не в том, что алгоритмы “не видят” манипуляции, а в том, что сами манипуляции становятся всё более изощрёнными, а критерии оценки — неадекватными. Увлечение метриками качества видео, рассчитанными для реального контента, в применении к искусственно сгенерированному — это всё равно что оценивать красоту математической теоремы по её каллиграфическому оформлению.
Будущие исследования должны сосредоточиться не на увеличении сложности детекторов, а на разработке принципиально новых подходов, основанных на глубоком понимании процесса генерации. Иными словами, необходимо не столько “видеть” артефакты, сколько предсказывать их появление, исходя из архитектуры генеративной модели. Создание эталонных наборов данных, учитывающих не только визуальные особенности, но и метаданные, связанные с процессом генерации, представляется задачей нетривиальной, но необходимой.
Наконец, стоит признать, что проблема обнаружения синтетических видео — это лишь частный случай более общей задачи — верификации информации. Стремление к созданию “универсального детектора” обречено на неудачу. Гораздо перспективнее выглядит разработка специализированных инструментов, адаптированных к конкретным сценариям использования и учитывающих контекст распространения информации. И тогда, возможно, иллюзия реальности не будет столь коварной.
Оригинал статьи: https://arxiv.org/pdf/2602.04939.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-08 15:44