Автор: Денис Аветисян
Новая система TKG-Thinker использует обучение с подкреплением, чтобы самостоятельно находить ответы на сложные вопросы, основанные на данных, меняющихся во времени.
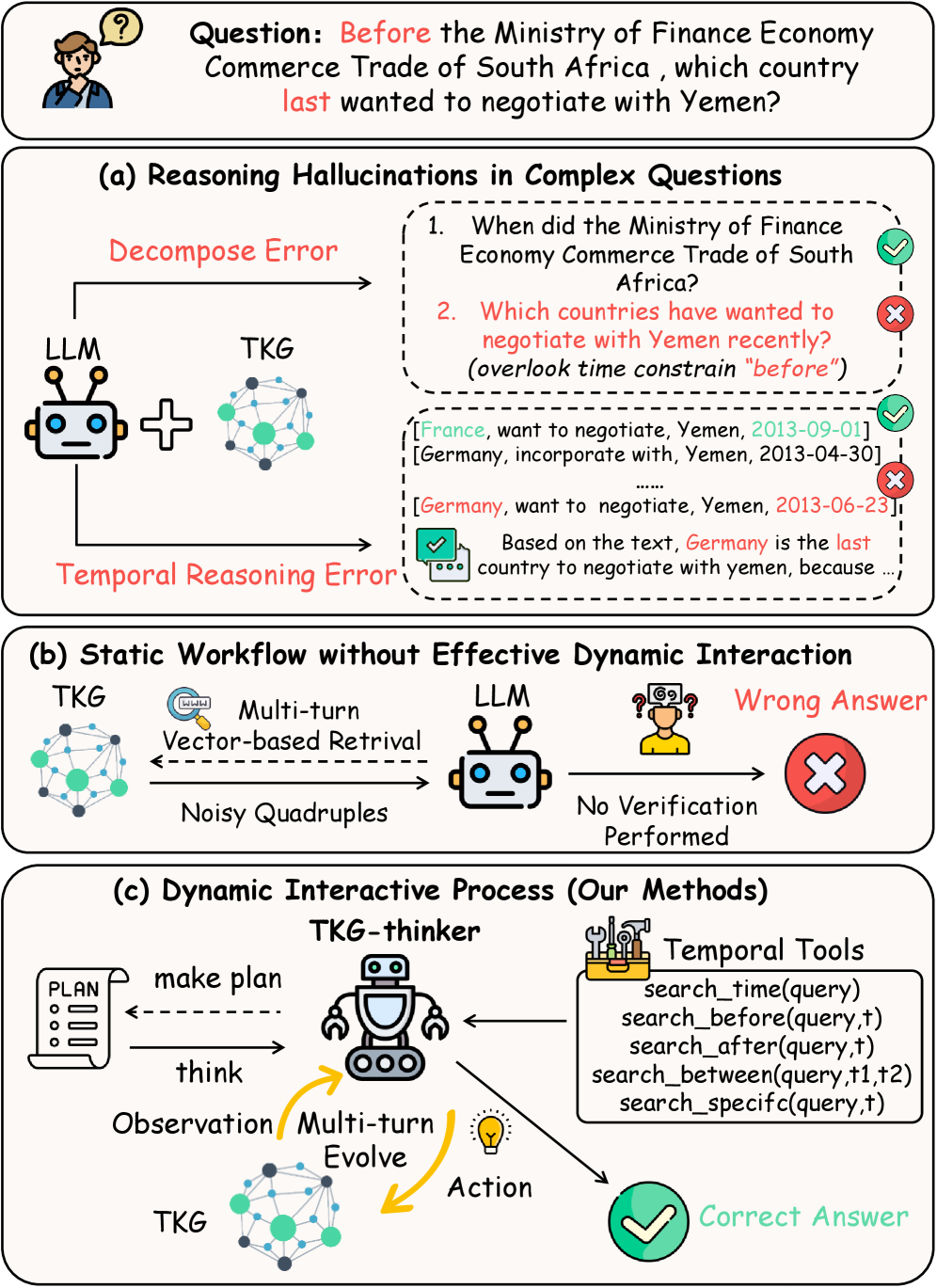
Представлен агент TKG-Thinker, использующий обучение с подкреплением для динамического рассуждения над временными графами знаний и повышения эффективности решения задач TKGQA.
Несмотря на значительный потенциал больших языковых моделей (LLM) в решении задач ответа на вопросы по временным графам знаний (TKGQA), существующие подходы ограничены склонностью к логическим ошибкам при работе со сложными временными зависимостями и недостаточной автономией в процессе рассуждений. В данной работе, представленной под названием ‘TKG-Thinker: Towards Dynamic Reasoning over Temporal Knowledge Graphs via Agentic Reinforcement Learning’, предлагается новый агент TKG-Thinker, использующий обучение с подкреплением для обеспечения автономного, динамического рассуждения над временными графами знаний. Эксперименты на стандартных наборах данных демонстрируют, что TKG-Thinker превосходит современные методы и обладает высокой обобщающей способностью. Способны ли подобные агентские системы кардинально изменить подход к анализу и интерпретации временных данных?
Временные Запутанности: Природа Изменчивых Знаний
Традиционные методы рассуждений сталкиваются со значительными трудностями при работе с постоянно меняющимися знаниями. Проблема заключается в том, что большинство существующих систем оперируют статичными данными, не учитывая временную динамику информации. Это приводит к неточностям и ошибкам при попытке ответить на вопросы, требующие понимания истории изменений, последовательности событий или прогнозирования будущих состояний. Например, системы, основанные на логических правилах, часто не способны адекватно обработать информацию о том, что какое-то утверждение было истинным в прошлом, но больше не является таковым. Сложность возрастает экспоненциально с увеличением объема данных и количеством взаимосвязей между ними, что делает задачу временного рассуждения особенно трудной для классических алгоритмов и требует разработки принципиально новых подходов к представлению и обработке знаний.
Для ответов на вопросы, требующие понимания временных взаимосвязей, необходимо фиксировать и обрабатывать динамически изменяющиеся отношения между сущностями и событиями. Иначе говоря, система должна не просто знать факты, но и понимать, когда эти факты были верны и как они менялись со временем. Это подразумевает построение моделей, способных отслеживать эволюцию знаний, учитывать причинно-следственные связи, зависящие от времени, и делать выводы на основе истории изменений. Например, для вопроса о том, был ли определенный человек премьер-министром в конкретный год, необходимо не только знать его должность, но и понимать временной период, в течение которого он занимал этот пост. Подобный подход требует сложных алгоритмов и структур данных, способных эффективно представлять и манипулировать временной информацией, что представляет собой серьезную задачу для современных систем искусственного интеллекта.
Существующие методы рассуждений зачастую испытывают трудности при учете временного контекста, что негативно сказывается на точности ответов. Проблема заключается в том, что традиционные системы обработки информации не способны эффективно интегрировать данные, изменяющиеся во времени, и учитывать последовательность событий. Это приводит к неверным выводам, особенно в задачах, требующих понимания причинно-следственных связей и динамики процессов. Например, при анализе исторических данных или прогнозировании будущих событий, игнорирование временного аспекта может привести к ошибочным интерпретациям и неадекватным решениям. Необходимость разработки новых подходов, способных полноценно учитывать временной контекст, становится всё более очевидной для повышения надежности и эффективности систем искусственного интеллекта.
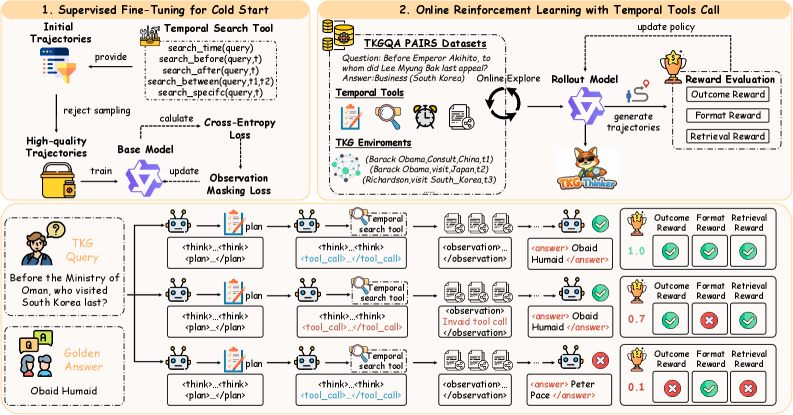
TKG-Thinker: Агентный Фреймворк для Динамических Рассуждений
Архитектура TKG-Thinker построена на цикле «думай-действуй-наблюдай», позволяющем итеративно совершенствовать пути рассуждений. В рамках этого цикла, система генерирует ход мыслей (think), выполняет действие на основе этого рассуждения (action), и анализирует полученный результат (observe). Данные, полученные на этапе наблюдения, используются для корректировки дальнейших рассуждений и действий, что позволяет системе динамически адаптироваться и улучшать качество принимаемых решений. Такой подход обеспечивает возможность последовательного улучшения стратегии решения задач путем анализа обратной связи и внесения корректировок в процесс рассуждения.
Агентный подход TKG-Thinker обеспечивает динамическое взаимодействие с Временным Графом Знаний (Temporal Knowledge Graph), позволяя исследовать релевантную информацию в процессе работы. Вместо статического извлечения данных, система активно итерирует по графу, формируя цепочки рассуждений и уточняя запросы на основе полученных результатов. Это достигается путем последовательного анализа узлов и связей в графе, определения наиболее перспективных направлений исследования и адаптации стратегии поиска в зависимости от контекста и доступной информации. Такой подход позволяет эффективно извлекать знания из сложной и динамично меняющейся структуры данных, представленной Временным Графом Знаний.
Архитектура TKG-Thinker использует в качестве основы большие языковые модели, такие как Llama3-8B-Instruct и Qwen2.5-7B-Instruct, что позволяет ей использовать предварительно обученное понимание языка. Эти модели прошли обучение на обширных текстовых корпусах, что обеспечивает им способность к эффективному анализу и генерации естественного языка, а также извлечению смысла из сложных запросов. Использование предварительно обученных моделей значительно сокращает необходимость в обучении с нуля и позволяет TKG-Thinker демонстрировать высокую производительность в задачах, связанных с пониманием и обработкой информации.
Предварительное обучение с учителем (Supervised Fine-Tuning) играет ключевую роль в инициализации TKG-Thinker, обеспечивая заданное начальное поведение системы. Этот процесс предполагает обучение модели на размеченном наборе данных, содержащем примеры желаемых рассуждений и действий в контексте Темпорального Графа Знаний. Использование размеченных данных позволяет TKG-Thinker быстрее адаптироваться к специфике задачи и генерировать более релевантные и точные ответы на начальном этапе работы, сокращая время, необходимое для достижения оптимальной производительности в процессе взаимодействия с графом знаний и выполнения поставленных задач.
![Результаты показывают, что TKG-Thinker, обученный с использованием SFT+GRPO [♣] или SFT+PPO [♠], превосходит базовые модели по метрике Hits@1 на наборах данных MULTITQ и CronQuestions, демонстрируя лучшие и вторые лучшие результаты, выделенные полужирным и подчеркнутым шрифтом соответственно.](https://arxiv.org/html/2602.05818v1/x14.png)
Обучение с Подкреплением для Эволюционирующих Рассуждений
Обучение модели TKG-Thinker осуществляется посредством обучения с подкреплением, что позволяет оптимизировать её поведение при рассуждениях путём взаимодействия с Knowledge Graph (TKG). В процессе обучения агент, представляющий собой TKG-Thinker, выполняет последовательность действий в среде TKG, получая вознаграждение за каждое действие. Это вознаграждение формируется на основе многоцелевой функции, учитывающей корректность ответа, формат выдаваемой информации и релевантность извлечённых данных. Подобный подход позволяет модели адаптировать свою стратегию рассуждений, улучшая качество и обоснованность генерируемых ответов на сложные вопросы.
Для усовершенствования стратегии поведения агента TKG-Thinker используются алгоритмы обучения с подкреплением Proximal Policy Optimization (PPO) и Group Relative Policy Optimization (GRPO). PPO обеспечивает стабильность обучения за счет ограничения изменений в политике на каждом шаге, предотвращая резкие ухудшения производительности. GRPO, в свою очередь, позволяет эффективно обучать агента в задачах, требующих координации нескольких целей, путем группировки схожих действий и оптимизации политики относительно этих групп. Оба алгоритма используют градиентные методы для обновления параметров политики на основе собранных данных об опыте взаимодействия с Knowledge Graph (TKG).
Обучение модели TKG-Thinker осуществляется с использованием многоцелевой функции вознаграждения, включающей три основных компонента. Вознаграждение за результат (outcome reward) оценивает корректность и точность ответа. Вознаграждение за формат (format reward) стимулирует генерацию ответов в структурированном и читаемом виде. Вознаграждение за извлечение (retrieval reward) поощряет эффективное использование релевантной информации, полученной посредством поиска с использованием модели e5-base-v2, что способствует обоснованности и достоверности генерируемых ответов. Комбинирование этих трех компонентов позволяет оптимизировать модель для достижения как высокой точности, так и качественной структуры и обоснованности ответов.
Метод генерации с поиском подтверждающей информации (Retrieval-Augmented Generation) улучшает процесс рассуждений путем включения релевантных данных, полученных в результате поиска. В данной реализации используется модель e5-base-v2 для векторного представления запросов и документов, что позволяет эффективно находить наиболее подходящую информацию из базы знаний. Полученные векторы используются для поиска наиболее близких по смыслу документов, которые затем предоставляются модели в качестве контекста при генерации ответа. Это позволяет генерировать более обоснованные и точные ответы, основанные на конкретных фактах, а не только на внутренних знаниях модели.
Влияние и Валидация на TKGQA Бенчмарках
Система TKG-Thinker продемонстрировала передовые результаты в решении задач TKGQA, значительно превзойдя существующие аналоги. Данное достижение указывает на превосходство предложенного подхода к обработке сложных запросов, требующих анализа временных взаимосвязей. Способность системы эффективно оперировать знаниями и логически выстраивать цепочки рассуждений позволила добиться впечатляющей точности и эффективности в задачах, связанных с пониманием и ответом на вопросы о событиях, происходящих во времени. Результаты подтверждают, что TKG-Thinker представляет собой значительный шаг вперед в области временных рассуждений и обработки знаний.
Оценка работы системы на наборах данных, таких как MULTITQ и CronQuestions, подтверждает её способность успешно решать сложные задачи, связанные с временными отношениями. Эти наборы данных специально разработаны для проверки способности моделей понимать и рассуждать о событиях, упорядоченных во времени, что требует глубокого анализа контекста и умения делать логические выводы о последовательности и длительности событий. Результаты показывают, что система эффективно справляется с вопросами, требующими понимания не только самих событий, но и их взаимосвязей во времени, что свидетельствует о значительном прогрессе в области временного рассуждения и обработки естественного языка.
Оценка точности модели TKG-Thinker, проведенная на наборах данных MULTITQ и CronQuestions, продемонстрировала впечатляющие результаты по метрике Hits@1. Модель достигла 82.1% точности на MULTITQ и 78.5% на CronQuestions, что значительно превосходит показатели предыдущих передовых решений, как показано в Таблице 1. Данный результат указывает на высокую способность TKG-Thinker корректно отвечать на сложные вопросы, требующие понимания временных связей и логических зависимостей, и подтверждает эффективность предложенного подхода к построению агентов для работы с временными знаниями.
Полученные результаты демонстрируют значительный потенциал агентных фреймворков и обучения с подкреплением в области развития способностей к временному рассуждению. Достигнутая эффективность в решении сложных задач, требующих понимания последовательности событий и их взаимосвязей, указывает на перспективность данного подхода для создания интеллектуальных систем, способных к глубокому анализу временных данных. Способность к адаптации и обучению на основе обратной связи позволяет агентным системам постепенно улучшать свои навыки в понимании и интерпретации временных отношений, открывая новые возможности для автоматизации процессов, требующих анализа исторических данных и прогнозирования будущих событий. Таким образом, комбинация агентных технологий и обучения с подкреплением представляется ключевым направлением для дальнейшего развития искусственного интеллекта в области временного рассуждения.
Будущие Направления: К Адаптивному Рассуждению
Дальнейшие исследования сосредоточены на повышении способности TKG-Thinker адаптироваться к новым и постоянно меняющимся графам знаний. В динамичном мире информация непрерывно обновляется и дополняется, поэтому критически важно, чтобы система могла не просто обрабатывать статические данные, но и эффективно интегрировать новые факты и связи. Разработчики планируют внедрить механизмы, позволяющие TKG-Thinker самостоятельно обнаруживать изменения в графе знаний, перестраивать свои внутренние представления и корректировать стратегии рассуждений, обеспечивая тем самым актуальность и надежность принимаемых решений. Такая адаптивность позволит системе успешно функционировать в условиях неопределенности и неполноты информации, приближая её к уровню человеческого мышления.
Дальнейшее повышение эффективности рассуждений в системах, подобных TKG-Thinker, напрямую связано с разработкой более сложных функций вознаграждения и алгоритмов обучения с подкреплением. Исследователи стремятся выйти за рамки простых метрик правильности, вводя нюансированные оценки, учитывающие не только конечный результат, но и процесс рассуждения — его логичность, полноту и креативность. Внедрение алгоритмов, способных к самообучению и адаптации стратегий рассуждений на основе получаемой обратной связи, позволит системе самостоятельно оптимизировать процесс поиска решений, избегать логических ошибок и эффективно использовать доступные знания. Такой подход открывает перспективы для создания искусственного интеллекта, способного к гибкому и адаптивному мышлению в сложных и динамично меняющихся условиях, что особенно важно для решения реальных задач, требующих не только правильного ответа, но и обоснованного и понятного хода мыслей.
Исследования направлены на расширение возможностей TKG-Thinker посредством интеграции внешних источников знаний и мультимодальной информации. Включение данных из различных баз знаний, текстовых корпусов и, что особенно важно, нетекстовых форматов, таких как изображения и аудиозаписи, позволит системе формировать более полное и контекстуально-обогащенное представление о предметной области. Это, в свою очередь, приведет к повышению точности и надежности процесса рассуждений, а также позволит TKG-Thinker оперировать с более сложными и неоднозначными ситуациями, приближая искусственный интеллект к пониманию мира, аналогичному человеческому.
Представленная работа открывает многообещающие перспективы для создания искусственного интеллекта, способного эффективно рассуждать в условиях постоянно меняющегося мира. Возможность адаптации к новым знаниям и динамичным ситуациям является ключевым шагом к созданию действительно интеллектуальных систем, которые смогут не просто обрабатывать информацию, но и понимать её контекст и последствия. Развитие подобных технологий позволит создавать ИИ, способные решать сложные задачи в реальном времени, принимать обоснованные решения в неопределенных условиях и успешно взаимодействовать с окружающей средой, что особенно важно для таких областей, как автономные системы, робототехника и интеллектуальный анализ данных. В конечном итоге, подобный подход к разработке ИИ способствует созданию систем, которые не просто имитируют интеллект, но и демонстрируют способность к обучению, адаптации и эффективному решению проблем в динамичном мире.
Представленная работа демонстрирует стремление к созданию систем, способных не просто хранить знания, но и динамически рассуждать над ними во времени. Подход, реализованный в TKG-Thinker, подчеркивает важность адаптации и обучения в сложных условиях, что созвучно идеям о системах как об экосистемах, а не статичных конструкциях. Как однажды заметил Дональд Дэвис: «Любая сложная система, которая работает, работает благодаря неэффективности». Эта фраза отражает суть исследования — признание того, что полная предсказуемость и гарантии в реальных системах недостижимы. Вместо этого, TKG-Thinker фокусируется на обучении агента адаптироваться к изменяющимся данным и неопределенности временных графов знаний, что позволяет достичь впечатляющих результатов в решении сложных задач временного вопросно-ответного анализа.
Что дальше?
Представленная работа, подобно любому семени, прорастает не в готовый сад, а в запутанные заросли нерешенных вопросов. Автономный агент, оперирующий временными графами знаний, — это, безусловно, шаг вперед, но необходимо помнить: система — это не машина, это сад; и даже самый искусный садовник не может предвидеть каждую сорняк. Сложность временных данных заключается не только в их объеме, но и в их текучести — знание, как вода, меняет русло, и любая архитектура, претендующая на долговечность, должна учитывать эту изменчивость.
Устойчивость не в изоляции компонентов, а в их способности прощать ошибки друг друга. Текущие подходы к обучению с подкреплением часто фокусируются на максимизации немедленной награды, упуская из виду долгосрочные последствия. Следующим шагом видится разработка механизмов, позволяющих агенту не просто отвечать на вопросы, но и критически оценивать достоверность источников, выявлять противоречия и адаптироваться к меняющемуся контексту. Каждый архитектурный выбор — это пророчество о будущем сбое, и необходимо строить системы, способные к самовосстановлению и эволюции.
В конечном счете, истинный прогресс лежит не в создании все более сложных алгоритмов, а в понимании того, как знание формируется, распространяется и устаревает. Временные графы знаний — это лишь инструмент, отражающий реальность, но не заменяющий ее. Задача исследователей — не построить идеальную систему, а создать экосистему, способную к непрерывному обучению и адаптации.
Оригинал статьи: https://arxiv.org/pdf/2602.05818.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- HYPE ПРОГНОЗ. HYPE криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-08 10:32