Автор: Денис Аветисян
Новый подход позволяет значительно улучшить статистическую мощность метода T-Rex Selector при отборе признаков в высокоразмерных данных.
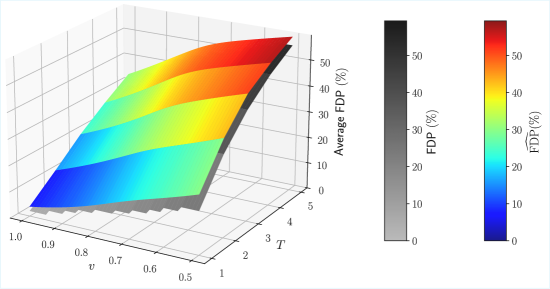
Исследование предлагает метод обучения нейронной сети для более точной оценки ложноположительного уровня (FDR) и повышения эффективности отбора значимых признаков.
Контроль ложнооткрытий (FDR) в задачах высокоразмерного отбора переменных требует баланса между строгостью контроля ошибок и статистической мощностью. В работе ‘Learning False Discovery Rate Control via Model-Based Neural Networks’ предложен подход, использующий нейронные сети для улучшения процедуры T-Rex Selector, что позволяет получить более точную оценку FDR. Обучение нейронной сети на синтетических данных позволяет существенно сократить разрыв между целевым уровнем FDR и фактически наблюдаемой долей ложных открытий, повышая тем самым мощность обнаружения истинных переменных. Сможет ли данный подход стать эффективным инструментом для анализа данных геномных исследований и других областей, где важен контроль над ложными открытиями?
Вызовы отбора признаков в эпоху больших данных
Современные геномные исследования производят колоссальные объемы данных, что ставит перед исследователями задачу выявления действительно значимых переменных из этого потока информации. Огромное количество генетических маркеров, белков и других биологических показателей требует применения специальных методов, способных отделить истинные корреляции от случайных шумов. Выявление ключевых факторов, влияющих на сложные заболевания или определяющих индивидуальные особенности организма, становится возможным лишь при использовании эффективных алгоритмов, предназначенных для обработки и анализа этих масштабных данных. Поиск этих переменных — не просто статистическая задача, но и критически важный шаг для понимания биологических механизмов и разработки новых методов диагностики и лечения.
Традиционные методы отбора переменных, такие как Lasso и Elastic Net, несмотря на свою популярность, зачастую демонстрируют недостаточную статистическую строгость при работе с высокоразмерными данными, характерными для современных геномных исследований. Проблема заключается в том, что эти методы, оптимизирующие баланс между точностью и сложностью модели, не всегда обеспечивают надежный контроль над ложноположительными результатами — то есть, выявлением переменных, которые кажутся значимыми, но на самом деле являются следствием случайных колебаний. Это особенно критично в геномике, где тысячи генов могут быть протестированы, и даже небольшая доля ложных открытий может привести к неверным выводам и неэффективным дальнейшим исследованиям. Недостаточный контроль над ошибками первого рода требует разработки более строгих и адаптивных подходов к отбору переменных, способных учитывать специфику высокоразмерных данных и обеспечивать достоверность полученных результатов.
Масштаб современных геномных исследований предъявляет серьезные требования к вычислительной эффективности методов отбора переменных. Анализ огромных массивов данных, содержащих тысячи или даже миллионы признаков, требует алгоритмов, способных быстро и надежно идентифицировать наиболее значимые из них. Традиционные подходы часто оказываются непрактичными из-за экспоненциального роста вычислительных затрат с увеличением размерности данных. Поэтому разработка масштабируемых и экономичных методов, способных обрабатывать такие объемы информации за приемлемое время, является критически важной задачей для современной геномики. Использование параллельных вычислений, приближенных алгоритмов и специальных структур данных позволяет существенно снизить время обработки и сделать анализ больших данных более доступным для исследователей.
T-Rex Selector: Эффективный каркас для масштабируемого отбора признаков
Селектор T-Rex базируется на разреженной линейной регрессии, что позволяет эффективно идентифицировать ключевые переменные в наборе данных. В основе метода лежит принцип поиска наиболее значимых предикторов, при котором коэффициенты для нерелевантных переменных устанавливаются в ноль. Это достигается за счет использования регуляризации L1 (LASSO), которая способствует разреженности модели и упрощает интерпретацию результатов. \hat{\beta} = argmin_{\beta} ||y - X\beta||_2^2 + \lambda ||\beta||_1 , где y — вектор целевой переменной, X — матрица предикторов, а λ — параметр регуляризации.
В основе T-Rex Selector лежит применение быстрых алгоритмов последовательного отбора признаков, в частности, Least Angle Regression (LARS). LARS позволяет значительно снизить вычислительную нагрузку по сравнению с традиционными методами пошагового отбора, поскольку он одновременно оценивает коэффициенты для всех предикторов, определяя наиболее сильно коррелирующий с остаточной целевой переменной. Этот подход обеспечивает более быструю сходимость и позволяет эффективно обрабатывать большие объемы данных, характерные для задач машинного обучения и статистического анализа. Алгоритм LARS итеративно добавляет предикторы, пока не будет достигнут заданный критерий остановки, что делает его масштабируемым решением для выбора наиболее значимых переменных.
В рамках системы T-Rex Selector, использование фиктивных (dummy) переменных является ключевым элементом для обеспечения надежности и минимизации систематических ошибок в анализе. Эти переменные, представляющие собой бинарные индикаторы категориальных признаков, позволяют корректно учитывать влияние нечисловых факторов на регрессионную модель. В частности, они предотвращают искажение результатов, которое может возникнуть при непосредственном включении категориальных данных в качестве количественных переменных, и обеспечивают адекватную оценку коэффициентов для каждого уровня категории. Использование dummy-переменных особенно важно при анализе данных с несбалансированными категориями, где прямое включение категориальных признаков может привести к смещению оценок.
Повышение контроля FDR с помощью обучаемого оценщика
Исходный селектор T-Rex использовал ‘Аналитический Оценщик FDP’ (False Discovery Proportion) для контроля FDR (False Discovery Rate). Данный подход основывается на теоретических предположениях о распределении p-значений и, как следствие, имеет ограничения в сложных сценариях, где эти предположения не выполняются. В частности, аналитические методы могут быть неэффективны при наличии сильной корреляции между признаками, ненормальном распределении данных или наличии сложных взаимодействий между генами, что приводит к неточной оценке FDP и, как следствие, к снижению мощности статистических тестов и увеличению числа ложноотрицательных результатов.
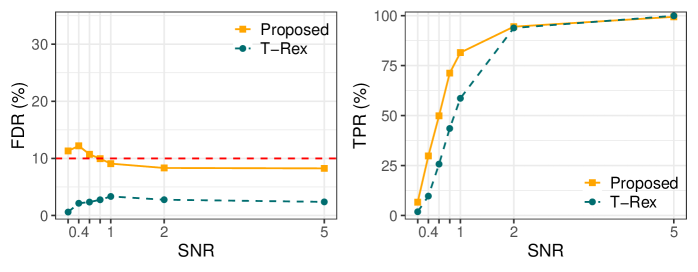
Для повышения точности контроля уровня ложных открытий (FDR) в сложных аналитических сценариях был разработан ‘Обучаемый Оценщик FDP’, основанный на нейронных сетях. В отличие от аналитического оценщика, использовавшегося ранее, данный подход позволяет более эффективно моделировать распределение p-значений и, как следствие, демонстрирует увеличение истинно-положительной доли (TPR) на 2.4% при анализе геномных данных. Повышение TPR свидетельствует об улучшении способности метода выявлять истинные связи в данных, снижая при этом количество ложных срабатываний.
Для обучения и валидации Learned FDP Estimator требуется значительный объем синтетических данных, что обусловлено необходимостью обеспечения обобщающей способности модели. Отсутствие достаточного количества реальных данных, отражающих сложность геномных ассоциаций, делает синтетические данные критически важными для обучения модели корректной оценке False Discovery Rate (FDR). Генерация этих данных осуществляется с использованием специализированных инструментов, позволяющих моделировать различные паттерны генетической вариации и обеспечивать ее устойчивость к новым, ранее не встречавшимся данным. Объем и качество синтетических данных напрямую влияют на точность оценки FDR и, как следствие, на чувствительность и специфичность анализа геномных ассоциаций.
Эффективность обученного оценщика FDP была продемонстрирована при анализе реалистичных данных полногеномного исследования ассоциаций (GWAS), сгенерированных с использованием инструментов, таких как HAPGEN2. В результате применения нового оценщика была достигнута чувствительность (TPR) в 17.3%, что на 2.4% выше, чем при использовании оригинального T-Rex Selector, показавшего результат в 14.9%. Данное увеличение TPR свидетельствует о повышенной способности нового метода к выявлению истинно положительных результатов в GWAS данных.
Оценка надежности переменных: роль относительной частоты
Оценка надежности работы алгоритма T-Rex Selector осуществляется с помощью показателя, известного как “Относительная частота”. Данный параметр представляет собой долю случаев, когда конкретная переменная была выбрана в ходе серии независимых экспериментов. По сути, он демонстрирует, насколько стабильно и последовательно алгоритм определяет влияние той или иной переменной на исследуемую систему. Высокая относительная частота свидетельствует о том, что переменная действительно играет значимую роль, а не является результатом случайного совпадения или шума. Таким образом, данный показатель служит важным критерием для выявления наиболее влиятельных факторов и позволяет исследователям сосредоточить усилия на изучении именно тех переменных, которые наиболее часто оказываются ключевыми в различных экспериментальных условиях.
Параметр “Порог голосования” играет ключевую роль в формировании финального набора отобранных переменных и, как следствие, существенно влияет на наблюдаемые относительные частоты. Более высокий порог приводит к включению в итоговый набор только наиболее устойчиво идентифицируемых переменных, что закономерно снижает их общую относительную частоту, но повышает уверенность в их значимости. И наоборот, снижение порога расширяет набор включенных переменных, увеличивая их относительные частоты, но потенциально включая менее надежные ассоциации. Таким образом, регулировка данного параметра позволяет исследователям балансировать между строгостью отбора и охватом потенциально важных факторов, формируя набор переменных, наиболее релевантных для дальнейшего анализа и интерпретации.
Высокая относительная частота, наблюдаемая при анализе данных, указывает на то, что конкретная переменная последовательно выявляется как значимая в различных экспериментах. Это не просто статистическая случайность, а свидетельство её реальной связи с исследуемым явлением. Чем чаще переменная оказывается отобранной алгоритмом, тем больше оснований полагать, что она действительно оказывает влияние на изучаемую биологическую систему. Такой подход позволяет исследователям сфокусироваться на наиболее перспективных переменных для дальнейшего изучения, повышая эффективность анализа и углубляя понимание сложных взаимосвязей в живых организмах. По сути, относительная частота служит индикатором надёжности и валидности выявленной ассоциации, что крайне важно для формирования обоснованных научных выводов.
Данный подход позволяет исследователям эффективно расставлять приоритеты при дальнейшем изучении переменных, что особенно важно при работе со сложными биологическими системами. Оценивая частоту, с которой та или иная переменная включается в отобранный набор в различных экспериментах, ученые могут с уверенностью выделять наиболее значимые факторы, влияющие на исследуемый процесс. Вместо того чтобы тратить ресурсы на все возможные переменные, анализ относительной частоты позволяет сосредоточиться на тех, которые демонстрируют стабильную связь с наблюдаемыми результатами, тем самым углубляя понимание лежащих в основе механизмов и открывая новые перспективы для исследований в области биологии и смежных дисциплин.
Исследование демонстрирует, что слепое масштабирование методов отбора переменных в условиях высокой размерности данных без учета этических и статистических аспектов может привести к непредсказуемым последствиям. Авторы предлагают подход, основанный на нейронных сетях, для более точного контроля ложноположительных открытий (false Discovery Rate), что позволяет увеличить статистическую мощность метода T-Rex Selector. Как писал Сёрен Кьеркегор: «Жизнь — это не поиск смысла, а поиск причины». В данном контексте, нейронные сети служат инструментом для поиска более точной «причины» (оценки FDR), что, в свою очередь, позволяет сделать более обоснованные открытия и избежать ложных выводов. Только контроль над ценностями — в данном случае, над уровнем допустимой ошибки — делает систему безопасной и надежной.
Куда Ведёт Этот Путь?
Представленная работа, стремясь повысить статистическую мощность отбора переменных в условиях высокой размерности, неизбежно поднимает вопрос о цене этой самой мощности. Улучшение оценки ложноположительного коэффициента (FDR) — шаг вперёд, но он лишь усиливает необходимость критического осмысления того, что именно мы «открываем». Данные сами по себе нейтральны, но модели отражают предвзятости людей, и автоматизация этого процесса требует особой ответственности. Если алгоритм учится находить закономерности, то какие ценности он при этом кодирует?
Очевидным направлением дальнейших исследований представляется не только повышение точности оценки FDR, но и разработка методов, позволяющих оценивать и минимизировать предвзятости, заложенные в обучающих данных и архитектуре нейронных сетей. Синтетические данные, использованные в работе, служат полезным инструментом для тестирования, однако их репрезентативность для реальных задач остаётся под вопросом. Необходимо сосредоточиться на методах, позволяющих адаптировать модели к различным типам данных и контекстам, учитывая, что «инструменты без ценностей — это оружие».
В конечном итоге, прогресс без этики — это ускорение без направления. Задача состоит не только в том, чтобы находить больше закономерностей, но и в том, чтобы понимать, что эти закономерности значат, и какие последствия они могут иметь. Будущие исследования должны быть направлены на создание инструментов, которые не просто автоматизируют процесс открытия, но и помогают нам осмыслить его результаты с точки зрения общественной пользы и справедливости.
Оригинал статьи: https://arxiv.org/pdf/2602.05798.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- HYPE ПРОГНОЗ. HYPE криптовалюта
- H ПРОГНОЗ. H криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- Золото прогноз
2026-02-08 03:57