Автор: Денис Аветисян
Новый алгоритм обучения с подкреплением помогает преодолеть проблему сужения вариантов ответа в больших языковых моделях, улучшая их способность к логическому мышлению.
Предложен алгоритм ProGRPO, использующий взвешивание преимущества на основе оценок уверенности для повышения разнообразия и стабильности рассуждений в больших языковых моделях.
Несмотря на успехи обучения с подкреплением в повышении рассудительных способностей больших языковых моделей, стандартные методы оптимизации часто страдают от коллапса энтропии, ограничивая разнообразие генерируемых ответов. В статье ‘Back to Basics: Revisiting Exploration in Reinforcement Learning for LLM Reasoning via Generative Probabilities’ предложен новый алгоритм ProGRPO, который решает эту проблему путем перевзвешивания функции преимущества на основе оценок уверенности, тем самым стимулируя исследование альтернативных цепочек рассуждений. Проведенные эксперименты на моделях Qwen2.5 и DeepSeek показали, что ProGRPO значительно увеличивает энтропию и улучшает точность, обеспечивая более сбалансированное сочетание исследования и эксплуатации. Сможет ли этот подход стать основой для создания более надежных и креативных систем искусственного интеллекта, способных решать сложные задачи с высокой степенью уверенности?
Вызов глубокого рассуждения в больших языковых моделях
Несмотря на впечатляющую способность генерировать текст, большие языковые модели (БЯМ) зачастую испытывают трудности при решении задач, требующих последовательного, многошагового рассуждения. В отличие от человеческого мышления, где сложные проблемы разбиваются на более простые подзадачи, БЯМ склонны к ошибкам при построении длинных цепочек логических выводов. Это связано с тем, что модели обучаются предсказывать следующее слово в последовательности, а не с пониманием причинно-следственных связей и глубоким анализом информации. Следовательно, даже небольшая ошибка на одном из этапов рассуждения может привести к неверному конечному результату, что особенно заметно в задачах, требующих точного следования сложным правилам или применения специализированных знаний. Таким образом, хотя БЯМ и демонстрируют впечатляющие результаты в обработке языка, их способность к сложному рассуждению остается серьезным ограничением.
Традиционные методы обучения с подкреплением, применяемые к большим языковым моделям, сталкиваются с серьезными трудностями, обусловленными разреженностью вознаграждения и нестабильностью процесса обучения. Разреженность вознаграждения означает, что модель редко получает значимый сигнал обратной связи за свои действия, особенно в сложных задачах, требующих последовательности шагов для достижения цели. Это затрудняет определение, какие действия привели к успеху или неудаче. Нестабильность, в свою очередь, проявляется в колебаниях параметров модели в процессе обучения, что может привести к сходимости к субоптимальным решениям или даже к полному краху обучения. В результате, даже при правильно сформулированной задаче, модель может испытывать трудности с освоением сложных стратегий рассуждений, что ограничивает ее способность решать задачи, требующие логического мышления и планирования.
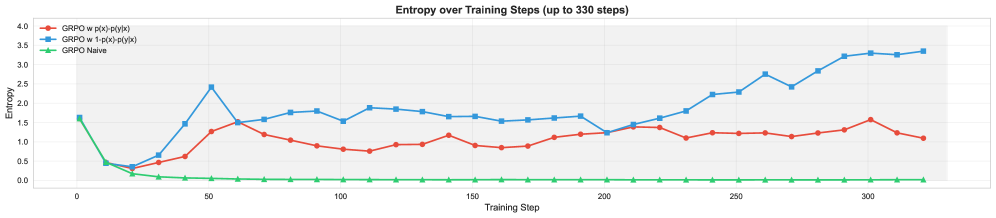
В процессе обучения больших языковых моделей часто наблюдается явление, известное как «энтропийный коллапс». Суть его заключается в том, что модель, стремясь максимизировать вознаграждение, постепенно сужает пространство поиска решений, фокусируясь на ограниченном наборе стратегий. Это происходит из-за того, что наиболее очевидные и быстро приносящие результат подходы становятся доминирующими, в то время как более сложные, требующие многоступенчатого рассуждения, игнорируются. В результате, способность модели к истинному рассуждению, требующему исследования различных вариантов и учета нюансов, существенно снижается, ограничиваясь лишь простыми и предсказуемыми ответами. Фактически, модель перестает «думать» в полном смысле этого слова, заменяя рассуждение на заучивание и воспроизведение шаблонных решений.
ProGRPO: Стабилизированная структура обучения с подкреплением
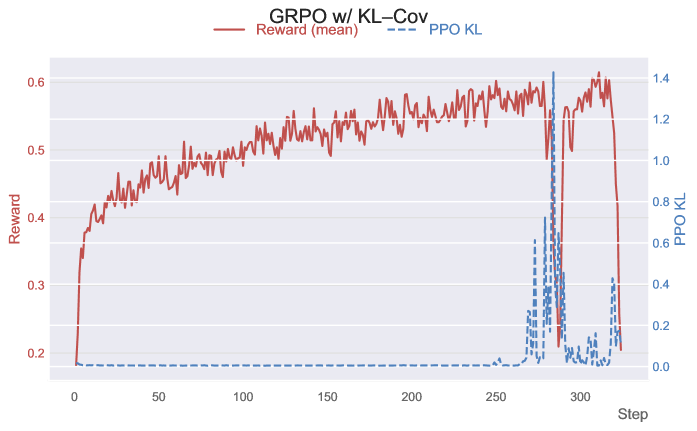
ProGRPO расширяет алгоритм Group Relative Policy Optimization (GRPO) за счет введения механизма перевзвешивания преимуществ (Advantage Re-weighting). Данный механизм позволяет модифицировать распределение оценок преимущества, что способствует повышению эффективности использования данных и стабилизации процесса обучения. В отличие от стандартного GRPO, где оценки преимущества используются напрямую, ProGRPO применяет весовые коэффициенты, основанные на вероятностных сигналах, для акцентирования наиболее значимых действий и уменьшения влияния шума, тем самым улучшая сходимость и общую производительность модели в задачах обучения с подкреплением.
Механизм перевзвешивания преимуществ (Advantage Re-weighting) в ProGRPO модифицирует распределение значений преимущества, используя сигналы вероятности, полученные в процессе обучения с подкреплением. Это достигается путем умножения значений преимущества на соответствующие вероятности, что позволяет алгоритму более эффективно использовать имеющиеся данные и повышает стабильность обучения. Перевзвешивание позволяет снизить дисперсию градиентов, что приводит к более быстрой сходимости и улучшению результатов обучения, особенно в задачах, где данные ограничены или шумны. В результате, алгоритм требует меньше выборок для достижения заданной производительности, что существенно повышает эффективность обучения.
Нормализация длины токенов с низкой вероятностью (Low-Probability Token Length Normalization) представляет собой метод уточнения процесса вычисления оценок достоверности в алгоритме GRPO. Вместо учета всех токенов при расчете, данный подход фокусируется на информативных токенах, определяемых по их низкой вероятности. Это позволяет снизить влияние менее значимых токенов на итоговую оценку достоверности, что приводит к более точной оценке и, как следствие, к повышению эффективности и стабильности обучения модели. Фактически, этот метод позволяет модели более эффективно использовать доступные данные, концентрируясь на наиболее важных элементах входной последовательности.
В основе ProGRPO лежит использование верифицируемых наград (Verifiable Rewards) для стабильного стимулирования более длинных путей рассуждений типа Chain-of-Thought. Механизм предполагает проверку каждого шага в процессе рассуждения на соответствие заданным критериям или внешним источникам знаний. При успешной верификации, каждому шагу присваивается награда, что поощряет алгоритм продолжать построение более сложных и последовательных цепочек рассуждений. Это позволяет модели не только достигать конечной цели, но и демонстрировать логическую последовательность в процессе решения задачи, повышая надежность и интерпретируемость результатов. Отсутствие верификации или обнаружение несоответствий приводит к снижению награды, препятствуя формированию нелогичных или ошибочных путей рассуждений.
Эмпирическая валидация и прирост производительности
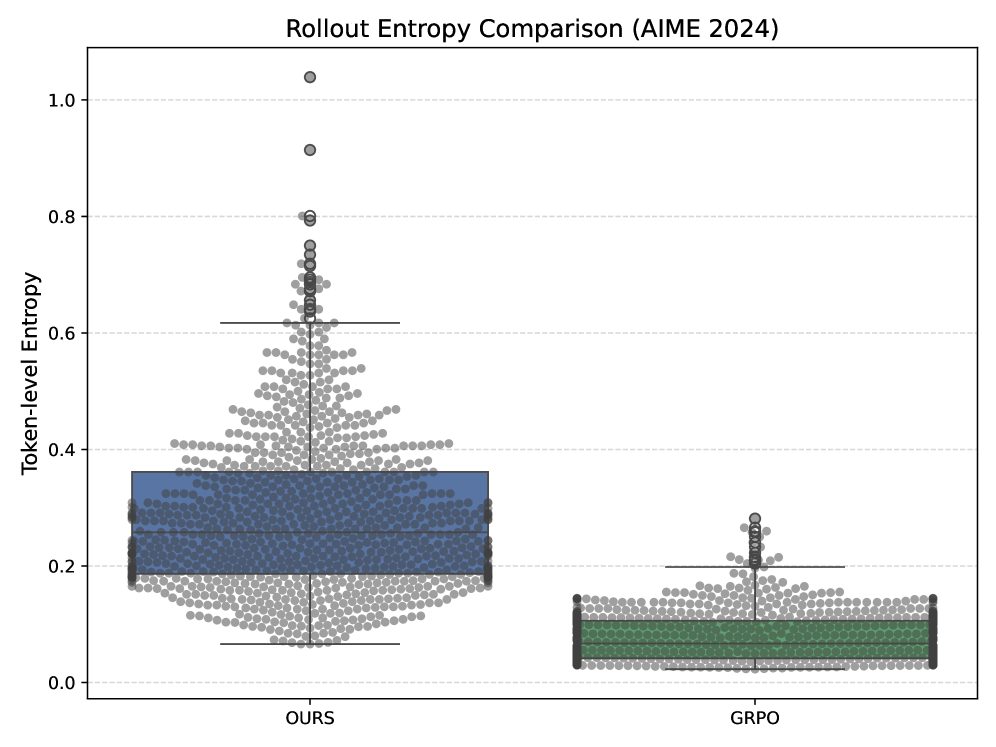
Проведенное тестирование ProGRPO на моделях Qwen2.5 и DeepSeek продемонстрировало стабильное повышение производительности. В ходе экспериментов было зафиксировано улучшение результатов по сравнению с базовыми алгоритмами, что подтверждает эффективность метода в различных сценариях генерации. Результаты показывают, что ProGRPO успешно адаптируется к особенностям архитектур Qwen2.5 и DeepSeek, обеспечивая более качественные и точные результаты генерации текста. Данное подтверждение эффективности на различных моделях является важным шагом в развитии алгоритмов обучения с подкреплением для задач генерации.
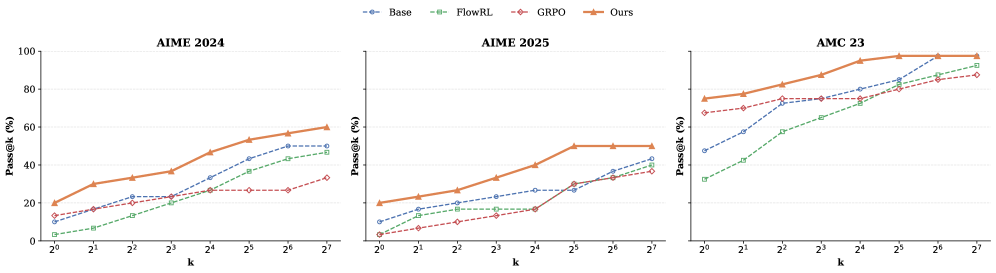
В ходе оценки ProGRPO с использованием метрик Pass@1 и Pass@32 было установлено, что данный метод превосходит базовые алгоритмы, такие как REINFORCE, Proximal Policy Optimization и FlowRL. На модели Qwen2.5-7B ProGRPO демонстрирует улучшение на 5.7% по метрике Pass@1 и на 13.9% по метрике Pass@32 в сравнении с алгоритмом GRPO. Данные результаты подтверждают эффективность ProGRPO в задачах генерации и оптимизации, а также его превосходство над существующими подходами в данной области.
Проведенные тесты демонстрируют повышенную устойчивость ProGRPO к данным, не представленным в обучающей выборке (OOD Robustness). В отличие от многих алгоритмов, эффективность ProGRPO не снижается при работе с ранее не встречавшимися распределениями данных, что подтверждается стабильными результатами оценки на новых наборах данных. Данное свойство критически важно для практического применения в реальных сценариях, где входные данные могут значительно отличаться от тех, на которых модель была обучена, обеспечивая надежность и предсказуемость результатов.
В ходе тестирования на модели Qwen2.5-7B, предложенный метод продемонстрировал улучшение метрики Pass@32 на 7.5% и метрики Pass@1 на 8.0% по сравнению с алгоритмом FlowRL. Данные результаты свидетельствуют о более высокой эффективности предложенного метода в задачах генерации корректных ответов, оцениваемых с использованием данных метрик, в сравнении с базовым алгоритмом FlowRL на указанной модели.
Метод ProGRPO использует подход обучения с подкреплением по учебной программе (Curriculum Reinforcement Learning), что позволяет ему более эффективно осваивать сложные задачи. Данный подход предполагает постепенное увеличение сложности обучающих примеров, начиная с простых и переходя к более сложным. Это позволяет модели быстрее сходиться к оптимальному решению и улучшает общую производительность. В частности, использование учебной программы позволяет ProGRPO превосходить базовые алгоритмы, такие как REINFORCE, Proximal Policy Optimization и FlowRL, демонстрируя значительное улучшение метрик Pass@1 и Pass@32 на моделях Qwen2.5 и DeepSeek.
Влияние и перспективы развития
Метод ProGRPO представляет собой действенное решение для стабилизации и улучшения обучения с подкреплением больших языковых моделей. В условиях, когда стандартные алгоритмы сталкиваются с проблемами нестабильности вознаграждения и коллапсом режимов, ProGRPO обеспечивает более устойчивый процесс обучения, позволяя моделям осваивать сложные стратегии и демонстрировать более нюансированное рассуждение. Этот подход позволяет эффективно преодолевать трудности, связанные с масштабированием обучения с подкреплением для крупных моделей, открывая путь к созданию более надежных и интеллектуальных систем искусственного интеллекта, способных решать задачи, требующие глубокого понимания и сложного анализа.
Устранение проблем нестабильности вознаграждения и коллапса мод открывает новые горизонты для развития сложных когнитивных способностей больших языковых моделей. Традиционные методы обучения с подкреплением часто сталкиваются с трудностями при работе со сложными задачами, приводя к непредсказуемому поведению и ограниченным возможностям. Благодаря стабилизации процесса обучения, ProGRPO позволяет моделям более эффективно исследовать пространство решений, избегая застревания в локальных оптимумах и позволяя им развивать более тонкие и детализированные стратегии рассуждения. Это, в свою очередь, способствует развитию моделей, способных к более глубокому пониманию и генерации более осмысленного и полезного контента, приближая искусственный интеллект к способности решать сложные задачи, требующие не только обработки информации, но и истинного понимания и критического мышления.
Предстоящие исследования направлены на расширение области применения ProGRPO за пределы языковых моделей, с целью изучения его эффективности в решении других сложных задач, требующих рассуждений, таких как планирование и решение проблем в робототехнике или анализ сложных данных. Особое внимание будет уделено интеграции ProGRPO с другими передовыми методами обучения, включая обучение с подкреплением с использованием имитаций и мета-обучение, что позволит создать гибридные системы, сочетающие в себе сильные стороны различных подходов. Такая интеграция может привести к созданию более устойчивых и эффективных алгоритмов, способных адаптироваться к изменяющимся условиям и решать задачи, которые в настоящее время недоступны существующим системам искусственного интеллекта.
Разработанная схема ProGRPO представляет собой значительный шаг к созданию более надежных и полезных систем искусственного интеллекта. Устраняя проблемы нестабильности обучения и коллапса режимов, она позволяет моделям осваивать сложные рассуждения и принимать обоснованные решения. Эта повышенная надежность критически важна для применения ИИ в чувствительных областях, таких как здравоохранение, финансы и автономные системы, где ошибки могут иметь серьезные последствия. По мере совершенствования алгоритмов и расширения масштабов применения, подобный подход к стабилизации обучения открывает путь к созданию ИИ, которому можно доверять в решении сложных задач и принятии важных решений, способствуя тем самым более безопасному и благоприятному взаимодействию человека и искусственного интеллекта.
Исследование, представленное в данной работе, демонстрирует стремление к созданию более устойчивых и разнообразных систем рассуждений в больших языковых моделях. Подход ProGRPO, фокусируясь на преодолении коллапса энтропии, подчёркивает важность взвешенного исследования пространства решений. Как отмечал Андрей Колмогоров: «Математика — это искусство невозможного». Эта фраза отражает суть представленного исследования: стремление к решению сложной задачи — обеспечению стабильного и разнообразного исследования в контексте обучения с подкреплением, где стандартные методы часто сталкиваются с трудностями. Успешная реализация ProGRPO, с акцентом на ревзвешивание функции преимущества, подтверждает, что элегантные решения возникают из простоты и ясности структуры, а не из усложнения системы.
Куда Далее?
Представленная работа, стремясь к преодолению коллапса энтропии в больших языковых моделях, демонстрирует, что кажущаяся простота перевзвешивания функции преимущества может принести ощутимые результаты. Однако, архитектура — это поведение системы во времени, а не схема на бумаге. Оптимизация одного узла неизбежно создаёт новые точки напряжения. Вопрос не в том, насколько успешно удалось “починить” исследование, а в том, какие новые ограничения и неявные предположения были введены этим решением.
Дальнейшие исследования должны быть направлены на понимание фундаментальных причин, лежащих в основе коллапса энтропии. Недостаточно просто бороться с симптомами; необходимо выявить корень проблемы, возможно, связанный с особенностями процесса обучения языковых моделей или с присущей им склонностью к генерации наиболее вероятных, но не обязательно наиболее полезных, ответов. Важно исследовать, как предложенный подход масштабируется на более сложные задачи и различные архитектуры моделей.
В конечном счете, поиск эффективных стратегий исследования в области обучения с подкреплением для больших языковых моделей требует не просто улучшения алгоритмов, а глубокого переосмысления самой парадигмы обучения. Элегантный дизайн рождается из простоты и ясности, но истинная ясность приходит только с пониманием взаимосвязи всех элементов системы. Следующим шагом должно стать рассмотрение исследования как неотъемлемой части процесса обучения, а не как отдельной задачи.
Оригинал статьи: https://arxiv.org/pdf/2602.05281.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-08 02:11