Автор: Денис Аветисян
Новое исследование выявляет, что современные генеративные модели, несмотря на впечатляющие результаты, часто демонстрируют непоследовательность и отсутствие причинно-следственной связи в своих «представлениях» о мире.
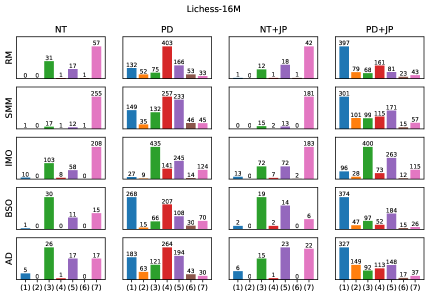
Предложен метод атак с использованием специальных последовательностей для проверки согласованности неявных моделей мира, реализованных в генеративных моделях последовательностей, на примере шахмат.
Несмотря на успехи генеративных последовательных моделей в имитации языковых структур, остается неясным, насколько полно они усваивают лежащие в их основе правила предметной области. В работе ‘Verification of the Implicit World Model in a Generative Model via Adversarial Sequences’ предложен метод антагонистической генерации последовательностей для проверки корректности неявной «мировой модели», усвоенной моделью, на примере шахмат. Полученные результаты демонстрируют, что даже модели, обученные на больших объемах данных, не обладают полной корректностью, а связь между состоянием доски и предсказаниями модели часто оказывается не причинной. Возможно ли разработать более надежные методы обучения, позволяющие генеративным моделям действительно понимать и воспроизводить сложные правила предметной области?
За гранью предсказания: Рождение генеративных последовательностей
Традиционное моделирование последовательностей долгое время было сосредоточено на предсказании — определении следующего элемента в данной последовательности. Однако, по мере усложнения решаемых задач, таких как создание текстов, генерация изображений или разработка новых молекул, простого предсказания становится недостаточно. Возникает потребность в моделях, способных не только угадывать, но и самостоятельно создавать новые, осмысленные последовательности, демонстрируя истинные генеративные способности. Это требует от моделей глубокого понимания структуры данных и способности к абстракции, что выходит за рамки простой экстраполяции известных паттернов и открывает путь к созданию действительно интеллектуальных систем.
Генеративные последовательные модели, такие как GPT-2 и LLaMA, открывают новые горизонты в понимании и создании контента. В отличие от традиционных моделей, ориентированных на предсказание следующего элемента в последовательности, эти архитектуры способны самостоятельно генерировать связные и осмысленные тексты, изображения или даже музыкальные композиции. Они не просто воспроизводят увиденное в обучающих данных, а учатся улавливать скрытые закономерности и взаимосвязи, позволяя создавать принципиально новые произведения. Такой подход к моделированию последовательностей позволяет решать задачи, требующие не только анализа, но и творческого подхода, от написания стихов и сценариев до создания реалистичных виртуальных миров и разработки инновационных дизайнерских решений.
Современные генеративные модели последовательностей, такие как GPT-2 и LLaMA, не просто предсказывают следующие элементы в ряду, но и формируют неявные представления об окружающем мире, фактически строя внутренние «модели мира» на основе обработанных данных. Этот процесс позволяет им улавливать сложные взаимосвязи и закономерности, скрытые в массивах информации, и использовать эти знания для генерации новых, когерентных и контекстуально релевантных последовательностей. Вместо простого запоминания шаблонов, модели учатся понимать основные принципы, управляющие данными, что позволяет им творчески адаптироваться к новым ситуациям и создавать оригинальный контент, имитирующий реальные процессы и явления.
Обучение генеративных последовательностных моделей опирается на ключевые принципы, такие как предсказание следующего токена и предсказание вероятностного распределения. В процессе обучения модель анализирует огромные объемы данных, стремясь не просто предсказать следующий элемент в последовательности, но и оценить вероятность каждого возможного элемента. Этот подход позволяет модели создавать не только правдоподобные, но и контекстуально релевантные последовательности. Фактически, задача предсказания вероятностей формирует внутреннее представление о структуре данных, позволяя модели генерировать последовательности, которые кажутся связными и осмысленными, а не просто случайным набором символов. Подобная методология лежит в основе способности современных моделей создавать текст, код и другие типы данных с высокой степенью когерентности и реалистичности.
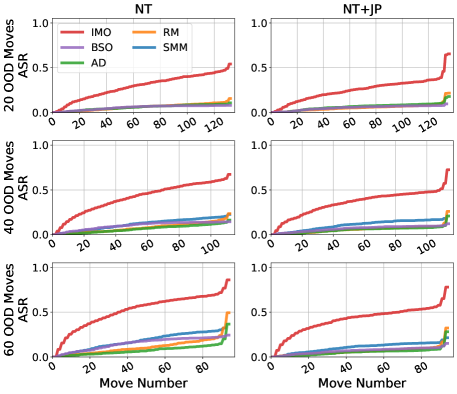
Испытание на прочность: Корректность и состязательное поколение
Критически важным свойством языковых моделей, генерирующих последовательности, является их корректность (Soundness) — способность последовательно выдавать валидные (допустимые) последовательности токенов в соответствии с заданными правилами. Данное свойство подразумевает, что модель не должна генерировать недопустимые или незаконные продолжения последовательности, даже при сложных или неопределенных входных данных. Обеспечение высокой корректности является необходимым условием для надежности и предсказуемости работы модели, особенно в критически важных приложениях, где недопустимые выходные данные могут привести к серьезным последствиям. Оценка корректности требует строгих методов тестирования, направленных на выявление и анализ случаев, когда модель нарушает правила генерации последовательностей.
Генерация состязательных последовательностей (Adversarial Sequence Generation) представляет собой эффективный метод для строгой проверки надёжности моделей, направленный на выявление их слабых мест путём принуждения к генерации невалидных выходных данных. Данный подход предполагает создание входных последовательностей, специально разработанных для максимизации вероятности получения недопустимого продолжения, что позволяет оценить устойчивость модели к преднамеренно провокационным данным и выявить потенциальные уязвимости в её логике генерации. Эффективность тестирования оценивается по показателю Attack Success Rate (ASR), отражающему процент случаев, когда модели генерируют невалидные выходные данные в ответ на состязательные входные данные.
Для оценки устойчивости моделей к генерации невалидных последовательностей используется методология, включающая так называемый “Illegal Move Oracle” (оракул нелегальных ходов). Данный инструмент позволяет находить входные данные, максимизирующие вероятность генерации невалидной (нелегальной) последовательности, что позволяет оценить надежность модели. Применение данного подхода, в частности, позволило достичь 100% Attack Success Rate (ASR) — то есть, гарантированно генерировать невалидные продолжения — против различных моделей, демонстрируя их уязвимость к специально подобранным входным данным.
Шахматы представляют собой идеальную тестовую среду для оценки способности моделей генерировать корректные последовательности, благодаря чётко определённым правилам и однозначному разграничению между допустимыми и недопустимыми ходами. Для представления ходов используется стандартная нотация UCI (Universal Chess Interface), обеспечивающая машиночитаемый формат и упрощающая автоматизированное тестирование. Эта нотация позволяет точно задавать начальную и конечную позиции фигур, что необходимо для оценки валидности генерируемых моделей продолжений игры и выявления потенциальных нарушений правил.
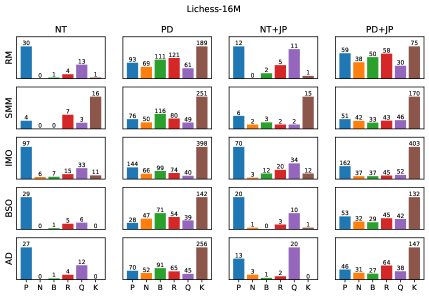
Стратегии декодирования и влияние данных: Путь к гармонии
Качество генерируемых последовательностей напрямую зависит от двух ключевых факторов: данных, на которых обучена модель, и используемой стратегии декодирования. Обучение на тщательно отобранных (curated) наборах данных, представляющих экспертную игру, может привести к высококачественным, но менее разнообразным результатам. Использование случайных (random) наборов данных, напротив, обеспечивает более широкое исследование пространства состояний, но может снизить общую когерентность генерируемых последовательностей. Стратегии декодирования, такие как Top-k Sampling и Top-p Sampling, позволяют балансировать между исследованием (exploration) и использованием (exploitation) полученных знаний, оказывая существенное влияние на разнообразие и связность генерируемых данных.
Обучение моделей может производиться на двух основных типах наборов данных: курированных (Curated Datasets) и случайных (Random Datasets). Курированные наборы данных состоят из партий, собранных на основе экспертной игры, что позволяет модели изучать и воспроизводить стратегии высокого уровня. Случайные наборы данных, напротив, содержат более широкий спектр возможных состояний и ходов, обеспечивая более полное исследование игрового пространства, но могут включать менее оптимальные или неэффективные последовательности действий. Выбор типа набора данных оказывает значительное влияние на характеристики модели, определяя баланс между воспроизведением известных стратегий и способностью к творческому поиску новых решений.
Несмотря на то, что модели демонстрируют высокий процент допустимых ходов, находясь в диапазоне от 94.65% до 99.98%, это не является гарантией наличия у них корректной внутренней модели мира. Высокий показатель допустимости ходов лишь подтверждает способность модели следовать синтаксическим правилам игры, но не отражает понимания стратегических последствий этих ходов или долгосрочного планирования. Модель может генерировать легальные, но бессмысленные или контрпродуктивные последовательности действий, поскольку оценка хода основывается на статистических закономерностях в данных обучения, а не на глубоком понимании игровой механики.
Стратегии декодирования, такие как Top-k Sampling и Top-p Sampling (также известная как Nucleus Sampling), регулируют баланс между исследованием (exploration) и использованием (exploitation) при генерации последовательностей. Top-k Sampling ограничивает выборку наиболее вероятными k токенами на каждом шаге, снижая вероятность генерации нерелевантных или нелогичных продолжений. Top-p Sampling, напротив, динамически выбирает минимальный набор токенов, сумма вероятностей которых превышает заданное значение p, позволяя модели исследовать более широкий спектр возможностей, сохраняя при этом когерентность. Комбинирование этих стратегий позволяет контролировать разнообразие и связность генерируемого текста, влияя на качество и полезность выходных данных.
Зондирование внутренних представлений: За пределами видимого
Для оценки истинного понимания модели необходимо выходить за рамки анализа её выходных данных и обращать внимание на внутренние представления, которые она формирует. Простого сопоставления входных и выходных сигналов недостаточно, поскольку модель может успешно выполнять задачи, не обладая при этом глубоким пониманием лежащих в их основе принципов. Изучение того, как информация кодируется и хранится внутри модели, позволяет получить представление о её способности к обобщению, рассуждению и адаптации к новым ситуациям. Понимание внутренней логики модели открывает возможность выявления её сильных и слабых сторон, а также разработки более эффективных методов обучения и улучшения её интеллектуальных возможностей. Таким образом, исследование внутренних представлений является ключевым шагом на пути к созданию действительно разумных систем искусственного интеллекта.
Метод зондирования состояния игрового поля предоставляет способ декодирования информации, заложенной во внутреннем представлении модели. Суть заключается в предсказании текущего состояния поля на основе анализа активаций нейронной сети — фактически, попытке “прочитать мысли” модели. Успешное предсказание свидетельствует о том, что модель не просто научилась сопоставлять входные данные с выходными, но и сформировала внутреннюю репрезентацию игрового мира, содержащую информацию о расположении объектов и их взаимосвязях. По сути, это позволяет оценить, насколько глубоко модель “понимает” игровую ситуацию, а не просто имитирует эффективную игру. Чем точнее модель предсказывает состояние поля, тем более полным и структурированным является её внутреннее представление, что указывает на наличие имплицитной модели мира.
Исследования показали, что высокая эффективность зонда, предсказывающего состояние игрового поля, не всегда свидетельствует о наличии у модели надежной внутренней репрезентации мира. Различия в степени соответствия между предсказаниями модели и фактическим состоянием мира (измеряемым, например, через IoU — Intersection over Union) в зависимости от метода обучения указывают на то, что модель может научиться «обманывать» зонд, выдавая корректные предсказания, не формируя при этом глубокого и устойчивого понимания окружающей среды. Иными словами, модель способна успешно проходить тесты зонда, не обладая при этом способностью к обобщению и адаптации в новых, незнакомых ситуациях. Это подчеркивает важность разработки более сложных и всесторонних методов оценки внутренних репрезентаций, выходящих за рамки простой проверки соответствия предсказаний и реальности.
Успешное зондирование внутренних представлений модели указывает на формирование ею неявной модели мира, способной к представлению и рассуждениям об окружающей среде. Это означает, что модель не просто оперирует входными данными для генерации ответов, но и создает внутреннюю репрезентацию, отражающую взаимосвязи между объектами и явлениями. Такая внутренняя модель позволяет модели предсказывать последствия действий, планировать стратегии и адаптироваться к изменяющимся условиям, демонстрируя способность к более глубокому пониманию, нежели просто статистическое сопоставление входных и выходных данных. В частности, если зондирование показывает, что модель может точно реконструировать состояние окружающей среды на основе своих внутренних представлений, это свидетельствует о наличии у нее структурированного и когерентного представления о мире.
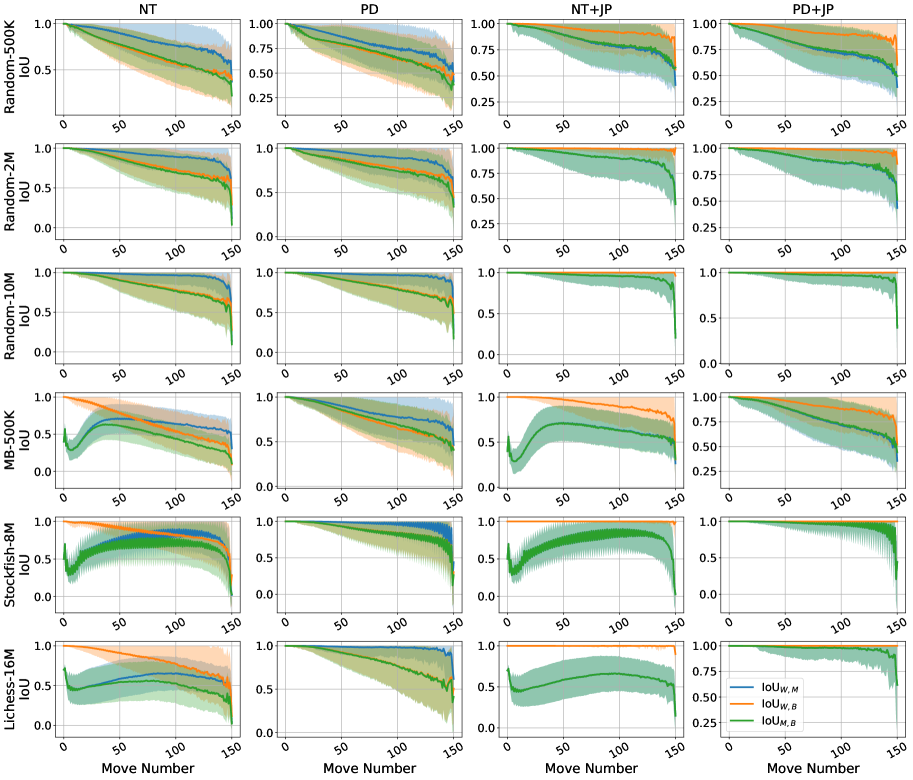
Исследование показывает, что современные генеративные модели, даже обученные на огромных объемах данных, часто демонстрируют отсутствие надежной внутренней модели мира. Авторы предлагают антагонистический подход к верификации этой модели, выявляя слабые места в причинно-следственных связях между состоянием доски и предсказаниями модели. В этом контексте уместна мысль Дональда Дэвиса: «Системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить.» Попытки насильно создать надежную модель, не учитывая сложность и взаимосвязанность данных, обречены на провал. Модель, как и экосистема, развивается органически, и лишь тщательная верификация, подобная предложенной в статье, способна выявить скрытые уязвимости и несоответствия.
Что Дальше?
Представленная работа обнажает хрупкость неявных моделей мира, выстроенных генеративными последовательными моделями. Очевидно, что обучение на больших объемах данных не гарантирует ни корректности, ни, что более важно, причинности. Модель может успешно предсказывать, но не понимать причинно-следственных связей, что делает её предсказания уязвимыми к тонко настроенным состязательным воздействиям. Архитектура, как способ откладывать хаос, здесь демонстрирует свою ограниченность.
Следующим шагом представляется не поиск более сложных архитектур, а глубокое осмысление самой природы моделирования. Вместо того, чтобы строить модели, следует стремиться к созданию экосистем, способных к самокоррекции и адаптации. Не существует лучших практик, есть лишь выжившие — и выживут те модели, которые смогут распознавать и нейтрализовывать состязательные воздействия, а не просто игнорировать их.
Порядок — это кеш между двумя сбоями. Предложенная методология состязательной проверки — лишь первый шаг к выявлению скрытых уязвимостей. Будущие исследования должны быть направлены на разработку более robustных и интерпретируемых моделей, способных к обоснованию своих предсказаний и обнаружению причинно-следственных связей, а не на простое запоминание паттернов. Иначе, все наши усилия сведутся к созданию всё более изощренных инструментов для откладывания неизбежного.
Оригинал статьи: https://arxiv.org/pdf/2602.05903.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-07 22:50