Автор: Денис Аветисян
Новый подход к обнаружению дипфейков в аудио использует сложные взаимосвязи между сигналами, значительно повышая точность и надежность.

В статье представлена HyperPotter — инновационная гиперграфовая нейронная сеть, эффективно захватывающая высокопорядковые синергетические взаимодействия в аудиосигналах для улучшения обнаружения подделок и повышения обобщающей способности.
Современные методы обнаружения аудио-дипфейков зачастую упускают из виду сложные взаимосвязи в сигналах, полагаясь на локальные характеристики. В работе ‘HyperPotter: Spell the Charm of High-Order Interactions in Audio Deepfake Detection’ предложен инновационный гиперграфовый подход, позволяющий эффективно моделировать взаимодействия высокого порядка в аудиоданных. Предложенная архитектура HyperPotter, использующая кластеризацию и прототипное обучение, демонстрирует значительное превосходство над существующими методами, обеспечивая прирост в 22.15% на 11 различных датасетах и 13.96% на сложных кросс-доменных задачах. Не откроет ли это новые перспективы для разработки более устойчивых и обобщающих систем обнаружения подделок в эпоху все более совершенных технологий генерации контента?
Появление угрозы аудио-дипфейков: математическая чистота под вопросом
Современные технологии искусственного интеллекта, известные как AIGC, достигли значительного прогресса в области синтеза речи, позволяя создавать голосовые образцы, практически неотличимые от человеческих. Этот прорыв открывает широкие возможности для злоумышленного использования: от создания фальшивых новостей и манипулирования общественным мнением до совершения мошеннических действий и дискредитации отдельных лиц. Способность генерировать реалистичную речь, имитирующую голоса конкретных людей, представляет серьезную угрозу для безопасности и доверия в цифровом пространстве, требуя разработки новых методов аутентификации и обнаружения подделок. Ранее сложные для воспроизведения нюансы речи теперь успешно моделируются алгоритмами, что делает выявление синтетической речи особенно сложной задачей.
В современном цифровом ландшафте, где искусственный интеллект способен создавать убедительно реалистичные аудиозаписи, способность отличать подлинные звуковые файлы от синтетических становится критически важной для обеспечения безопасности и поддержания доверия. Однако, существующие методы обнаружения, основанные на анализе спектральных характеристик и применении сверточных нейронных сетей, зачастую оказываются неэффективными против все более изощренных технологий синтеза речи. Это связано с тем, что продвинутые алгоритмы генерации аудио способны имитировать тончайшие нюансы человеческой речи, делая практически невозможным выявление искусственных артефактов традиционными подходами. Поэтому, возрастает необходимость в разработке новых, более совершенных методов аудио-криминалистики, способных эффективно противостоять угрозе аудио-дипфейков и защитить от потенциального злоупотребления.
Традиционные методы обнаружения аудио-дипфейков, такие как сверточные нейронные сети (CNN), всё чаще оказываются неэффективными в противостоянии современным технологиям синтеза речи. Эти сети, обученные выявлять грубые артефакты и несоответствия в аудиозаписях, испытывают затруднения при анализе сгенерированных голосов, которые имитируют человеческую речь с высокой точностью. Более сложные алгоритмы синтеза, использующие передовые модели машинного обучения, способны создавать аудио, лишенное тех явных признаков, которые ранее служили индикаторами подделки. В результате, CNN часто пропускают тонкие, но критически важные аномалии, оставляя возможность для распространения дезинформации и мошенничества, основанных на реалистичных, но фальшивых аудиозаписях. Это подчеркивает необходимость разработки принципиально новых подходов к аудио-форензике, способных выявлять более скрытые и сложные манипуляции.
Постоянно растущая сложность систем генерации искусственного контента (AIGC) требует принципиально новых подходов к аудио-форензике. Традиционные методы анализа, основанные на выявлении явных артефактов синтеза речи, становятся все менее эффективными по мере совершенствования алгоритмов. Современные модели AIGC способны создавать аудиозаписи, практически неотличимые от человеческой речи, что делает обнаружение подделок чрезвычайно сложной задачей. Необходимы инновационные методики, учитывающие тонкие, едва заметные особенности синтезированного звука, а также применение машинного обучения для выявления скрытых паттернов и аномалий, которые могут указывать на искусственное происхождение записи. Разработка таких инструментов имеет критическое значение для обеспечения безопасности и поддержания доверия в цифровом пространстве, где аутентичность аудиоинформации становится все более важной.
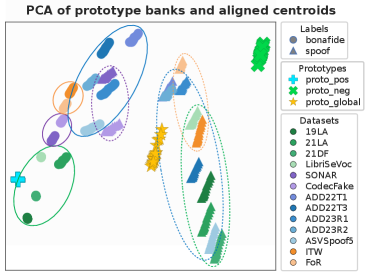
За пределами попарных связей: моделирование взаимодействий высшего порядка
Обнаружение тонких артефактов, возникающих при создании дипфейков аудио, требует анализа не только попарных взаимосвязей между признаками звука, но и более сложных взаимодействий — взаимодействий высшего порядка. Традиционные методы, рассматривающие признаки изолированно или попарно, часто оказываются неэффективными, поскольку синтезированные искажения могут проявляться как тонкие изменения в нелинейных комбинациях признаков. Например, взаимодействие между формантами, спектральной энергией и фазой сигнала может выявить аномалии, невидимые при анализе отдельных признаков. Именно учет этих сложных взаимосвязей позволяет более точно идентифицировать манипулированные аудиозаписи и отличать их от естественной речи.
Гиперграфы представляют собой обобщение традиционных графов, позволяющее моделировать связи между более чем двумя узлами одновременно. В то время как обычный граф описывает отношения между парами узлов посредством ребер, гиперграф использует гиперребра, которые могут соединять любое количество узлов. Это позволяет более точно представлять сложные взаимосвязи между аудиопризнаками, где взаимодействие трех и более признаков может быть критичным для выявления артефактов, созданных при синтезе речи. Формально, гиперграф определяется как G = (V, E), где V — множество вершин, а E — множество гиперребер, каждое из которых является подмножеством V. Использование гиперграфов позволяет представить зависимости, которые не могут быть уловлены стандартными графовыми моделями, обеспечивая более полное представление о взаимодействии аудиопризнаков.
O-информация представляет собой теоретический инструмент, позволяющий количественно оценить, раскрывают ли взаимодействия высшего порядка между признаками синергетическую или избыточную информацию. В основе лежит концепция, что взаимодействие нескольких признаков может либо предоставить информацию, которую нельзя получить, рассматривая каждый признак по отдельности (синергия), либо просто дублировать информацию, уже содержащуюся в отдельных признаках (избыточность). Математически, O-информация измеряет разницу между информацией, содержащейся в совместном распределении признаков, и информацией, предсказуемой на основе их маргинальных распределений. O(X;Y;Z) = I(X,Y,Z) - I(X,Y) - I(X,Z) - I(Y,Z), где I обозначает взаимную информацию. Положительное значение O-информации указывает на синергию, отрицательное — на избыточность, а нулевое — на независимость. В контексте обнаружения дипфейков, выявление синергетических взаимодействий позволяет выделить уникальные артефакты, возникающие при синтезе речи.
Основная цель анализа синергетических взаимодействий между аудиопризнаками заключается в выявлении уникальных артефактов, характерных для синтезированной речи. В отличие от традиционных методов, фокусирующихся на попарных связях, исследование синергии позволяет обнаружить нелинейные зависимости, которые могут быть неявны при рассмотрении отдельных признаков. Это особенно важно, поскольку алгоритмы синтеза речи часто стремятся скрыть артефакты на уровне отдельных параметров, однако не всегда способны эффективно моделировать сложные взаимодействия между ними. Выявление и акцентирование таких синергетических сигнатур позволяет разработать более эффективные методы обнаружения дипфейков, основанные на анализе не только индивидуальных признаков, но и их комбинированного влияния.
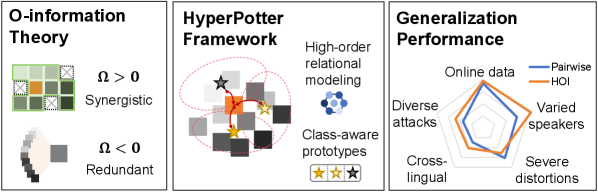
HyperPotter: гиперграфовая основа для обнаружения дипфейков
В основе системы HyperPotter лежит построение гиперграфов, представляющих взаимосвязи между спектральными и временными признаками аудиосигналов. В отличие от традиционных графов, где ребра соединяют только две вершины, гиперграфы позволяют соединять произвольное количество вершин одним гиперребром. В контексте анализа аудио, это позволяет моделировать сложные зависимости между несколькими признаками, извлеченными из различных временных и частотных областей сигнала. Например, одно гиперребро может объединять признаки, соответствующие конкретному музыкальному инструменту, определенному в определенный момент времени. Такое представление данных позволяет более эффективно захватывать и анализировать сложные аудиосцены, улучшая точность обнаружения и классификации звуковых событий.
Инициализация гиперребер в HyperPotter посредством обучения прототипам заключается в наделении каждого гиперребра представлением, учитывающим классовую принадлежность данных. Вместо случайной инициализации или использования усредненных значений, прототипы, представляющие типичные образцы каждого класса, используются для формирования начальных весов гиперребер. Это позволяет системе с самого начала учитывать различия между классами и формировать более выразительные связи между аудиопризнаками. В результате, формируемые гиперграфы обладают повышенной дискриминационной способностью, что способствует более точной классификации и обнаружению аномалий в аудиопотоке. Эффективность подхода заключается в том, что он направленно усиливает связи, релевантные для различения между классами, что снижает влияние шума и повышает общую производительность системы.
Для эффективного построения гиперребер в HyperPotter используется алгоритм нечеткой кластеризации C-средних (Fuzzy C-Means). В отличие от жесткой кластеризации, Fuzzy C-Means позволяет каждой точке данных принадлежать к нескольким кластерам с определенной степенью принадлежности, что особенно важно для представления сложных взаимосвязей в аудиоданных. Алгоритм определяет оптимальные центроиды кластеров и степень принадлежности каждой точки к каждому кластеру, минимизируя функцию стоимости, учитывающую как расстояние до центроидов, так и степень нечеткости кластеризации. Это позволяет более точно моделировать взаимосвязи между спектральными и временными признаками, формируя гиперребра, отражающие нелинейные зависимости и повышая дискриминационную способность модели.
В HyperPotter, механизм усиления реляционных артефактов (Relational Artifact Amplification) направлен на выделение и акцентирование информативных синергетических артефактов в гиперграфе. Это достигается путем анализа взаимосвязей между гиперребрами и узлами, с целью выявления комбинаций признаков, которые наиболее эффективно различают классы. Усиление происходит за счет увеличения веса этих взаимосвязей, что приводит к более выраженным различиям в представлении данных и, как следствие, к повышению точности обнаружения. В процессе используется анализ комбинаций спектральных и временных аудио-признаков для выявления паттернов, которые не были бы заметны при анализе отдельных признаков.
Подтверждение эффективности: превосходство над базовым уровнем
Wav2Vec2-AASIST представляет собой надежную базовую модель для обнаружения аудио-подделок, использующую передовые методы извлечения признаков и механизмы графового внимания. Данная модель базируется на архитектуре Wav2Vec2, дополненной алгоритмом Attention-based Audio Spoofing Identification System (AASIST), который позволяет моделировать зависимости между различными фрагментами аудиосигнала. Механизм графового внимания позволяет эффективно обрабатывать временные зависимости в аудиоданных, выделяя ключевые признаки, указывающие на манипуляции со звуком. Использование Wav2Vec2-AASIST в качестве базовой модели обеспечивает объективную отправную точку для оценки эффективности новых алгоритмов обнаружения аудио-подделок, благодаря её высокой производительности и способности к обобщению.
Результаты экспериментов показывают, что HyperPotter превосходит Wav2Vec2-AASIST, демонстрируя преимущества моделирования взаимодействий высокого порядка. В среднем, HyperPotter обеспечивает относительное улучшение в 15.32% по результатам оценки на 13 различных наборах данных. Данный прирост производительности указывает на эффективность предложенной архитектуры в задаче обнаружения аудио-подделок по сравнению с базовой моделью Wav2Vec2-AASIST.
Оценка производительности HyperPotter с использованием метрик Equal Error Rate (EER) и F1 Score последовательно демонстрирует его превосходство. Набор данных In-the-Wild показал EER в 5.72%, ASVspoof2021 DF — 1.78%, FoR — 3.89%, а ADD2022 Track3 — 11.31%. Эти результаты подтверждают более высокую точность и надежность HyperPotter в обнаружении аудио-подделок по сравнению с базовыми моделями, что делает его перспективным решением для задач аутентификации и защиты от мошенничества.
В основе Wav2Vec2-AASIST лежит мощное представление признаков, достигаемое за счет интеграции HS-GAL (High-order Self-Gated Attention Layers) и модели XLS-R (Cross-lingual Speech Representations). HS-GAL позволяют моделировать взаимодействия признаков более высокого порядка, что улучшает способность к выявлению тонких различий в аудиосигналах. XLS-R, предварительно обученная на большом объеме многоязычных данных, обеспечивает надежное кодирование речевых признаков, устойчивое к различным акцентам и условиям записи. Сочетание этих технологий формирует надежный базовый уровень для оценки эффективности новых методов обнаружения аудио-подделок, обеспечивая объективное сравнение и демонстрируя возможности современных подходов к представлению речевых данных.
Перспективы развития: к надежному и интерпретируемому обнаружению дипфейков
В дальнейшем планируется расширить сферу применения HyperPotter, включив анализ видеоматериалов, что позволит создать комплексную систему обнаружения дипфейков. Исследователи стремятся к разработке единого алгоритма, способного эффективно выявлять подделки не только в изображениях, но и в динамичных видеопотоках. Это потребует адаптации существующих методов к особенностям видеоданных, таким как временная последовательность кадров и сложные визуальные эффекты. Успешная реализация данного направления откроет возможности для более надежной защиты от дезинформации и манипуляций в цифровом пространстве, обеспечивая более точное и всестороннее обнаружение поддельных медиафайлов.
Исследование объяснимости решений, принимаемых системой HyperPotter, представляется критически важным для формирования доверия к её работе и понимания логики, лежащей в основе выявления дипфейков. Поскольку алгоритмы глубокого обучения часто воспринимаются как “черные ящики”, понимание того, какие именно признаки изображения или аудиосигнала влияют на классификацию, позволит не только оценить надёжность системы, но и выявить потенциальные уязвимости. Разработка методов визуализации и интерпретации внутренних механизмов HyperPotter, например, путём выделения областей изображения, наиболее важных для принятия решения, или анализа активаций нейронных сетей, необходима для обеспечения прозрачности и возможности аудита. Такой подход позволит не только убедиться в корректности работы системы, но и предоставить пользователям ценную информацию о характеристиках дипфейков, способствуя разработке более эффективных стратегий защиты от дезинформации.
Обеспечение устойчивости системы HyperPotter к преднамеренным искажениям, известным как adversarial атаки, является ключевой задачей для ее практического применения. Исследования показывают, что даже незначительные, специально разработанные изменения во входных данных могут привести к ошибочной классификации deepfake-контента, обманывая алгоритм. Для решения этой проблемы необходимо разработать методы, позволяющие HyperPotter распознавать и нейтрализовать подобные атаки, например, путем обучения модели на примерах, содержащих преднамеренные искажения. Повышение устойчивости к adversarial атакам не только гарантирует надежность системы в реальных условиях, но и способствует укреплению доверия к ней, поскольку демонстрирует способность противостоять целенаправленным попыткам обмана.
Перспективным направлением развития технологий обнаружения дипфейков является расширение области применения за пределы полной синтетической генерации аудио, с акцентом на выявление тонких манипуляций со звуком. Исследования показывают, что даже незначительные изменения в аудиозаписи, такие как едва заметные искажения или добавление нерелевантных шумов, могут свидетельствовать о подделке. Разработка алгоритмов, способных улавливать эти нюансы, позволит обнаруживать дипфейки, которые сложнее идентифицировать традиционными методами, и значительно повысит надежность систем защиты от дезинформации. Такой подход позволит не только выявлять полностью сгенерированные аудиозаписи, но и оценивать достоверность оригинального контента, подвергшегося незначительной обработке.
Исследование, представленное в данной работе, демонстрирует стремление к математической чистоте в решении задачи обнаружения аудио-дипфейков. Авторы, подобно тем, кто стремится к элегантности в коде, фокусируются на выявлении и использовании высокопорядковых взаимодействий в аудиосигналах. Как говорил Алан Тьюринг: «Иногда люди, которые кажутся сумасшедшими, — это те, кто видят вещи, которые другие не видят». В данном случае, применение гиперграфов позволяет увидеть синергетические связи, ускользающие от традиционных методов, и тем самым повысить обобщающую способность системы. Подход HyperPotter, раскрывающий реляционные артефакты, является свидетельством стремления к доказуемости и непротиворечивости алгоритма, а не просто к его работоспособности на тестовых примерах.
Что Дальше?
Представленная работа, хотя и демонстрирует потенциал гиперграфовых сетей в обнаружении аудио-дипфейков, оставляет ряд вопросов без ответа. Пусть N стремится к бесконечности — что останется устойчивым? Эффективность модели, несомненно, зависит от способности захватывать сложные синергетические взаимодействия, но остается неясным, насколько хорошо предложенный подход масштабируется до ещё более сложных и зашумленных сценариев. Ключевым ограничением остается зависимость от специфических характеристик обучающих данных — устойчивость к новым, ранее не встречавшимся артефактам, порожденным развивающимися алгоритмами генерации аудио, пока не доказана.
Перспективным направлением представляется исследование более глубокой интеграции принципов теории информации, в частности, O-информации, не только в архитектуру сети, но и в процесс обучения. Более того, необходимы работы, направленные на повышение интерпретируемости модели — понимание, какие именно высокопорядковые взаимодействия являются наиболее важными для обнаружения дипфейков, позволит создать более надежные и устойчивые системы.
В конечном счете, задача обнаружения аудио-дипфейков — это гонка вооружений. Каждый новый метод обнаружения будет провоцировать создание более совершенных алгоритмов генерации, способных обходить существующие защиты. Поэтому, ключевым приоритетом должно стать не просто улучшение точности, а разработка фундаментально новых подходов, основанных на глубоком понимании природы аудио-сигналов и принципов машинного обучения.
Оригинал статьи: https://arxiv.org/pdf/2602.05670.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- HYPE ПРОГНОЗ. HYPE криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-07 21:07