Автор: Денис Аветисян
В статье рассматриваются трудности, с которыми сталкиваются специалисты при обеспечении качества данных в системах машинного обучения в контексте растущих требований европейского законодательства.
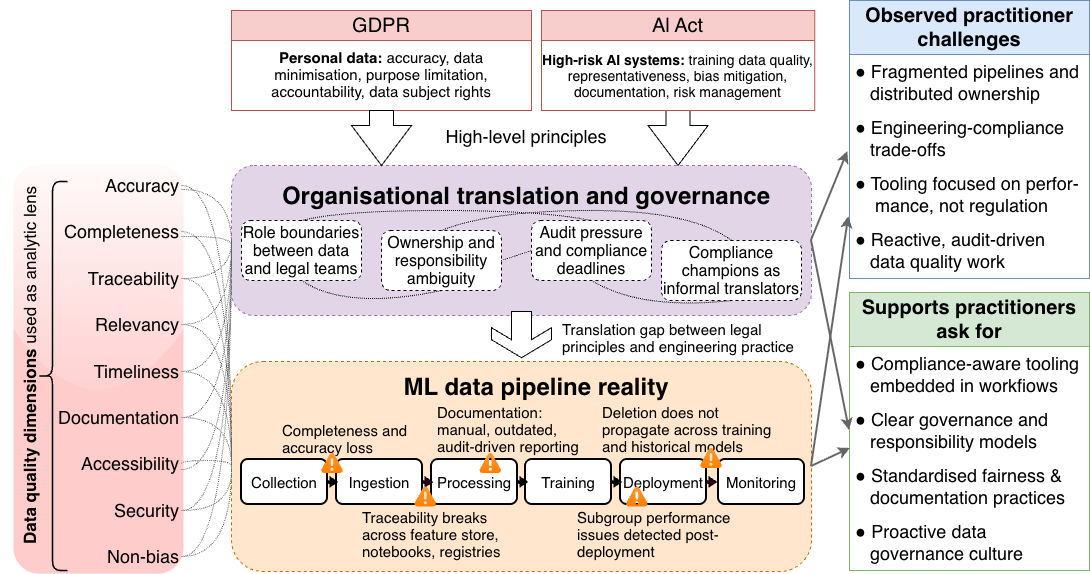
Анализ пробелов между технической реализацией и правовыми нормами GDPR и AI Act, а также необходимость улучшения взаимодействия и инфраструктуры для обеспечения соответствия.
Обеспечение качества данных в системах машинного обучения становится все более сложной задачей, особенно в контексте расширяющихся регуляторных требований. В своей работе ‘»Detective Work We Shouldn’t Have to Do»: Practitioner Challenges in Regulatory-Aligned Data Quality in Machine Learning Systems’, авторы исследуют проблемы, с которыми сталкиваются специалисты, стремящиеся соответствовать требованиям законодательства ЕС, включая GDPR и будущий AI Act. Исследование выявило существенный разрыв между принципами юридической ответственности и практическими рабочими процессами в разработке и эксплуатации систем машинного обучения. Какие шаги необходимо предпринять для создания эффективных механизмов управления данными, сочетающих в себе техническую надежность и юридическую прозрачность?
Нормативное давление: Данные под прицепом регуляторов
Современные системы машинного обучения неразрывно связаны с качеством используемых данных, однако практики работы с данными подвергаются всё более пристальному юридическому и этическому контролю. Ранее допустимые методы сбора, обработки и использования информации сегодня часто сталкиваются с требованиями новых нормативных актов, таких как GDPR и готовящийся Закон об искусственном интеллекте. Это обусловлено растущим пониманием потенциальных рисков, связанных с неправомерным использованием данных, включая вопросы конфиденциальности, предвзятости и дискриминации. В результате, организации вынуждены пересматривать свои подходы к управлению данными, внедряя более строгие меры контроля и обеспечивая соответствие новым стандартам, что, в свою очередь, требует значительных инвестиций и изменений в корпоративной культуре.
Современные нормативные акты, такие как Общий регламент по защите данных (GDPR) и разрабатываемый Закон об искусственном интеллекте (AI Act), оказывают кардинальное влияние на то, как организации собирают, обрабатывают и используют данные. Данное исследование представляет собой эмпирический анализ трудностей, с которыми сталкиваются специалисты на практике при соблюдении этих требований. В ходе работы были выявлены ключевые проблемы, связанные с интерпретацией новых норм, обеспечением прозрачности обработки данных и защитой прав субъектов. Полученные результаты демонстрируют, что соблюдение нормативных требований требует не только технологических решений, но и пересмотра внутренних процессов и повышения квалификации персонала, работающего с данными.
Несоблюдение новых регуляторных требований в области обработки данных, таких как Общий регламент по защите данных (GDPR) и разрабатываемый Закон об искусственном интеллекте, влечет за собой не только существенные финансовые санкции и штрафы, но и серьезный урон репутации организации. Потеря доверия со стороны клиентов и партнеров, вызванная утечкой данных или неправомерным использованием информации, может привести к долгосрочным негативным последствиям для бизнеса. Более того, постоянные юридические разбирательства и необходимость адаптации к меняющимся правилам существенно замедляют внедрение инноваций, отвлекая ресурсы и внимание от разработки новых продуктов и сервисов. В результате, организации, не уделяющие должного внимания вопросам соответствия нормативным требованиям, рискуют оказаться неконкурентоспособными на быстро развивающемся рынке.
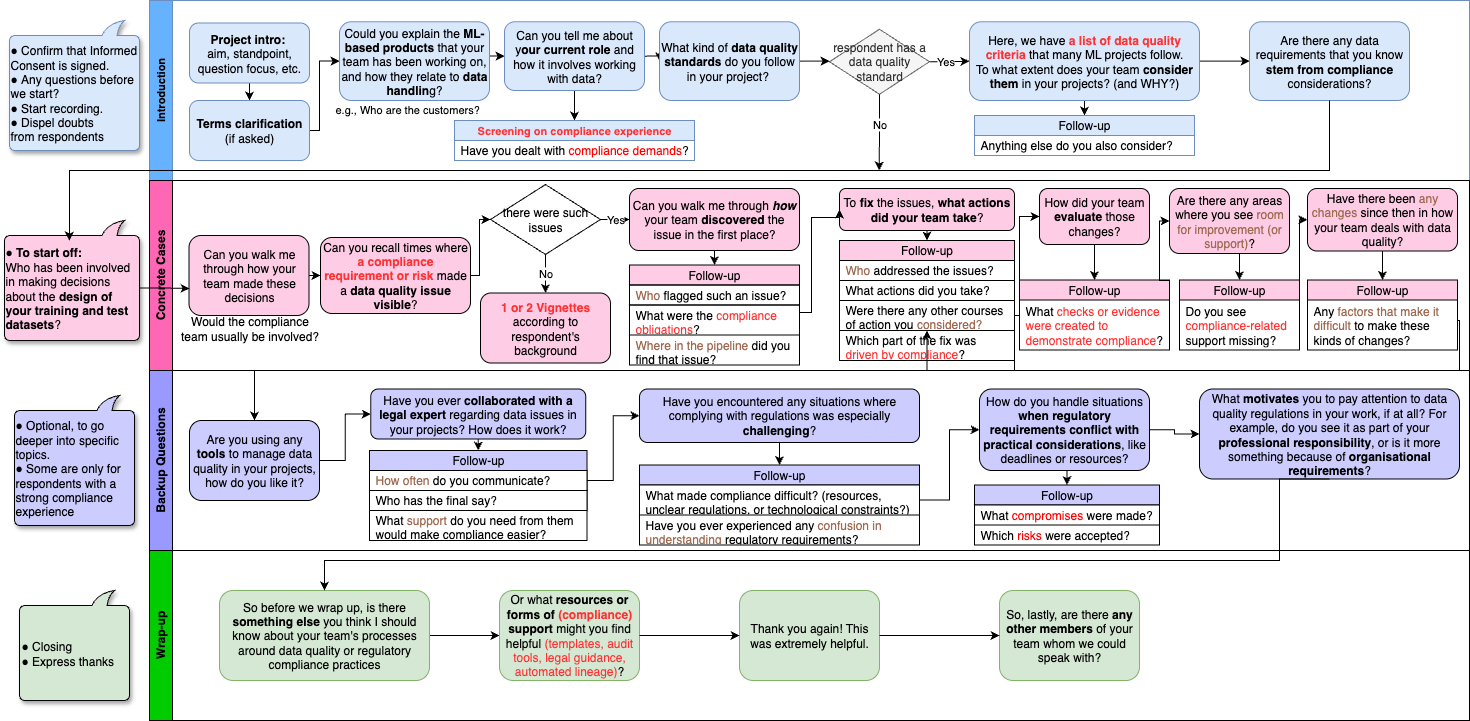
Управление данными: От колыбели до могилы
Надежное управление данными (Data Governance) подразумевает разработку и внедрение комплекса политик и процедур, обеспечивающих эффективное управление информационными активами на протяжении всего их жизненного цикла. Это включает в себя определение ролей и обязанностей, установление стандартов качества данных, обеспечение соответствия нормативным требованиям и регламентирование процессов доступа, использования и защиты данных. Эффективное управление данными охватывает все этапы — от сбора и хранения до обработки, анализа, архивирования и, при необходимости, удаления данных, гарантируя их целостность, достоверность и доступность для авторизованных пользователей.
Эффективное управление жизненным циклом данных является критически важным для поддержания их качества на всех этапах — от первоначального сбора до архивирования или удаления. Этот процесс включает в себя определение политик и процедур для контроля данных, обеспечение их точности, полноты, согласованности и своевременности. На этапах сбора данных необходимо проводить валидацию и очистку. В процессе хранения требуется мониторинг целостности и обеспечение безопасности. При архивировании важно соблюдать требования к хранению и доступности данных, а при удалении — следовать установленным нормам и правилам, чтобы избежать потери важной информации или нарушения законодательства о защите данных.
Проактивные меры, такие как валидация данных и их документирование, являются основополагающими для обеспечения пригодности данных для использования по назначению и их аудируемости. Валидация включает в себя проверку данных на соответствие заданным правилам и форматам на этапах ввода и обработки, что позволяет выявлять и исправлять ошибки на ранних стадиях. Документирование данных подразумевает создание подробных метаданных, описывающих происхождение, структуру, формат, смысл и правила трансформации данных. Это обеспечивает прозрачность, облегчает понимание данных различными заинтересованными сторонами и позволяет отслеживать изменения в данных на протяжении всего жизненного цикла, что критически важно для соответствия нормативным требованиям и проведения эффективного аудита.
Происхождение данных: Откуда взялась эта информация?
Происхождение данных — это полная история данных, включающая в себя информацию об их источнике, методах сбора, всех преобразованиях и изменениях, которым они подвергались. В контексте соблюдения нормативных требований, таких как GDPR или отраслевые стандарты, документирование происхождения данных является обязательным условием для обеспечения прозрачности и возможности аудита. Кроме того, подробная история данных необходима для повышения доверия к результатам машинного обучения, поскольку позволяет оценить влияние исходных данных и промежуточных преобразований на конечные прогнозы и выявить потенциальные источники ошибок или смещений.
Полная документация преобразований данных имеет решающее значение для выявления потенциальных смещений и обеспечения подотчетности. Фиксация каждого этапа обработки, включая используемые алгоритмы, параметры, и версии программного обеспечения, позволяет отследить, как конкретные изменения могли повлиять на результирующие данные. Это особенно важно при анализе больших наборов данных, где даже незначительные ошибки или предвзятости в процессе преобразования могут привести к существенным искажениям в результатах моделирования и принятии решений. Детальная информация о преобразованиях данных обеспечивает возможность воспроизведения результатов, аудита и коррекции ошибок, что является ключевым требованием для соответствия нормативным требованиям и поддержания доверия к данным.
Четкое понимание происхождения данных позволяет эффективно управлять рисками и оперативно реагировать на инциденты безопасности или проблемы с качеством данных. Детальная прослеживаемость данных, от источника до конечного результата, позволяет быстро выявить источник ошибок или уязвимостей. В случае утечки данных, информация о происхождении позволяет определить объем скомпрометированных данных и затронутых систем, что необходимо для эффективного реагирования и минимизации последствий. Кроме того, знание происхождения данных способствует выявлению и устранению систематических ошибок в процессе обработки, что повышает надежность и достоверность аналитических результатов и обеспечивает соответствие регуляторным требованиям.
Ответственный ИИ: Минимизация рисков и максимизация справедливости
Принципы минимизации данных и ограничения целей обработки играют ключевую роль в обеспечении конфиденциальности пользователей и снижении потенциального вреда. Исследования показывают, что сбор и хранение только тех данных, которые строго необходимы для конкретной, четко определенной цели, существенно уменьшает риски неправомерного использования или утечки информации. Ограничение целей обработки, то есть использование собранных данных исключительно в рамках изначально заявленной задачи, предотвращает непредвиденные последствия и обеспечивает прозрачность. Данный подход не только соответствует требованиям законодательства о защите персональных данных, но и способствует формированию доверия к системам искусственного интеллекта, демонстрируя ответственное отношение к информации и уважение к частной жизни пользователей.
Методы смягчения предвзятости играют решающую роль в обеспечении справедливости и предотвращении дискриминационных результатов при использовании моделей машинного обучения. Исследования показывают, что предвзятость может проникать в алгоритмы на различных этапах — от сбора и обработки данных до выбора признаков и самой архитектуры модели. Для борьбы с этим применяются разнообразные техники, включая перевзвешивание данных, модификацию алгоритмов обучения и применение пост-процессинговых методов для корректировки предсказаний. Важно понимать, что не существует универсального решения, и выбор подходящего метода зависит от конкретной задачи и типа предвзятости. Эффективное смягчение предвзятости требует комплексного подхода, включающего тщательный анализ данных, осознанный выбор алгоритмов и постоянный мониторинг результатов для выявления и устранения потенциальных источников несправедливости.
Исследование демонстрирует, что успешное внедрение искусственного интеллекта напрямую связано с приоритетом этических норм и надежной системой управления данными. Организации, уделяющие внимание этим аспектам, не только раскрывают весь потенциал технологий ИИ, но и формируют доверие со стороны пользователей и заинтересованных сторон. Анализ практических проблем, с которыми сталкиваются специалисты, выявил необходимость оптимизации организационных структур для обеспечения эффективного контроля над данными и алгоритмами. Результаты показывают, что продуманное управление данными, прозрачность процессов и соблюдение этических принципов являются ключевыми факторами для создания надежных и справедливых систем ИИ, способствующих долгосрочному развитию и принятию этих технологий.
Исследование показывает, что практикам приходится заниматься настоящим детективным поиском, чтобы соответствовать нормативным требованиям вроде GDPR и готовящегося AI Act. Это не просто вопрос технической реализации пайплайнов данных, а скорее, необходимость преодолеть разрыв между юридическими формулировками и фактическим состоянием данных. Как метко заметил Алан Тьюринг: «Иногда люди, у которых есть все возможности, не видят тех, что у них перед носом». В данном случае, это касается недостаточной видимости и контроля над качеством данных, что требует от специалистов не только навыков в области машинного обучения, но и глубокого понимания регуляторных аспектов. Неудивительно, что багтрекеры становятся дневниками боли, когда речь заходит о соответствии требованиям.
Что дальше?
Рассмотренные проблемы соответствия качества данных нормативным требованиям — это, как обычно, лишь вершина айсберга. Каждая «революция» в области машинного обучения неизбежно порождает новые способы обойти существующие проверки и балансы. Идея о том, что можно «задокументировать» соответствие, выглядит особенно наивно, учитывая скорость, с которой меняются модели и данные. В конечном итоге, документация станет лишь ещё одним слоем legacy, который придётся поддерживать.
Акцент на сотрудничестве между юристами и инженерами звучит, конечно, благородно. Однако, опыт подсказывает, что истинный диалог возможен лишь тогда, когда обе стороны признают ограниченность своих знаний. Юристы, к сожалению, часто склонны к абсолютизации регуляторных требований, а инженеры — к вере в непогрешимость алгоритмов. Разрыв между теорией соответствия и практической реализацией, вероятно, только увеличится.
Вместо того, чтобы стремиться к идеальному соответствию, стоит признать, что системы машинного обучения всегда будут содержать ошибки и уязвимости. Задача состоит не в том, чтобы их устранить, а в том, чтобы минимизировать риски и обеспечить возможность быстрого реагирования на инциденты. Иными словами, мы не чиним продакшен — мы просто продлеваем его страдания, делая это немного более аккуратно.
Оригинал статьи: https://arxiv.org/pdf/2602.05944.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ЕВРО К ШЕКЕЛЮ
- SOL ПРОГНОЗ. SOL криптовалюта
- HYPE ПРОГНОЗ. HYPE криптовалюта
- TON ПРОГНОЗ. TON криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
2026-02-07 17:52