Автор: Денис Аветисян
Новая методика позволяет повысить достоверность информации, генерируемой нейросетями для финансовых задач, за счет проверки каждого фрагмента ответа на соответствие исходным данным.
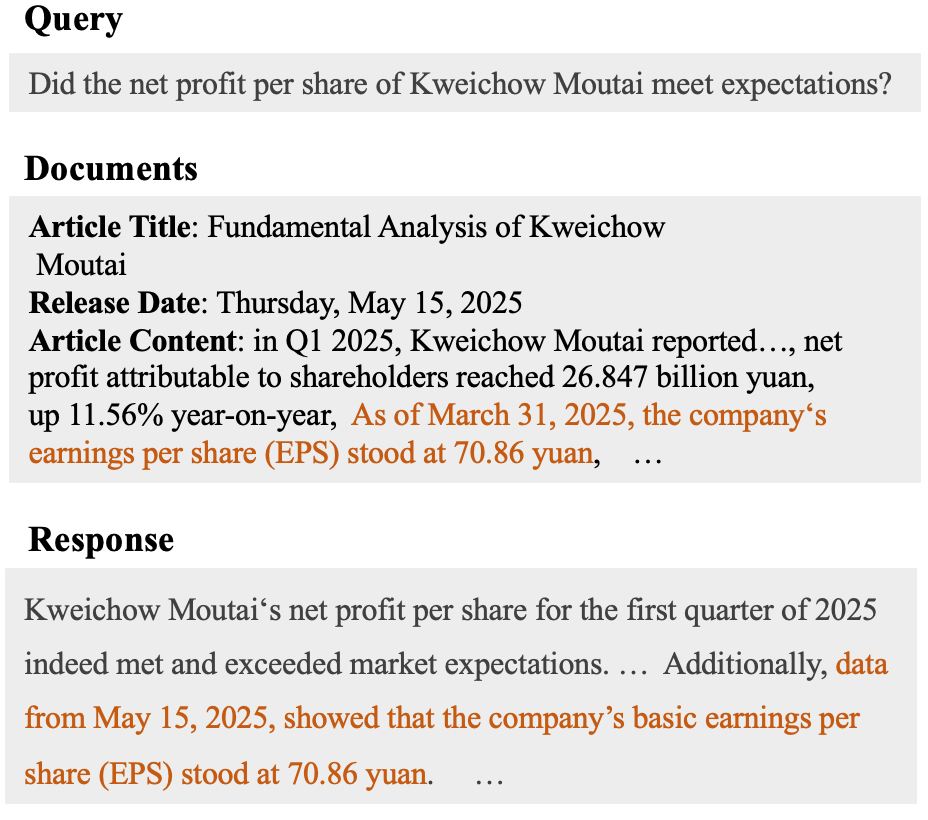
Предлагается фреймворк RLFKV, использующий обучение с подкреплением для верификации отдельных единиц знаний в ответах, полученных с помощью генеративных моделей, дополненных поиском релевантной информации.
Несмотря на растущую популярность систем генерации с использованием поиска (RAG), особенно в критически важных областях, таких как финансы, модели часто склонны к галлюцинациям, противоречащим извлечённой информации. В данной работе, ‘Mitigating Hallucination in Financial Retrieval-Augmented Generation via Fine-Grained Knowledge Verification’, предложен фреймворк RLFKV, использующий обучение с подкреплением и детальную проверку знаний для повышения фактической согласованности генерируемых ответов. Метод декомпозирует финансовые ответы на атомарные единицы знаний и предоставляет гранулированные награды за их верификацию, что позволяет более точно оптимизировать соответствие извлечённым документам. Сможет ли предложенный подход стать ключевым элементом в создании надёжных и точных финансовых систем, основанных на больших языковых моделях?
Иллюзии и Знание: Вызов Фактической Согласованности в Больших Языковых Моделях
Современные большие языковые модели (БЯМ) демонстрируют впечатляющую способность генерировать текст, неотличимый от созданного человеком, однако эта сила часто сопровождается проблемой “галлюцинаций” — склонностью к порождению информации, противоречащей общеизвестным фактам. Данное явление представляет собой серьезное препятствие на пути к созданию надежных и достоверных систем искусственного интеллекта, поскольку БЯМ могут убедительно излагать ложные сведения, представляя их как истинные. Несмотря на продвинутые алгоритмы обучения, модели иногда не способны отличить проверенную информацию от вымышленной, что ставит под вопрос их применимость в областях, требующих высокой точности и надежности, таких как научные исследования, журналистика и правовая практика.
Традиционные методы обучения с подкреплением, полагающиеся на бинарные сигналы вознаграждения — «верно» или «неверно» — оказываются недостаточными для обеспечения фактической достоверности языковых моделей. Такой упрощенный подход не позволяет учесть нюансы и градации истинности, что особенно критично при работе с болькими объемами информации и сложными знаниями. В результате, модель может испытывать трудности в различении близких по смыслу, но не идентичных утверждений, или же, получив незначительное вознаграждение за приблизительно верный ответ, закрепить неточность. Это приводит к нестабильности обучения, когда модель колеблется между различными вариантами ответа, не стремясь к однозначно верному результату, и в конечном итоге снижает надежность генерируемого текста.
Для достижения соответствия больших языковых моделей (LLM) достоверным знаниям, необходимы принципиально новые механизмы обратной связи, выходящие за рамки простых бинарных оценок. Традиционные подходы, оперирующие лишь сигналами «верно» или «неверно», оказываются недостаточными для тонкой оценки фактической точности генерируемого текста. Более детальная, гранулированная обратная связь, учитывающая степень соответствия информации различным источникам и контексту, позволяет модели не просто избегать очевидных ошибок, но и стремиться к более глубокому пониманию и точному воспроизведению знаний. Такая система, способная оценивать нюансы и предоставлять модели информацию о степени достоверности каждого утверждения, является ключевым шагом к созданию надежных и заслуживающих доверия искусственных интеллектов, способных генерировать текст, основанный на проверенных фактах.
Существующие методы оценки достоверности генерируемого текста, используемые в больших языковых моделях, сталкиваются с серьезными трудностями в обеспечении последовательной и надежной проверки фактов. Проблема заключается в том, что алгоритмы часто не способны точно определить, соответствует ли утверждение общепринятым знаниям, особенно в сложных или неоднозначных ситуациях. Это приводит к тому, что модели могут генерировать правдоподобные, но ложные утверждения, что существенно ограничивает их применимость в областях, требующих высокой степени надежности, таких как медицина, юриспруденция или научные исследования. Неспособность последовательно вознаграждать модели за фактическую точность тормозит развитие действительно надежных систем искусственного интеллекта, способных предоставлять проверенную и достоверную информацию.
RLFKV: Архитектура Знаний и Точная Верификация
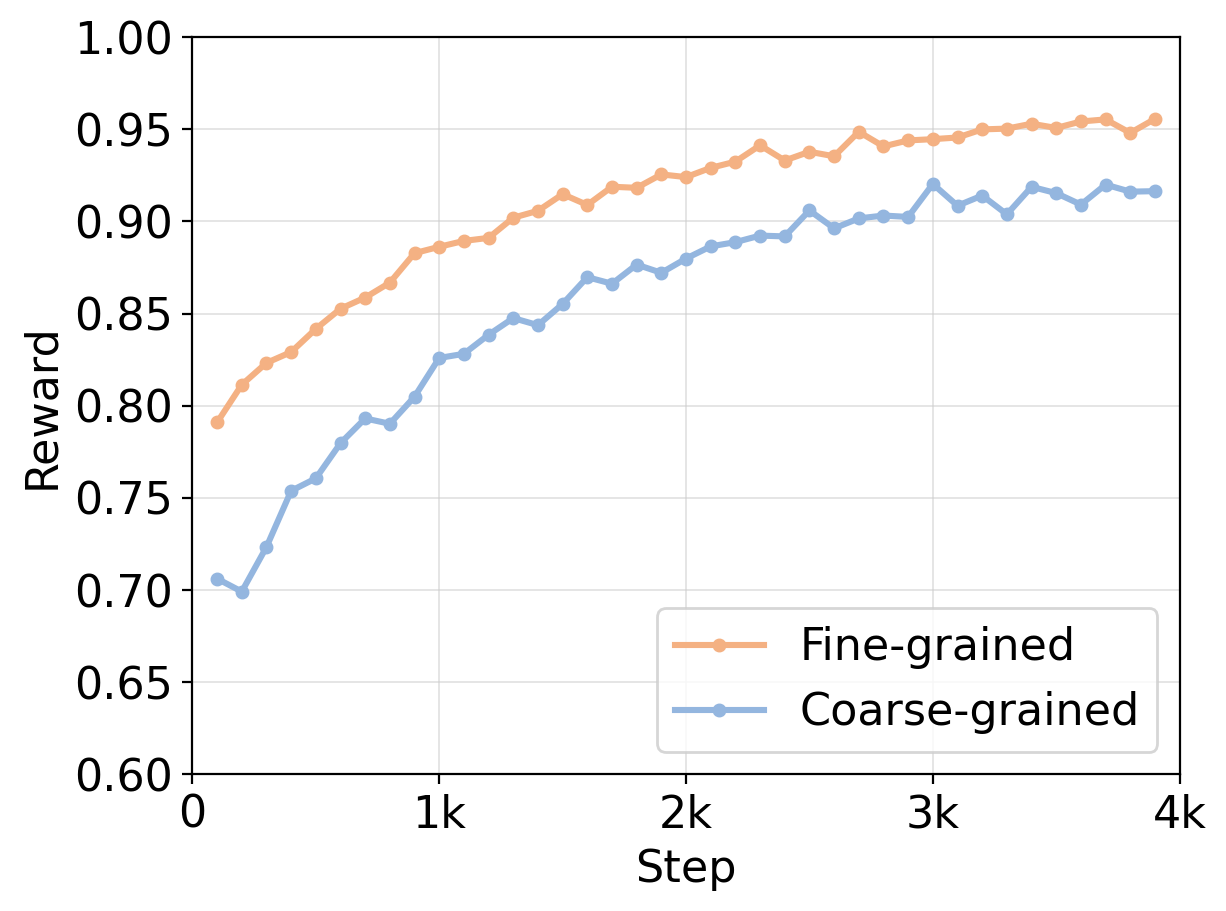
В рамках RLFKV, оптимизация больших языковых моделей (LLM) осуществляется посредством обучения с подкреплением, использующего инновационную систему вознаграждения с высокой детализацией. В отличие от традиционных методов, оценивающих ответ LLM целиком, RLFKV формирует сигнал вознаграждения на основе анализа каждого элемента ответа. Это позволяет точно определить, какие части ответа нуждаются в улучшении, что способствует более стабильному и эффективному процессу обучения модели и повышению точности генерируемой информации.
В основе системы RLFKV лежит декомпозиция ответов языковой модели на ‘атомарные знания’ — минимальные, самодостаточные утверждения, содержащие конкретную фактологическую информацию. Этот процесс предполагает разбивку сложных предложений на отдельные, проверяемые единицы знания. Каждое ‘атомарное знание’ представляет собой минимальный блок информации, который можно независимо оценить на предмет соответствия истине. Такой подход позволяет системе предоставлять более точную и детализированную обратную связь при обучении, фокусируясь на конкретных фактологических ошибках, а не на общей оценке ответа. Разделение на атомарные знания необходимо для формирования сигнала вознаграждения, используемого в алгоритме обучения с подкреплением.
В рамках RLFKV, проверка каждого элемента “атомарного знания” позволяет формировать точные сигналы обратной связи для обучения языковых моделей. Вместо оценки ответа в целом, система оценивает каждый минимальный факт, содержащийся в нем, что позволяет более детально корректировать поведение модели. Такой подход обеспечивает повышенную стабильность обучения за счет уменьшения разброса в сигналах обратной связи и позволяет более эффективно оптимизировать модель для генерации фактически корректной информации. В результате, модель точнее усваивает и воспроизводит факты, минимизируя вероятность галлюцинаций и повышая общую достоверность генерируемого текста.
Фреймворк RLFKV расширяет возможности генерации на основе извлечения (Retrieval-Augmented Generation), что способствует улучшению фактической обоснованности генерируемых текстов и снижению частоты галлюцинаций. В отличие от стандартных подходов, RLFKV не ограничивается проверкой общей релевантности извлеченных документов, а проводит детальную верификацию каждого элемента фактической информации, представленного в ответе модели. Это позволяет более точно оценить, насколько сгенерированный текст соответствует проверенным источникам, и, как следствие, уменьшить вероятность генерации ложных или неподтвержденных утверждений. Усиленная проверка фактических данных приводит к более надежным и достоверным результатам, особенно в задачах, требующих высокой точности и объективности.
Деконструкция Знаний: Атомарные Единицы и Временная Чувствительность
В основе нашей системы лежит метод “Атомарной декомпозиции знаний”, позволяющий разбивать ответы на отдельные факты, представленные в виде “Финансового Четверичного Структурирования”. Эта структура состоит из четырех ключевых элементов: сущность (entity) — объект, к которому относится информация; метрика (metric) — измеряемый показатель; значение (value) — конкретное числовое или текстовое представление метрики; и метка времени (timestamp) — точная дата и время, к которым относится факт. Использование данной структуры обеспечивает возможность точной верификации и структурирования финансовых данных, выделяя каждый элемент информации как самостоятельную единицу.
Структура, состоящая из четырех элементов — сущность, метрика, значение и временная метка — позволяет точно и однозначно представить финансовую информацию. Использование данной структуры обеспечивает возможность верификации данных путем сопоставления каждого элемента с внешними источниками и подтверждения его актуальности на конкретный момент времени. Четкое разделение информации на эти компоненты облегчает автоматизированный анализ и выявление несоответствий, повышая надежность и достоверность финансовых отчетов и прогнозов. Такой подход особенно важен при обработке больших объемов данных и в системах, требующих высокой степени точности и прозрачности.
В финансовом анализе временная составляющая данных критически важна для обеспечения точности и достоверности информации. Наш метод учитывает это за счет реализации “Временной Чувствительности”, которая позволяет точно фиксировать и интерпретировать временные метки, связанные с каждым финансовым фактом. Это достигается путем включения поля “timestamp” в структуру “Финансового Четверичного Конструктора” (entity, metric, value, timestamp), что позволяет однозначно определить момент, когда было получено или актуально данное значение. Точное отслеживание времени позволяет избежать ошибок, связанных с устаревшей информацией, и обеспечивает возможность проведения корректного анализа трендов и динамики финансовых показателей.
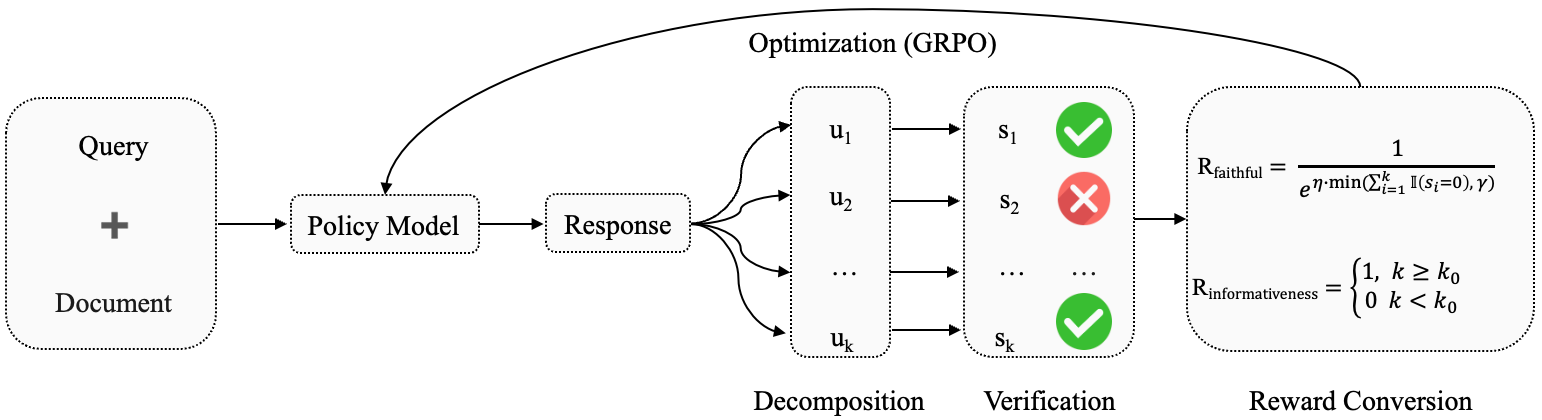
Для эффективной оптимизации политики модели в рамках RLFKV (Reinforcement Learning from Knowledge Vectors) используется алгоритм GRPO (Gradient-based Policy Optimization). GRPO представляет собой метод оптимизации, основанный на вычислении градиента функции вознаграждения для корректировки параметров политики. Этот подход позволяет итеративно улучшать модель, максимизируя ожидаемое вознаграждение и обеспечивая более точные и надежные результаты в процессе обучения с подкреплением. Алгоритм GRPO особенно эффективен в задачах, требующих быстрой адаптации к изменяющимся условиям и оптимизации сложных финансовых стратегий.
Валидация и Результаты: Устойчивость к Различным Наборам Данных
Для оценки эффективности RLFKV использовались два набора данных: публично доступный набор ‘FDD Dataset’ и новый, более разнообразный набор ‘FDD-ANT Dataset’. Набор ‘FDD-ANT Dataset’ был специально создан для расширения охвата и повышения репрезентативности данных, что позволило провести более комплексную оценку производительности модели в различных сценариях. Использование двух наборов данных позволило подтвердить устойчивость и обобщающую способность RLFKV при работе с различными типами финансовых данных и структурами отчетов.
Оптимизация моделей с использованием RLFKV привела к существенным улучшениям как в показателе “Faithfulness” (соответствие с извлеченными документами), так и в показателе “Informativeness” (информативность). Увеличение показателей по обоим параметрам свидетельствует о том, что RLFKV способствует генерации более точных и содержательных описаний, снижая вероятность фактических ошибок и повышая полезность предоставляемой информации. Данное улучшение наблюдалось при применении к различным наборам данных, что подтверждает эффективность подхода.
Оптимизация моделей с использованием RLFKV привела к повышению показателей достоверности (Faithfulness) до 3,6 баллов на наборе данных FDD и до 3,1 балла на более разнообразном наборе данных FDD-ANT. Данное улучшение свидетельствует о снижении количества фактических ошибок и галлюцинаций в генерируемых моделями описаниях финансовых данных, что подтверждает эффективность RLFKV в повышении надежности информации.
Метод RLFKV был успешно применен к базовым моделям ‘LLaMA3.1-8B-Instruct’ и ‘Qwen3-8B’, что демонстрирует его общую применимость и независимость от конкретной архитектуры модели. Это указывает на то, что RLFKV может быть эффективно интегрирован в различные большие языковые модели (LLM) для улучшения качества генерируемых финансовых описаний, не требуя существенных изменений в базовой модели. Успешная работа с обеими моделями подтверждает универсальность подхода и его потенциал для широкого применения в задачах генерации финансовой информации.
Результаты оценки показали, что применение RLFKV к моделям привело к увеличению показателя Faithfulness (согласованности с извлеченными документами) на 1.6 пункта на наборе данных FDD-ANT по сравнению с базовой моделью LLaMA3. Данный прирост демонстрирует улучшение фактической точности генерируемых финансовых описаний и снижение вероятности появления фактических ошибок при использовании RLFKV.
Результаты проведенных экспериментов подтверждают, что применение RLFKV эффективно повышает фактическую согласованность и улучшает качество генерируемых языковыми моделями описаний финансовых данных. Оценка на общедоступном наборе данных ‘FDD’ и на специально созданном, более разнообразном наборе ‘FDD-ANT’ показала увеличение показателей ‘Faithfulness’ (соответствие извлеченным документам) до 3.6 и 3.1 пункта соответственно, что свидетельствует о снижении количества фактических ошибок и галлюцинаций. Данный подход успешно применен к моделям LLaMA3.1-8B-Instruct и Qwen3-8B, что демонстрирует его общую применимость и потенциал для улучшения надежности и точности финансовых отчетов, генерируемых большими языковыми моделями.
Перспективы: К Надежным Системам Искусственного Интеллекта
Разработка RLFKV представляет собой существенный прорыв в создании более надежных систем искусственного интеллекта, способных генерировать точную и достоверную информацию. Данный подход, сочетающий в себе разложение знаний и их последующую верификацию, позволяет значительно снизить вероятность генерации ложных или вводящих в заблуждение утверждений. В отличие от традиционных языковых моделей, RLFKV не просто предсказывает наиболее вероятную последовательность слов, но и стремится к соответствию фактам, используя внешние источники знаний для подтверждения генерируемого контента. Это открывает возможности для создания интеллектуальных систем, которым можно доверять в критически важных областях, таких как медицина, юриспруденция и научные исследования, где точность и надежность информации имеют первостепенное значение.
Дальнейшие исследования направлены на адаптацию RLFKV к различным областям знаний, выходящим за рамки текущих экспериментов. Особое внимание будет уделено разработке более сложных методов декомпозиции знаний — разделению сложных концепций на более простые, проверяемые компоненты. Параллельно изучаются усовершенствованные подходы к верификации — подтверждению истинности полученных результатов, используя внешние источники и логические рассуждения. Предполагается, что такие улучшения позволят значительно повысить надежность и точность генерируемой искусственным интеллектом информации, расширив область его применения и способствуя более эффективному решению сложных задач.
Предвидится будущее, в котором искусственный интеллект сможет бесшовно объединять фактические знания с творческой генерацией, предоставляя ценные идеи и решения для широкого спектра задач. Такая интеграция позволит системам не просто создавать новый контент, но и гарантировать его соответствие действительности, что особенно важно в областях, требующих высокой точности и объективности. Представьте себе системы, способные писать научно-фантастические романы, основанные на проверенных научных данных, или создавать произведения искусства, вдохновленные историческими событиями, достоверно отражая детали эпохи. Подобные возможности откроют новые горизонты для инноваций в образовании, науке, медицине и других сферах, позволяя искусственному интеллекту стать незаменимым помощником в решении сложных проблем и генерации передовых решений.
Приоритет фактической достоверности является ключевым фактором для раскрытия всего потенциала больших языковых моделей (LLM) и создания действительно полезных для общества систем искусственного интеллекта. Повышенная надежность генерируемой информации не только укрепляет доверие к этим технологиям, но и открывает возможности для их применения в критически важных областях, таких как медицина, образование и научные исследования. Системы, способные с высокой точностью оперировать фактами, могут предоставлять более обоснованные решения, минимизировать риски, связанные с дезинформацией, и способствовать более эффективному принятию решений в различных сферах жизни. В конечном итоге, фокусировка на фактической точности позволит LLM перейти от простого генерирования текста к созданию интеллектуальных систем, способных приносить реальную пользу человечеству.
Исследование демонстрирует, что стремление к абсолютному контролю над генерируемыми ответами — иллюзия. Авторы предлагают подход, основанный на декомпозиции знаний на атомарные единицы и поощрении соответствия этим единицам извлеченным данным. Это напоминает о высказывании Брайана Кернигана: «Отладка — это как поиск иглы в стоге сена, но игла — это всегда в стоге». Подобно тому, как поиск ошибки требует внимательного анализа каждого элемента, обеспечение фактической достоверности в системах Retrieval-Augmented Generation требует верификации каждого атомарного факта. Настоящая устойчивость системы проявляется не в предотвращении галлюцинаций, а в способности обнаруживать и исправлять их, опираясь на проверенные знания.
Что дальше?
Представленная работа, стремясь обуздать склонность больших языковых моделей к галлюцинациям в финансовой сфере, лишь подчеркивает фундаментальную истину: разделение системы на атомарные единицы знания не устраняет зависимость между ними. Напротив, это создает новые, более изощренные векторы для распространения ошибок. Каждая «атомарная» единица — это потенциальная точка отказа, а стремление к детальной верификации — лишь откладывает неизбежное. Всё связанное когда-нибудь упадёт синхронно.
Будущие исследования, вероятно, сосредоточатся на создании ещё более гранулярных систем вознаграждения, на разработке алгоритмов, способных предсказывать и смягчать каскадные сбои. Но следует помнить: сложность не является синонимом устойчивости. Попытки построить идеальную систему контроля всегда приведут к появлению новых, непредсказуемых уязвимостей. Системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить.
Настоящим вызовом является не создание алгоритмов, способных выявлять ложь, а признание того, что полная достоверность — недостижимая иллюзия. Вместо этого, необходимо научиться жить с неопределенностью, создавать системы, которые способны адаптироваться к ошибкам, и принимать тот факт, что в конечном итоге, всё стремится к зависимости.
Оригинал статьи: https://arxiv.org/pdf/2602.05723.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-02-06 07:59