Автор: Денис Аветисян
Новый подход к обучению моделей обработки языка позволяет им лучше понимать социальный контекст и решать задачи анализа данных без большого количества размеченных примеров.
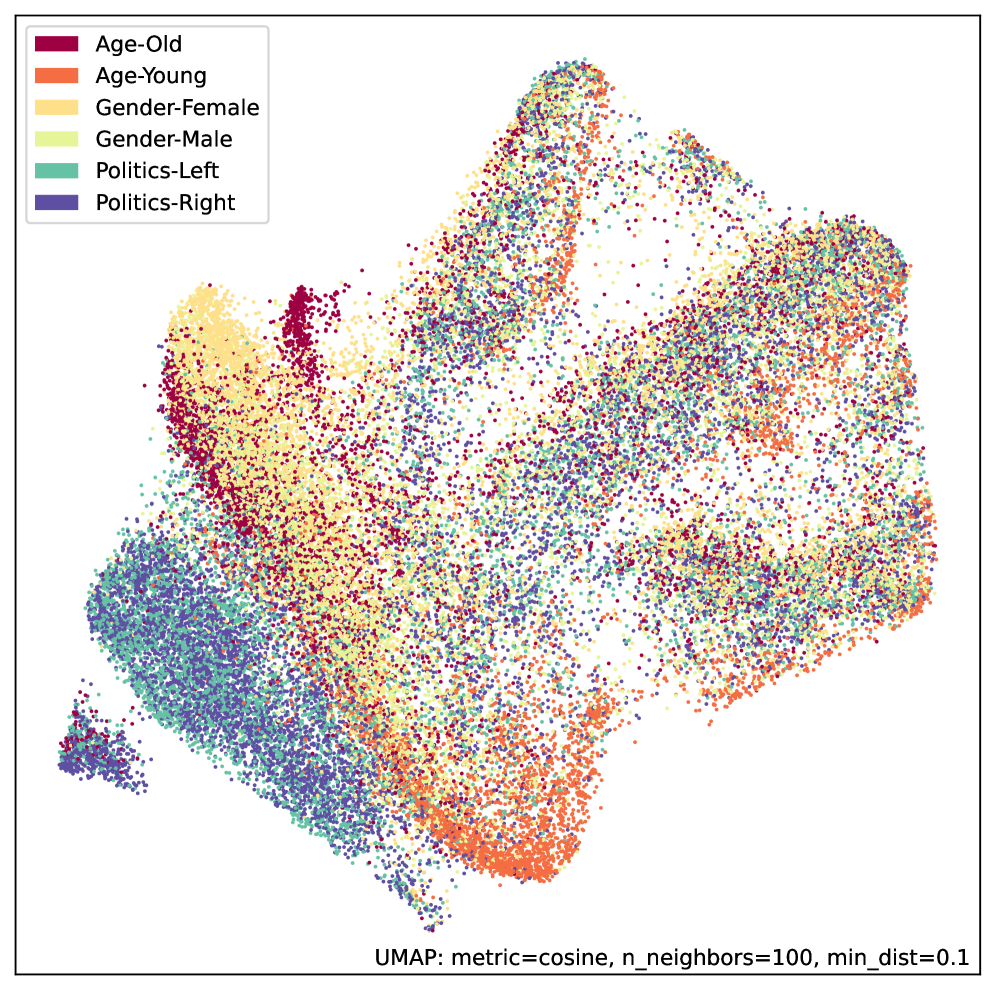
Исследование предлагает использовать самообучение моделей-трансформеров на основе норм, принятых в онлайн-сообществах, для улучшения понимания контекста и борьбы с дефицитом данных.
Моделирование динамики онлайн-социальных платформ сталкивается с ограничениями, обусловленными зависимостью от размеченных данных для решения задач, таких как выявление языка вражды. В данной работе, ‘Community Norms in the Spotlight: Enabling Task-Agnostic Unsupervised Pre-Training to Benefit Online Social Media’, предложен переход от целевого обучения к неконтролируемому предварительному обучению моделей Discussion Transformers, основанному на учёте социальных норм сообществ. Данный подход не только смягчает проблему нехватки данных, но и позволяет интерпретировать социальные нормы, лежащие в основе решений ИИ-системы. Не откроет ли это новые возможности для разработки социально-ориентированного искусственного интеллекта, способного к более глубокому пониманию контекста онлайн-взаимодействий?
За пределами Последовательности: Ограничения Традиционного Предварительного Обучения
Традиционные языковые модели, несмотря на свою вычислительную мощь, сталкиваются с трудностями при адекватном представлении сложной взаимосвязи элементов, присущей данным, полученным из диалогов. Эти модели, как правило, обрабатывают информацию последовательно, что препятствует пониманию нелинейной структуры разговоров и скрытых социальных сигналов, которыми они насыщены. В то время как они успешно справляются с задачами, требующими анализа отдельных предложений, модели испытывают затруднения при интерпретации контекста, охватывающего несколько реплик, и при улавливании тонких нюансов, определяющих динамику беседы. Данное ограничение существенно влияет на их способность генерировать связные и релевантные ответы в многооборотном диалоге, подчеркивая необходимость разработки новых подходов к моделированию диалоговых данных.
Традиционные языковые модели, обрабатывающие информацию последовательно, сталкиваются с ограничениями в понимании сложных диалоговых структур. Человеческие беседы редко развиваются линейно; скорее, они напоминают графоподобную сеть взаимосвязанных тем, реплик и подтекстов. Последовательная обработка не позволяет моделям эффективно улавливать эти нелинейные зависимости, а также неявные социальные сигналы, такие как ирония, сарказм или изменение тональности, которые формируют динамику разговора. В результате, модели испытывают трудности в понимании контекста, выходящего за рамки непосредственно предшествующей реплики, что снижает их способность генерировать осмысленные и релевантные ответы в многооборотном диалоге. Игнорирование этих сложных взаимосвязей приводит к упрощенному представлению беседы, упуская важные нюансы, определяющие ее естественный ход.
Существующие методы предварительного обучения языковых моделей зачастую оказываются недостаточно эффективными при обработке контекста, выходящего за рамки непосредственной реплики в диалоге. Это ограничение существенно снижает производительность при работе с многооборотными беседами, где понимание предшествующей истории и неявных связей между репликами критически важно. Модели, обученные преимущественно на последовательном анализе текста, испытывают трудности с удержанием долгосрочного контекста и распознаванием тонких изменений в намерениях участников диалога. В результате, способность генерировать релевантные и когерентные ответы в сложных, развернутых беседах заметно снижается, поскольку модель не способна в полной мере учитывать всю глубину и сложность коммуникативного процесса.
Графовые Трансформеры: Моделирование Разговора как Реляционной Системы
Дискуссионные Трансформеры используют графовые нейронные сети (GNN) для представления реплик в диалоге как узлов графа, а взаимосвязи между этими репликами — как ребра. Каждый узел соответствует отдельному высказыванию участника беседы, а ребра отражают зависимости, такие как ответы, уточнения или перефразировки. Эта структура позволяет модели учитывать контекст диалога, представляя его не как линейную последовательность, а как сложную сеть взаимосвязанных реплик. В частности, GNN позволяют эффективно агрегировать информацию от связанных узлов, формируя векторное представление каждой реплики с учетом ее контекста в диалоге. Такой подход позволяет моделировать сложные зависимости, возникающие в многоходовых беседах, и более эффективно улавливать семантические связи между различными репликами.
В отличие от последовательных моделей, основанных на обработке реплик диалога как линейной последовательности, использование графовой структуры позволяет моделировать иерархические и разветвленные структуры разговора. Каждая реплика представляется как узел графа, а связи между репликами — как ребра, отражающие зависимости и логические связи. Это позволяет модели учитывать контекст не только предыдущей реплики, но и других реплик, связанных с текущей, что особенно важно для сложных диалогов с несколькими ветвями обсуждения или в ситуациях, когда участники возвращаются к ранее обсуждаемым темам. Такой подход обеспечивает более полное представление о контексте диалога и повышает способность модели к пониманию и генерации связных и релевантных ответов.
Предварительное обучение, не зависящее от конкретной задачи (Task-Agnostic Pre-training), предполагает обучение модели на большом корпусе диалоговых данных для формирования базового понимания принципов ведения беседы. Этот этап предшествует специализированной настройке (fine-tuning) для решения конкретных задач, таких как ответы на вопросы или генерация диалогов. Использование предварительно обученной модели позволяет значительно улучшить обобщающую способность (generalization ability) — то есть, способность эффективно работать на новых, ранее не встречавшихся данных и в новых ситуациях, поскольку модель уже обладает общими знаниями о структуре и семантике диалогов. В результате, требуется меньше данных для тонкой настройки под конкретную задачу и достигается более высокая производительность.
Предварительное Обучение для Реляционного Понимания: Улавливание Нюансов Разговора
Методы предварительного обучения, такие как реконструкция признаков узлов (Node Feature Reconstruction) и классификация ответов на уровне ребер (Edge-Level Reply Classification), позволяют усилить возможности генеративных моделей в понимании реляционных зависимостей. Реконструкция признаков узлов заставляет модель прогнозировать атрибуты участников дискуссии, опираясь на контекст, а классификация ответов на уровне ребер требует определения взаимосвязи между сообщениями и их авторами. Эти подходы вынуждают модель учитывать не только содержание сообщений, но и структуру взаимодействия между участниками, что способствует более глубокому пониманию контекста и взаимосвязей в диалоге.
Контрастивное предварительное обучение, особенно с использованием задач, учитывающих структуру обсуждений (Discussion-Aware Contrastive Tasks), позволяет модели различать тонкие различия в нормах общения и намерениях участников. Данный подход обучает модель оценивать схожесть и различие между различными репликами в контексте обсуждения, что позволяет ей более точно интерпретировать неявные сигналы и понимать, как меняются нормы поведения в различных сообществах. Эффективность метода заключается в формировании векторных представлений реплик, отражающих их семантическую близость и соответствие определенным социальным правилам, что критически важно для понимания нюансов коммуникации.
Предварительные результаты, полученные с использованием разработанного фреймворка, демонстрируют четкое разделение векторных представлений дискуссий (embeddings) на основе норм, принятых в различных сообществах. Визуализация с помощью UMAP подтверждает эту тенденцию. Примечательно, что достижение данной степени разделения было получено при значительном сокращении размера используемого набора данных Contextual Abuse Dataset (CAD) в 10 раз: с 1394 дискуссий и 27 487 меток до 183 дискуссий и 2765 меток, что свидетельствует об эффективности предложенного подхода к предварительному обучению.
Соединяя Разрозненное: К Объяснимому и Нормативному Искусственному Интеллекту
Современные модели искусственного интеллекта, стремясь к более глубокому пониманию языка, учатся не просто распознавать отдельные слова, но и анализировать структуру диалога. Это означает, что они способны выявлять взаимосвязи между репликами, определять темы обсуждения и отслеживать развитие мысли в беседе. Вместо поверхностного сопоставления шаблонов, такие модели строят внутреннее представление о логической организации разговора, что позволяет им предсказывать последующие реплики, выявлять противоречия и даже понимать скрытый смысл высказываний. Таким образом, переход от анализа отдельных фраз к пониманию общей структуры диалога открывает путь к созданию действительно интеллектуальных систем, способных к осмысленному общению и решению сложных задач.
Возможность проследить ход рассуждений модели открывает новую эру в развитии объяснимого искусственного интеллекта. Вместо «черного ящика», выдающего результат без каких-либо пояснений, современные системы начинают демонстрировать прозрачность принятия решений. Это достигается за счет анализа внутренних представлений и логических шагов, которые приводят к определенному ответу. Понимание этих процессов не только повышает доверие к ИИ, но и позволяет выявлять и исправлять ошибки, а также оптимизировать алгоритмы для достижения более качественных и обоснованных результатов. В конечном итоге, это способствует созданию ИИ, который не просто выполняет задачи, но и способен аргументировать свои действия, что критически важно для применения в сферах, требующих высокой ответственности и прозрачности.
Современные модели искусственного интеллекта, стремясь к более реалистичному взаимодействию, всё чаще обращаются к учёту социальных норм, действующих в различных сообществах. Понимание неписаных правил, определяющих вежливое и уместное поведение, позволяет создавать системы, способные генерировать ответы, учитывающие контекст и избегающие социально неприемлемых высказываний. Это достигается путём анализа больших объёмов текстовых данных, позволяющего выявить паттерны поведения и предпочтения, характерные для конкретных групп пользователей. В результате, искусственный интеллект перестаёт быть просто генератором грамматически верных предложений, а становится способным к более тонкому и адекватному восприятию социальных сигналов, что открывает путь к созданию действительно уважительных и этичных систем взаимодействия.
За горизонтом: Преодоление ограничений и расширение возможностей
Несмотря на значительные успехи в предварительном обучении больших языковых моделей, существует риск так называемого негативного переноса знаний. Это явление возникает, когда обучение на одной задаче ухудшает производительность модели при решении другой, казалось бы, несвязанной задачи. Для смягчения этой проблемы необходима тщательная оценка способности модели к обобщению и применение методов регуляризации. Такие методы позволяют предотвратить переобучение на конкретных данных и способствуют формированию более устойчивых и универсальных представлений, что критически важно для успешной адаптации к новым и разнообразным задачам в области искусственного интеллекта. Постоянный мониторинг и коррекция процесса обучения с использованием валидационных данных позволяют минимизировать негативное влияние переноса и обеспечить стабильное повышение эффективности модели.
Перспективные исследования направлены на разработку систем, способных динамически адаптироваться к изменяющимся нормам общения в различных сообществах. Это предполагает создание алгоритмов, отслеживающих и учитывающих эволюцию языковых трендов, сленга и социальных конвенций, что позволит избежать устаревших или неуместных ответов. Особое внимание уделяется обработке многопоточных диалогов — сложных бесед, в которых одновременно обсуждаются несколько тем и участвуют разные пользователи. Эффективное управление контекстом и поддержание когерентности в таких ситуациях требует разработки новых методов моделирования диалога, способных учитывать взаимосвязи между различными ветвями обсуждения и обеспечивать плавный переход между ними. Такой подход позволит создавать более естественные и эффективные системы искусственного интеллекта, способные полноценно участвовать в сложных социальных взаимодействиях.
Интеграция разработанных методов с другими модальностями, такими как аудио и видео, открывает перспективы для создания принципиально новых, более мощных и универсальных систем искусственного интеллекта, способных к ведению диалога. Возможность анализа не только текстовых данных, но и интонации голоса, мимики и жестов позволит системе более точно понимать намерения собеседника и генерировать ответы, максимально соответствующие контексту и эмоциональному состоянию. Это особенно важно для создания реалистичных виртуальных ассистентов и компаньонов, а также для улучшения взаимодействия человека с машиной в целом, обеспечивая более естественное и интуитивно понятное общение. Предполагается, что такая мультимодальность значительно повысит эффективность и удобство использования диалоговых систем в различных сферах, от образования и здравоохранения до развлечений и обслуживания клиентов.
Работа демонстрирует, что попытки навязать системе жесткие рамки часто приводят к неожиданным сбоям. Авторы предлагают отойти от привычной практики обучения с учителем, фокусируясь на предварительном обучении моделей с использованием норм сообществ. Это позволяет учитывать контекст и преодолевать дефицит данных, особенно в анализе социальных медиа. Как однажды заметил Джон Маккарти: «Каждая архитектурная конструкция — это пророчество о будущем сбое». Действительно, стремление к абсолютной предсказуемости в сложных системах иллюзорно; гораздо эффективнее позволить системе развиваться органически, учитывая неявные правила и нормы, формирующиеся в сообществе. Стабильность, в таком подходе, не достигается принуждением, а возникает как побочный эффект адаптации к меняющимся условиям.
Что дальше?
Предложенный переход от контролируемой тонкой настройки к неконтролируемому предварительному обучению, опирающемуся на нормы сообществ, — это не столько решение, сколько переформулировка проблемы. Система, обученная на понимании неявных правил дискурса, не становится более надежной, она лишь приобретает новые, изощренные способы обмануть ожидания. Долгосрочная стабильность метрик, особенно в области выявления враждебных высказываний, должна вызывать не радость, а подозрение — признак того, что система адаптировалась к обходу, а не к реальному разрешению конфликтов.
Наиболее сложная задача, остающаяся вне поля зрения данной работы, — это динамическая природа этих самых норм. Сообщества эволюционируют, язык меняется, и то, что вчера считалось приемлемым, сегодня может быть расценено как оскорбление. Система, зафиксировавшая нормы на определенный момент времени, обречена на постепенное устаревание, превращаясь в своего рода цифровой артефакт. Необходимо исследовать механизмы непрерывного обучения и адаптации к изменяющемуся контексту, но любое подобное решение неизбежно вносит новые, непредсказуемые риски.
В конечном итоге, эта работа — не шаг к созданию идеального фильтра, а приглашение к пониманию того, что система не ломается — она эволюционирует в неожиданные формы. Изучение этих форм, а не попытки их подавления, представляется более перспективным путем. Каждый архитектурный выбор — это пророчество о будущем сбое, и задача исследователя — научиться читать эти пророчества.
Оригинал статьи: https://arxiv.org/pdf/2602.02525.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-04 19:11