Автор: Денис Аветисян
Исследователи разработали инновационный подход к обнаружению изображений, созданных искусственным интеллектом, основанный на анализе цветовых корреляций, возникающих в процессе формирования картинки камерой.
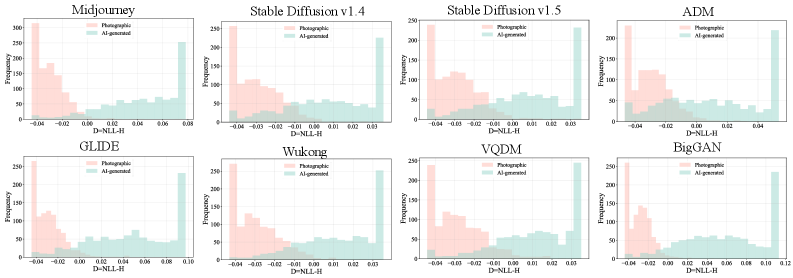
Метод DCCT, использующий демосэйкинг и расстояние Вассерштейна, демонстрирует передовые результаты в обобщении и устойчивости к различным генеративным моделям.
Растущая реалистичность изображений, сгенерированных искусственным интеллектом, ставит под угрозу цифровую подлинность и требует новых подходов к их обнаружению. В работе ‘Color Matters: Demosaicing-Guided Color Correlation Training for Generalizable AI-Generated Image Detection’ предложен метод DCCT, использующий особенности цветокорреляций, возникающих в процессе обработки изображений камерой, для выявления артефактов, свойственных изображениям, созданным генеративными моделями. DCCT позволяет достичь передовых результатов в обобщении и устойчивости к различным генераторам изображений, выявляя различия в распределении цветовых корреляций между фотографиями и изображениями, созданными ИИ. Способны ли подобные методы, основанные на анализе физических процессов формирования изображений, обеспечить надежную защиту от все более изощренных генеративных моделей в будущем?
Иллюзия Реальности: Введение в Эру Синтетических Изображений
Современные модели генерации изображений, такие как генеративно-состязательные сети (GAN) и диффузионные модели, демонстрируют беспрецедентный прогресс в создании фотореалистичных синтетических изображений. Эти алгоритмы, обучаясь на огромных массивах данных, способны генерировать изображения, практически неотличимые от настоящих фотографий. Развитие этих технологий привело к тому, что созданные искусственно изображения стали настолько сложными и детализированными, что визуальный анализ человеком становится неэффективным для их обнаружения. Изначально, синтетические изображения имели заметные артефакты, но современные модели научились их минимизировать, что значительно усложняет задачу верификации подлинности визуального контента и поднимает вопросы о доверии к цифровым изображениям в целом.
В эпоху стремительного развития технологий генерации изображений, способность различать подлинные фотографии и созданные искусственным интеллектом становится краеугольным камнем доверия к визуальной информации. Ранее полагаться на видимые несовершенства или артефакты было достаточно, однако современные генеративные модели, такие как диффузионные сети, способны создавать изображения, практически неотличимые от реальности. Это создает серьезную угрозу в различных сферах — от новостной журналистики и социальных сетей до судебных разбирательств и документирования исторических событий. Потеря способности верить увиденному подрывает основы общественного дискурса и может привести к манипуляциям и распространению дезинформации. Поэтому разработка эффективных методов обнаружения синтетических изображений становится не просто технической задачей, а необходимостью для сохранения целостности информационного пространства и поддержания доверия к визуальной культуре.
Традиционные методы компьютерной криминалистики изображений сталкиваются с растущими трудностями при выявлении синтетических изображений, созданных современными генеративными моделями. Если ранее анализ шумов, цветовых аномалий или следов редактирования позволял достоверно определить подлинность изображения, то новые алгоритмы, такие как генеративно-состязательные сети (GAN) и диффузионные модели, способны создавать артефакты, практически неотличимые от естественных. Это связано с тем, что эти модели обучаются на огромных массивах данных, имитируя сложные закономерности и текстуры, что существенно затрудняет обнаружение следов искусственного происхождения. В результате, существующие методы, основанные на статистическом анализе и выявлении несоответствий, становятся все менее эффективными, подчеркивая необходимость разработки принципиально новых подходов к обнаружению синтетических изображений.

Признаки Искусственности: Методы Выявления Синтетических Изображений
Существующие методы обнаружения сгенерированных изображений, такие как обнаружение артефактов и обнаружение на основе общих представлений, основываются на выявлении внутренних несоответствий, свойственных искусственно созданным изображениям. Методы обнаружения артефактов анализируют специфические дефекты, возникающие в процессе генерации, например, шумы, искажения или неестественные текстуры. Обнаружение на основе общих представлений, напротив, стремится выявить отклонения от статистических закономерностей, характерных для реальных изображений, путем анализа признаков на уровне представления данных. Оба подхода эксплуатируют предположение о том, что сгенерированные изображения, даже при высокой степени реалистичности, содержат тонкие несоответствия, позволяющие отличить их от фотографий, полученных естественным путем.
Высокочастотная фильтрация, в частности, метод SRM (Spectral Residual Magnitude), позволяет выявлять незначительные расхождения в частотной области изображений. SRM анализирует остаток спектра после применения фильтра низких частот, акцентируя внимание на высокочастотных компонентах, которые часто содержат артефакты, возникающие при генерации изображений. Незначительные несоответствия в этих высокочастотных компонентах, невидимые для человеческого глаза, могут указывать на то, что изображение является синтетическим. В основе метода лежит предположение, что естественные изображения имеют определенные закономерности в распределении амплитуд остатка спектра, в то время как сгенерированные изображения могут отклоняться от этих закономерностей, что позволяет использовать SRM для обнаружения подделок.
Метод обнаружения аномалий на основе одного класса (One-Class Anomaly Detection) предполагает построение модели, описывающей распределение характеристик только для реальных, несинтетических изображений. Данная модель, как правило, обучается на наборе данных, содержащем исключительно образцы, относящиеся к «нормальному» классу. В процессе обнаружения, входное изображение анализируется, и вычисляется его отклонение от модели нормального распределения. Значительные отклонения указывают на потенциальную принадлежность изображения к синтетическим, поскольку оно не соответствует усвоенным характеристикам реальных данных. Эффективность метода напрямую зависит от точности моделирования нормального распределения и выбора метрики отклонения.

DCCT: Новый Взгляд на Обнаружение Синтетических Изображений, Основанный на Физике
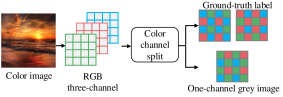
Основой фреймворка DCCT является анализ физических процессов, происходящих при получении изображения, в частности, процесса демозаики. В цифровых камерах данные о цвете получают с помощью матрицы цветовых фильтров (Color Filter Array, CFA), где каждый пиксель регистрирует интенсивность света только одного цвета (обычно красного, зеленого или синего). Процесс демозаики предназначен для восстановления информации о цвете для каждого пикселя, интерполируя значения на основе соседних пикселей. DCCT использует понимание этого процесса для анализа статистических закономерностей в цветовых каналах и выявления аномалий, которые могут указывать на искусственное вмешательство или манипуляции с изображением.
В основе работы DCCT лежит анализ корреляции между цветовыми каналами изображения. Для этого применяется сегментация с использованием архитектуры U-Net, позволяющая различать естественно полученные и искусственно сгенерированные цветовые паттерны. U-Net выделяет области изображения, где цветовые зависимости соответствуют физическим свойствам процесса захвата изображения с использованием матрицы цветовых фильтров (CFA), в отличие от паттернов, возникающих при искусственной генерации или манипуляциях. Анализ этих цветовых корреляций позволяет DCCT выявлять несоответствия, указывающие на потенциальную подделку или манипуляцию с изображением.
В основе DCCT используется моделирование распределения цветовой корреляции с помощью смеси логистических функций. Этот подход позволяет более точно описать статистические зависимости между цветовыми каналами, чем традиционные методы. Для количественного сравнения полученных распределений и выявления различий между реальными и искусственно созданными изображениями применяется метрика Вассерштейна (Wasserstein Distance). W(P, Q) = \in f_{γ ∈ Π(P, Q)} E_{(x, y) \sim γ}[||x - y||], где Π(P, Q) — множество всех совместных распределений, имеющих маргиналы P и Q. Использование метрики Вассерштейна обеспечивает высокую чувствительность к изменениям в форме распределений, что критически важно для точного различения подлинных и сгенерированных изображений.

Экспериментальная Проверка и Важность Выборочных Данных
Для оценки эффективности DCCT-фреймворка использовались стандартные наборы данных, такие как ImageNet и MSCOCO, содержащие обширную коллекцию изображений, отражающих разнообразие реальных сцен и объектов. ImageNet включает более 14 миллионов изображений, классифицированных по более чем 20 тысячам категорий, а MSCOCO специализируется на задачах обнаружения объектов, сегментации и описания изображений, содержа более 330 тысяч изображений с аннотациями. Использование этих общедоступных наборов данных позволило провести объективное сравнение DCCT с другими существующими методами и продемонстрировать его способность к обобщению и устойчивости к различным типам изображений и условиям освещения.
В процессе оценки DCCT-фреймворка была специально включена оценка устойчивости к артефактам сжатия JPEG, широко распространенным в цифровых изображениях. Использование изображений, подвергшихся сжатию JPEG различной степени, позволило проверить способность метода к корректному функционированию в условиях, приближенных к реальным сценариям использования, где исходные данные часто содержат подобные искажения. Данный подход позволил оценить влияние артефактов сжатия на точность обнаружения и классификации изображений, а также подтвердить надежность DCCT в условиях сниженного качества входных данных.
Для визуализации пространства признаков и оценки степени различимости между реальными и сгенерированными изображениями использовались методы понижения размерности, в частности, t-SNE (t-distributed Stochastic Neighbor Embedding). t-SNE позволяет отобразить многомерные данные на плоскость, сохраняя при этом локальную структуру данных. Анализ полученных проекций позволил оценить, насколько хорошо DCCT различает реальные изображения из обучающей выборки и изображения, сгенерированные различными генеративными моделями, что является важным показателем эффективности одноклассового детектора. Разделение кластеров, полученное при визуализации, служит количественной мерой способности DCCT к обнаружению аномалий.
Метод DCCT демонстрирует передовые показатели обобщения и устойчивости, достигая средней точности в 97% на датасете GenImage. Данный результат превосходит показатели существующих методов на 8%. Полученные данные свидетельствуют о значительном улучшении в задачах классификации и обнаружения аномалий по сравнению с текущими решениями, что подтверждает эффективность предложенного подхода к обработке изображений и его способность к адаптации к различным типам данных.
При оценке на датасете DRCT-2M, DCCT продемонстрировал практически 100% точность на большинстве генераторов изображений. Данный датасет содержит 2 миллиона сгенерированных изображений, полученных с использованием различных методов, что позволяет оценить способность детектора к обобщению и устойчивости к разнообразным артефактам, присущим сгенерированным данным. Высокая точность на DRCT-2M указывает на эффективность DCCT в различении реальных и синтетических изображений даже при использовании сложных генеративных моделей.
Особенностью детектора DCCT является его способность достигать конкурентоспособной точности, будучи обученным исключительно на фотографических изображениях. Данный подход позволяет детектору эффективно различать реальные и сгенерированные изображения, несмотря на отсутствие данных о сгенерированных изображениях в процессе обучения. В ходе экспериментов было показано, что DCCT демонстрирует высокую производительность даже при использовании различных генеративных моделей и артефактов сжатия, что подтверждает его обобщающую способность и устойчивость к различным типам входных данных.

Перспективы Развития: К Надежному и Универсальному Обнаружению
Исследования в области обнаружения синтетических изображений должны быть направлены на повышение их обобщающей способности, чтобы эффективно работать с постоянно развивающимся спектром генеративных моделей и типов изображений. Существующие методы часто демонстрируют высокую точность на конкретном наборе данных, но быстро теряют эффективность при столкновении с изображениями, созданными другими моделями или отличающимися по визуальным характеристикам. Необходима разработка алгоритмов, устойчивых к изменениям в архитектуре генеративных сетей и способных адаптироваться к новым визуальным стилям, чтобы обеспечить надежное обнаружение подделок в широком диапазоне сценариев. Такой подход позволит создать системы, которые не просто распознают известные типы синтетических изображений, а способны идентифицировать любые манипуляции с изображениями, независимо от способа их создания.
Исследования показывают, что объединение метода DCCT с другими техниками обнаружения синтетических изображений может значительно повысить общую эффективность и устойчивость систем. Вместо того чтобы полагаться на один алгоритм, комбинация различных подходов позволяет компенсировать недостатки каждого из них и использовать их сильные стороны. Например, DCCT, фокусирующийся на анализе частотных артефактов, может быть успешно дополнен методами, исследующими несоответствия в текстуре или семантическом содержании изображения. Такой мультимодальный подход, использующий синергию нескольких детекторов, демонстрирует перспективные результаты в повышении надежности выявления сгенерированных изображений, особенно в условиях, когда генеративные модели становятся все более изощренными и способны создавать реалистичные подделки.
Разработка методов объяснимого искусственного интеллекта (XAI) становится ключевым фактором в контексте обнаружения синтетических изображений. Недостаточно просто определить, что изображение сгенерировано искусственно; необходимо понимать, какие конкретно признаки привели к такому заключению. Это требует создания алгоритмов, способных не только выявлять манипуляции, но и предоставлять прозрачное обоснование своего решения, например, указывая на артефакты генерации, несоответствия в освещении или неестественные текстуры. Такой подход крайне важен для построения доверия к системам обнаружения, поскольку позволяет пользователям и заинтересованным сторонам оценить надежность результатов и выявить потенциальные смещения. Более того, объяснимость является необходимой предпосылкой для обеспечения ответственности и возможности аудита, особенно в ситуациях, когда решения, основанные на обнаружении синтетических изображений, могут иметь серьезные последствия.
Исследование, представленное в данной работе, демонстрирует элегантность подхода к обнаружению изображений, сгенерированных искусственным интеллектом. Авторы, подобно искусным архитекторам, обращаются к фундаментальным принципам цветовоспроизведения, а именно к корреляциям, возникающим в процессе демозаики, чтобы выявить следы машинного вмешательства. Эта методика DCCT, основанная на тонком понимании цветовых особенностей, позволяет преодолеть ограничения существующих алгоритмов, обеспечивая обобщающую способность и устойчивость к различным генеративным моделям. Как однажды заметил Джеффри Хинтон: «Мы должны стремиться к созданию систем, которые учатся, как учатся люди». В данном случае, обучение системы основано на глубоком анализе базовых принципов формирования изображения, что позволяет достичь высокой точности и надежности.
Куда же дальше?
Представленная работа, безусловно, демонстрирует элегантность подхода, используя тонкости цветокорреляций, заложенных в самом процессе формирования изображения камерой. Однако, следует признать, что совершенство недостижимо. Обнаружение артефактов, создаваемых генеративными моделями, подобно попытке поймать ускользающую тень. Каждая новая модель — это новая иллюзия, требующая переосмысления существующих методов. Вопрос не в том, чтобы создать “непробиваемую” систему, а в том, чтобы разработать адаптивные алгоритмы, способные улавливать даже самые тонкие несоответствия.
В дальнейшем, представляется перспективным углубленное изучение влияния различных типов сенсоров и алгоритмов демозаики на характеристики цветокорреляций. Не менее важным представляется исследование возможности использования не только статистических, но и перцептивных метрик для оценки качества и реалистичности изображений. Ведь красота — понятие субъективное, а задача алгоритма — приблизиться к ней настолько, насколько это возможно.
Наконец, следует признать, что борьба с искусственными изображениями — это бесконечный танец. Каждая победа — это лишь временная передышка, после которой начинается новый раунд. И в этом, возможно, и заключается истинная красота этой области — в постоянном стремлении к совершенству, которое никогда не будет достигнуто.
Оригинал статьи: https://arxiv.org/pdf/2601.22778.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-02-03 02:46