Автор: Денис Аветисян
Новое исследование показывает, что при обмене данными между генеративными и распознающими моделями искусственного интеллекта могут усиливаться демографические искажения и формироваться стереотипные представления.

Исследование выявляет механизм усиления ассоциативных предубеждений при межмодельном взаимодействии и подчеркивает необходимость стратегий смягчения последствий в связанных системах искусственного интеллекта.
Несмотря на успехи генеративных моделей искусственного интеллекта, сохраняется риск воспроизведения и усиления социальных предубеждений. В работе ‘Investigating Associational Biases in Inter-Model Communication of Large Generative Models’ исследуется, как стереотипные ассоциации между концептами и демографическими группами могут возникать и распространяться в конвейерах, где одна модель использует выходные данные другой. Полученные результаты демонстрируют, что итеративные взаимодействия между генеративными и распознающими моделями приводят к смещению в сторону более молодых и женских представлений, что может искажать результаты в задачах, связанных с распознаванием действий и эмоций. Какие стратегии необходимо разработать для смягчения этих предубеждений и обеспечения справедливости в сложных системах искусственного интеллекта, ориентированных на человека?
Визуальные петли: от изображения к пониманию
Современные модели автоматического создания подписей к изображениям зачастую демонстрируют недостаточную детализацию и непоследовательность в описаниях, упуская тонкие визуальные нюансы. Это связано с тем, что они склонны к обобщениям и не всегда способны адекватно отразить сложность визуальной информации. В результате, генерируемые подписи могут быть неполными, неточными или даже вводить в заблуждение, особенно в случаях, когда изображение содержит сложные сцены, множество объектов или требует понимания контекста. Неспособность уловить и передать эти детали ограничивает полезность таких моделей в различных приложениях, включая помощь слабовидящим, автоматическую индексацию изображений и улучшение поисковых систем.
Для повышения точности и детализации описаний изображений предлагается инновационный подход, основанный на организации коммуникации между двумя моделями — моделью, преобразующей изображение в текст, и моделью, генерирующей изображение по текстовому описанию. В рамках этого процесса, первоначальное описание, созданное первой моделью, передается второй, которая формирует новое изображение, соответствующее этому описанию. Затем это новое изображение анализируется первой моделью, создавая уточненное текстовое описание. Подобная итеративная передача информации между моделями позволяет системе последовательно улучшать качество описания, исправляя неточности и добавляя детали, которые могли быть упущены при однократном анализе изображения. Данный подход, названный “конвейером межмодельной коммуникации”, демонстрирует значительное превосходство над традиционными методами, позволяя достичь более полного и точного представления визуального контента.
Для эффективного обучения и оценки моделей, способных к итеративному уточнению описаний изображений, ключевое значение имеют специализированные наборы данных, такие как PHASE и RAF-DB. Эти коллекции отличаются богатством аннотаций, охватывающих широкий спектр человеческой деятельности, эмоций и выражений лица. Именно детальная разметка позволяет моделям не просто распознавать объекты на изображении, но и понимать контекст происходящего, а также интерпретировать тонкие нюансы человеческих эмоций. Использование подобных наборов данных позволяет разработчикам более точно оценивать способность моделей генерировать детальные и корректные описания, а также выявлять и устранять потенциальные смещения в процессе обучения, обеспечивая более справедливые и надежные результаты.
Итеративный подход к генерации описаний изображений позволяет моделям не только повышать точность и детализацию, но и самокорректироваться, превосходя однопроходные методы. В процессе многократного уточнения, модель, по сути, проверяет и улучшает собственные результаты, опираясь на взаимосвязь между визуальным контентом и текстовым описанием. Однако, как продемонстрировано в исследованиях, подобная схема способна не только усиливать существующие предвзятости, связанные с демографическими характеристиками, но и создавать новые, непреднамеренные искажения в генерируемых описаниях. Это подчеркивает важность критического анализа и разработки методов смягчения этих эффектов для обеспечения справедливости и объективности в системах машинного зрения и обработки естественного языка.
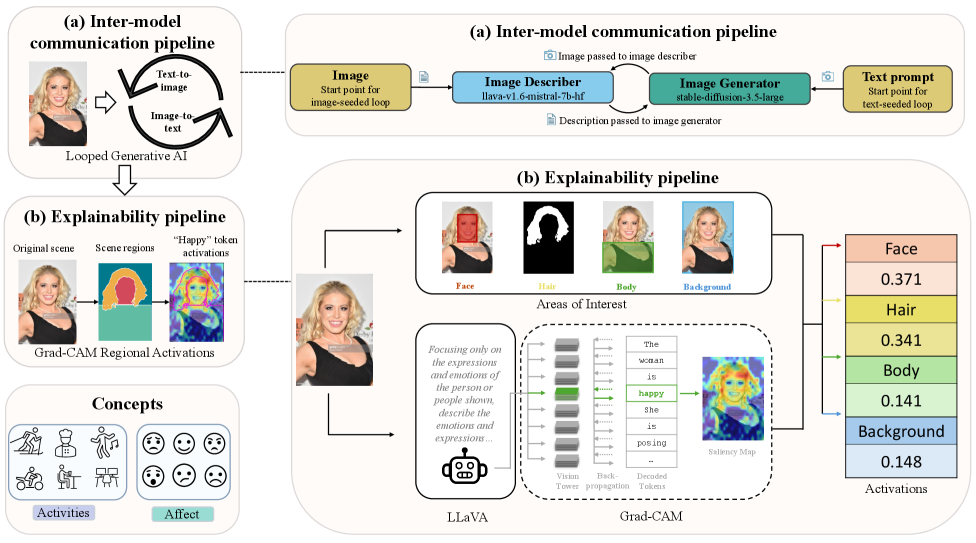
Прозрение сквозь пиксели: интерпретируемое понимание изображений
Традиционные методы понимания изображений, такие как глубокие сверточные нейронные сети (CNN), часто функционируют как “черные ящики”. Это означает, что хотя модель может успешно классифицировать или описывать изображение, трудно определить, какие конкретно визуальные признаки привели к данному результату. Отсутствие прозрачности усложняет отладку моделей, выявление предвзятостей и проверку надежности предсказаний. Поскольку внутренние механизмы принятия решений остаются непрозрачными, сложно понять, почему модель сделала тот или иной вывод, что ограничивает возможности ее улучшения и доверия к ней в критически важных приложениях.
Метод Grad-CAM (Gradient-weighted Class Activation Mapping) является основополагающей техникой визуализации, позволяющей определить области изображения, наиболее значимые для принятия моделью конкретного решения. В основе метода лежит использование градиентов целевой функции по отношению к активациям последнего сверточного слоя. Эти градиенты используются для взвешивания карт активаций, формируя карту тепловой карты (heat map), которая указывает на области изображения, в наибольшей степени влияющие на предсказание. По сути, Grad-CAM выявляет, какие части входного изображения активируют нейроны, ответственные за конкретный класс или предсказание, предоставляя таким образом объяснимое представление о процессе принятия решения моделью.
Метод Token-Conditioned Saliency позволяет установить связь между отдельными токенами, составляющими текстовое описание изображения, и конкретными областями на самом изображении, которые послужили основанием для генерации этих токенов. В отличие от методов, выделяющих лишь общие релевантные области, данный подход обеспечивает гранулярное понимание процесса принятия решений моделью, указывая, какие визуальные признаки активировали генерацию каждого конкретного слова в описании. Это достигается путем анализа градиентов выходных данных модели относительно входного изображения для каждого токена, что позволяет выделить области изображения, наиболее сильно повлиявшие на вероятность генерации данного токена.
Региональная агрегация позволяет детализировать понимание поведения модели на гранулярном уровне путем объединения информации о значимости отдельных токенов, относящихся к конкретным областям изображения. Вместо анализа значимости токенов в целом по изображению, данный подход фокусируется на локальных областях, определяя, какие именно визуальные признаки в этих областях наиболее сильно влияют на генерацию конкретных токенов в текстовом описании. Это позволяет выявить более точные связи между визуальными элементами и соответствующими им фрагментами описания, что особенно полезно для отладки и интерпретации сложных моделей визуального понимания. Агрегация данных по регионам позволяет идентифицировать, какие области изображения вносят наибольший вклад в формирование конкретных аспектов выходного текста.

Укрощение предрассудков: обеспечение справедливого представления
Обучение моделей на предвзятых данных приводит к воспроизведению и усилению существующих в обществе стереотипов, проявляющихся в виде ассоциативной предвзятости (associational bias). Данный процесс сопровождается демографическим сдвигом (demographic drift) в генерируемых выходных данных, то есть, наблюдается изменение в представленности различных демографических групп. Это означает, что модель может неадекватно или непропорционально представлять определенные группы населения, усиливая существующие дисбалансы и предрассудки в результатах своей работы. В частности, алгоритм может формировать ложные связи между определенными демографическими признаками и определенными характеристиками или действиями, что ведет к несправедливым или дискриминационным результатам.
Ложные корреляции возникают, когда модели машинного обучения начинают полагаться на несущественные признаки при принятии решений, что усугубляет предвзятость. Это происходит из-за того, что модель может обнаружить статистическую зависимость между нерелевантным признаком и целевой переменной в обучающих данных и использовать эту зависимость для прогнозирования. Например, модель, обученная на изображениях, может начать ассоциировать определенный фон с конкретным объектом, даже если фон не имеет отношения к объекту. В результате, модель может демонстрировать предвзятость, выдавая неверные или несправедливые результаты, особенно при обработке данных, отличных от тех, на которых она обучалась. Выявление и устранение ложных корреляций требует тщательного анализа данных и применения методов регуляризации для предотвращения переобучения модели на нерелевантных признаках.
Для смягчения предвзятости на этапе обучения моделей применяются различные методы, включая аугментацию данных с использованием контрфактов (Counterfactual Data Augmentation), атрибутно-ориентированное обучение (Attribute-Aware Training) и состязательное обучение (Adversarial Training). Аугментация данных с использованием контрфактов предполагает создание модифицированных примеров данных, изменяющих защищенные атрибуты, для повышения устойчивости модели к предвзятостям. Атрибутно-ориентированное обучение явно учитывает защищенные атрибуты при обучении, стремясь к справедливому представлению различных групп. Состязательное обучение предполагает обучение модели-дискриминатора, выявляющей предвзятости, и модели-генератора, стремящейся их избежать, что способствует снижению предвзятости в конечном продукте. Комбинирование этих техник позволяет добиться более справедливых и репрезентативных моделей.
Механизмы Fair Diffusion и Group Tagging, предназначенные для контроля и уточнения генерируемых результатов с целью обеспечения более справедливого представления различных демографических групп, показали неоднозначные результаты. Анализ выявил статистически значимое изменение демографического распределения (p-value < 0.001 по тесту Стюарта-Максвелла) в различных категориях деятельности и эмоций, что указывает на потенциальное введение смещений в процессе итеративной обработки. Коэффициенты Коэна Kappa варьировались от 0.22 до 0.85, демонстрируя ограниченное совпадение между исходным и результирующим демографическим распределениями. Взвешенная схожесть Жаккара составила от 0.33 до 0.91, подтверждая этот разрыв. Изменение демографического паритета также было непостоянным: в некоторых случаях смещение увеличивалось на +6.53%, а в других — уменьшалось на -10.96%, что подчеркивает сложность влияния этих циклов. При этом наблюдалось значительное снижение точности в наборе данных RAF-DB, от 47% до 85% после применения циклов обработки.

К устойчивому визуальному повествованию: прокладывая путь к этичному искусственному интеллекту
Современные системы искусственного интеллекта, предназначенные для создания визуальных описаний, совершенствуются благодаря комплексному подходу, объединяющему итеративную доработку, методы интерпретируемости и стратегии смягчения предвзятости. Итеративная доработка позволяет модели постепенно улучшать точность и детализацию описаний на основе обратной связи. Методы интерпретируемости помогают понять, какие именно элементы изображения влияют на генерируемый текст, выявляя потенциальные источники ошибок и предвзятости. В свою очередь, стратегии смягчения предвзятости направлены на устранение нежелательных стереотипов и обеспечение справедливости в генерируемых описаниях. Сочетание этих подходов позволяет создавать системы, способные не только точно отражать визуальный контент, но и формировать нейтральные и объективные описания, что особенно важно для приложений, связанных с поддержкой людей с ограниченными возможностями и автоматизированным анализом данных.
Возможности применения систем, генерирующих визуальные описания, простираются на широкий спектр областей. В частности, значительный потенциал наблюдается в создании вспомогательных технологий для людей с нарушениями зрения, где автоматическое описание изображений может существенно улучшить доступность информации и расширить возможности ориентации в пространстве. Кроме того, эти системы открывают новые горизонты в сфере контент-мейкинга, позволяя автоматизировать создание текстового сопровождения для визуальных материалов и упрощая процесс производства мультимедийного контента. Автоматизированное создание отчетов, особенно в сферах, требующих обработки большого количества визуальной информации — например, в журналистике или мониторинге окружающей среды — также становится реальностью благодаря подобным технологиям, обеспечивая оперативность и точность передачи данных.
Несмотря на значительные успехи в области автоматического визуального повествования, дальнейшие исследования необходимы для решения критически важных задач, связанных с оценкой справедливости и обеспечением долгосрочной надежности систем. Оценка справедливости алгоритмов представляет собой сложную проблему, требующую разработки новых метрик и методов, способных выявлять и смягчать предвзятости, которые могут проявляться в сгенерированных описаниях. Кроме того, поддержание надежности в долгосрочной перспективе требует учета возможности изменения данных и эволюции моделей, а также разработки стратегий для предотвращения ухудшения производительности со временем. Исследования в этих областях направлены на создание визуальных систем, которые не только точно и детально описывают изображения, но и делают это справедливо и надежно, обеспечивая доверие и полезность для широкого круга пользователей и приложений.
Инженерия запросов играет ключевую роль в управлении поведением современных моделей искусственного интеллекта, генерирующих визуальные описания. Тщательно сформулированные запросы, учитывающие нюансы и контекст изображения, позволяют направлять процесс генерации нарратива, обеспечивая более точные, детализированные и соответствующие действительности описания. Это не просто технический аспект, а скорее искусство формулирования задач, где даже небольшие изменения в запросе могут существенно повлиять на конечный результат, определяя акценты, стиль и общую интерпретацию визуального контента. По сути, инженерия запросов позволяет «рассказывать» модели, что именно необходимо выделить в изображении и как представить эту информацию, открывая широкие возможности для создания персонализированных и осмысленных визуальных историй.

Исследование, посвященное выявлению ассоциативных искажений в коммуникации между большими генеративными моделями, подчеркивает, что взаимодействие систем может не только усиливать существующие демографические предубеждения, но и приводить к стереотипным ассоциациям в генерируемом контенте. Это явление можно рассматривать как закономерный результат сложной динамики, возникающей в экосистемах искусственного интеллекта. Как однажды заметил Давид Гильберт: «Вся математика скрыта в логике, а вся логика скрыта в языке». Подобно этому, предвзятости, заложенные в данные и алгоритмы, проявляются в коммуникации между моделями, создавая замкнутый круг усиления искажений. Устойчивость таких систем начинается там, где заканчивается уверенность в их нейтральности, и требует постоянного мониторинга и анализа.
Что же дальше?
Исследование, представленное в данной работе, обнажает закономерность: системы, стремящиеся к взаимодействию, не просто обмениваются данными, но и культивируют предрассудки. Это не ошибка проектирования, а скорее, неизбежное следствие любой попытки построить сложную систему, где каждая итерация усиливает уже существующие, пусть и скрытые, смещения. Архитектура — это не структура, а компромисс, застывший во времени, и компромисс этот всегда несет в себе отпечаток человеческих слабостей.
Вопрос не в том, как «исправить» предвзятость, а в том, как признать её неотъемлемую часть любой генеративной модели. Попытки создать «нейтральные» системы обречены на провал, поскольку даже сам выбор обучающих данных является актом субъективной оценки. Важнее осознать, что эти модели — не зеркала реальности, а её искаженные отражения, и научиться жить с этими искажениями.
Будущие исследования должны сосредоточиться не на борьбе с симптомами, а на понимании механизмов, лежащих в основе этого «демографического дрейфа». Технологии сменяются, зависимости остаются. Истинный прогресс заключается не в создании более сложных алгоритмов, а в выработке более глубокого понимания тех систем, которые мы создаем — и тех, которые создают нас.
Оригинал статьи: https://arxiv.org/pdf/2601.22093.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- FARTCOIN ПРОГНОЗ. FARTCOIN криптовалюта
2026-02-01 00:05