Автор: Денис Аветисян
Новая архитектура A2RAG позволяет эффективно извлекать и использовать знания из графов для получения точных и обоснованных ответов на сложные вопросы.
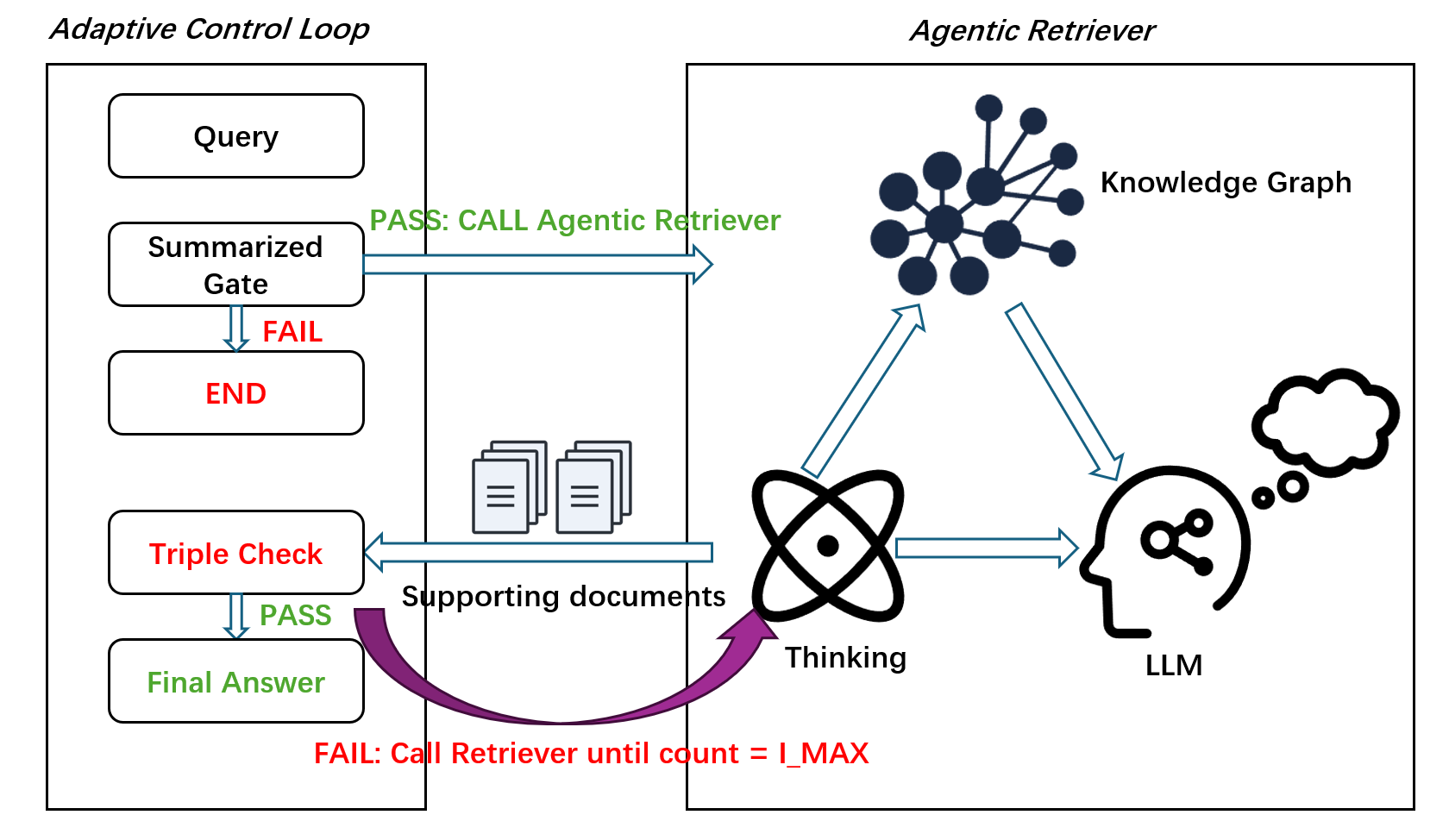
A2RAG — это адаптивная система поиска по графам знаний, повышающая эффективность и надёжность ответов в задачах, требующих многоступенчатого рассуждения и доступа к исходным данным.
Несмотря на успехи методов извлечения знаний из графов, существующие системы часто сталкиваются с проблемами при обработке сложных запросов и ограниченных данных. В данной работе представлена система ‘A2RAG: Adaptive Agentic Graph Retrieval for Cost-Aware and Reliable Reasoning’, предлагающая адаптивный и агентский подход к поиску и извлечению знаний из графов. A2RAG позволяет повысить эффективность и надежность многошагового логического вывода за счет динамического управления поиском и восстановления деталей из исходных текстов, даже при неполноте графа знаний. Сможет ли такой подход существенно снизить затраты и улучшить качество ответов в задачах, требующих глубокого понимания и анализа информации?
Пределы Традиционного Поиска
Несмотря на впечатляющие способности к генерации текста и пониманию языка, большие языковые модели (БЯМ) сталкиваются с трудностями при решении задач, требующих глубокого, многоступенчатого рассуждения. Эта проблема обусловлена фундаментальными ограничениями в области “заземления” — способности БЯМ надежно связывать языковые конструкции с реальными фактами и знаниями. Модели, обученные на огромных объемах текстовых данных, часто оперируют статистическими закономерностями, а не истинным пониманием, что приводит к ошибкам при построении логических цепочек и выводов, требующих синтеза информации из нескольких источников. В результате, БЯМ могут генерировать грамматически правильные и правдоподобные ответы, но при этом не способны к надежному решению сложных задач, требующих критического анализа и подтверждения фактов.
Традиционные методы извлечения информации, несмотря на свою кажущуюся простоту, часто оказываются неспособными уловить тонкие взаимосвязи, необходимые для поддержки сложных процессов рассуждения. В отличие от человеческого мышления, способного к ассоциативному поиску и интеграции разрозненных фактов, стандартные алгоритмы полагаются на прямое соответствие ключевых слов или фраз. Это приводит к тому, что важные контекстуальные детали и неявные связи между данными остаются незамеченными, что, в свою очередь, ведет к неточным или неполным ответам на сложные вопросы. Подобные ограничения особенно заметны в задачах, требующих многоступенчатого логического вывода, где для достижения верного решения необходимо учитывать множество факторов и взаимосвязанных данных, которые не всегда очевидны при поверхностном анализе.
GraphRAG: Структурирование Знаний для Рассуждений
GraphRAG решает проблему неструктурированности информации путем явного моделирования знаний в виде графа знаний. В этом подходе, сущности и связи между ними представляются в структурированном формате, где узлы графа соответствуют сущностям (например, объектам, понятиям, событиям), а ребра — взаимосвязям между ними (например, «является частью», «принадлежит», «вызывает»). Такое представление позволяет системе не только хранить информацию, но и понимать ее семантическую структуру, что необходимо для более точного извлечения релевантных данных и выполнения логических выводов.
Использование графа знаний в GraphRAG обеспечивает более эффективный поиск релевантной информации за счет явного представления сущностей и связей между ними. В отличие от традиционных методов, основанных на векторном поиске, GraphRAG позволяет учитывать структуру данных и логические зависимости между элементами, что существенно повышает точность извлечения информации. Это особенно важно для задач, требующих анализа сложных взаимосвязей, где поиск по ключевым словам может быть недостаточным. Основываясь на структурированном представлении знаний, GraphRAG может не только находить релевантные фрагменты текста, но и выводить новые знания на основе существующих связей, улучшая качество генерируемых ответов и обеспечивая более глубокое понимание контекста.
GraphRAG усовершенствует подход Retrieval-Augmented Generation (RAG) за счет интеграции поиска на основе графов. Вместо традиционного поиска по текстовым фрагментам, GraphRAG использует структурированное представление знаний в виде графа, где узлы — это сущности, а ребра — связи между ними. Это позволяет системе не просто находить релевантные документы, но и учитывать взаимосвязи между сущностями, что значительно улучшает точность и обоснованность генерируемых ответов. Использование графового поиска обеспечивает более глубокое понимание контекста и позволяет находить информацию, которая может быть неявно связана с исходным запросом, повышая надежность и достоверность сгенерированного контента.
A2RAG: Адаптивный и Агентский Поиск
A2RAG развивает архитектуру GraphRAG за счет внедрения адаптивного контура управления, обеспечивающего итеративную доработку запросов и верификацию извлеченных данных посредством механизма Triple-Check. Данный контур позволяет системе динамически корректировать поисковые запросы на основе промежуточных результатов, повышая точность и релевантность найденной информации. Triple-Check включает в себя многократную проверку извлеченных фактов, обеспечивая более надежное подтверждение ответов и минимизируя вероятность получения недостоверных данных. Этот подход позволяет A2RAG адаптироваться к сложности запроса и специфике источника информации, улучшая общую производительность системы.
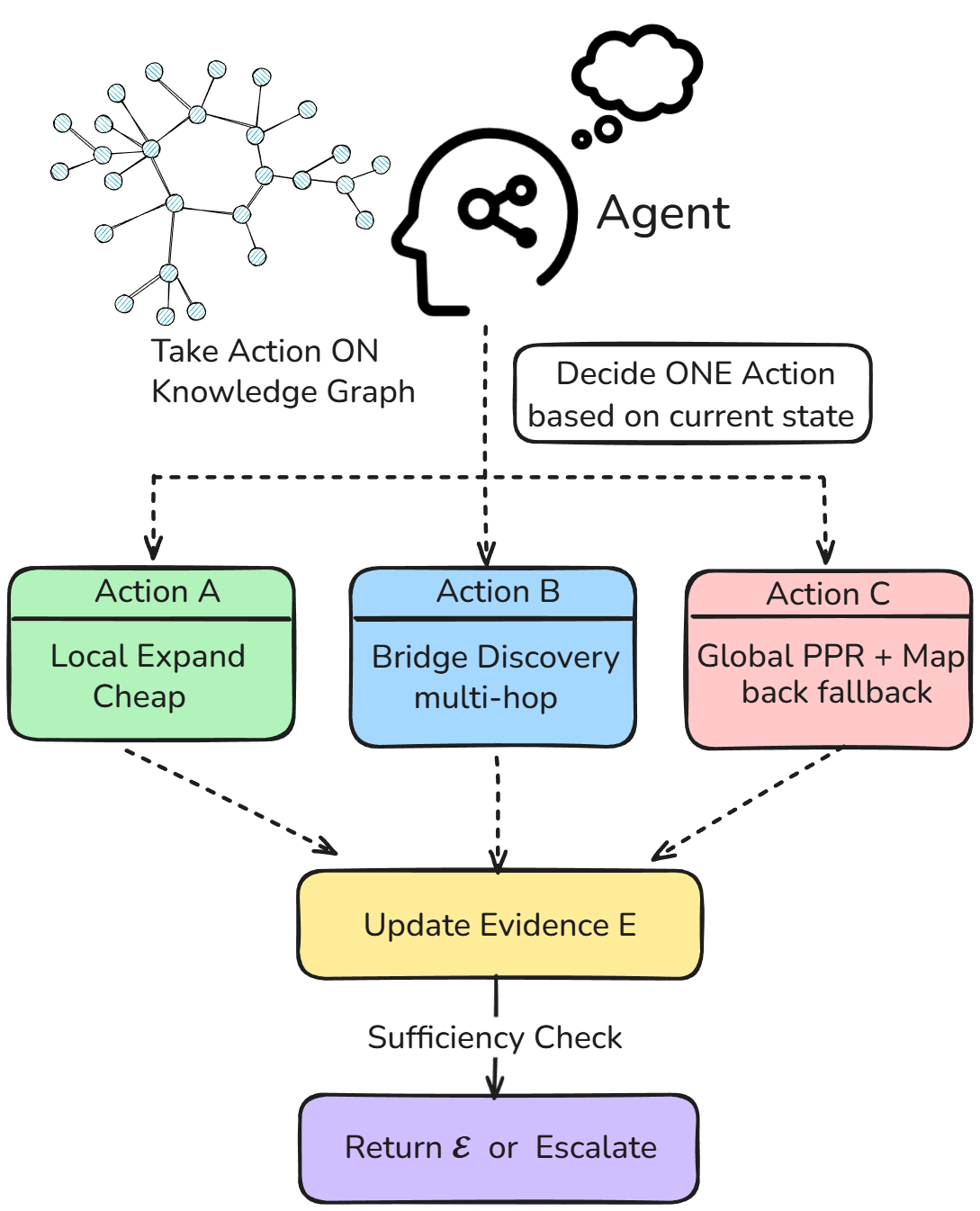
Компонент Agentic Retriever использует алгоритм Personalized PageRank для выявления прогрессивных доказательств, основываясь на индивидуальных предпочтениях и релевантности источников. Метод Provenance Map-back отслеживает происхождение информации, позволяя реконструировать цепочку рассуждений и подтверждать достоверность данных. Приоритет отдается локальной политике поиска, что означает предпочтение источников, расположенных ближе к исходному запросу, для обеспечения более полного охвата релевантной информации и повышения эффективности поиска.
В A2RAG для направления поиска Agentic Retriever используются Entity Seed и Relation Seed. Entity Seed представляет собой набор ключевых сущностей, релевантных запросу, что позволяет сузить область поиска и сконцентрироваться на значимых объектах. Relation Seed определяет релевантные отношения между этими сущностями, направляя поиск по связям и контексту. Использование этих “семян” обеспечивает более целенаправленный сбор доказательств, повышая точность и эффективность поиска информации, особенно в задачах, требующих многошагового рассуждения и понимания взаимосвязей между различными фактами.
В ходе оценок было установлено, что A2RAG демонстрирует улучшение показателя полноты (Recall) до 15% по сравнению с существующими методами. В частности, на датасете HotpotQA система достигает Recall@2 в 62.4% и Recall@5 в 73.6%, а на 2WikiMultiHopQA — Recall@2 в 58.9% и Recall@5 в 69.2%. Эти результаты свидетельствуют о повышенной способности A2RAG находить релевантную информацию в сложных запросах, требующих анализа нескольких источников.
В ходе оценки A2RAG продемонстрировала следующие показатели точности поиска: на наборе данных HotpotQA система достигла Recall@2 в 62.4% и Recall@5 в 73.6%, что указывает на способность находить релевантные документы среди первых двух и пяти результатов соответственно. На более сложном наборе данных 2WikiMultiHopQA A2RAG показала Recall@2 в 58.9% и Recall@5 в 69.2%. Данные результаты свидетельствуют о высокой эффективности A2RAG в задачах многошагового поиска и извлечения информации из различных источников.
В ходе тестирования A2RAG продемонстрировала существенные улучшения в эффективности по сравнению с моделью IRCoT при обработке многошаговых запросов. В частности, зафиксировано снижение потребления токенов на 50% и уменьшение средней задержки (mean latency) на 40%. Эти улучшения достигаются за счет оптимизированного процесса поиска и извлечения информации, что позволяет A2RAG обрабатывать сложные запросы с меньшими вычислительными затратами и более высокой скоростью ответа.
Валидация и Более Широкие Последствия
Оценки, проведенные на авторитетных эталонных наборах данных, таких как HotpotQA и 2WikiMultiHopQA, однозначно демонстрируют превосходство A2RAG над традиционными методами извлечения и генерации ответов. В ходе этих тестов, A2RAG показал значительное улучшение показателей точности и полноты ответов, особенно в задачах, требующих сложного рассуждения и объединения информации из нескольких источников. Преимущества A2RAG проявляются в его способности более эффективно извлекать релевантные фрагменты знаний и генерировать ответы, которые не только точны, но и подкреплены убедительными доказательствами, что делает его перспективным решением для систем ответов на вопросы и интеллектуального поиска.
Система A2RAG демонстрирует значительное улучшение качества и достоверности ответов за счет смягчения проблемы, известной как “потеря извлечения” (Extraction Loss). Традиционные методы часто упускают важные детали при извлечении информации из больших объемов текста, что приводит к неполным или неточным ответам. A2RAG, напротив, фокусируется на восстановлении этих тонких нюансов, позволяя более полно и точно отвечать на сложные вопросы. Благодаря этому подходу, система способна улавливать и учитывать даже незначительные детали, которые критически важны для формирования надежного и обоснованного ответа, что повышает доверие к предоставляемой информации и делает её более ценной для пользователя.
Механизм итеративного поиска, реализованный в A2RAG, позволяет системе не просто извлекать информацию, но и последовательно уточнять запрос и углублять понимание контекста. В отличие от традиционных методов, выполняющих поиск один раз, A2RAG циклически пересматривает и расширяет релевантные фрагменты, что особенно важно для решения сложных задач, требующих логических выводов и синтеза информации из различных источников. Этот подход позволяет системе улавливать тонкие нюансы и взаимосвязи, которые могли бы остаться незамеченными при однократном поиске, что, в свою очередь, значительно повышает точность и содержательность ответов, а также обеспечивает более глубокое осмысление представленных данных.
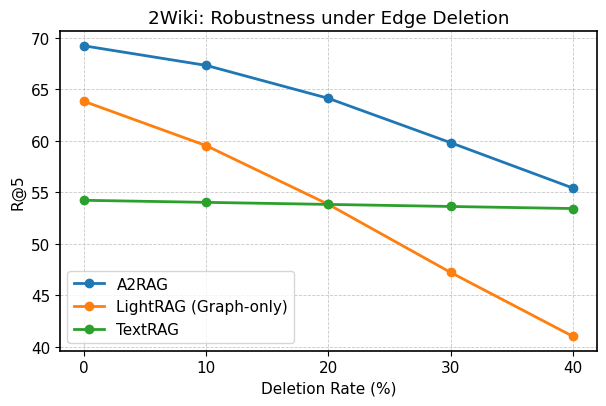
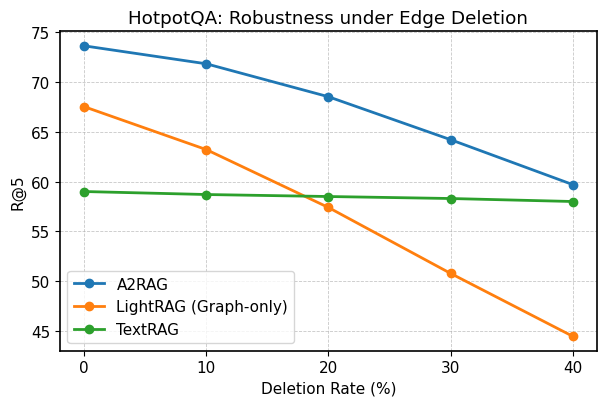
Исследования показали, что система A2RAG демонстрирует высокую устойчивость к неполноте знаний. В ходе тестирования на наборе данных HotpotQA, даже при искусственном удалении 40% узлов и связей из базы знаний, система сохраняет показатель Recall@5 на уровне 59.7%. Это свидетельствует о способности A2RAG эффективно извлекать и использовать релевантную информацию, несмотря на пробелы в исходных данных, что особенно важно для приложений, работающих с динамично меняющимися или неполными источниками знаний. Такая устойчивость позволяет системе предоставлять более надежные и точные ответы, даже в условиях неопределенности.
Исследование, представленное в данной работе, демонстрирует, что даже несовершенные графы знаний могут служить основой для надежного и экономичного поиска информации. Система A2RAG, адаптируя процесс извлечения данных, постепенно формирует доказательную базу, возвращаясь к первоисточникам для уточнения деталей. Это напоминает о важности неспешного и вдумчивого подхода к познанию. Как однажды заметил Алан Тьюринг: «Иногда лучше наблюдать за процессом, чем пытаться ускорить его». В контексте A2RAG, адаптивное извлечение информации позволяет системе не просто находить ответы, а понимать путь к ним, восстанавливая контекст и обеспечивая прозрачность рассуждений. Таким образом, система учится стареть достойно, извлекая максимум пользы из доступных данных, даже если они не идеальны.
Что дальше?
Представленный подход, стремящийся к адаптивному извлечению знаний из графов, обнажает неизбежную истину: любая система, даже самая тщательно спроектированная, подвержена эрозии. Граф, как и любая структура, хранящая информацию, не является статичной записью истины, а скорее динамичным отголоском времени. Успех A2RAG в восстановлении деталей из исходных текстов — это не триумф над несовершенством графов, а признание его. Каждый сбой в извлечении — это сигнал времени, напоминание о том, что знание не существует в вакууме, а формируется в контексте изменяющейся реальности.
Будущие исследования, вероятно, будут сосредоточены не на создании идеальных графов, а на разработке систем, способных эффективно функционировать в условиях их неполноты и изменчивости. Важным направлением представляется изучение механизмов самокоррекции и адаптации, позволяющих системе не просто извлекать информацию, но и критически оценивать её достоверность и актуальность. Рефакторинг — это диалог с прошлым, а не попытка его игнорировать.
В конечном счете, задача заключается не в увеличении объема хранимой информации, а в развитии способности системы извлекать из неё смысл, даже когда сама информация фрагментирована и несовершенна. В этом и заключается истинная мера её устойчивости и долговечности. Иначе говоря, вопрос не в том, как долго прослужит система, а в том, насколько достойно она состарится.
Оригинал статьи: https://arxiv.org/pdf/2601.21162.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-01-31 20:48