Автор: Денис Аветисян
Представленная в статье система ASTRA позволяет создавать сложные сценарии взаимодействия для обучения языковых моделей с использованием инструментов и подкрепляющего обучения.

ASTRA — это фреймворк для автоматизированного синтеза траекторий действий и сред обучения с подкреплением, демонстрирующий передовые результаты на бенчмарках, требующих проявления инициативы.
Несмотря на растущую популярность больших языковых моделей (LLM) в качестве автономных агентов, обучение надежным системам, способным к многошаговому принятию решений, остается сложной задачей. В данной работе представлена система ‘ASTRA: Automated Synthesis of agentic Trajectories and Reinforcement Arenas’, предназначенная для автоматизированного обучения LLM с использованием масштабируемого синтеза данных и верифицируемого обучения с подкреплением. ASTRA позволяет создавать разнообразные траектории взаимодействия и среды обучения, обеспечивая устойчивое и эффективное освоение навыков использования инструментов. Сможет ли предложенный подход значительно упростить процесс обучения агентских систем и приблизить их к возможностям закрытых разработок?
Построение Семантической Среды для Рассуждений
Современные языковые модели, несмотря на впечатляющие успехи в обработке текста, часто испытывают затруднения при решении задач, требующих многоступенчатого логического вывода. Их способность к комплексному рассуждению ограничена, особенно когда требуется не просто распознать информацию, а последовательно анализировать данные, делать промежуточные выводы и, на их основе, приходить к конечному решению. Эта проблема особенно заметна в ситуациях, где требуется понимание контекста, выявление скрытых связей и применение знаний из различных областей. В отличие от человека, способного к гибкому и адаптивному мышлению, языковые модели склонны к ошибкам при столкновении со сложными логическими конструкциями и неоднозначными условиями, что подчеркивает необходимость разработки новых подходов к моделированию рассуждений.
Существенное ограничение современных языковых моделей заключается в отсутствии структурированной среды, необходимой для обоснования и проверки процессов рассуждений. В отличие от человека, способного опираться на накопленный опыт и контекст, модели зачастую оперируют изолированными фрагментами информации. Это приводит к ошибкам в сложных задачах, требующих последовательного применения логики и знаний. Отсутствие возможности верифицировать каждый шаг рассуждений лишает систему надежности и способности к самокоррекции. В результате, даже при кажущейся логичности, выводы модели могут оказаться ошибочными или нерелевантными реальному миру, поскольку отсутствует механизм, позволяющий подтвердить или опровергнуть правильность промежуточных и конечных результатов.
Для создания действительно надёжных интеллектуальных агентов необходимо уловить и воспроизвести лежащую в основе человеческого мышления «семантическую топологию». Речь идет не просто о хранении фактов, а о понимании взаимосвязей между ними, о том, как знания организованы и используются для решения задач. Именно структура этих взаимосвязей, подобная карте местности, позволяет человеку эффективно рассуждать, делать выводы и адаптироваться к новым ситуациям. Воспроизведение этой топологии в искусственном интеллекте потребует не только улучшения алгоритмов обработки информации, но и создания систем, способных моделировать и использовать контекст, аналогично тому, как это делает человеческий мозг, что открывает путь к созданию агентов, способных к более глубокому пониманию и рассуждению.
Предлагается новая структура, в основе которой лежит создание проверяемых сред на основе пар «вопрос-ответ». Данный подход позволяет языковой модели не просто оперировать информацией, но и подтверждать свои выводы в специально сконструированном контексте. Фактически, каждая пара вопросов и ответов становится основой для моделирования небольшой «вселенной», где можно проверить логическую последовательность рассуждений. Создавая такие среды, исследователи стремятся преодолеть ограничения существующих моделей, которые часто демонстрируют неуверенность при решении задач, требующих многоступенчатого анализа и подтверждения. Вместо абстрактных вычислений, модель получает возможность «проверять» свои ответы, опираясь на заданные правила и взаимосвязи внутри этой искусственно созданной среды, что существенно повышает надежность и обоснованность получаемых результатов.
Обучение с Контролируемой Адаптацией для Многошагового Взаимодействия
Предварительное обучение модели с использованием контролируемой тонкой настройки (SFT) значительно повышает ее начальную производительность при взаимодействии с инструментами. SFT предполагает обучение модели на размеченном наборе данных, демонстрирующем правильное использование инструментов для решения конкретных задач. Этот этап позволяет модели усвоить базовые принципы функционирования инструментов, синтаксис запросов и ожидаемые форматы ответов, что существенно упрощает и ускоряет дальнейшее обучение с подкреплением. Без предварительной тонкой настройки, модель испытывает значительные трудности в освоении даже простых операций с инструментами, требуя гораздо больше данных и вычислительных ресурсов для достижения приемлемого уровня производительности.
На этапе контролируемой тонкой настройки (SFT) для обучения базовому использованию инструментов ключевую роль играют детальные спецификации, именуемые “Документацией по инструментам”. Данная документация содержит исчерпывающее описание функциональности каждого инструмента, включая допустимые входные параметры, ожидаемые выходные данные, а также возможные ошибки и способы их обработки. Формат документации стандартизирован для обеспечения однозначной интерпретации и использования данных о функциях инструментов в процессе обучения модели. Точность и полнота этих спецификаций напрямую влияют на способность модели правильно понимать и выполнять запросы, связанные с использованием инструментов.
Для создания многошаговых диалоговых примеров используется метод «Синтеза Траекторий», основанный на статическом графе зависимостей вызовов инструментов («Tool-Call Graph»). Этот граф определяет допустимые последовательности вызовов инструментов в процессе диалога. Синтез траекторий позволяет генерировать разнообразные диалоговые сценарии, в которых последовательность вызовов инструментов соответствует структуре, определенной в графе зависимостей. Это обеспечивает создание обучающих данных, отражающих корректное и логичное использование инструментов в многошаговом взаимодействии, и позволяет избежать генерации невозможных или некорректных последовательностей вызовов.
Предварительная подготовка модели посредством контролируемого обучения (SFT) и синтеза траекторий создает надежную основу для последующего обучения с подкреплением. Этот этап позволяет модели усвоить базовые навыки использования инструментов и понимать зависимости между вызовами, что значительно упрощает и ускоряет процесс обучения с подкреплением. Использование SFT и синтезированных данных обеспечивает более эффективное исследование пространства действий и достижение лучших результатов в задачах, требующих последовательного взаимодействия с инструментами. Без предварительной настройки, обучение с подкреплением потребовало бы значительно больше данных и времени для достижения сопоставимой производительности.
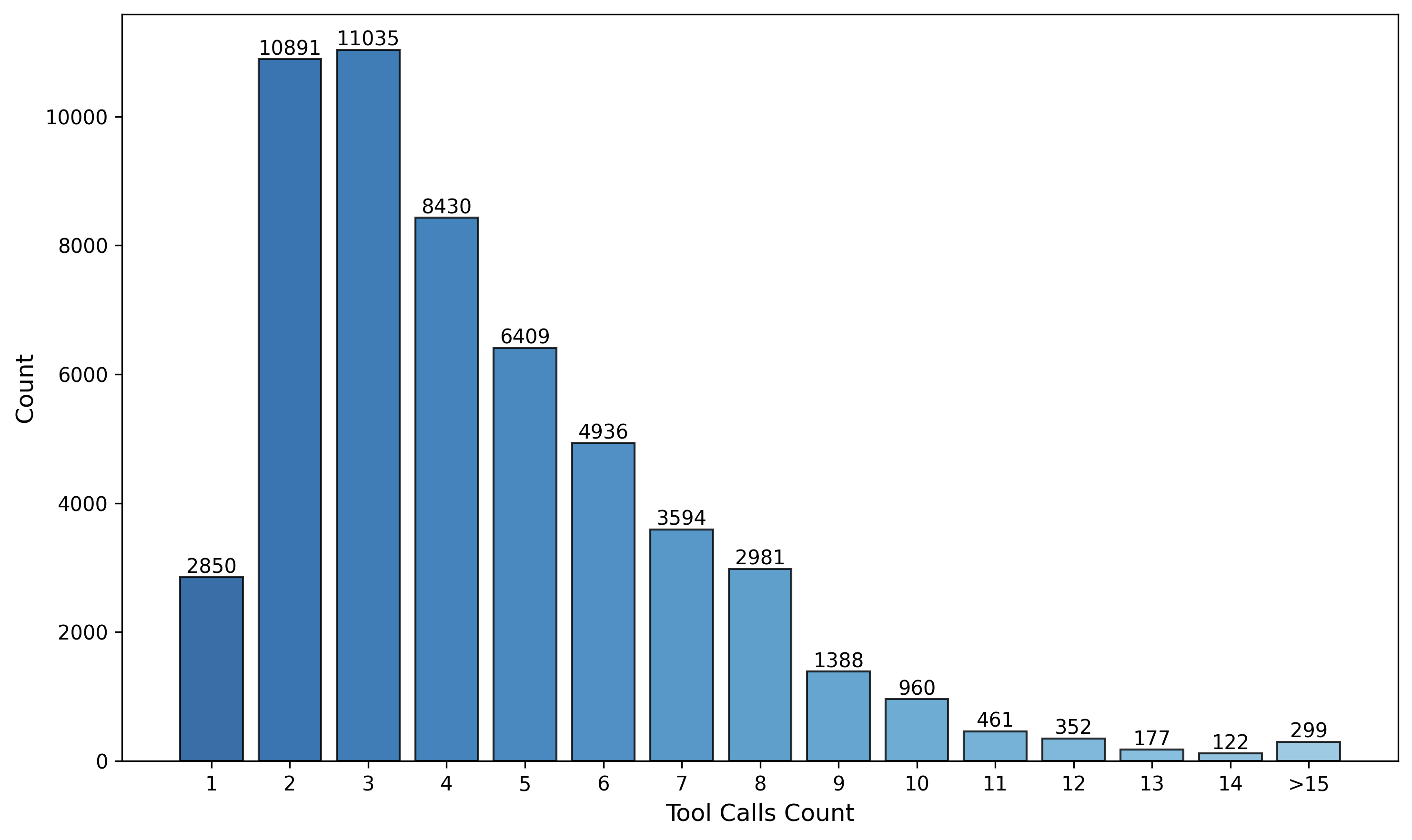
Онлайн Обучение с Подкреплением для Надежного Использования Инструментов
Для улучшения стратегии агента в процессе использования инструментов мы применяем обучение с подкреплением (Reinforcement Learning, RL). В рамках этого подхода, агент взаимодействует с синтезированной средой, получая обратную связь в виде вознаграждения или штрафа за каждое действие. Этот процесс позволяет агенту корректировать свою политику (стратегию выбора действий) с целью максимизации суммарного вознаграждения, полученного в ходе выполнения задачи. Обучение происходит итеративно: агент выполняет действия, получает обратную связь и обновляет свою политику на основе полученного опыта. Используемый алгоритм RL позволяет агенту адаптироваться к сложным условиям и оптимизировать процесс использования инструментов.
Оптимизация поведения агента осуществляется посредством функции потерь GRPO (Generalized Reward-based Policy Optimization), направленной на максимизацию суммарного вознаграждения, полученного в ходе многошаговых диалогов. GRPO вычисляет ожидаемое суммарное вознаграждение, учитывая вероятности действий агента и динамику среды, и использует этот расчет для обновления политики агента. В отличие от стандартных методов обучения с подкреплением, GRPO эффективно обрабатывает сложные последовательности действий, характерные для задач использования инструментов, и способствует стабильному обучению за счет учета долгосрочных последствий каждого действия. Целью является не просто успешное выполнение задачи, но и оптимизация всей траектории взаимодействия для достижения максимальной эффективности.
Функция вознаграждения, разработанная по принципу ‘F1-стиля’, объединяет оптимизацию успешного завершения задачи и эффективности взаимодействия. Данная функция оценивает как корректное выполнение поставленной цели, так и минимальное количество шагов или запросов, необходимых для достижения результата. Это достигается путем комбинирования метрик, отражающих успешность выполнения задачи (например, бинарный флаг успешного завершения) с метриками, оценивающими количество использованных действий или токенов. Такой подход стимулирует агента к поиску оптимальных стратегий, которые обеспечивают не только правильное решение, но и экономичное использование ресурсов в процессе взаимодействия с пользователем. R = \alpha <i> TaskCompletion + \beta </i> InteractionEfficiency, где α и β — весовые коэффициенты, определяющие вклад каждой метрики в общую функцию вознаграждения.
Для повышения обобщающей способности модели в процессе обучения с подкреплением (RL) используется метод “смешивания нерелевантных инструментов”. В ходе обучения агент взаимодействует с синтезированной средой, в которой наряду с полезными инструментами, необходимыми для выполнения задачи, присутствуют и нерелевантные. Это вынуждает агента активно оценивать каждый инструмент и выбирать только те, которые действительно способствуют достижению поставленной цели, что способствует развитию способности к дискриминации и повышает устойчивость к незнакомым ситуациям. Данный подход позволяет модели лучше адаптироваться к различным контекстам и избегать использования бесполезных или вредных инструментов при решении новых задач.
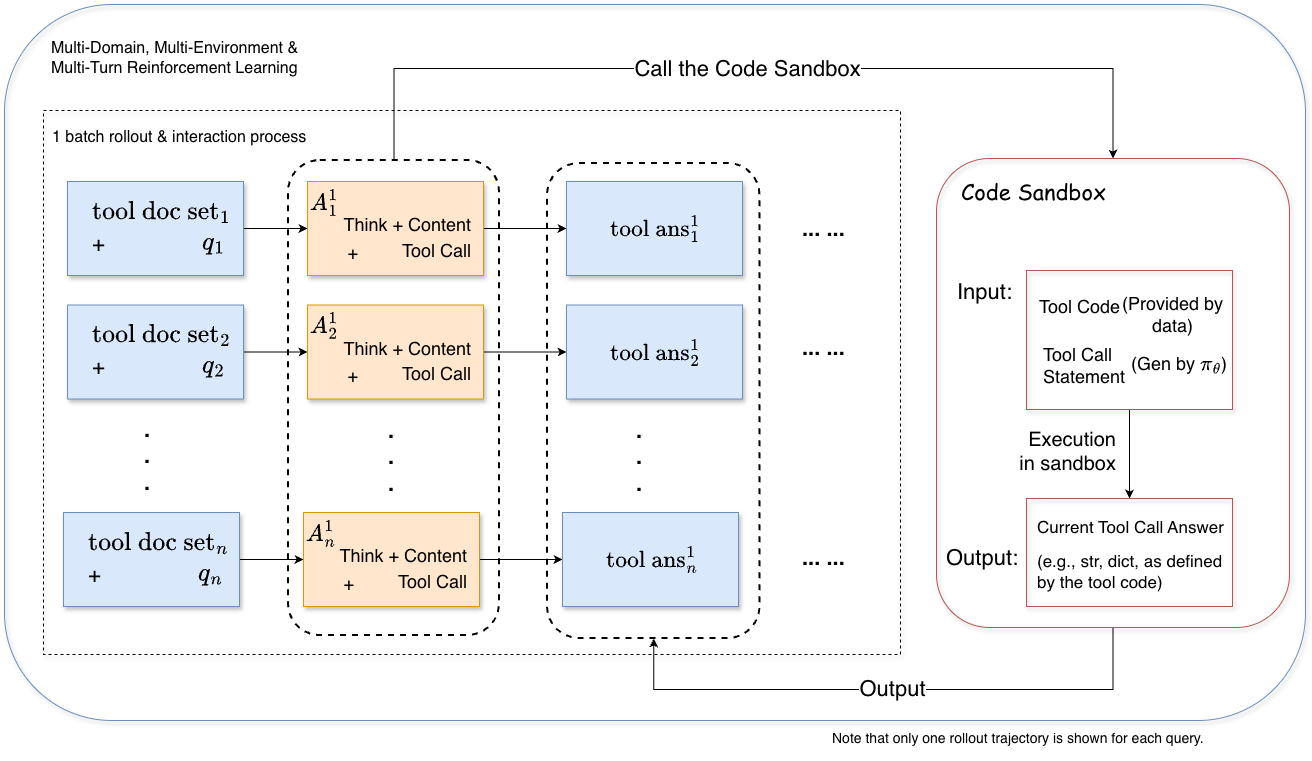
Масштабируемый Синтез Данных и Онлайн Обучение
Для поддержания эффективности обучения используется метод “Адаптивного заполнения пакета” (Adaptive Batch Filling). Суть его заключается в динамической корректировке состава обучающего пакета, чтобы обеспечить максимальную полезность каждого образца данных. Вместо использования случайной выборки, система оценивает качество и релевантность каждого потенциального элемента, добавляя в пакет те, которые наиболее способствуют улучшению модели. Такой подход позволяет избежать ситуаций, когда пакет заполнен неинформативными или избыточными данными, что значительно ускоряет процесс обучения и повышает его результативность. Реализация данного метода особенно важна при работе с большими объемами данных и сложными задачами, где эффективное использование каждого обучающего примера критически важно для достижения высоких показателей.
Разработанная автоматизированная система, получившая название ‘ASTRA’, объединяет в себе масштабируемый синтез данных и обучение с подкреплением в режиме реального времени с возможностью верификации. Этот подход позволяет системе непрерывно совершенствоваться, используя сгенерированные данные для адаптации к новым задачам и условиям. Результаты показывают, что ‘ASTRA’ достигает передовых результатов в ряде эталонных тестов, связанных с использованием инструментов агентами, демонстрируя способность к сложному рассуждению и эффективному решению задач в динамической среде. Система успешно справляется с задачами, требующими планирования, логического вывода и взаимодействия с различными инструментами, приближаясь по эффективности к закрытым системам и устанавливая новый стандарт в области обучения агентов.
Для создания обогащенной обучающей среды используется метод «Декомпозиции пар вопросов и ответов». Суть подхода заключается в разделении исходных запросов пользователя на более простые, взаимосвязанные вопросы и соответствующие им ответы. Такой подход позволяет модели не просто отвечать на конечный запрос, а последовательно осваивать логику решения, выстраивая цепочку рассуждений. Вместо обработки единого сложного вопроса, система учится на множестве небольших задач, что значительно упрощает процесс обучения и повышает эффективность освоения сложных навыков, особенно в контексте работы с инструментами и решения задач, требующих многоступенчатого анализа.
Разработанная система ASTRA демонстрирует впечатляющие результаты, приближаясь по производительности к закрытым коммерческим решениям в таких сложных бенчмарках, как BFCL-MT, τ2-Bench и ACEBench. Это достижение свидетельствует о значительном прогрессе в области обучения с подкреплением и способности системы к решению задач, требующих сложного рассуждения. В частности, ASTRA превосходит существующие открытые системы в задачах, требующих последовательного применения логики и анализа, что подтверждает её эффективность в моделировании и решении проблем, близких к тем, с которыми сталкиваются люди в реальных условиях. Данные результаты подчеркивают потенциал автоматизированных систем для достижения экспертного уровня в широком спектре когнитивных задач.
Представленная работа демонстрирует, что масштабируемость в обучении агентов определяется не вычислительными мощностями, а ясностью и элегантностью архитектуры системы. Как отмечал Г.Х. Харди: «Математика — это не только язык, но и наука, требующая точности и простоты». В данном исследовании, ASTRA, благодаря синтезу данных и верифицируемой среде обучения с подкреплением, позволяет создавать эффективные и масштабируемые системы, где каждая часть взаимодействует как единый организм. Подход, предложенный авторами, подчеркивает важность целостного взгляда на систему, что перекликается с принципом, согласно которому нельзя улучшить одну часть, не понимая влияния на остальные компоненты.
Куда же дальше?
Представленная работа, несомненно, демонстрирует элегантность подхода к синтезу данных и обучению агентов. Однако, за кажущейся простотой скрывается сложный вопрос: что именно мы оптимизируем? Достижение высоких результатов на существующих бенчмарках — это лишь первый шаг. Более глубокий анализ должен быть направлен на понимание, действительно ли созданные траектории и арены отражают подлинную сложность взаимодействия, или же это лишь искусственно сконструированная иллюзия компетентности. Важно помнить, что хорошая система — это живой организм, и её эффективность определяется не только отдельными компонентами, но и их взаимодействием в целом.
Очевидным направлением для дальнейших исследований является расширение масштаба синтезируемых данных и аренд. Но простое увеличение объёма не решит проблему. Необходимо разработать более тонкие метрики оценки, позволяющие отличать действительно сложные и разнообразные сценарии от тривиальных вариаций. Следует также учитывать, что структура определяет поведение. Необходимо тщательно исследовать, как архитектура синтезируемых данных влияет на возможности и ограничения обученных агентов.
В конечном итоге, задача состоит не в создании все более мощных агентов, а в понимании принципов, лежащих в основе разумного поведения. Истинная простота заключается не в минимализме, а в чётком различении необходимого и случайного. Поиск этой простоты — вот что должно определять будущее исследований в данной области.
Оригинал статьи: https://arxiv.org/pdf/2601.21558.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-31 10:47