Автор: Денис Аветисян
Новая работа предлагает эффективный метод обнаружения и смягчения дискриминации в алгоритмах, учитывающий сложные взаимосвязи между различными группами пользователей.
В статье представлен фреймворк на основе целочисленного программирования для обеспечения справедливого машинного обучения с сохранением точности и интерпретируемости.
В современных системах машинного обучения, несмотря на растущую потребность в справедливости, существующие подходы часто упускают из виду сложные пересечения защищаемых групп. В работе ‘Intersectional Fairness via Mixed-Integer Optimization’ предложен унифицированный фреймворк, использующий методы целочисленного линейного программирования для обучения классификаторов, обеспечивающих справедливость на пересечениях признаков и одновременно сохраняющих интерпретируемость. Показано, что предложенный подход позволяет эффективно находить наиболее несправедливые подгруппы и ограничивать предвзятость ниже заданного порога, обеспечивая соответствие нормативным требованиям. Сможет ли данный подход стать основой для создания действительно беспристрастных и прозрачных систем искусственного интеллекта в критически важных областях?
Алгоритмическая предвзятость: Раскрытие скрытых предубеждений
В современном мире, где системы искусственного интеллекта (ИИ) все глубже проникают во все сферы жизни — от кредитных рейтингов и найма на работу до правосудия и здравоохранения — возрастает риск возникновения алгоритмической предвзятости. Эта предвзятость, проявляющаяся в систематических ошибках и неравномерных результатах, может приводить к несправедливым решениям, ущемляющим права определенных групп населения. Поскольку ИИ-системы обучаются на исторических данных, отражающих существующие социальные неравенства, они способны невольно воспроизводить и даже усугублять эти предубеждения. Таким образом, широкое распространение ИИ требует пристального внимания к вопросам справедливости и равенства, поскольку неконтролируемая алгоритмическая предвзятость представляет серьезную угрозу для построения справедливого и равноправного общества.
Предвзятость алгоритмов — это не просто техническая погрешность, а следствие систематических ошибок, заложенных в данные и структуру моделей машинного обучения. Эти ошибки могут возникать на различных этапах — от сбора и разметки данных, отражающих существующие социальные неравенства, до выбора признаков и архитектуры самой модели. В результате, алгоритмы могут воспроизводить и даже усиливать дискриминационные практики, приводя к неравномерному распределению возможностей и ресурсов для различных групп населения. Например, системы распознавания лиц могут показывать худшую точность при определении лиц людей с темным цветом кожи, или алгоритмы, используемые при приеме на работу, могут неосознанно отдавать предпочтение определенным гендерным или этническим группам, что приводит к несправедливым результатам и усугубляет существующие социальные проблемы.
Противодействие алгоритмическим предубеждениям требует не просто исправления технических ошибок, а комплексных, упреждающих мер. Традиционные представления о справедливости, основанные на статистическом равенстве или равных возможностях, зачастую оказываются недостаточными для выявления и смягчения сложных социальных последствий. Алгоритмы, обученные на исторических данных, могут увековечивать и усиливать существующее неравенство, даже если формально соблюдаются принципы равного обращения. Поэтому, для обеспечения действительно справедливых результатов необходимо учитывать контекст, культурные особенности и потенциальные долгосрочные эффекты, а также привлекать к оценке алгоритмов специалистов из разных областей, включая социологов, этиков и представителей заинтересованных сообществ. Решение этой проблемы требует выхода за рамки технических показателей и принятия более широкого, междисциплинарного подхода.
За пределами простого равенства: Анализ пересечений
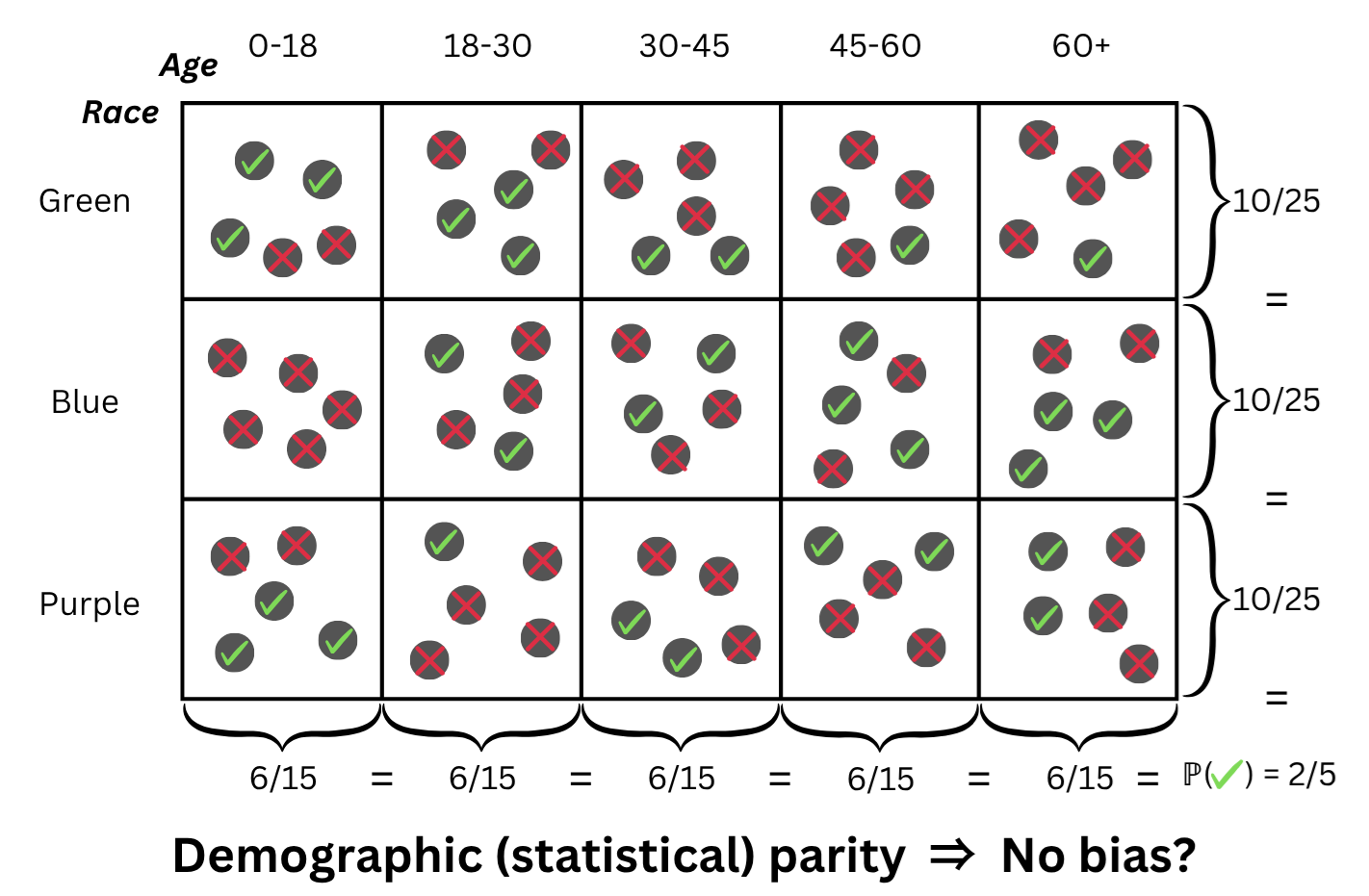
Принцип справедливости с учетом пересечений (Intersectional Fairness) расширяет традиционные критерии справедливости, такие как статистическое равенство (Statistical Parity) и равные возможности (Equal Opportunity), учитывая одновременное влияние нескольких защищаемых признаков. Традиционные метрики оценивают справедливость по каждому признаку отдельно, что может скрывать дискриминацию, возникающую при их комбинации. Например, анализ может выявить, что определенная группа, определенная пересечением признаков пола и расы, систематически сталкивается с неблагоприятными результатами, несмотря на то, что общая статистика по полу или расе может не указывать на проблему. Этот подход позволяет более точно оценить и смягчить предвзятость в алгоритмических системах, обеспечивая более справедливые результаты для всех групп населения.
Анализ справедливости, выходящий за рамки рассмотрения отдельных признаков, предполагает оценку результатов алгоритмов внутри специфических подгрупп, определяемых пересечением защищенных характеристик. Например, вместо оценки справедливости по признаку “пол” или “раса” по отдельности, проводится анализ для подгруппы “афроамериканки” или “белые мужчины”. Такой подход позволяет выявить дискриминацию, которая может быть скрыта при анализе отдельных признаков, поскольку неравномерное влияние может проявляться только в конкретных комбинациях характеристик. Выделение и оценка производительности алгоритма для каждой такой подгруппы является ключевым элементом обеспечения более точной и всесторонней справедливости.
Анализ подгрупп, формируемых пересечением защищаемых признаков (например, комбинация пола и расы), является ключевым для выявления и смягчения дискриминационного воздействия (disparate impact). Традиционные метрики справедливости часто не учитывают, что негативное влияние может проявляться непропорционально в определенных комбинациях признаков. Идентификация этих подгрупп позволяет оценить, действительно ли алгоритм оказывает равное воздействие на все демографические группы, а не просто усредненно по каждому признаку в отдельности. Выявление таких комбинаций, называемых conjunction subgroups, позволяет более точно определить случаи дискриминации и разработать целенаправленные стратегии для устранения предвзятости.

Количественная оценка справедливости: Методы выявления расхождений
Для оценки справедливости в пересекающихся группах (intersectional settings) применяются различные методы, в частности, меры на основе соотношений (Ratio-based Fairness Measures) и меры на основе расстояний (Distance-based Fairness Measures). Меры на основе соотношений, такие как демографическое равенство (demographic parity) и равенство возможностей (equal opportunity), сравнивают пропорции положительных исходов между группами. Меры на основе расстояний, включая расстояние Кульбака-Лейблера (Kullback-Leibler divergence) и расстояние Хеллингера (Hellinger distance), количественно оценивают разницу в распределении исходов между группами. Выбор конкретного метода зависит от контекста задачи и определяемого типа несправедливости; оба подхода позволяют численно оценить степень расхождений в результатах для разных подгрупп населения.
Метрики оценки справедливости позволяют количественно определить разницу между распределениями результатов для различных подгрупп, предоставляя объективные доказательства наличия дисбаланса. Для этого используются различные подходы, такие как расчет разницы в средних значениях, дисперсии или других статистических показателей между группами. Например, можно рассчитать D = |μ_1 - μ_2|, где μ_1 и μ_2 — средние значения результатов для двух подгрупп. Большое значение D указывает на значительную разницу в результатах и, следовательно, на потенциальную несправедливость. Эти количественные оценки необходимы для выявления и устранения систематических ошибок и обеспечения равных возможностей для всех.
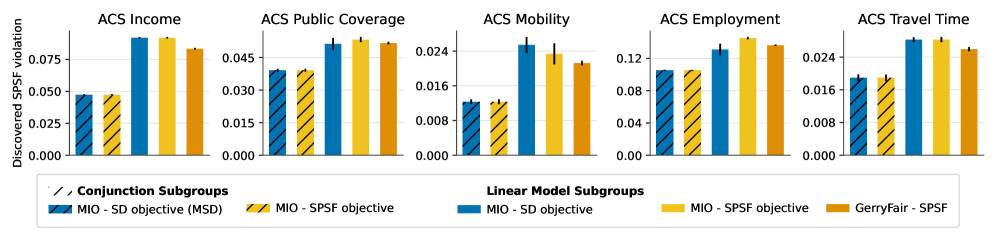
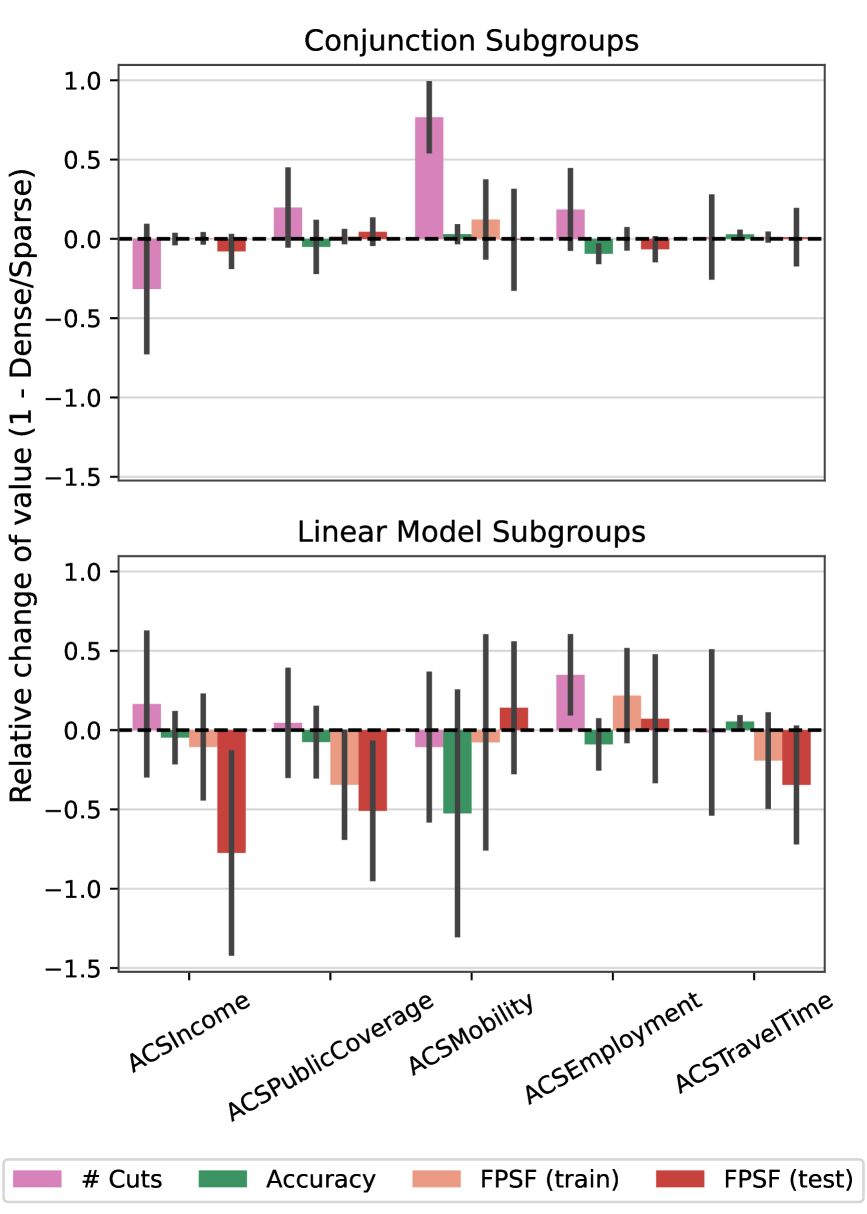
Предложенная структура демонстрирует значительное улучшение в отношении нарушения справедливости (FPSF), достигая значения менее 1.5-кратного от установленного порога, что превосходит показатели базовых моделей. Анализ характеристик подгрупп, в частности, линейных подгрупп, позволяет выявлять факторы, приводящие к дисбалансу в результатах. Это понимание критически важно для разработки целенаправленных стратегий смягчения последствий и обеспечения более справедливых и равноправных результатов для всех категорий пользователей. Идентификация ключевых характеристик подгрупп позволяет адаптировать алгоритмы и процессы принятия решений, минимизируя потенциальные предубеждения и улучшая общую справедливость системы.
Смягчение предвзятости: Рамки для справедливого будущего
Разработка рамок смягчения предвзятости является ключевым шагом в воплощении принципов справедливости в конкретные руководства и нормативные акты. Эти рамки предоставляют структурированный подход к выявлению, оценке и устранению алгоритмической предвзятости на протяжении всего жизненного цикла искусственного интеллекта. Они позволяют перейти от абстрактных представлений о справедливости к практическим инструментам, которые можно использовать для создания более надежных и беспристрастных систем. Без таких рамок, принципы справедливости остаются лишь декларативными, а риск увековечивания и усиления существующих социальных неравенств в алгоритмах сохраняется. Таким образом, эффективные рамки смягчения предвзятости не просто желательны, а необходимы для обеспечения того, чтобы развитие искусственного интеллекта приносило пользу всему обществу.
Разработанные структуры обеспечивают систематический подход к выявлению, оценке и смягчению алгоритмической предвзятости на протяжении всего жизненного цикла искусственного интеллекта. Этот процесс начинается с тщательного анализа данных, используемых для обучения моделей, с целью обнаружения и устранения потенциальных источников дискриминации. Далее, на этапе разработки, внедряются методы, позволяющие оценить справедливость алгоритмов и внести коррективы для обеспечения равного отношения к различным группам населения. Наконец, в процессе развертывания и мониторинга, непрерывно отслеживается работа системы, чтобы своевременно выявлять и устранять любые проявления предвзятости, гарантируя, что решения, принимаемые искусственным интеллектом, являются объективными и справедливыми для всех.
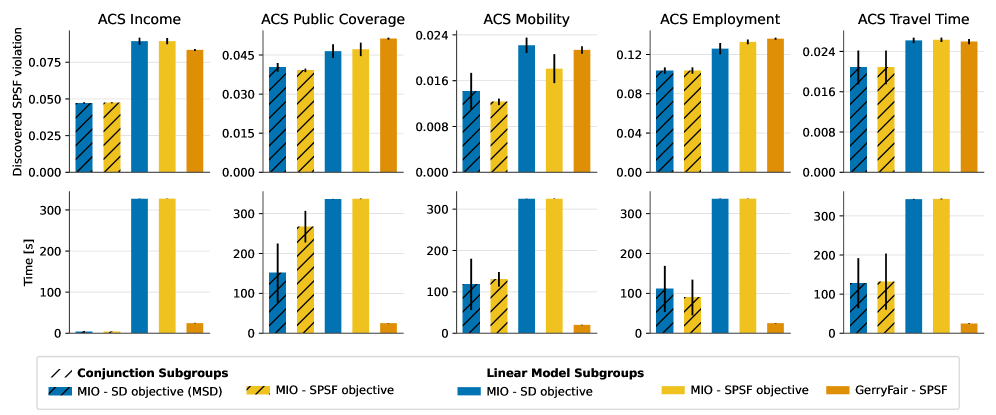
Предложенная структура использует метод целочисленного линейного программирования, позволяя применять в среднем 47 ограничений, направленных на обеспечение справедливости, при этом сохраняя сопоставимую точность с базовыми моделями. Обнаружение предвзятости осуществляется за 5-10 минут, что демонстрирует превосходство над системой GerryFair. Эти результаты подчеркивают важность проактивного внедрения подобных структур, гарантируя, что системы искусственного интеллекта приносят пользу всем слоям общества равноправно и не увековечивают существующие неравенства. Такой подход позволяет не только выявлять, но и эффективно устранять предвзятость на различных этапах жизненного цикла ИИ, способствуя созданию более справедливых и инклюзивных технологий.
Исследование демонстрирует, что обнаружение и смягчение пересекающихся предубеждений в моделях машинного обучения требует не просто статистического анализа, но и глубокого понимания внутренней структуры этих моделей. Авторы предлагают использовать методы оптимизации для достижения справедливости, не жертвуя при этом производительностью. Это напоминает слова Анри Пуанкаре: «Наука не состоит из ряда истин, а из ряда более или менее вероятных мнений». Подобно тому, как Пуанкаре подчеркивал относительность научного знания, данная работа показывает, что и справедливость в алгоритмах — это не абсолютная категория, а результат оптимизации определенных параметров и компромиссов. Поиск баланса между точностью и справедливостью требует критического взгляда на систему и ее ограничения, подобно реверс-инжинирингу реальности, чтобы понять, как она работает и как ее можно улучшить.
Куда двигаться дальше?
Представленная работа, как и любой инструмент, выявляет границы своей применимости. Формулировка справедливости через смешанное целочисленное программирование — элегантное решение, но оно предполагает, что сама концепция «справедливости» может быть формализована. А что, если «справедливость» — это не статичная метрика, а динамичная, контекстуально-зависимая величина? Настоящий вызов заключается не в оптимизации существующих определений, а в создании моделей, способных адаптироваться к меняющимся представлениям о равенстве.
Обнаружение и смягчение пересекающихся предвзятостей — это лишь первый шаг. Более глубокий вопрос — в самой природе алгоритмических систем. Если алгоритм — это отражение данных, а данные — отражение мира, то исправление предвзятости в алгоритме — это, по сути, попытка исправить предвзятость в реальности. Не стоит ли вместо этого сосредоточиться на создании систем, которые не стремятся к абсолютной точности, а признают и учитывают присущую миру неопределенность и неоднозначность?
Предложенный подход демонстрирует улучшение интерпретируемости, однако, интерпретируемость — это иллюзия контроля. Знание причинно-следственных связей не гарантирует возможности их изменения. В конечном итоге, задача заключается не в том, чтобы «взломать» систему, а в том, чтобы понять её фундаментальные ограничения и научиться жить с ними. Ведь, как известно, баг — это признание системы в собственных грехах, а не её смертный приговор.
Оригинал статьи: https://arxiv.org/pdf/2601.19595.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-29 06:51