Автор: Денис Аветисян
Исследователи предлагают алгоритм, позволяющий значительно улучшить процесс обучения агентов, принимающих решения в динамичной среде.
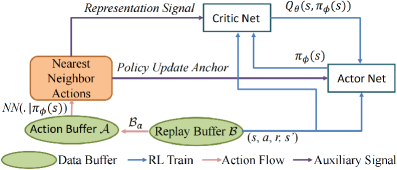
Представлен алгоритм Instant Retrospect Action (IRA), сочетающий в себе обучение с ограничениями, направленное представление опыта и мгновенное обновление стратегии для повышения эффективности обучения с подкреплением.
Несмотря на значительные успехи в обучении с подкреплением, алгоритмы, основанные на оценке ценности, часто сталкиваются с проблемами медленной эксплуатации политики из-за неэффективного исследования и задержки обновлений. В данной работе, посвященной ‘Improving Policy Exploitation in Online Reinforcement Learning with Instant Retrospect Action’, предложен алгоритм Instant Retrospect Action (IRA), использующий эволюцию расхождений в представлении Q-сети (RDE) и механизм мгновенного обновления политики (IPU) для повышения эффективности эксплуатации. IRA, за счет использования исторических действий для наведения оптимальной политики (Greedy Action Guidance), позволяет создавать более адаптивные и эффективные стратегии обучения. Способствует ли предложенный подход снижению смещения переоценки, характерного для алгоритмов обучения с подкреплением, и какие перспективы открывает мгновенная обратная связь для разработки интеллектуальных систем управления?
Сложность Эффективного Исследования
Агенты обучения с подкреплением (RL) зачастую сталкиваются с трудностями при эффективном исследовании среды, особенно в задачах непрерывного управления, характеризующихся высокой сложностью. В отличие от дискретных пространств действий, где можно перебрать все варианты, в непрерывных задачах необходимо самостоятельно находить оптимальные стратегии поиска, что требует значительных вычислительных ресурсов и времени. Неспособность агента эффективно исследовать пространство состояний приводит к застреванию в локальных оптимумах и препятствует достижению глобально оптимального решения. Проблема усугубляется необходимостью баланса между исследованием новых стратегий и использованием уже известных, что требует разработки продвинутых алгоритмов, способных эффективно управлять этим компромиссом и обеспечивать устойчивое обучение в сложных условиях.
Методы обучения с подкреплением, основанные на оценке ценности действий Q (value-based RL), несмотря на свою эффективность в решении сложных задач, подвержены систематической переоценке ценности, что негативно влияет на процесс улучшения политики управления. Данное явление возникает из-за того, что оценка Q-функции часто строится на основе максимальных значений, что приводит к завышению ожидаемой награды. Эта переоценка, накапливаясь в процессе обучения, может привести к выбору неоптимальных действий и замедлить сходимость алгоритма. В результате, агент может застрять в субоптимальной стратегии, неспособный достичь наилучшей возможной производительности, даже при достаточном количестве обучающих данных и времени.
Проблема переоценки в алгоритмах обучения с подкреплением, основанных на оценке ценности, в сочетании с медленной эксплуатацией найденных решений, создает существенное препятствие для формирования надежных стратегий управления. Данное сочетание факторов приводит к тому, что агент часто выбирает субоптимальные действия, основываясь на завышенных оценках их потенциальной выгоды, и медленно адаптируется к более эффективным подходам. В результате, обучение становится замедленным и неэффективным, особенно в сложных задачах непрерывного управления, где требуется точная и быстрая адаптация к изменяющимся условиям. Преодоление этого «узкого места» является ключевой задачей для разработки более совершенных и надежных систем искусственного интеллекта, способных решать сложные задачи управления в реальном времени.
Ускорение Обучения Политики с Мгновенными Обновлениями
Увеличение частоты обновления сети актора, известное как Instant Policy Update, является прямым методом снижения задержки в освоении оптимальной стратегии. Традиционные подходы к обучению с подкреплением часто обновляют политику лишь периодически, что замедляет адаптацию к новым данным и может приводить к субоптимальному поведению. Instant Policy Update позволяет сети актора немедленно реагировать на каждый новый опыт, минимизируя интервал между получением данных и корректировкой стратегии. Это особенно полезно в сложных средах, где быстро меняющиеся условия требуют оперативной адаптации политики для поддержания высокой производительности и эффективного исследования пространства состояний.
Увеличение частоты обновления нейронной сети актора позволяет агенту быстрее адаптироваться к новым данным и, следовательно, более эффективно корректировать свою стратегию управления. Более частые обновления снижают задержку между получением опыта и внесением изменений в политику, что приводит к более оперативной оптимизации действий агента в изменяющейся среде. Это особенно важно в сложных задачах, где быстрое реагирование на новые ситуации критически важно для достижения оптимальной производительности и максимизации вознаграждения.
Использование алгоритмов ограничения политики (Policy Constraint Algorithms) позволяет направлять процесс исследования пространства действий, предотвращая выбор неэффективных действий и, как следствие, ускоряя обучение агента. Эти алгоритмы работают путем введения ограничений на изменения политики, гарантируя, что обновления будут происходить в пределах допустимых и перспективных стратегий. Это особенно полезно в сложных средах, где случайное исследование может быть неэффективным или даже контрпродуктивным, поскольку агент сосредоточивается на изучении только тех действий, которые, вероятно, приведут к положительным результатам. В результате, алгоритмы ограничения политики повышают эффективность исследования и улучшают скорость сходимости обучения.
Подтверждение Эффективности на Разнообразных Средах Непрерывного Управления
Алгоритм Twin Delayed Deep Deterministic Policy Gradient (TD3) успешно применяется в ряде сред непрерывного управления MuJoCo. Это включает в себя сложные задачи, такие как HalfCheetah, Hopper, Walker2d, Ant, Humanoid и Reacher, демонстрируя его способность решать задачи с высокой степенью сложности и различными кинематическими структурами. Успешное применение TD3 подтверждается стабильной и эффективной работой в этих средах, что делает его ценным инструментом для разработки и тестирования алгоритмов обучения с подкреплением в области робототехники и управления.
Алгоритм TD3 был успешно протестирован на сложных задачах управления непрерывными процессами в среде MuJoCo, включая симуляции HalfCheetah, Hopper, Walker2d, Ant, Humanoid и Reacher. Эти среды характеризуются различной сложностью динамики и количеством степеней свободы, представляя собой значительный вызов для алгоритмов обучения с подкреплением. Успешное применение TD3 в этих задачах демонстрирует его способность эффективно обучаться и адаптироваться к сложным условиям, требующим точного управления и координации движений.
Алгоритм TD3 демонстрирует стабильную работу и на задачах с упрощенной динамикой, таких как InvertedPendulum и InvertedDoublePendulum. Это подтверждает его универсальность и способность эффективно обучаться как в сложных, так и в более простых средах управления. Успешное применение TD3 к этим задачам указывает на надежность алгоритма и его пригодность для широкого спектра приложений в области непрерывного управления.
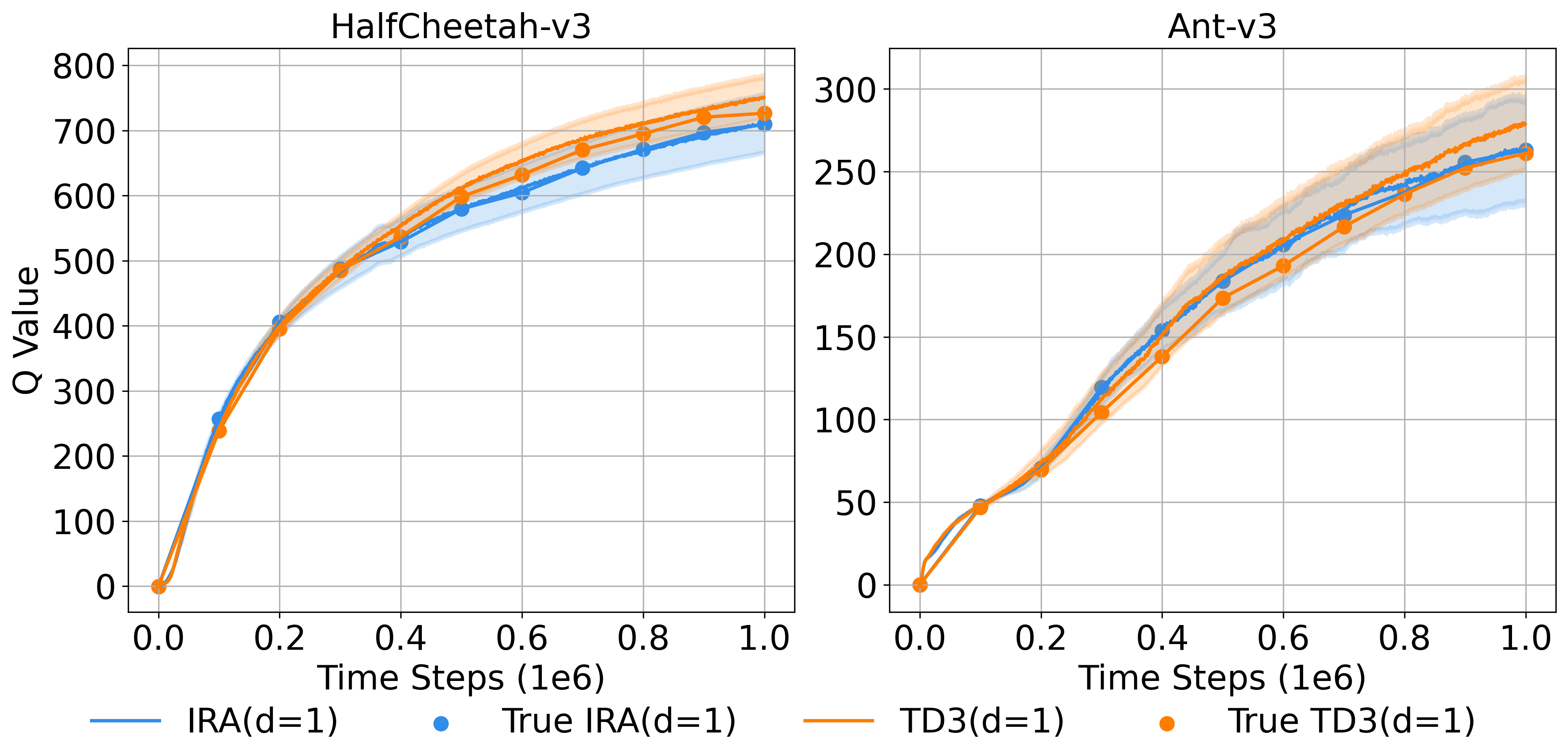
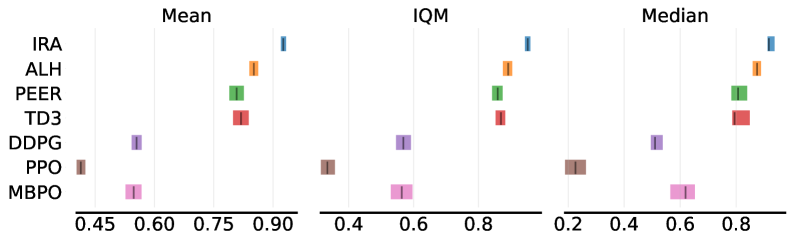
Предложенный алгоритм Instant Retrospect Action (IRA) демонстрирует среднее увеличение производительности на 36.9% при применении к набору задач управления в среде MuJoCo по сравнению с базовым алгоритмом Twin Delayed Deep Deterministic Policy Gradient (TD3). Данный прирост производительности был зафиксирован при тестировании на задачах, включающих HalfCheetah, Hopper, Walker2d, Ant, Humanoid и Reacher, что подтверждает эффективность IRA в сложных сценариях непрерывного управления.
Алгоритм Instant Retrospect Action (IRA) демонстрирует значительное превосходство по сравнению с существующими методами обучения с подкреплением на наборе задач MuJoCo. В частности, IRA обеспечивает относительное улучшение производительности на 21.4% по сравнению с алгоритмом ALH, 35.6% по сравнению с PEER, 135.6% по сравнению с DDPG, 304.5% по сравнению с PPO и 194.6% по сравнению с MBPO. Эти данные свидетельствуют о существенном прогрессе в эффективности обучения и позволяют IRA достигать более высоких результатов в задачах непрерывного управления.

Влияние на Развитие Надежных и Обобщающих Систем Обучения с Подкреплением
Успех алгоритма TD3 и схожих подходов ярко демонстрирует ключевую роль эффективного исследования среды в обучении с подкреплением. В то время как многие алгоритмы сосредотачиваются на эксплуатации уже известных стратегий, TD3 подчеркивает необходимость постоянного и продуманного исследования, позволяющего агенту обнаруживать новые, потенциально более выгодные решения. Этот подход, основанный на сглаживании целевых политик и добавлении шума к действиям, позволяет агенту избегать застревания в локальных оптимумах и более эффективно осваивать сложные пространства состояний. В результате, алгоритмы, делающие акцент на исследовании, демонстрируют повышенную стабильность обучения и лучшую обобщающую способность, что критически важно для применения обучения с подкреплением в реальных задачах.
Современные методы обучения с подкреплением демонстрируют значительный прогресс в скорости и надёжности освоения сложных задач благодаря усовершенствованным техникам исследования среды. В частности, алгоритмы с мгновенным обновлением политики позволяют агенту оперативно адаптироваться к новым данным и избегать застревания в локальных оптимумах. Ограниченные алгоритмы, в свою очередь, способствуют более безопасному и предсказуемому исследованию, минимизируя риски получения нежелательных результатов и обеспечивая стабильность обучения. Эти инновации не только ускоряют процесс освоения, но и повышают устойчивость агентов к шумам и изменениям в окружающей среде, что критически важно для успешного применения в реальных условиях.
Достижения в области алгоритмов обучения с подкреплением, такие как TD3, открывают перспективные пути для создания более устойчивых и обобщающих агентов. Способность к эффективному освоению сложных задач, ранее недоступных для автоматизированных систем, становится реальностью благодаря улучшенным методам исследования и обучения. Это не просто увеличение скорости обучения, но и повышение надежности работы агентов в условиях неопределенности и изменчивости реального мира. В результате, ожидается широкое внедрение таких агентов в различные области — от робототехники и автономного транспорта до управления ресурсами и оптимизации сложных систем, что позволит решать задачи, требующие адаптивности, гибкости и способности к самообучению в динамически меняющейся среде.
Исследование, представленное в данной работе, демонстрирует стремление к оптимизации процессов обучения с подкреплением, акцентируя внимание на улучшении стратегий эксплуатации политики. Алгоритм IRA, предлагаемый авторами, направлен на более эффективное использование получаемой информации и адаптацию к изменяющимся условиям среды. В этом контексте, уместно вспомнить слова Андрея Николаевича Колмогорова: «Вероятность — это мера нашей уверенности в том, что событие произойдет». Подобно тому, как IRA стремится повысить уверенность в выборе оптимальных действий, математические инструменты, разработанные Колмогоровым, позволяют оценивать и прогнозировать вероятность различных исходов, что является ключевым для успешного обучения и принятия решений в сложных системах. Работа показывает, что задержка в применении исправлений, подобно инерции в любой системе, может стать существенным препятствием на пути к оптимальному решению.
Что впереди?
Представленный подход, стремящийся к более эффективной эксплуатации политики в обучении с подкреплением, лишь констатирует очевидное: любая система, даже самая изощренная, подвержена энтропии. Алгоритм Instant Retrospect Action (IRA) — это, скорее, попытка замедлить этот процесс, а не остановить его. Логирование действий, в данном контексте, — это не просто хроника жизни системы, а ее попытка осознать собственное старение, зафиксировать моменты оптимальности перед неминуемым угасанием. Вопрос в том, насколько долго эта «память» сможет компенсировать неизбежные ошибки, возникающие в динамичной среде.
Очевидным ограничением остается зависимость от качества представления. Как и любое зеркало, оно может искажать реальность, если не откалибровано должным образом. Развертывание политики — это мгновение на оси времени, но последствия этого мгновения растягиваются во времени, и ошибка в представлении может привести к каскаду неоптимальных действий. Будущие исследования должны сосредоточиться на создании более устойчивых к шуму и помехам представлений, а также на разработке механизмов самокоррекции, позволяющих системе учиться на собственных ошибках.
В конечном итоге, задача состоит не в создании идеальной политики, а в создании системы, способной адаптироваться к меняющимся условиям и извлекать уроки из своего опыта. Подобно любому живому организму, система должна уметь стареть достойно, сохраняя при этом способность к обучению и адаптации. Именно в этом направлении, вероятно, и лежит истинный путь развития обучения с подкреплением.
Оригинал статьи: https://arxiv.org/pdf/2601.19720.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-29 04:50