Автор: Денис Аветисян
Новый подход использует возможности больших языковых моделей для перевода экспертных знаний в понятные правила, позволяющие эффективно обнаруживать аномалии в данных цепочек поставок.
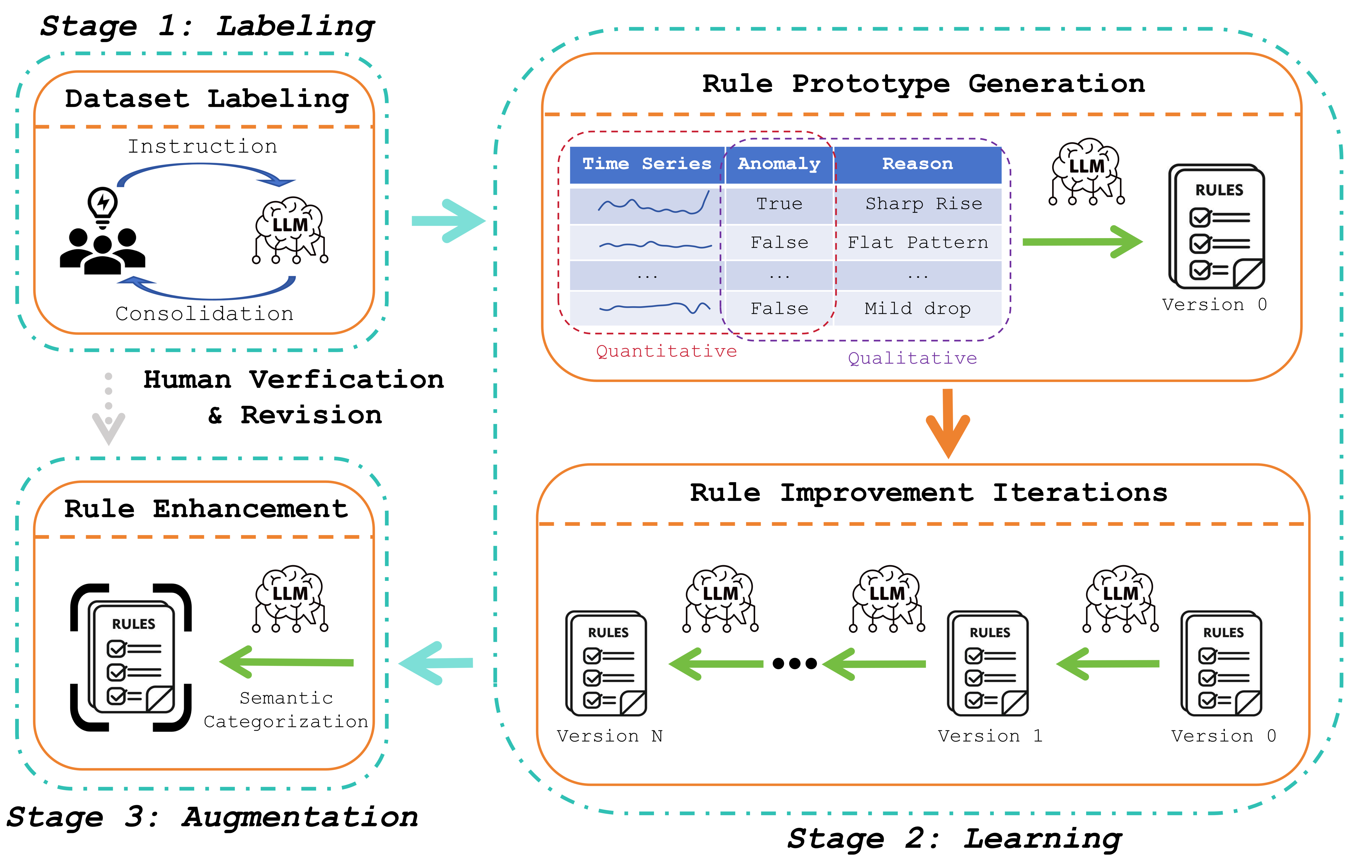
Предлагается фреймворк, использующий большие языковые модели для автоматического обучения логическим правилам, повышающим точность и надежность обнаружения аномалий во временных рядах.
Обнаружение аномалий во временных рядах критически важно для управления цепочками поставок, однако классические подходы, основанные на выявлении закономерностей в данных, часто не соответствуют бизнес-требованиям, а ручной анализ экспертов не масштабируется для миллионов продуктов. В данной работе, посвященной ‘LLM-Assisted Logic Rule Learning: Scaling Human Expertise for Time Series Anomaly Detection’, предлагается фреймворк, использующий большие языковые модели (LLM) для систематической кодификации экспертных знаний в интерпретируемые логические правила обнаружения аномалий. Предложенный подход превосходит традиционные методы машинного обучения как по точности, так и по интерпретируемости, обеспечивая стабильные и детерминированные результаты с низкой вычислительной стоимостью. Способны ли подобные системы стать основой для автоматизированной поддержки принятия решений в сложных операционных средах?
Преодолевая Масштаб: Вызовы Обнаружения Аномалий
Традиционные методы обнаружения аномалий во временных рядах, такие как статистические пороги и базовые алгоритмы машинного обучения, испытывают значительные трудности при работе с современными потоками данных. Объём и сложность этих потоков, характеризующиеся высокой скоростью поступления информации и большим количеством параметров, приводят к увеличению числа ложных срабатываний и снижению точности обнаружения реальных аномалий. Простые статистические модели зачастую не способны уловить тонкие изменения в данных, а базовые алгоритмы машинного обучения, несмотря на свою скорость, не обладают достаточной гибкостью для адаптации к динамически меняющимся характеристикам потока. В результате, системы, основанные на этих методах, оказываются перегружены информацией и не способны эффективно выявлять критически важные отклонения, что снижает их ценность для оперативного управления и принятия решений.
Несмотря на то, что алгоритмы, такие как Random Forest и XGBoost, демонстрируют улучшения в обнаружении аномалий, их применение в динамичных операционных средах ограничено из-за недостаточной интерпретируемости и способности к адаптации. Эти методы, хотя и способны выявлять отклонения от нормы, часто представляют собой «черные ящики», затрудняя понимание причин, лежащих в основе обнаруженной аномалии, и, следовательно, усложняя процесс принятия обоснованных решений. Отсутствие прозрачности также препятствует быстрой адаптации моделей к изменяющимся условиям и новым данным, что особенно критично в сложных системах, где оперативная корректировка стратегии обнаружения аномалий является ключевым фактором эффективности. В результате, несмотря на свою точность, данные алгоритмы могут оказаться недостаточно гибкими для решения задач в условиях постоянно меняющейся операционной среды.
Масштаб управления цепочками поставок Amazon предъявляет всё более высокие требования к системам обнаружения аномалий, и существующие методы оказываются неспособны справиться с возросшей сложностью. Обработка данных по более чем 10 тысячам уникальных товарных позиций (ASIN) требует не просто выявления отклонений, но и обеспечения прозрачности и объяснимости этих процессов. Традиционные алгоритмы, несмотря на свою эффективность в простых сценариях, зачастую не предоставляют достаточной информации для понимания причин возникновения аномалий, что затрудняет принятие обоснованных решений и оперативное реагирование на возникающие проблемы. В связи с этим, актуальной задачей является разработка и внедрение интеллектуальных систем, способных не только обнаруживать, но и интерпретировать аномалии в контексте сложной и динамичной среды управления цепочками поставок.
От Языка к Логике: Новый Подход
Предлагаемый подход, LLM-Assisted Logic-Based Rule Learning, представляет собой систему, преобразующую экспертные знания в интерпретируемые правила для обнаружения аномалий. В основе лежит использование больших языковых моделей (LLM) для автоматизированного извлечения логических правил из данных предметной области. Эти правила, в отличие от «черных ящиков» нейронных сетей, обеспечивают прозрачность и объяснимость процесса обнаружения аномалий, позволяя специалистам понимать, почему конкретное событие было классифицировано как аномальное. Система ориентирована на решение задач, где важно не только выявить аномалию, но и предоставить обоснование этого вывода, что критично для таких областей, как финансовый мониторинг, кибербезопасность и промышленный контроль качества.
Начальный этап процесса включает в себя стадию разметки, на которой используются мультимодальные языковые модели (LLM) для анализа данных временных рядов. Для повышения эффективности анализа и улучшения понимания закономерностей применяется визуальное представление временных рядов. LLM обрабатывают как числовые данные временных рядов, так и визуализацию, что позволяет им выявлять аномалии и особенности, которые могли бы быть упущены при анализе только числовых данных. Визуальное представление позволяет модели учитывать контекст и тренды, облегчая идентификацию значимых изменений в данных.
Ключевым элементом предложенного подхода является двухступенчатый механизм консенсуса, обеспечивающий надежность и согласованность меток, генерируемых большими языковыми моделями (LLM). На первом этапе несколько LLM независимо друг от друга анализируют данные временных рядов и присваивают метки аномалий. Затем, на втором этапе, специальный модуль консенсуса оценивает согласованность этих меток. Метки, по которым достигнуто высокое согласие между моделями, принимаются как окончательные. В случае расхождений, применяется процедура разрешения конфликтов, включающая пересмотр данных и повторный анализ, что гарантирует высокую точность и уменьшает вероятность ложноположительных или ложноотрицательных результатов.
Уточнение Правил с Учетом Доменной Экспертизы
Этап обучения использует итеративное улучшение правил, основанное на логических правилах, путем последовательной корректировки на основе оценки производительности и анализа поведения. Процесс включает в себя циклическое применение правил к данным, оценку результатов на предмет точности и полноты, а также внесение изменений в правила для оптимизации их эффективности. Анализ поведения позволяет выявлять закономерности в данных и адаптировать правила к конкретным сценариям, повышая их применимость и снижая количество ложных срабатываний. Итеративный характер процесса гарантирует, что правила постоянно совершенствуются по мере поступления новых данных и получения обратной связи.
Внедрение бизнес-контекста является ключевым аспектом данной системы, обеспечивая большие языковые модели (LLM) специализированными знаниями о предметной области и семантике данных. Это достигается путем предоставления LLM структурированной информации о бизнес-правилах, определениях ключевых показателей и специфических характеристиках данных, что позволяет им более точно интерпретировать входные данные и генерировать релевантные результаты. В отличие от моделей, работающих только с сырыми данными, интеграция бизнес-контекста позволяет LLM учитывать нюансы предметной области, повышая точность и надежность принимаемых решений и выявляемых аномалий.
В ходе сравнительного анализа производительности предложенный фреймворк продемонстрировал более высокую точность выявления аномалий по сравнению с рядом широко используемых базовых методов. В частности, точность превзошла показатели моделей VAE-LSTM, Anomaly Transformer, iForest, а также моделей, использующих большие языковые модели (LLM) напрямую, без применения разработанного механизма уточнения правил на основе экспертных знаний. Полученные результаты свидетельствуют о значимом улучшении качества обнаружения аномалий благодаря интеграции доменной экспертизы и итеративному совершенствованию логических правил.
За Пределы Обнаружения: К Проактивной Устойчивости Цепочек Поставок
Предложенная система представляет собой значительный шаг вперед в области обнаружения аномалий в цепочках поставок, объединяя возможности больших языковых моделей (LLM) и точность логических правил. В отличие от традиционных методов, полагающихся исключительно на статистический анализ или машинное обучение, данная разработка использует LLM для понимания контекста и выявления потенциальных проблем, а затем формулирует эти наблюдения в виде четких, логически обоснованных правил. Такой подход позволяет не просто фиксировать отклонения, но и объяснять причины их возникновения, что существенно облегчает процесс анализа и принятия решений. Сочетание гибкости LLM и детерминированности логических правил обеспечивает более надежное и интерпретируемое обнаружение аномалий, что особенно важно в динамичной среде современных цепочек поставок.
Особенностью разработанного подхода является возможность генерации понятных правил, что значительно упрощает и ускоряет анализ первопричин возникающих проблем в цепях поставок. Вместо простого обнаружения аномалий, система предоставляет четкое объяснение, почему возникла та или иная ситуация, позволяя оперативно выявлять узкие места и принимать эффективные корректирующие меры. Такая интерпретируемость не только снижает время реагирования на инциденты, но и способствует повышению общей операционной эффективности, поскольку позволяет целенаправленно улучшать процессы и предотвращать повторение проблем в будущем. В отличие от «черных ящиков» машинного обучения, где причины аномалий остаются скрытыми, предлагаемая система предоставляет прозрачную картину происходящего, что особенно важно для принятия обоснованных управленческих решений.
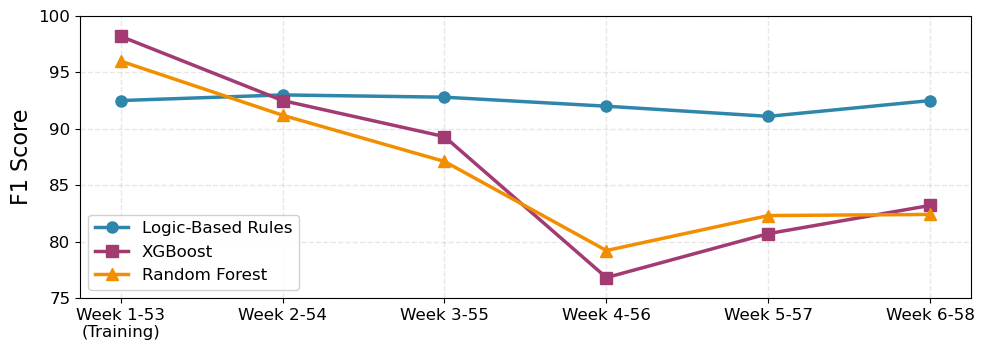
Исследования показали, что разработанная система демонстрирует повышенную устойчивость к колебаниям спроса, в частности, в периоды праздничных пиков. В течение недели, характеризующейся повышенной нагрузкой, ее производительность оставалась стабильной, в отличие от методов машинного обучения, таких как XGBoost и Random Forest, которые показали снижение эффективности (см. рис. 3). Это указывает на то, что предложенный подход, сочетающий возможности больших языковых моделей и логических правил, обладает значительным преимуществом в ситуациях, требующих надежной работы в условиях нестабильного спроса, и может служить основой для создания более устойчивых цепочек поставок.
Представленное исследование демонстрирует, что эффективное обнаружение аномалий во временных рядах, особенно в контексте управления цепочками поставок, требует не только алгоритмической точности, но и способности к интерпретации и адаптации. Авторы предлагают подход, в котором большие языковые модели служат мостом между человеческим опытом и машинным обучением, создавая явные логические правила. Это позволяет не просто выявлять отклонения, но и понимать причины их возникновения. Как заметил Дональд Кнут: «Преждевременная оптимизация — корень всех зол». В данном случае, стремление к немедленному улучшению показателей без понимания базовых принципов и логики работы системы может привести к неэффективности и уязвимости. Разработанный фреймворк позволяет создавать надежные и понятные системы обнаружения аномалий, способные адаптироваться к изменяющимся условиям и обеспечивать устойчивость цепочек поставок.
Что же дальше?
Предложенная методика, несомненно, представляет собой шаг к более осмысленному взаимодействию человека и искусственного интеллекта в области обнаружения аномалий временных рядов. Однако, следует признать, что любое стремление к формализации экспертных знаний — это лишь попытка зафиксировать текущее состояние системы, обреченной на старение. Логические правила, даже полученные с помощью больших языковых моделей, — это не вечные истины, а лишь отражение понимания на определенный момент времени. Система, стабильно работающая на основе этих правил, может оказаться лишь отложенным проявлением более глубоких, скрытых изменений.
Будущие исследования должны сосредоточиться не столько на повышении точности, сколько на разработке механизмов адаптации этих правил к изменяющимся условиям. Ключевым представляется вопрос о самообучении системы — способности пересматривать и корректировать логику, основываясь на новых данных и опыте. Важно помнить, что сама стабильность может стать ловушкой, маскирующей надвигающуюся катастрофу, если система не способна к эволюции.
В конечном счете, успех подобного подхода зависит не от совершенства алгоритмов, а от способности признать неизбежность времени и разработать системы, которые стареют достойно — то есть, способны адаптироваться, учиться и сохранять свою функциональность в постоянно меняющемся мире.
Оригинал статьи: https://arxiv.org/pdf/2601.19255.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- ПРОГНОЗ ДОЛЛАРА
2026-01-28 20:33