Автор: Денис Аветисян
Новое исследование демонстрирует, что модели искусственного интеллекта способны прогнозировать наступление задокументированных рисков, основываясь на анализе публичной отчетности компаний.
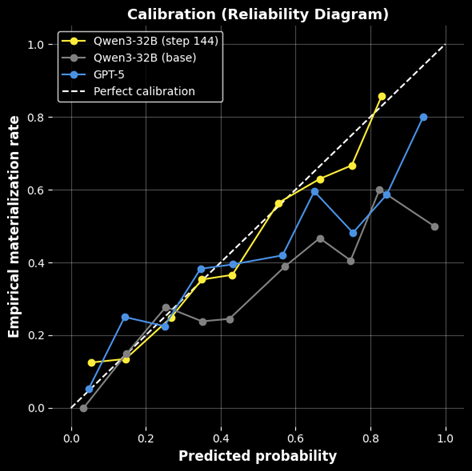
Разработанный подход позволяет с высокой точностью оценивать вероятность наступления рисков, описанных в документах SEC, без использования ручной разметки или проприетарных данных.
Несмотря на то, что раскрытия рисков в документах SEC описывают потенциальные неблагоприятные события, их количественная оценка вероятности затруднена, что ограничивает возможности вероятностного анализа. В работе ‘Foresight Learning for SEC Risk Prediction’ представлен автоматизированный конвейер генерации данных, преобразующий качественные раскрытия рисков в хронологически привязанные метки, используя только общедоступную информацию. Показано, что компактная большая языковая модель, обученная на этом наборе данных, существенно превосходит существующие модели и даже передовые универсальные модели, такие как GPT-5, по точности и калибровке вероятностных прогнозов. Открывает ли этот подход, основанный на методе Foresight Learning, путь к созданию специализированных экспертных моделей, способных извлекать откалиброванные сигналы из корпоративных документов без ручной разметки или использования проприетарных данных?
Предвидение Рисков: Эхо Будущих Сбоев в Регуляторных Данных
Точное прогнозирование будущих рисков, раскрываемых в документах SEC, имеет решающее значение для принятия обоснованных инвестиционных решений. Инвесторы полагаются на прозрачность компаний в отношении потенциальных угроз, и способность предвидеть эти риски позволяет более эффективно оценивать стоимость активов и управлять портфелем. Недооценка или игнорирование будущих рисков может привести к значительным финансовым потерям, в то время как своевременное выявление и анализ этих рисков позволяет инвесторам адаптировать свои стратегии и минимизировать негативные последствия. Таким образом, совершенствование методов прогнозирования рисков, основанных на анализе раскрываемой информации, является ключевым фактором для обеспечения стабильности и прибыльности инвестиций.
Традиционные методы оценки рисков, применяемые к финансовым отчетам, сталкиваются со значительными трудностями при обработке огромных объемов текстовой информации, содержащихся в документах SEC. Анализ этих отчетов, зачастую исчисляемых тысячами страниц, требует колоссальных временных затрат и ручного труда, что делает процесс неэффективным и подверженным человеческим ошибкам. Существующие подходы, основанные на ключевых словах или тематическом моделировании, часто не способны уловить тонкие нюансы и скрытые взаимосвязи между различными рисками, а также не учитывают контекст, в котором они раскрываются. В результате, важная информация о потенциальных угрозах может быть упущена из виду, что негативно сказывается на точности прогнозов и принятии обоснованных инвестиционных решений.
Определение временных рамок реализации выявленных рисков представляет собой серьезную проблему для современных прогностических моделей, анализирующих нормативную отчетность. В то время как существующие алгоритмы способны идентифицировать потенциальные угрозы, указанные в документах, например, в отчетах SEC, предсказание когда именно этот риск может материализоваться остается сложной задачей. Это связано с тем, что риски часто описываются в общих терминах, без четких временных ориентиров, и могут зависеть от множества внешних факторов, которые сложно учесть. Понимание временной динамики риска имеет решающее значение для принятия обоснованных инвестиционных решений, поскольку своевременная оценка вероятности наступления негативного события позволяет более эффективно управлять портфелем и минимизировать потенциальные убытки. Таким образом, разработка моделей, способных точно прогнозировать сроки реализации рисков, является ключевым направлением в области анализа финансовой отчетности.
Генерируя Прозрения: RAG и Gemini в Службе Прогнозирования
Для автоматической генерации релевантных “Запросов о рисках” из документов SEC используется конвейер Retrieval-Augmented Generation (RAG), основанный на языковой модели Gemini. Данный подход позволяет извлекать информацию из больших объемов неструктурированного текста, представленного в финансовых отчетах, и преобразовывать её в структурированные запросы, предназначенные для выявления потенциальных рисков. В процессе работы RAG-конвейер сначала извлекает релевантные фрагменты текста из документов SEC, а затем модель Gemini использует эти фрагменты для генерации конкретных запросов, фокусирующихся на выявлении рисков, указанных в исходных данных.
Конвейер обработки данных преобразует неструктурированный текст из документов в структурированные утверждения, представляющие потенциальные риски. Этот процесс включает в себя извлечение ключевых фактов и отношений из текста и их представление в формализованном виде, например, в виде троек “субъект-отношение-объект”. Структурированные данные позволяют проводить более точный и целенаправленный анализ, а также использовать их для прогнозирования потенциальных рисков, связанных с деятельностью компании, на основе информации, содержащейся в исходных документах.
Основываясь на исходных документах SEC, процесс генерации запросов о рисках обеспечивает высокую точность и релевантность получаемых данных. Использование фактического текста filings в качестве основы для генерации позволяет избежать галлюцинаций и неточностей, типичных для моделей, работающих исключительно с общими знаниями. Данный подход гарантирует, что сгенерированные запросы непосредственно относятся к конкретным рискам, описанным в отчетах, и могут быть использованы для целенаправленного прогнозирования и анализа.
Qwen3-32B и Перспективное Обучение: Видя Риски За Рамками Настоящего
В качестве основы для модели прогнозирования рисков используется Qwen3-32B — мощный декодер-only трансформатор, разработанный компанией Alibaba. Qwen3-32B представляет собой языковую модель с 32 миллиардами параметров, обученную на большом объеме текстовых и кодовых данных. Выбор архитектуры декодер-only обусловлен её эффективностью в задачах генерации последовательностей, что позволяет модели предсказывать вероятные сценарии развития рисков на основе имеющихся данных. Модель Qwen3-32B была адаптирована и дообучена для специфических задач прогнозирования рисков, обеспечивая высокую точность и надежность результатов.
Модель обучается с использованием фреймворка перспективного обучения (foresight learning), в котором в качестве сигналов обучения используются будущие разрешенные исходы. Это означает, что во время обучения модель получает доступ к информации о том, как риски реализовались в будущем, что позволяет ей устанавливать более точные связи между текущими данными и вероятностью наступления рисковых событий. Такой подход позволяет модели не просто выявлять корреляции, но и прогнозировать развитие событий во времени, что критически важно для оценки и управления рисками. Использование будущих исходов в качестве сигналов обучения повышает способность модели к прогнозированию по сравнению с традиционными методами, основанными исключительно на текущей информации.
Использование подхода, основанного на обучении с предвидением (foresight learning), позволило модели изучить временную динамику возникновения рисков и повысить точность прогнозирования. Данный метод предполагает использование будущих разрешенных результатов в качестве сигналов обучения, что обеспечивает более эффективное моделирование временных зависимостей. В результате, модель достигла значения метрики Brier score, равного 0.0287, что свидетельствует о высокой калибровке вероятностных прогнозов и общей точности предсказаний.
Калибровка и Автоматизированные Данные: Укрепляя Основы Прогностической Системы
Точность калибровки имеет решающее значение для надежности моделей машинного обучения, поскольку она обеспечивает соответствие вероятностей, предсказываемых моделью, фактическим наблюдаемым результатам. Для оценки этой точности используется метрика, известная как Ошибка Ожидаемой Калибровки (Expected Calibration Error, ECE). В рамках проведенного исследования удалось достичь значения ECE, равного 0.0287, что свидетельствует о высокой степени соответствия между предсказанными вероятностями и реальными исходами. Низкое значение ECE указывает на то, что модель не только точно предсказывает результаты, но и правильно оценивает свою уверенность в этих предсказаниях, что особенно важно для приложений, где требуется надежная оценка рисков и принятие обоснованных решений.
Разработана автоматизированная система генерации синтетических данных, призванная расширить объём обучающей выборки и повысить эффективность модели. Эта система создает искусственные данные, дополняя реальные наборы, что позволяет значительно улучшить способность модели к обобщению и адаптации к новым ситуациям. Использование синтетических данных позволяет не только увеличить объём информации для обучения, но и контролировать её качество и разнообразие, что особенно важно при работе с ограниченными или предвзятыми реальными данными. В результате, модель, обученная с использованием данной системы, демонстрирует повышенную точность и надёжность в прогнозировании, превосходя по своим показателям как предварительно обученные базовые модели, так и современные языковые модели.
Разработанная система автоматической генерации данных позволила значительно улучшить калибровку и обобщающую способность модели. Использование синтетических данных в процессе обучения привело к почти 80%-ному снижению ошибки калибровки — с 0.1419 для предварительно обученной базовой модели до значительно более низкого значения. Результаты превзошли как производительность передовых больших языковых моделей, так и наивных базовых подходов, демонстрируя эффективность данного метода в повышении надежности и точности прогнозов. Этот подход открывает новые возможности для создания более устойчивых и достоверных систем искусственного интеллекта, способных эффективно работать в различных условиях и с разными наборами данных.
Исследование, представленное в статье, демонстрирует, что системы предсказания рисков, основанные на больших языковых моделях, способны к самообучению и адаптации к изменяющимся условиям. Это напоминает о словах Алана Тьюринга: «Самое важное — это не создавать машину, которая думает как человек, а создавать машину, которая может учиться». Обучение моделей на данных из SEC filings позволяет им выявлять закономерности и прогнозировать вероятность наступления рисков, без необходимости ручной разметки данных. Система, подобно живому организму, развивается и совершенствуется, реагируя на входящую информацию. Отказ от идеального решения в пользу системы, способной к самокоррекции, соответствует философии, согласно которой гибкость и адаптивность важнее, чем абсолютная точность.
Куда же дальше?
Представленная работа демонстрирует возможность предсказания материализации рисков, зафиксированных в документах SEC, с использованием больших языковых моделей. Однако, следует помнить: система — это не машина, это сад; предсказание риска — лишь первый росток. Важнее понять, как эти модели будут эволюционировать в условиях меняющихся регуляторных ландшафтов и непредсказуемости финансовых рынков. Калибровка вероятностей — это лишь инструмент, но истинная ценность заключается в способности системы «прощать ошибки», то есть адаптироваться к неточностям и неполноте данных.
Основным ограничением остается зависимость от данных, доступных в публичных документах. Риски, не раскрытые или завуалированные, останутся вне поля зрения модели. Поэтому, вместо того чтобы стремиться к абсолютной точности предсказаний, целесообразно сосредоточиться на создании систем, способных выявлять не только известные риски, но и потенциальные «слепые зоны» в информации. Каждый архитектурный выбор — это пророчество о будущем сбое, и важно учитывать, что система всегда будет неполной.
Вместо автоматизированного надзора, возможно, стоит говорить о «садоводстве надзора» — о создании экосистемы, в которой модели, регуляторы и участники рынка совместно поддерживают устойчивость финансовой системы. Устойчивость не в изоляции компонентов, а в их способности прощать ошибки друг друга. Истинный прогресс не в увеличении точности предсказаний, а в создании более гибких и адаптивных систем.
Оригинал статьи: https://arxiv.org/pdf/2601.19189.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SIREN ПРОГНОЗ. SIREN криптовалюта
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- ПРОГНОЗ ДОЛЛАРА
- ZEC ПРОГНОЗ. ZEC криптовалюта
2026-01-28 17:15