Автор: Денис Аветисян
В новой статье мы представляем детальный план создания системы, позволяющей задавать вопросы о финансах на естественном языке и получать точные ответы.
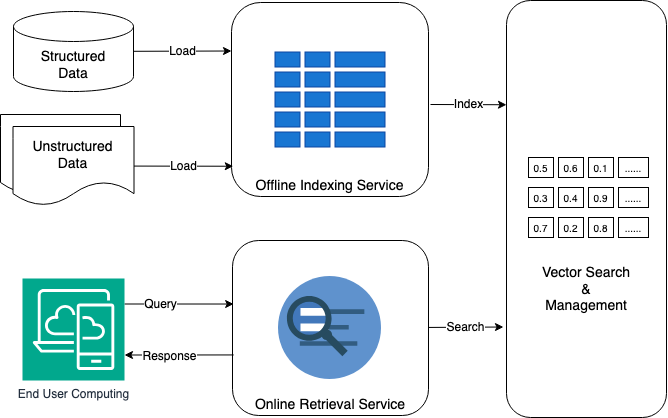
Обзор архитектуры системы поиска по финансовым знаниям, основанной на векторном поиске, семантическом анализе и гибридном извлечении данных.
Несмотря на растущие объемы финансовых данных, эффективный поиск и извлечение знаний остаются сложной задачей. В работе ‘FinMetaMind: A Tech Blueprint on NLQ Systems for Financial Knowledge Search’ представлен технологический проект системы поиска по естественному языку (NLQ), предназначенной для работы с финансовыми знаниями. Предложенная архитектура, сочетающая векторный поиск, внедрения и гибридный поиск, позволяет значительно повысить точность и скорость доступа к информации. Каким образом подобные системы смогут трансформировать финансовый анализ и принятие решений в будущем?
От слов к смыслу: вызовы семантического поиска
Традиционный поиск по ключевым словам зачастую сталкивается с трудностями при обработке сложных запросов и понимании смысла текста, что приводит к выдаче нерелевантных результатов. Вместо того чтобы анализировать намерение пользователя и контекст запроса, такая система просто сопоставляет введенные слова с терминами в базе данных. Например, запрос «лекарство от головной боли» может выдать информацию о головных уборах или инструментах для забивания гвоздей, если эти слова также присутствуют в документе. Эта неспособность различать значения и учитывать нюансы языка создает значительные проблемы для пользователей, которым требуется точная и релевантная информация, и подчеркивает необходимость более интеллектуальных методов поиска, способных понимать смысл запроса и контекст документа.
В эпоху экспоненциального роста неструктурированных данных, таких как текстовые документы, публикации в социальных сетях и веб-страницы, традиционные методы поиска, основанные на сопоставлении ключевых слов, оказываются все менее эффективными. Необходимость анализа смысла текста, а не просто идентификации совпадений по терминам, становится критически важной. Современные системы стремятся понять контекст, намерения и связи между словами, чтобы предоставлять релевантные результаты даже при сложных и неоднозначных запросах. Это требует применения методов обработки естественного языка, машинного обучения и семантического анализа, позволяющих извлекать знания из огромных объемов текстовой информации и предоставлять пользователям точные и полезные ответы.
Современные приложения, от интеллектуальных помощников и систем анализа больших данных до поисковых движков и автоматизированных служб поддержки, все чаще сталкиваются с необходимостью понимания смысла, заключенного в текстовой информации. Эффективное преодоление разрыва между естественным языком, которым пользуется человек, и извлечением данных из баз, становится ключевым фактором для их успешной работы. Простое сопоставление ключевых слов уже не удовлетворяет потребностям пользователей, требующих точных и релевантных ответов на сложные запросы. Поэтому, разработка методов, способных улавливать нюансы языка, контекст и намерения, стоящие за текстом, является не просто технологической задачей, но и необходимостью для создания интуитивно понятных и эффективных систем, способных обрабатывать и интерпретировать информацию так же, как это делает человек.
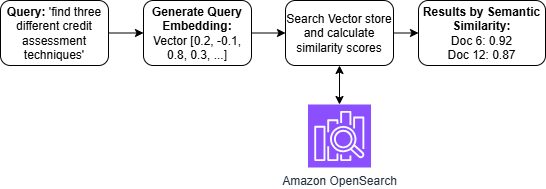
Строим семантические мосты: сила встраиваний
Встраивания (embeddings) представляют собой преобразование текстовых данных в плотные векторные представления, позволяющие численно выразить семантические связи между словами и понятиями. В отличие от традиционных методов, таких как one-hot encoding, где каждое слово представляется разреженным вектором высокой размерности, встраивания создают векторы меньшей размерности, в которых близость векторов отражает семантическую схожесть соответствующих слов или фраз. Это позволяет алгоритмам машинного обучения эффективно обрабатывать текст, учитывая контекст и смысл, а не только лексическое соответствие. Таким образом, слова со схожим значением будут представлены близкими векторами в многомерном пространстве, что обеспечивает возможность выполнения различных задач, таких как семантический поиск, кластеризация текста и анализ настроений.
Для создания векторных представлений текста, или эмбеддингов, широко используются модели, такие как BERT и модели OpenAI. В ходе экспериментов рассматривались различные модели, включая NV-Embed-v2, gte-Qwen2-7B-instruct и amazon.titan-embed-text-v2. Эти модели преобразуют текстовые данные в плотные векторы, позволяя улавливать семантические связи между словами и понятиями, что является ключевым для задач обработки естественного языка, включая поиск, классификацию и анализ текста.
В ходе экспериментов по созданию семантических представлений текста модель amazon.titan-embed-text-v2 была выбрана в качестве оптимальной. Данный выбор обусловлен ее превосходящими показателями по сравнению с другими протестированными моделями, такими как NV-Embed-v2, gte-Qwen2-7B-instruct, в задачах, требующих точного отражения семантических связей между словами и концепциями. Результаты тестирования продемонстрировали, что amazon.titan-embed-text-v2 обеспечивает более качественные векторные представления, что положительно сказывается на эффективности последующих этапов обработки естественного языка.
Платформа Amazon Bedrock обеспечивает упрощенный доступ к широкому спектру моделей для создания векторных представлений (embeddings), избавляя от необходимости самостоятельной настройки и развертывания инфраструктуры. Интеграция осуществляется через унифицированный API, что позволяет разработчикам легко экспериментировать с различными моделями, такими как NV-Embed-v2, gte-Qwen2-7B-instruct и amazon.titan-embed-text-v2, и выбирать наиболее подходящую для конкретной задачи. Bedrock берет на себя управление моделями и масштабирование, позволяя сосредоточиться на разработке приложений, использующих семантические представления данных.
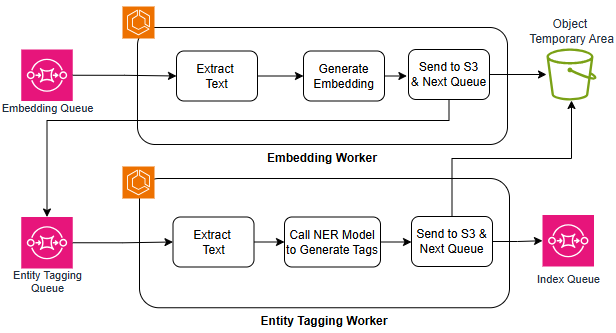
Индексируя для понимания: масштабирование векторного поиска
Служба оффлайн-индексации использует алгоритмы, такие как Hierarchical Navigable Small Worlds (HNSW), для создания эффективных векторных индексов. HNSW — это алгоритм приближенного ближайшего соседа (Approximate Nearest Neighbor, ANN), который строит многоуровневый граф, позволяющий быстро находить ближайшие векторы. Использование HNSW обеспечивает высокую скорость поиска и масштабируемость, необходимые для работы с большими объемами векторных данных. Алгоритм оптимизирован для снижения потребления памяти и повышения производительности при запросах, особенно в сценариях, где требуется поиск по миллионам или миллиардам векторов.
Сервис индексации использует конвейеры Extract и AI Enrichment для предварительной обработки и обогащения данных перед их добавлением в индекс. Конвейер Extract выполняет извлечение релевантной информации из исходных данных, например, извлечение текста из документов или метаданных из файлов. Затем конвейер AI Enrichment применяет модели искусственного интеллекта для улучшения качества данных, включая нормализацию текста, удаление стоп-слов, стемминг и лемматизацию, а также для добавления новых признаков, таких как тематические метки или семантические векторы. Этот процесс позволяет значительно повысить точность и релевантность результатов векторного поиска.
Сервис Elastic Container Service (ECS) обеспечивает развертывание и управление конвейерами индексации, что критически важно для масштабируемости и надежности системы. ECS автоматизирует процессы выделения ресурсов, мониторинга и восстановления компонентов конвейера, включая Extract Pipeline и AI Enrichment Pipeline. Это позволяет динамически адаптировать вычислительные мощности к текущей нагрузке, обеспечивая высокую пропускную способность при индексации больших объемов данных и минимизируя время отклика. Кроме того, ECS предоставляет механизмы автоматического масштабирования и самовосстановления, что гарантирует непрерывную работу системы даже в случае сбоев отдельных компонентов или увеличения нагрузки.
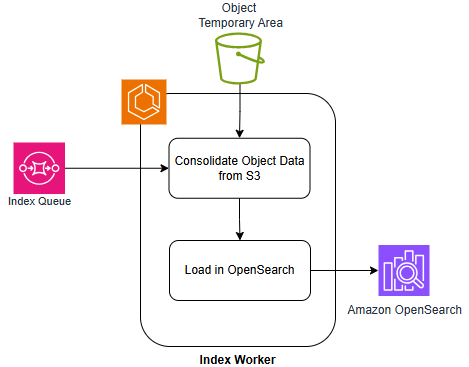
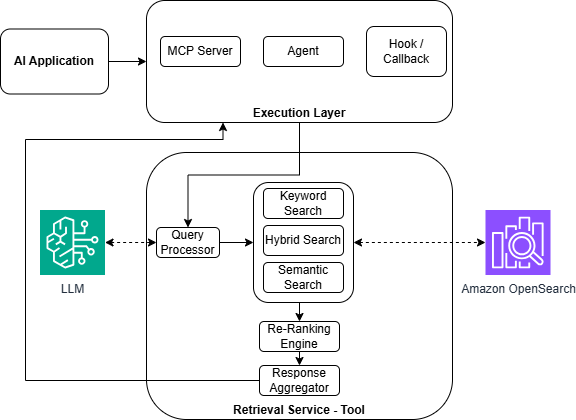
Интеллектуальное извлечение: от запроса к ответу
Онлайн-сервис поиска информации преобразует запросы, сформулированные на естественном языке, в векторные поисковые запросы, используя принцип семантического понимания. Вместо простого сопоставления ключевых слов, система создает числовое представление запроса — вектор, отражающий его смысл. Этот вектор сопоставляется с векторами, представляющими документы в базе данных, что позволяет находить информацию, релевантную не по ключевым словам, а по смыслу. Такой подход, основанный на создании и сопоставлении эмбеддингов — многомерных векторных представлений — значительно повышает точность и полноту поиска, особенно в случаях, когда пользователь формулирует запрос неоднозначно или использует синонимы.
Сервис интеллектуального поиска использует гибридный подход, объединяя возможности векторного и ключевого поиска для достижения оптимального баланса между полнотой и точностью извлечения информации. Векторный поиск, основанный на семантическом анализе запроса, позволяет находить релевантные документы, даже если они не содержат точных ключевых слов. В то же время, традиционный ключевой поиск обеспечивает высокую точность при совпадении запроса с конкретными терминами в документах. Эффективность гибридного поиска напрямую зависит от взвешивания этих двух компонентов — регулировка веса позволяет оптимизировать систему для конкретных задач, например, повысить полноту поиска за счет увеличения веса векторного поиска, или улучшить точность, отдав приоритет ключевому поиску. Такое комбинированное решение обеспечивает более надежное и контекстуально-осмысленное извлечение информации по сравнению с использованием только одного из методов.
Интеграция с технологией генерации, дополненной поиском (Retrieval-Augmented Generation), позволяет системе не просто находить релевантные данные в ответ на запрос, но и активно использовать их для формирования связных и осмысленных ответов. Вместо простой выдачи фрагментов текста, система анализирует полученную информацию, выявляет ключевые взаимосвязи и на их основе генерирует новый, оригинальный текст, отвечающий на вопрос пользователя. Этот подход значительно повышает ценность предоставляемой информации, поскольку она представляется не в виде разрозненных фактов, а в виде структурированного и понятного ответа, адаптированного к конкретному запросу. Таким образом, система выходит за рамки простого поиска, превращаясь в интеллектуального помощника, способного не только находить информацию, но и обрабатывать её, извлекая полезные знания.
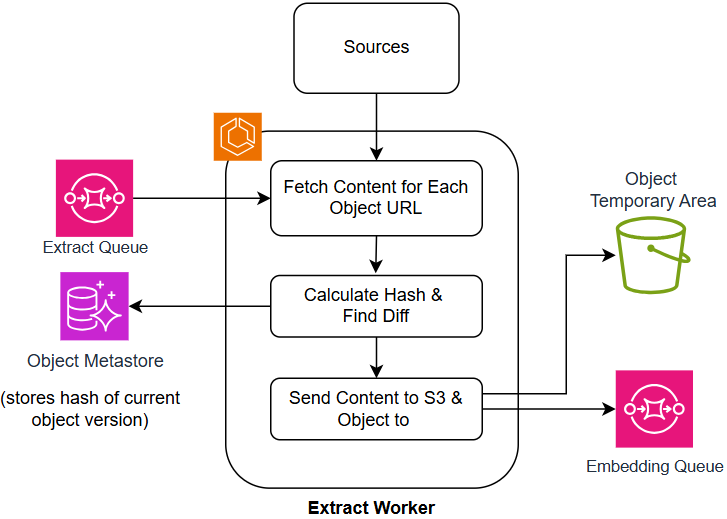
Полный конвейер: улучшение данных и запросов
Конвейер обогащения данных на основе искусственного интеллекта, включающий в себя компонент Embedding Worker и компонент Entity Tagging Worker, играет ключевую роль в подготовке информации для векторизации. Embedding Worker преобразует текстовые данные в векторные представления, позволяя алгоритмам машинного обучения понимать семантическое значение текста. Параллельно, Entity Tagging Worker выявляет и классифицирует именованные сущности, такие как организации, люди и места, что значительно улучшает точность и релевантность последующего анализа. Совместная работа этих компонентов обеспечивает создание высококачественных векторных представлений данных, необходимых для эффективной работы систем поиска, анализа настроений и других приложений, использующих машинное обучение. Таким образом, данный конвейер является фундаментальным этапом в процессе извлечения ценной информации из неструктурированных данных.
Преобразование текста в SQL расширяет возможности системы обработки запросов на естественном языке, позволяя пользователям взаимодействовать со структурированными данными, используя привычные фразы и вопросы. Вместо написания сложных SQL-запросов, система автоматически интерпретирует запрос на естественном языке и преобразует его в соответствующий SQL-код для извлечения необходимой информации из базы данных. Этот подход значительно упрощает доступ к данным для пользователей, не обладающих навыками программирования или знаниями SQL, открывая новые возможности для анализа и принятия решений на основе данных. Система обеспечивает гибкость и удобство взаимодействия, позволяя задавать вопросы о данных в свободной форме и получать точные и релевантные ответы.
Постоянная оптимизация каждого этапа обработки данных — от извлечения информации из различных источников до финальной обработки запросов — является ключом к раскрытию более глубоких и значимых знаний. Улучшение эффективности на каждом шаге конвейера позволяет не только ускорить процесс анализа, но и выявить скрытые закономерности и взаимосвязи, которые могли бы остаться незамеченными при менее тщательном подходе. Совершенствование алгоритмов извлечения, повышение точности обработки естественного языка и оптимизация структуры запросов к базам данных — все эти шаги в совокупности способствуют более полному и осмысленному пониманию данных, открывая новые возможности для принятия обоснованных решений и инновационных открытий.
Данная работа, описывающая построение системы поиска по финансовым знаниям на основе естественного языка, неизбежно столкнётся с суровой реальностью продакшена. Теоретические изыскания о векторном поиске и гибридном извлечении информации кажутся элегантными, пока не начинается поток реальных запросов пользователей с их непредсказуемыми формулировками. Как метко заметил Давид Гильберт: «В математике нет трамплина; нужно карабкаться по лестнице». Именно так и здесь: каждый новый алгоритм, каждая оптимизация — это лишь ещё одна ступенька к пониманию того, насколько сложна задача извлечения знаний из огромных массивов финансовых данных. В конечном итоге, система будет доработана не столько теоретиками, сколько практиками, сталкивающимися с ежедневными вызовами реальной эксплуатации.
Что дальше?
Представленный анализ архитектуры систем обработки естественного языка для финансовых знаний, безусловно, демонстрирует возможности, но, как и любое элегантное решение, неминуемо порождает новый уровень технического долга. Внедрение векторного поиска и гибридных методов извлечения — это лишь перекладывание сложности. Вопрос не в том, можно ли найти нужную информацию, а в том, сколько ресурсов потребуется для поддержания системы в рабочем состоянии, когда финансовые данные начнут меняться с той скоростью, с которой меняются мемы в социальных сетях. Документация, как обычно, останется мифом, придуманным менеджерами, а CI/CD превратится в храм, где разработчики будут молиться, чтобы ничего не сломалось.
Следующим этапом, вероятно, станет гонка за ещё более сложными моделями, обещающими “понимание” финансового контекста. Но каждая такая модель — это ещё один слой абстракции, усложняющий отладку и повышающий вероятность катастрофических ошибок. Вместо того чтобы стремиться к “искусственному интеллекту”, возможно, стоит сосредоточиться на создании более надёжных и прозрачных инструментов, позволяющих экспертам эффективно работать с данными, а не полагаться на чёрный ящик, который иногда выдаёт осмысленные ответы.
В конечном счёте, всё это — лишь попытка автоматизировать процесс, который требует критического мышления и экспертных знаний. И, как показывает история, каждая «революционная» технология рано или поздно потребует ручной работы — только уже в большем объёме и с более высокой степенью сложности.
Оригинал статьи: https://arxiv.org/pdf/2601.17333.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- БИТКОИН ПРОГНОЗ. BTC криптовалюта
- ПРОГНОЗ ДОЛЛАРА К ШЕКЕЛЮ
- ЭФИРИУМ ПРОГНОЗ. ETH криптовалюта
- MYX ПРОГНОЗ. MYX криптовалюта
- SAROS ПРОГНОЗ. SAROS криптовалюта
- SOL ПРОГНОЗ. SOL криптовалюта
- ZEC ПРОГНОЗ. ZEC криптовалюта
- РИППЛ ПРОГНОЗ. XRP криптовалюта
- ДОГЕКОИН ПРОГНОЗ. DOGE криптовалюта
- FARTCOIN ПРОГНОЗ. FARTCOIN криптовалюта
2026-01-27 17:32